Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
貴仁 大和屋
11,433 views
Sql serverインデックスの断片化と再構築の必要性について
Technology
◦
Read more
4
Save
Share
Embed
Embed presentation
Download
Downloaded 56 times
1
/ 29
2
/ 29
Most read
3
/ 29
4
/ 29
5
/ 29
6
/ 29
7
/ 29
8
/ 29
9
/ 29
10
/ 29
Most read
11
/ 29
12
/ 29
13
/ 29
14
/ 29
15
/ 29
16
/ 29
17
/ 29
18
/ 29
19
/ 29
20
/ 29
21
/ 29
22
/ 29
Most read
23
/ 29
24
/ 29
25
/ 29
26
/ 29
27
/ 29
28
/ 29
29
/ 29
More Related Content
PDF
Sql server エンジニアに知ってもらいたい!! sql server チューニングアプローチ
by
Masayuki Ozawa
PDF
Sql server 構築 運用 tips
by
Masayuki Ozawa
PDF
Sql server よく聞く設定とその効果
by
Masayuki Ozawa
PDF
Always on 可用性グループ 構築時のポイント
by
Masayuki Ozawa
PPTX
Sql server 運用 101
by
Masayuki Ozawa
PDF
C34 Always On 可用性グループ 構築時のポイント by 小澤真之
by
Insight Technology, Inc.
PDF
Sql server パーティション 概要
by
Masayuki Ozawa
PDF
SQL Server パフォーマンスカウンター
by
Masayuki Ozawa
Sql server エンジニアに知ってもらいたい!! sql server チューニングアプローチ
by
Masayuki Ozawa
Sql server 構築 運用 tips
by
Masayuki Ozawa
Sql server よく聞く設定とその効果
by
Masayuki Ozawa
Always on 可用性グループ 構築時のポイント
by
Masayuki Ozawa
Sql server 運用 101
by
Masayuki Ozawa
C34 Always On 可用性グループ 構築時のポイント by 小澤真之
by
Insight Technology, Inc.
Sql server パーティション 概要
by
Masayuki Ozawa
SQL Server パフォーマンスカウンター
by
Masayuki Ozawa
What's hot
PPTX
SQL Server replication overview (JP)
by
elanlilac
PPTX
SQL Server 入門
by
Tsuyoshi Kitagawa
PDF
PostgreSQL: XID周回問題に潜む別の問題
by
NTT DATA OSS Professional Services
PPTX
Sql server のバックアップとリストアの基礎
by
Masayuki Ozawa
PDF
A24 SQL Server におけるパフォーマンスチューニング手法 - 注目すべきポイントを簡単に by 多田典史
by
Insight Technology, Inc.
PDF
PostgreSQLバックアップの基本
by
Uptime Technologies LLC (JP)
PDF
IT エンジニアのための 流し読み Microsoft 365 - 入門!Microsoft Defender ATP
by
TAKUYA OHTA
PPTX
[Citrix on Nutanix] LoginVSI による MCSとPVS の比較検証
by
Wataru Unno
PDF
YugabyteDBを使ってみよう(NewSQL/分散SQLデータベースよろず勉強会 #1 発表資料)
by
NTT DATA Technology & Innovation
PPTX
SCCM を用いた OS 展開
by
Yutaro Tamai
PDF
YugabyteDBを使ってみよう - part2 -(NewSQL/分散SQLデータベースよろず勉強会 #2 発表資料)
by
NTT DATA Technology & Innovation
PPTX
今こそ知りたいSpring Batch(Spring Fest 2020講演資料)
by
NTT DATA Technology & Innovation
PPTX
Azure 仮想マシンにおける運用管理・高可用性設計のベストプラクティス
by
Yusuke Oi
PDF
Standard Edition 2でも使えるOracle Database 12c Release 2オススメ新機能
by
Ryota Watabe
PDF
ゲームのインフラをAwsで実戦tips全て見せます
by
infinite_loop
PPTX
Sql server これだけはやっておこう 最終版
by
elanlilac
PPTX
サポート エンジニアが語る、トラブルを未然に防ぐための Azure インフラ設計
by
ShuheiUda
PPTX
VSCodeで作るPostgreSQL開発環境(第25回 PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
PDF
[A31]AWS上でOracleを利用するためのはじめの一歩!by Masatoshi Yoshida
by
Insight Technology, Inc.
PDF
マネージドPostgreSQLの実現に向けたPostgreSQL機能向上(PostgreSQL Conference Japan 2023 発表資料)
by
NTT DATA Technology & Innovation
SQL Server replication overview (JP)
by
elanlilac
SQL Server 入門
by
Tsuyoshi Kitagawa
PostgreSQL: XID周回問題に潜む別の問題
by
NTT DATA OSS Professional Services
Sql server のバックアップとリストアの基礎
by
Masayuki Ozawa
A24 SQL Server におけるパフォーマンスチューニング手法 - 注目すべきポイントを簡単に by 多田典史
by
Insight Technology, Inc.
PostgreSQLバックアップの基本
by
Uptime Technologies LLC (JP)
IT エンジニアのための 流し読み Microsoft 365 - 入門!Microsoft Defender ATP
by
TAKUYA OHTA
[Citrix on Nutanix] LoginVSI による MCSとPVS の比較検証
by
Wataru Unno
YugabyteDBを使ってみよう(NewSQL/分散SQLデータベースよろず勉強会 #1 発表資料)
by
NTT DATA Technology & Innovation
SCCM を用いた OS 展開
by
Yutaro Tamai
YugabyteDBを使ってみよう - part2 -(NewSQL/分散SQLデータベースよろず勉強会 #2 発表資料)
by
NTT DATA Technology & Innovation
今こそ知りたいSpring Batch(Spring Fest 2020講演資料)
by
NTT DATA Technology & Innovation
Azure 仮想マシンにおける運用管理・高可用性設計のベストプラクティス
by
Yusuke Oi
Standard Edition 2でも使えるOracle Database 12c Release 2オススメ新機能
by
Ryota Watabe
ゲームのインフラをAwsで実戦tips全て見せます
by
infinite_loop
Sql server これだけはやっておこう 最終版
by
elanlilac
サポート エンジニアが語る、トラブルを未然に防ぐための Azure インフラ設計
by
ShuheiUda
VSCodeで作るPostgreSQL開発環境(第25回 PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
[A31]AWS上でOracleを利用するためのはじめの一歩!by Masatoshi Yoshida
by
Insight Technology, Inc.
マネージドPostgreSQLの実現に向けたPostgreSQL機能向上(PostgreSQL Conference Japan 2023 発表資料)
by
NTT DATA Technology & Innovation
Similar to Sql serverインデックスの断片化と再構築の必要性について
PDF
C11,12 SQL Server 2012 Performance Tuning by Yukio Kumazawa
by
Insight Technology, Inc.
PDF
C13 SQL Server2012知られざるTips集 by 平山理
by
Insight Technology, Inc.
PDF
データベースのインデックスの種類と内部の仕組み.pdf
by
釣りキチ翔平
PPTX
SQL Server Performance Tuning Essentials
by
Masaki Hirose
PDF
Sql server data store data access internals
by
Masayuki Ozawa
PDF
COD2012 T2/T3 : 実機で試す SQL Server の現状取得 ハンズオンマニュアル
by
Masayuki Ozawa
PDF
SQL Server のインデックス設計
by
Koji Yamada
PDF
DBP-009_クラウドで実現するスケーラブルなデータ ウェアハウス Azure SQL Data Warehouse 解説
by
decode2016
PDF
SQL Server中級者のための実践で使えるかもしれないTips集
by
Sho Okada
PDF
A25 sql server data page structure deep dive
by
Masayuki Ozawa
PDF
[B31,32]SQL Server Internal と パフォーマンスチューニング by Yukio Kumazawa
by
Insight Technology, Inc.
PPTX
Sql server sql database 最新機能紹介
by
Oda Shinsuke
PDF
Seas で語られたこととは?
by
Masayuki Ozawa
PPTX
Microsoft Azure - SQL Data Warehouse
by
Microsoft
PDF
Dat004 開発者に捧ぐ「sql server_2016_
by
Tech Summit 2016
PDF
[db tech showcase Sapporo 2015] A26:SQL Server Data Page Structure Deep Dive ...
by
Insight Technology, Inc.
PDF
MySQL 5.5 Update #denatech
by
Mikiya Okuno
PPTX
開発者の方向けの Sql server(db) t sql 振り返り
by
Oda Shinsuke
PDF
SQL Server 2014 In Memory OLTP Overview
by
Masayuki Ozawa
PDF
[C14] ソーシャル ゲーム基盤を支える SQL Server by Takashi Inaba
by
Insight Technology, Inc.
C11,12 SQL Server 2012 Performance Tuning by Yukio Kumazawa
by
Insight Technology, Inc.
C13 SQL Server2012知られざるTips集 by 平山理
by
Insight Technology, Inc.
データベースのインデックスの種類と内部の仕組み.pdf
by
釣りキチ翔平
SQL Server Performance Tuning Essentials
by
Masaki Hirose
Sql server data store data access internals
by
Masayuki Ozawa
COD2012 T2/T3 : 実機で試す SQL Server の現状取得 ハンズオンマニュアル
by
Masayuki Ozawa
SQL Server のインデックス設計
by
Koji Yamada
DBP-009_クラウドで実現するスケーラブルなデータ ウェアハウス Azure SQL Data Warehouse 解説
by
decode2016
SQL Server中級者のための実践で使えるかもしれないTips集
by
Sho Okada
A25 sql server data page structure deep dive
by
Masayuki Ozawa
[B31,32]SQL Server Internal と パフォーマンスチューニング by Yukio Kumazawa
by
Insight Technology, Inc.
Sql server sql database 最新機能紹介
by
Oda Shinsuke
Seas で語られたこととは?
by
Masayuki Ozawa
Microsoft Azure - SQL Data Warehouse
by
Microsoft
Dat004 開発者に捧ぐ「sql server_2016_
by
Tech Summit 2016
[db tech showcase Sapporo 2015] A26:SQL Server Data Page Structure Deep Dive ...
by
Insight Technology, Inc.
MySQL 5.5 Update #denatech
by
Mikiya Okuno
開発者の方向けの Sql server(db) t sql 振り返り
by
Oda Shinsuke
SQL Server 2014 In Memory OLTP Overview
by
Masayuki Ozawa
[C14] ソーシャル ゲーム基盤を支える SQL Server by Takashi Inaba
by
Insight Technology, Inc.
More from 貴仁 大和屋
PPTX
SQL Server 2016 :Managed backup to Azure
by
貴仁 大和屋
PPTX
freemium
by
貴仁 大和屋
PPTX
Instrumentation and Telemetry ガイダンス
by
貴仁 大和屋
PDF
SQL Server運用実践 - 3年間80台の運用経験から20の教訓
by
貴仁 大和屋
PPTX
Azure sql database 入門 2014年10月版
by
貴仁 大和屋
PDF
組織のナレッジ共有の促進方法 - 人を動かす
by
貴仁 大和屋
PDF
Azure LT at Japan Oracle User Group
by
貴仁 大和屋
PPTX
Memcached api搭載の「my sql cluster 7.2」
by
貴仁 大和屋
PPTX
2011/12/3 わんくま同盟
by
貴仁 大和屋
PPTX
2011/11/26 Dot netlab
by
貴仁 大和屋
PPTX
Sql azureデータバックアップ方法
by
貴仁 大和屋
PPTX
Windows azureストレージの耐障害性
by
貴仁 大和屋
PPTX
Sql azure入門
by
貴仁 大和屋
PPTX
2012年1月技術ひろば
by
貴仁 大和屋
PDF
マニアックス5Sql azure
by
貴仁 大和屋
PPTX
Light switch × sql azure
by
貴仁 大和屋
PPTX
Sqlto azure前座
by
貴仁 大和屋
PPTX
Windows Azure BootCamp - SQL Azure
by
貴仁 大和屋
PPTX
Sql azure database copy
by
貴仁 大和屋
PPTX
Windows Phone 7 Series初めの一歩
by
貴仁 大和屋
SQL Server 2016 :Managed backup to Azure
by
貴仁 大和屋
freemium
by
貴仁 大和屋
Instrumentation and Telemetry ガイダンス
by
貴仁 大和屋
SQL Server運用実践 - 3年間80台の運用経験から20の教訓
by
貴仁 大和屋
Azure sql database 入門 2014年10月版
by
貴仁 大和屋
組織のナレッジ共有の促進方法 - 人を動かす
by
貴仁 大和屋
Azure LT at Japan Oracle User Group
by
貴仁 大和屋
Memcached api搭載の「my sql cluster 7.2」
by
貴仁 大和屋
2011/12/3 わんくま同盟
by
貴仁 大和屋
2011/11/26 Dot netlab
by
貴仁 大和屋
Sql azureデータバックアップ方法
by
貴仁 大和屋
Windows azureストレージの耐障害性
by
貴仁 大和屋
Sql azure入門
by
貴仁 大和屋
2012年1月技術ひろば
by
貴仁 大和屋
マニアックス5Sql azure
by
貴仁 大和屋
Light switch × sql azure
by
貴仁 大和屋
Sqlto azure前座
by
貴仁 大和屋
Windows Azure BootCamp - SQL Azure
by
貴仁 大和屋
Sql azure database copy
by
貴仁 大和屋
Windows Phone 7 Series初めの一歩
by
貴仁 大和屋
Recently uploaded
PDF
流行りに乗っかるClaris FileMaker 〜AI関連機能の紹介〜 by 合同会社イボルブ
by
Evolve LLC.
PDF
エンジニアが選ぶべきAIエディタ & Antigravity 活用例@ウェビナー「触ってみてどうだった?Google Antigravity 既存IDEと...
by
NorihiroSunada
PDF
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #2
by
Tasuku Takahashi
PDF
20251210_MultiDevinForEnterprise on Devin 1st Anniv Meetup
by
Masaki Yamakawa
PPTX
楽々ナレッジベース「楽ナレ」3種比較 - Dify / AWS S3 Vector / Google File Search Tool
by
Kiyohide Yamaguchi
PDF
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #1
by
Tasuku Takahashi
流行りに乗っかるClaris FileMaker 〜AI関連機能の紹介〜 by 合同会社イボルブ
by
Evolve LLC.
エンジニアが選ぶべきAIエディタ & Antigravity 活用例@ウェビナー「触ってみてどうだった?Google Antigravity 既存IDEと...
by
NorihiroSunada
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #2
by
Tasuku Takahashi
20251210_MultiDevinForEnterprise on Devin 1st Anniv Meetup
by
Masaki Yamakawa
楽々ナレッジベース「楽ナレ」3種比較 - Dify / AWS S3 Vector / Google File Search Tool
by
Kiyohide Yamaguchi
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #1
by
Tasuku Takahashi
Sql serverインデックスの断片化と再構築の必要性について
1.
SQL Server
インデックスの仕組みと 断片化、 再構築の必要性について 2012/02/14 インフラグループ 大和屋貴仁
2.
細かいお話の前に…… データベースのデータは、 FusionIOなどの物理ディスク に書き込んで、保存します。
3.
Chapter. 1 物理ディスクのデータ格納のおさらい
ざっくりとした説明をします。 概念レベルなので、 詳しい人にしたら、間違ってる箇所も。。。
4.
物理ディスクのデータ格納 物理ディスクにデータを格納する時は、 最初に部屋を確保します。 どーんと、広いフロアから人を探すの 大変ですよね?
↓まず、部屋を確保 ● Aさん→ ● ↑Aさん専用の部屋
5.
物理ディスクのデータ格納 どーんと、広いフロアに部屋を たくさん作っていきます。 ●
←こんな感じで、新しいデータを いれる度に部屋を確保します。
6.
物理ディスクのデータ格納 Aさんが太って、 部屋におさまらない場合は? ● ←はみ出しちゃう!!でも、はみ出したら迷惑。
7.
物理ディスクのデータ格納 Aさんの部屋を 大きくしてあげたら良いよね!
● ↑Aさんの部屋を大きくしてあげれば良い。
8.
物理ディスクのデータ格納 部屋を並べ替えたら、 Aさんの部屋も収納できるけど…… ●
←部屋を並べ替えてあげれば、 Aさんの部屋を確保できるけど…… Aさんだけの為に、わざわざ部屋並べ替えるの 手間だよね。
9.
物理ディスクのデータ格納 Aさんを切り刻め!!
10.
物理ディスクのデータ格納 切り刻んだAさんを あっちこっちにあるAさんの部屋に格納。
11.
物理ディスクのデータ格納 え!? Aさんが必要!?まじか……。 Aさん切り刻んでるから、まず集めなきゃ。
あっちこちにちらばっているAさんの部屋から Aさんだった残骸を集めて!
12.
物理ディスクのデータ格納 集めたAさんを くっつけて、Aさん復活!。
●
13.
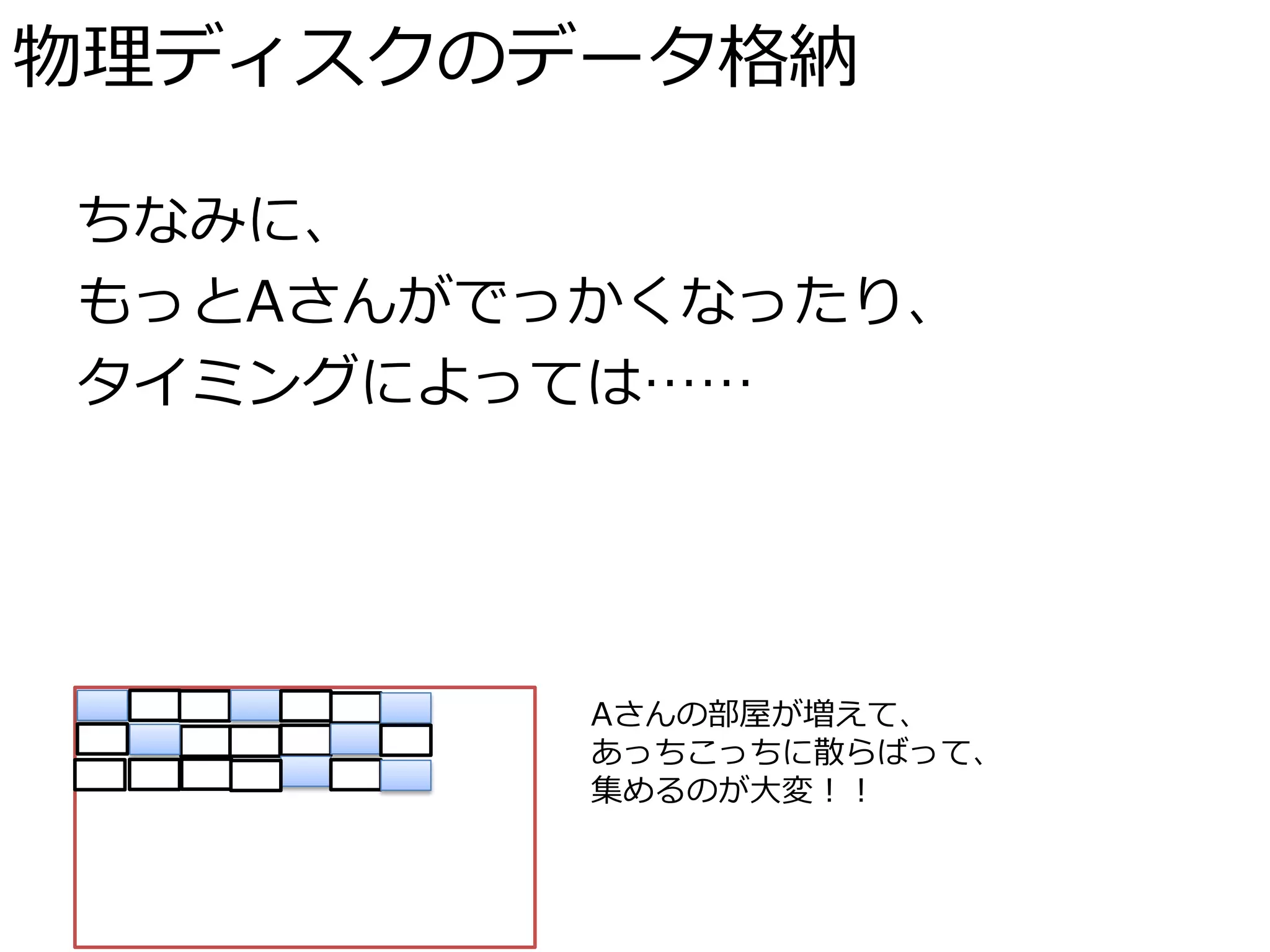
物理ディスクのデータ格納 ちなみに、 もっとAさんがでっかくなったり、 タイミングによっては……
Aさんの部屋が増えて、 あっちこっちに散らばって、 集めるのが大変!!
14.
物理ディスクのデータ格納 どれぐらい散らばっているかを示すのが 断片化率 と言います。
15.
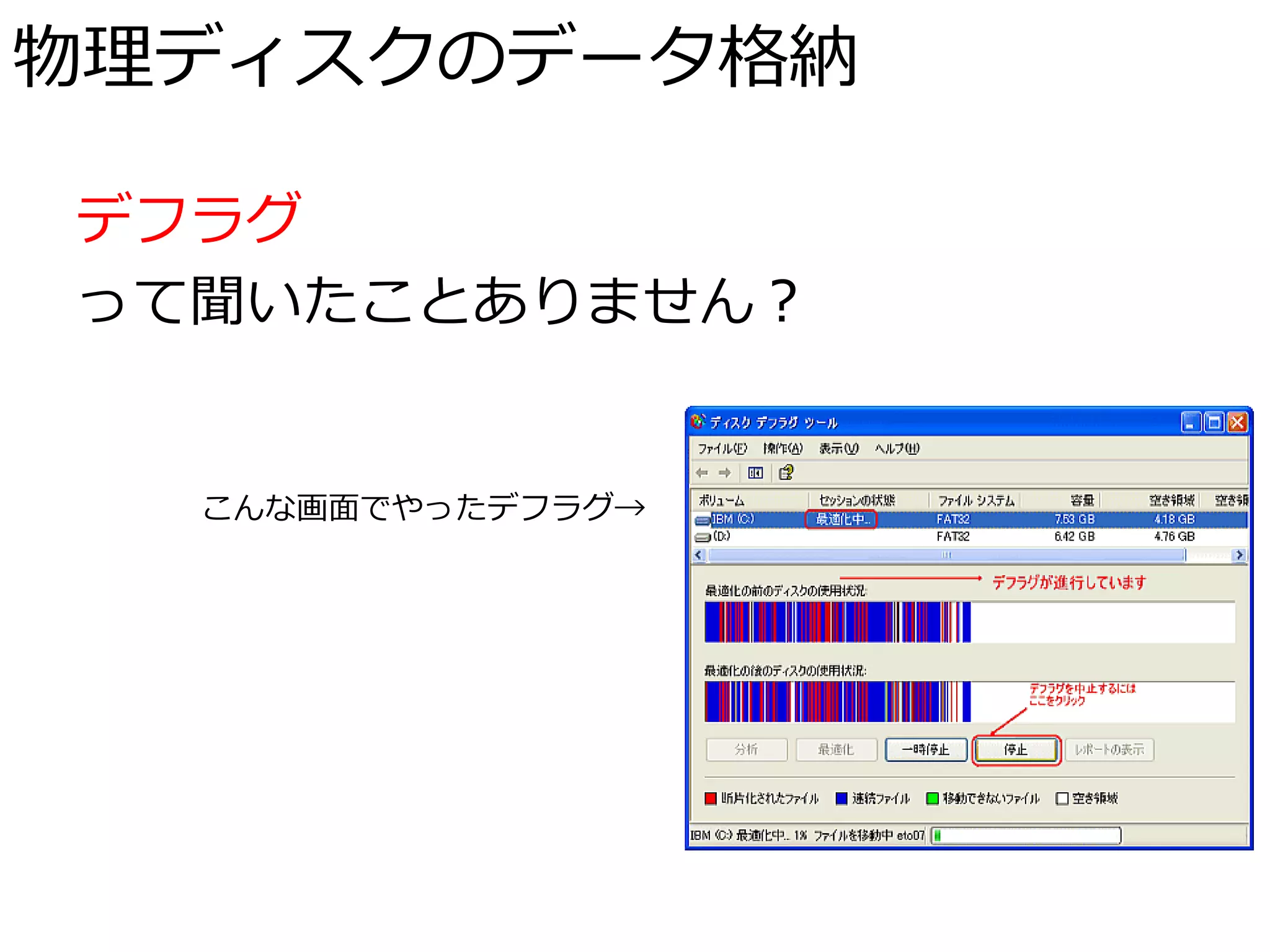
物理ディスクのデータ格納 デフラグ って聞いたことありません? こんな画面でやったデフラグ→
16.
物理ディスクのデータ格納 デフラグって、 切り刻んだAさんをくっつけて、 1個の部屋を用意してあげること。 ●
そう! 面倒だから、やらなかった 部屋の並べ替えですね。
17.
Chapter. 2 SQL Serverのインデックスの再構築
ざっくりとした説明をします。 概念レベルなので、 詳しい人にしたら、間違ってる箇所も。。。
18.
もう一度言います データベースのデータは、 FusionIOなどの物理ディスク に書き込んで、保存します。
19.
物理ディスクのデータ格納 データはディスクに書き込むんだから、 断片化とは無縁ではありません。
20.
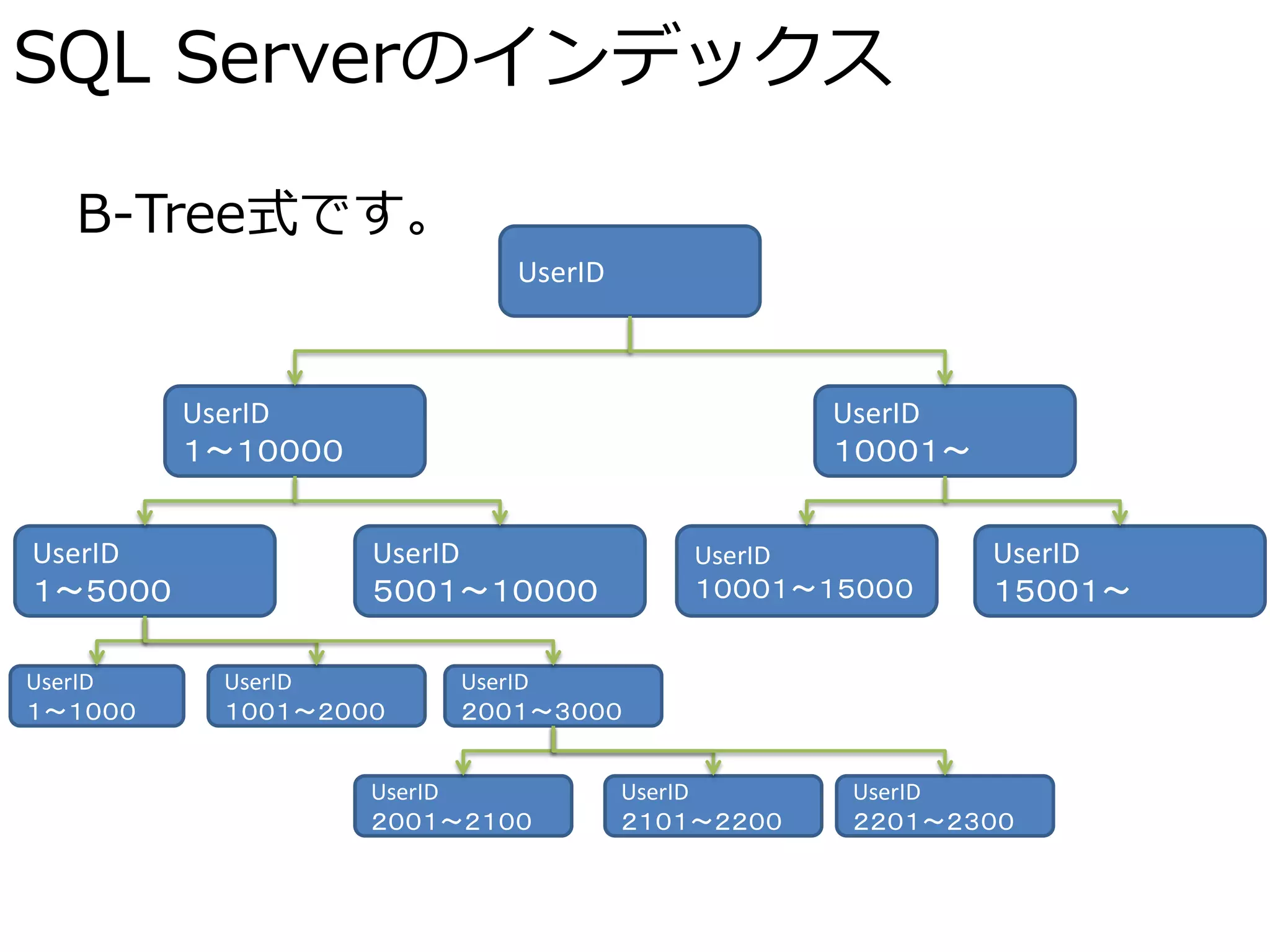
SQL Serverのインデックス
B-Tree式です。 UserID UserID UserID 1~10000 10001~ UserID UserID UserID UserID 1~5000 5001~10000 10001~15000 15001~ UserID UserID UserID 1~1000 1001~2000 2001~3000 UserID UserID UserID 2001~2100 2101~2200 2201~2300
21.
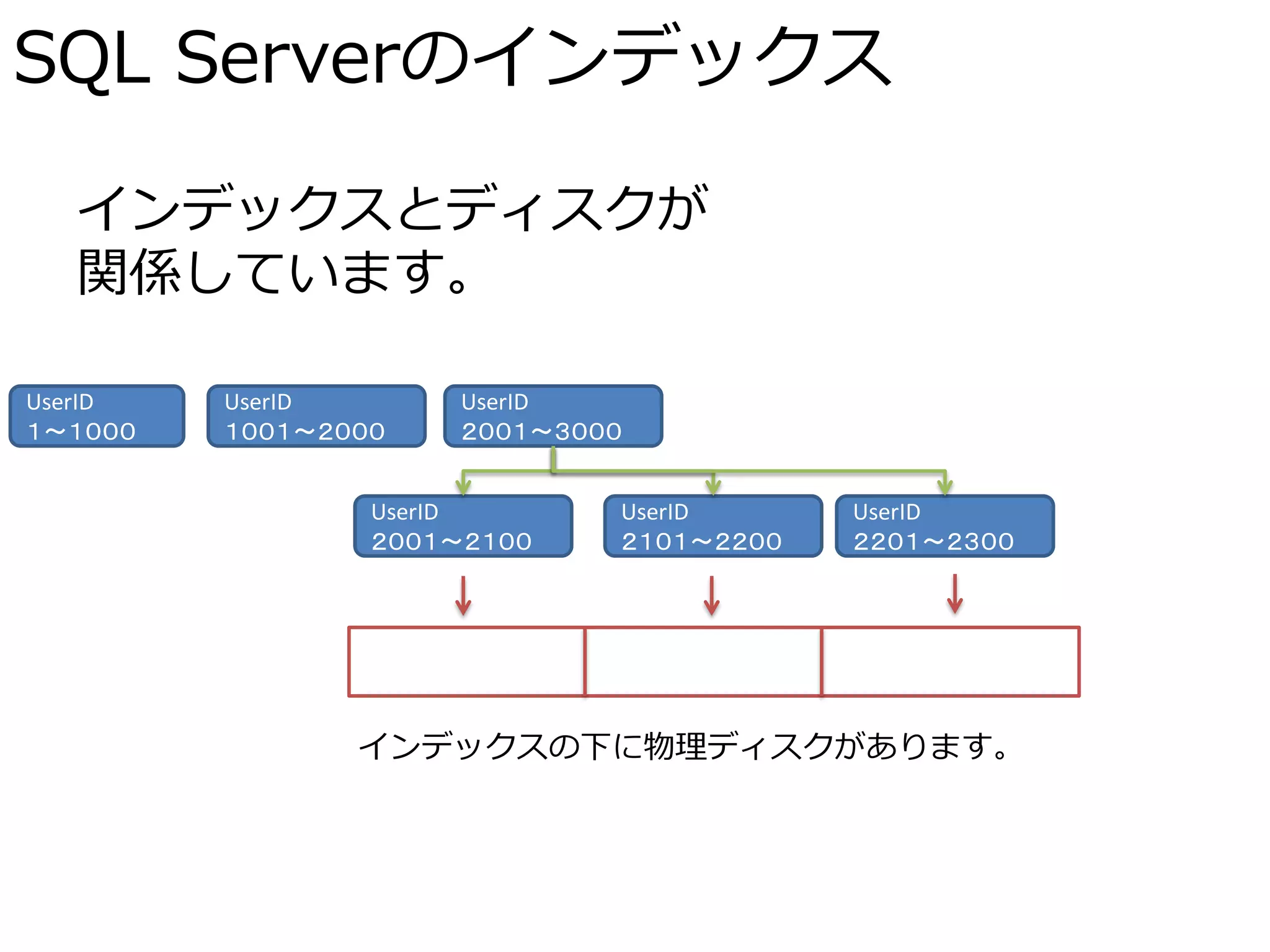
SQL Serverのインデックス
インデックスとディスクが 関係しています。 UserID UserID UserID 1~1000 1001~2000 2001~3000 UserID UserID UserID 2001~2100 2101~2200 2201~2300 インデックスの下に物理ディスクがあります。
22.
SQL Serverのインデックス
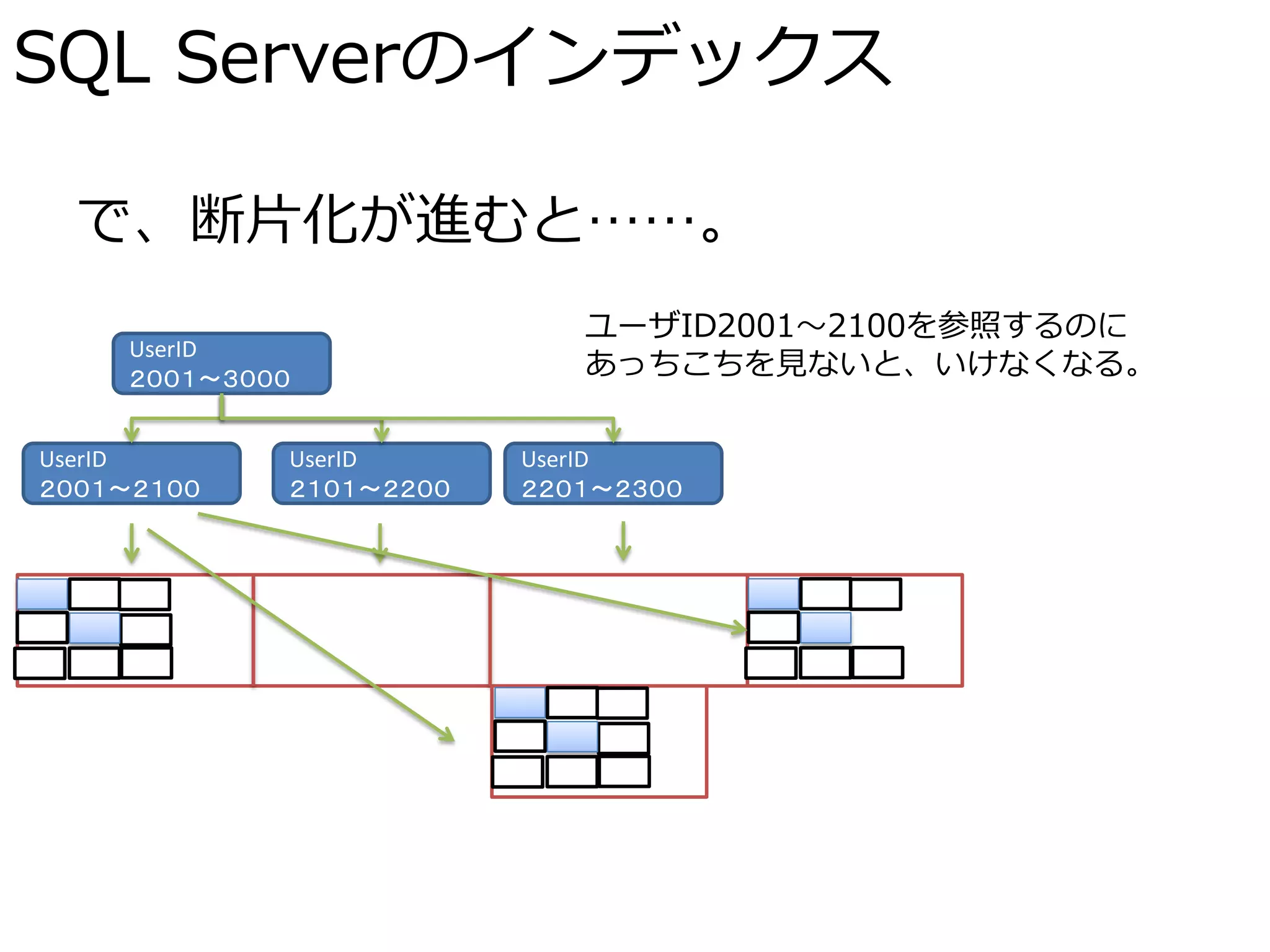
で、断片化が進むと……。 ユーザID2001~2100を参照するのに UserID 2001~3000 あっちこちを見ないと、いけなくなる。 UserID UserID UserID 2001~2100 2101~2200 2201~2300
23.
物理ディスクのデータ格納 データベースの中で、 断片化したデータを整理整頓するのが インデックスの再構築です。 物理ディスク上に散らばっているデータを 整理整頓する作業です。
24.
インデックスの再構築は 物理ディスク上に散らばっているデータを 物理的に整理整頓する作業です。 物理的に並べ替えているので、 途中でキャンセルすると、 元に戻します。
掃除をはじめて20分たったときに、 キャンセルすると 掃除をやめるのではなく、 掃除を始める前の状態にもどします。 キャンセルすると20分とは言いませんが、 案外時間かかることもあります。
25.
テーブルが断片化すると? • データを参照するのに、
CPU負荷が増えます。 Disk I/Oが増えます。 参照時間が増えます。 • データを更新するのに Diskスペースを確保し、 データを切り刻むので、 CPU負荷が増えます。 Disk I/Oが増えます。 更新時間が増えます。
26.
データの断片化は…… • データの更新、削除をしていけば
必ず断片化します。 • データ量が増えれば、増えるほど、 断片化によるオーバヘッドが増えます。
27.
インデックスの再構築は • 断片化率が高いほど、再構築に時間が
かかります。 • データ量が多いほど、再構築に時間が かかります。
28.
ご利用は計画的に。 DB性能に問題が無い段階でも、 定期的に、 断片化率の高いテーブルのインデックスを 再構築しておくことで、 トータルでのメンテ時間は短縮できます。
29.
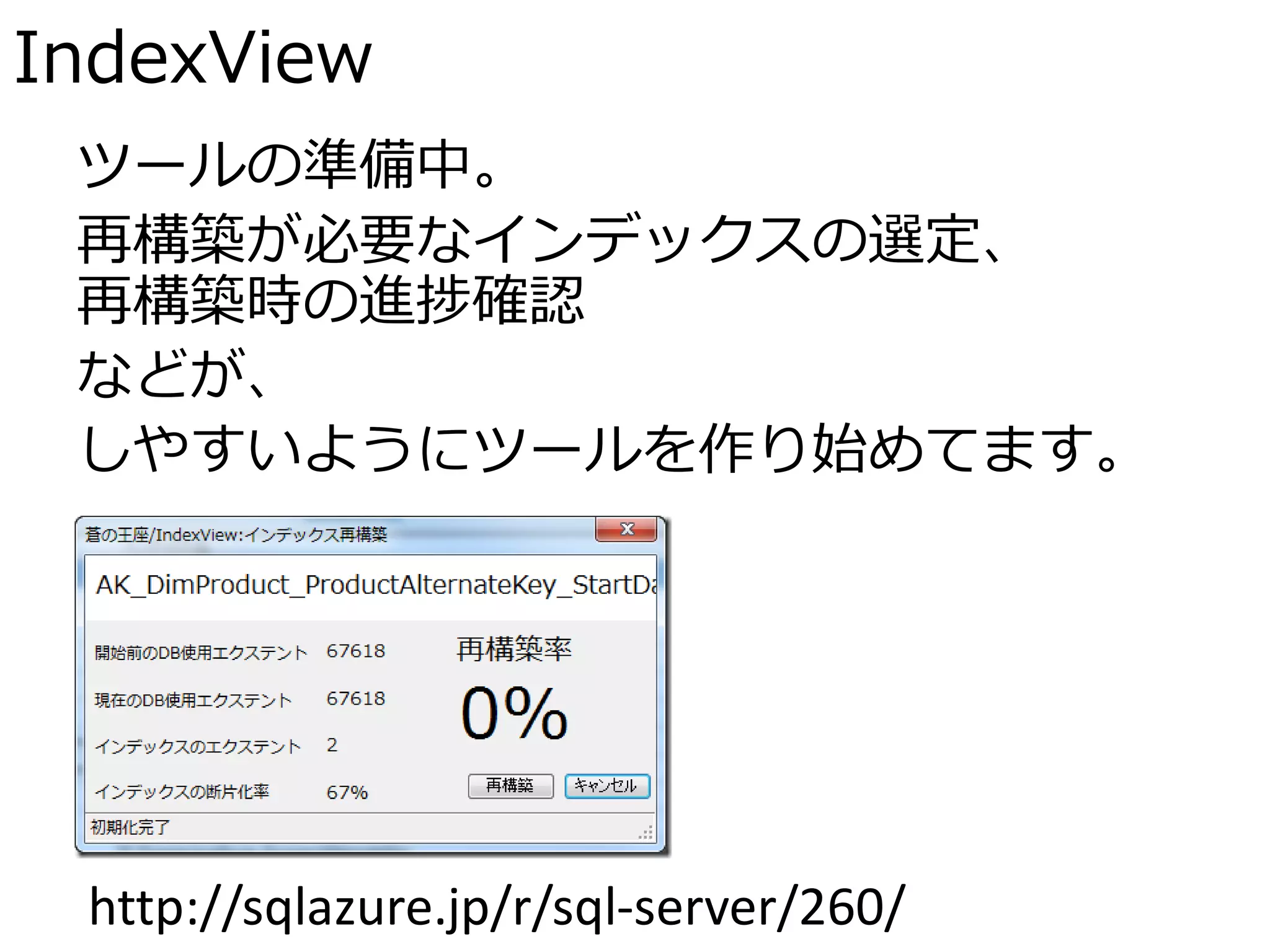
IndexView ツールの準備中。 再構築が必要なインデックスの選定、
再構築時の進捗確認 などが、 しやすいようにツールを作り始めてます。 http://sqlazure.jp/r/sql-server/260/
Download







































![[Citrix on Nutanix] LoginVSI による MCSとPVS の比較検証](https://cdn.slidesharecdn.com/ss_thumbnails/nutanixcitrixmcsorpvs-181205100326-thumbnail.jpg?width=640&height=640&fit=bounds)










![[A31]AWS上でOracleを利用するためのはじめの一歩!by Masatoshi Yoshida](https://cdn.slidesharecdn.com/ss_thumbnails/a31oracleyoshida-131122001746-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)











![[B31,32]SQL Server Internal と パフォーマンスチューニング by Yukio Kumazawa](https://cdn.slidesharecdn.com/ss_thumbnails/sqlserverinternalupload-140204185245-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)




![[db tech showcase Sapporo 2015] A26:SQL Server Data Page Structure Deep Dive ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtssapporo2015a26sqlserverozawamasayuki-150917043823-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)



![[C14] ソーシャル ゲーム基盤を支える SQL Server by Takashi Inaba](https://cdn.slidesharecdn.com/ss_thumbnails/c14sqlserver-131119194051-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

























