メモリのサイズが不足すると
メモリが不足するとデータ操作ができなくなる
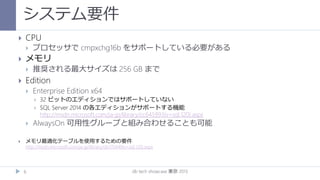
デフォルトでは max servermemory の 80% まで利用される
リソースガバナーを使用することで最大メモリを調整できる
以下は上限を 50% にするための設定
8
CREATE RESOURCE POOL Pool_Hekaton WITH (MAX_MEMORY_PERCENT = 50);
EXEC sp_xtp_bind_db_resource_pool 'TESTDB', 'Pool_Hekaton‘
EXEC sp_xtp_unbind_db_resource_pool 'TESTDB‘
How to: Bind a Database with Memory Optimized Tables to a Resource Pool
http://msdn.microsoft.com/ja-jp/library/dn465873(v=sql.120).aspx
db tech showcase 東京 2013
エラーのタイミング
INSERT
UPDATE
Session A
Session B
SessionA
Session B
BEGIN TRAN
BEGIN TRAN
BEGIN TRAN
BEGIN TRAN
UPDATE SET
WITH (SNAPSHOT)
UPDATE SET
WITH (SNAPSHOT)
COMMIT TRAN
Error
41302
3998
INSERT INTO
INSERT INTO
COMMIT TRAN
COMMIT TRAN
15
COMMIT TRAN
db tech showcase 東京 2013
Error
41325
ログの書き込みをタイミングを考慮すると…
SET NOCOUNT ON
GO
DECLARE@i bigint = 1)
WHILE (@i <= 100000)
BEGIN
INSERT INTO HekatonTable VALUES(@i, ‘AAAAA’)
SET @i += 1
END
SET NOCOUNT ON
GO
BEGIN TRAN
WHILE (@i <= 100000)
BEGIN
INSERT INTO HekatonTable VALUES(@i, ‘AAAAA’)
SET @i += 1
END
COMMIT TRAN
29
db tech showcase 東京 2013
30.
チェックポイントファイルの構造
データファイル
Max 128MB/file
256KB PageSize
Timestamp (INSERT)
Timestamp (INSERT)
Timestamp (INSERT)
Timestamp (INSERT)
Table ID
Table ID
Table ID
Table ID
デルタファイル
Write 4KB Page
Timestamp (INSERT)
Timestamp (INSERT)
Timestamp (INSERT)
Timestamp (INSERT)
Timestamp (DELETE)
Timestamp (DELETE)
Timestamp (DELETE)
Timestamp (DELETE)
チェックポイント
ファイルペア
Row ID
Row ID
Row ID
Row ID
Row Payload
Row Payload
Row Payload
Row Payload
Row ID
Row ID
Row ID
Row ID
sys.dm_db_xtp_checkpoint_files
複数のチェックポイントファイルはマージされることでファイルの最適化が行われる
通常は自動で実行されるが、手動で実行する場合は、sp_xtp_merge_checkpoint_files でファイルをマージ
30
db tech showcase 東京 2013
ネイティブコンパイルストアドプロシージャ
CREATE PROCEDURE dbo.usp_NativeSP_Persist
@param1int = 0
WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER
AS BEGIN ATOMIC WITH
(
TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'Japanese‘
-- 言語は sys.syslanguages から取得可能
)
DECLARE @i int = 1
WHILE (@i <= @param1)
BEGIN
INSERT INTO dbo.PersistTable VALUES(@i, RAND() * 1000, N‘dbts2013東京', N‘dbts2013)
SET @i += 1
END
END
GO
40
db tech showcase 東京 2013
参考資料 1/2
SQL Server2014 自習書シリーズ
http://www.microsoft.com/ja-jp/sqlserver/2014/technology/self-learning.aspx
Books Online
Blog
インメモリ OLTP (インメモリ最適化)
http://msdn.microsoft.com/ja-jp/library/dn133186(v=sql.120).aspx
In-Memory OLTP: High Availability for Databases with Memory-Optimized Tables
http://blogs.technet.com/b/dataplatforminsider/archive/2013/11/05/in-memory-oltp-high-availability-for-databases-with-memory-optimized-tables.aspx
The 411 on the Microsoft SQL Server 2014 In-Memory OLTP Blog Series
http://blogs.technet.com/b/dataplatforminsider/archive/2013/10/15/the-411-on-the-microsoft-sql-server-2014-in-memory-oltp-blog-series.aspx
SQL Server 2014 In-Memory Technologies: Blog Series Introduction
http://blogs.technet.com/b/dataplatforminsider/archive/2013/06/26/sql-server-2014-in-memory-technologies-blog-series-introduction.aspx
Getting Started with SQL Server 2014 In-Memory OLTP
http://blogs.technet.com/b/dataplatforminsider/archive/2013/06/26/getting-started-with-sql-server-2014-in-memory-oltp.aspx
Tech Ed
44
Microsoft SQL Server In-Memory OLTP: Overview of Project "Hekaton“
http://channel9.msdn.com/Events/TechEd/NorthAmerica/2013/DBI-B204
Microsoft SQL Server In-Memory OLTP Project "Hekaton": App Dev Deep Dive
http://channel9.msdn.com/Events/TechEd/NorthAmerica/2013/DBI-B307
Microsoft SQL Server In-Memory OLTP Project “Hekaton”: Management Deep Dive
http://channel9.msdn.com/Events/TechEd/NorthAmerica/2013/DBI-B308
db tech showcase 東京 2013
45.
参考資料 2/2
Sample Database
CaseStudy
SQL Server 2014 CTP2 In-Memory OLTP Sample, based
https://msftdbprodsamples.codeplex.com/releases/view/114491
bwin.party
http://www.microsoft.com/casestudies/Microsoft-SQL-Server-2014/bwin.party/Gaming-Site-Can-Scale-to-250-000-Requests-Per-Secondand-Improve-Player-Experience/710000003117
TPP
http://www.microsoft.com/casestudies/Microsoft-SQL-Server-2014/TPP/Clinical-Software-Easily-Supports-Thousands-of-New-Users-andHelps-Doctors-Save-Lives/710000003430
SBI Liquidity Market
http://www.microsoft.com/casestudies/Microsoft-SQL-Server-2014/SBI-Liquidity-Market/Leading-Japanese-Financial-Firm-AcceleratesTrading-Platform-with-In-Memory-OLTP/710000003429
White Paper
45
Main-Memory Databases
http://research.microsoft.com/en-us/projects/main-memory_dbs/
SQL Server In-Memory OLTP Internals Overview for CTP2
http://download.microsoft.com/download/5/F/8/5F8D223F-E08B-41CC-8CE5-95B79908A872/SQL_Server_2014_InMemory_OLTP_TDM_White_Paper.pdf
db tech showcase 東京 2013
















![ファイルグループの作成
ALTER DATABASE [Hekaton]
ADD FILEGROUP [HekatonFG]
CONTAINS MEMORY_OPTIMIZED_DATA
ALTER DATABASE [Hekaton]
ADD FILE ( NAME = N'Hekatn_FS', FILENAME =
N'F:¥Hekaton_FS¥Hekatn_FS' ) TO FILEGROUP
[HekatonFG]
19
db tech showcase 東京 2013](https://image.slidesharecdn.com/sqlserver2014inmemoryoltpoverview-140109164039-phpapp01/85/SQL-Server-2014-In-Memory-OLTP-Overview-19-320.jpg)



































![[D11] SQL Server エンジニアに知ってもらいたい!! SQL Server チューニングアプローチ by masayuki ozawa](https://cdn.slidesharecdn.com/ss_thumbnails/d11sqlserver-140623035219-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)


















![[B31,32]SQL Server Internal と パフォーマンスチューニング by Yukio Kumazawa](https://cdn.slidesharecdn.com/ss_thumbnails/sqlserverinternalupload-140204185245-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





![[D35] インメモリーデータベース徹底比較 by Komori](https://cdn.slidesharecdn.com/ss_thumbnails/d35hp-140623212142-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Sapporo 2015] B16:ビッグデータには、なぜ列指向が有効なのか? by 日本ヒューレット・パッカード株式...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtssapporo2015b16bigdataverticahewletpackard-150918014205-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)

![[C31]世界最速カラムナーDBは本物だ! by Daisuke Hirama](https://cdn.slidesharecdn.com/ss_thumbnails/c31hirama-131121192150-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

![[db tech showcase Tokyo 2014] L34: そのデータベース 5年後大丈夫ですか by 日本ヒューレット・パッカード株式会社 後藤宏](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014l34hp5-141120233511-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Sapporo 2015] A26:SQL Server Data Page Structure Deep Dive ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtssapporo2015a26sqlserverozawamasayuki-150917043823-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)




![[D24] あなたのビジネスを変えるInfiniDBケーススタディ by Toshihide Hanatani](https://cdn.slidesharecdn.com/ss_thumbnails/d24-140630203914-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

![[D23] SQL Server 2014 リリース記念!~Hekaton, カラムストアを試して、さらにギンギンに速くしてみました!~by Daisuk...](https://cdn.slidesharecdn.com/ss_thumbnails/d23iti-140624011401-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)



















