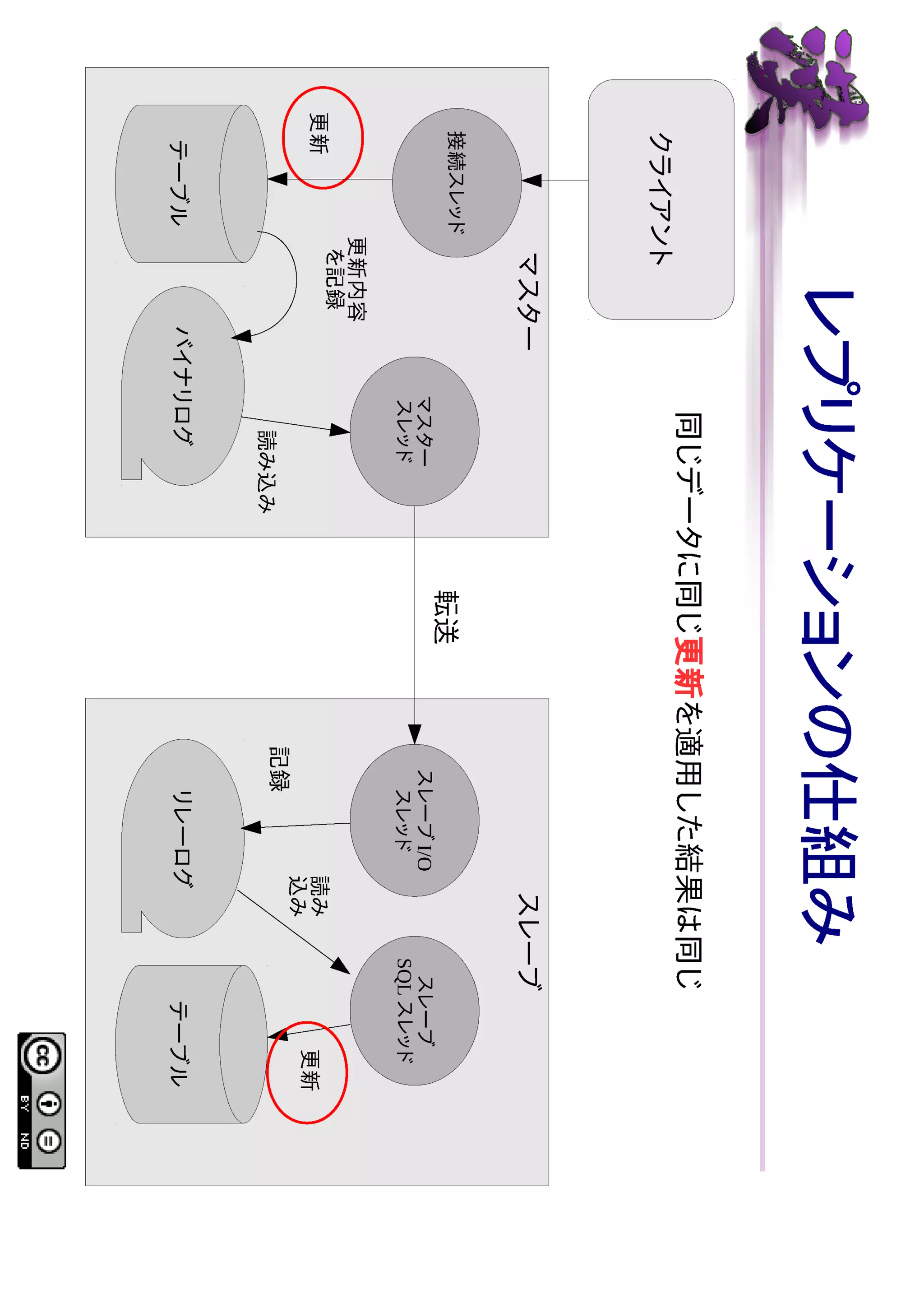
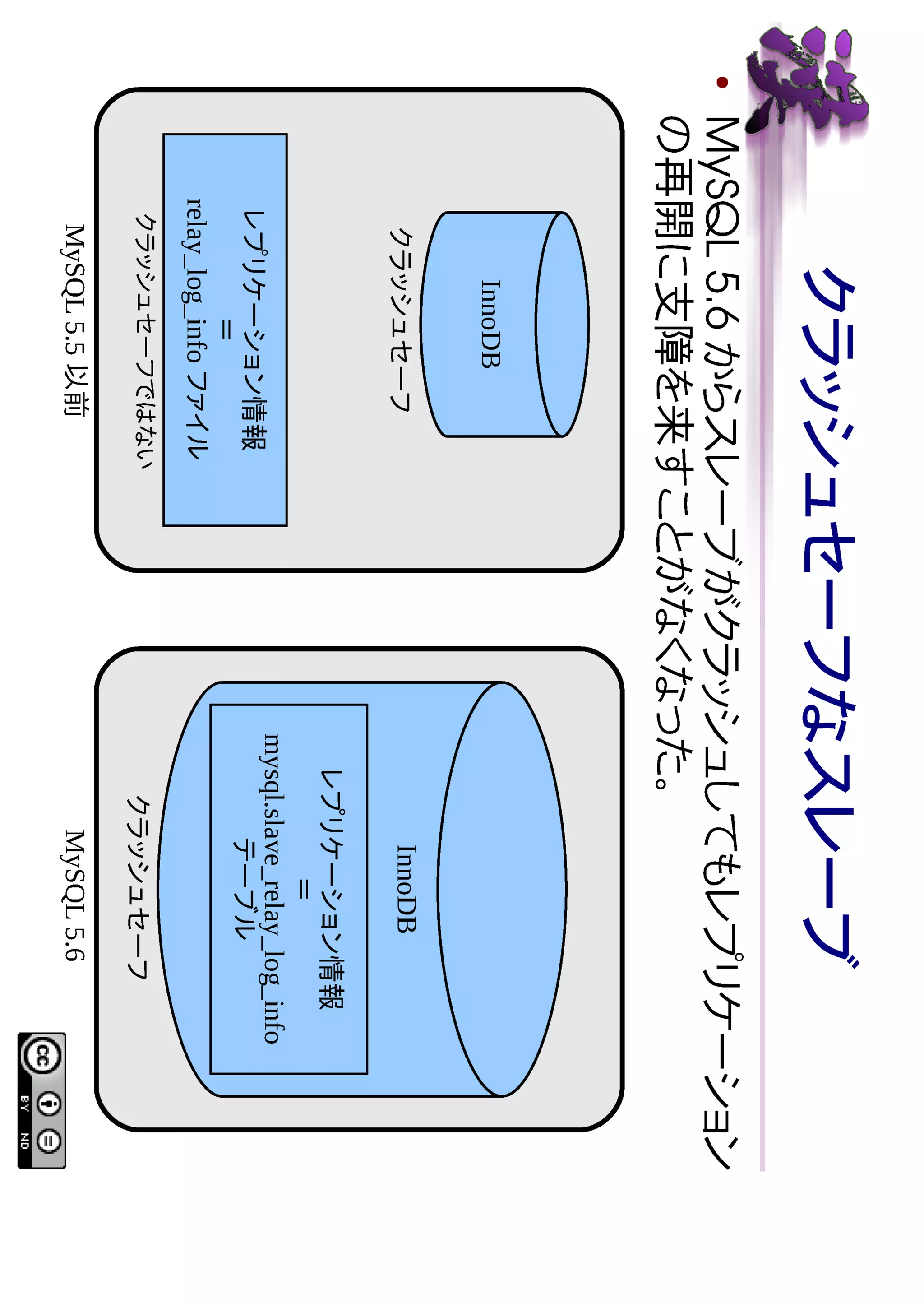
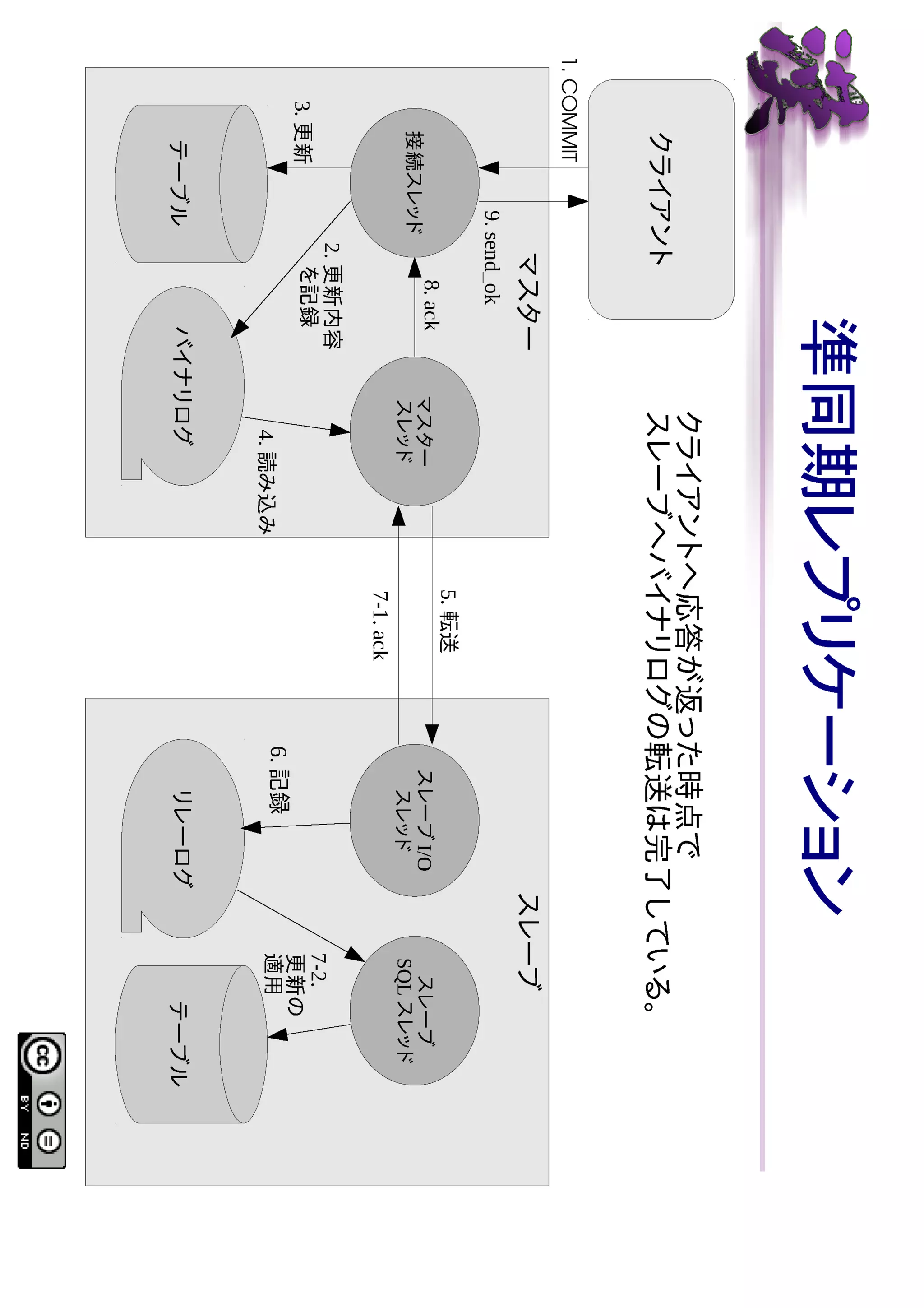
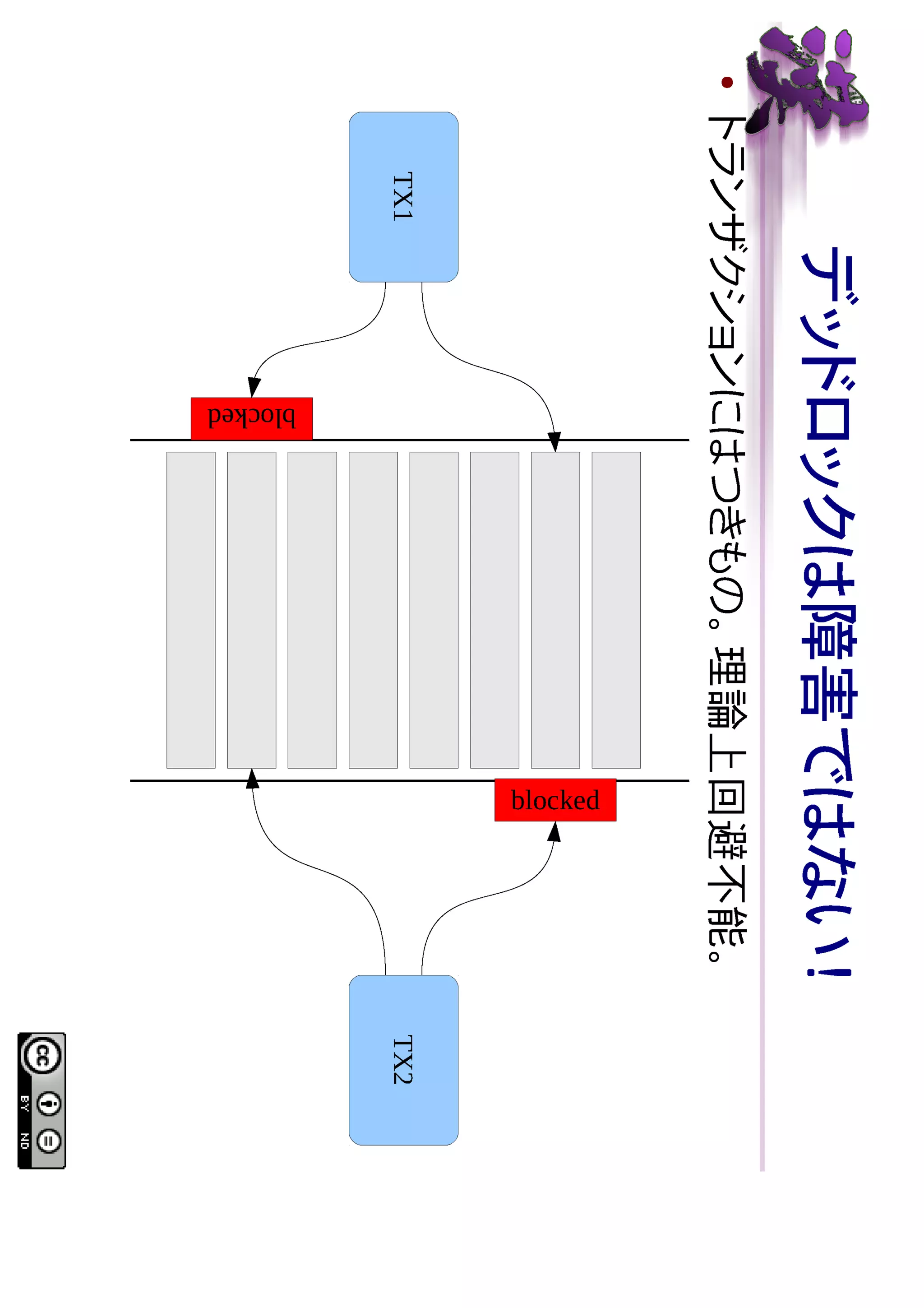
SHOW コマンド
●設定値
– SHOW GLOBAL VARIABLES
● 統計情報
– SHOW GLOBAL STATUS
● レプリケーション情報
– SHOW SLAVE STATUS
– SHOW MASTER STATUS
● InnoDB の情報
– SHOW ENGINE INNODB STATUS
●
● テーブル定義
– SHOW CREATE TABLE
etc...
56.
INFORMATION_SCHEMA
● SHOWコマンドをも凌駕する情報量
– バージョンを追うごとに内容が充実
– SHOW コマンドでは得られない情報多数
● SELECT でアクセス可能
– 必要な情報を得るため柔軟に絞り込みが可能
– JOIN 、サブクエリを利用可能
– GROUP BY による統計
– CASE 句による柔軟な出力
● よく使うSELECT にビューを定義可能
– 作業の効率化











![MySQL サーバー内の文字コード変換
テーブルセッションクライアント
MySQLサーバー
①送信する
SQL文に対する
文字コード
③クエリの
実行結果に対する
文字コード
②クエリの実行
に利用する
文字コード
④データを
蓄える際の
文字コード
⑤テーブル名や
カラム名に対する
文字コード
⑥ファイル名を
解決する際の
文字コード
ファイルシステム出展:エキスパートのための MySQL
[運用+管理]トラブルシューティングガイド](https://image.slidesharecdn.com/chugoku-db5-mysql-ts-140921173132-phpapp02/75/MySQL-12-2048.jpg)
![文字コードを確認する
● SHOW [GLOBAL] STATUS LIKE 'char%';
– character_set_client
– character_set_connection
– character_set_results
– character_set_server/character_set_database
– character_set_system
– character_set_filesystem
● アプリケーションから実行してみる
– ドライバの設定(接続プロパティ)に問題はないか](https://image.slidesharecdn.com/chugoku-db5-mysql-ts-140921173132-phpapp02/75/MySQL-13-2048.jpg)