Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Mikiya Okuno
PDF, PPTX
5,267 views
なぜ、いまリレーショナルモデルなのか
理論から学ぶデータベース実践入門 Nightで発表した資料です。
Software
◦
Read more
31
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 56
2
/ 56
3
/ 56
4
/ 56
5
/ 56
6
/ 56
7
/ 56
8
/ 56
9
/ 56
10
/ 56
11
/ 56
12
/ 56
13
/ 56
14
/ 56
15
/ 56
16
/ 56
17
/ 56
18
/ 56
19
/ 56
20
/ 56
21
/ 56
22
/ 56
23
/ 56
24
/ 56
25
/ 56
26
/ 56
27
/ 56
28
/ 56
29
/ 56
30
/ 56
31
/ 56
32
/ 56
33
/ 56
34
/ 56
35
/ 56
36
/ 56
37
/ 56
38
/ 56
39
/ 56
40
/ 56
41
/ 56
42
/ 56
43
/ 56
44
/ 56
45
/ 56
46
/ 56
47
/ 56
48
/ 56
49
/ 56
50
/ 56
51
/ 56
52
/ 56
53
/ 56
54
/ 56
55
/ 56
56
/ 56
More Related Content
PDF
なぜ、いま リレーショナルモデルなのか(理論から学ぶデータベース実践入門読書会スペシャル)
by
Mikiya Okuno
PDF
リレーショナルな正しいデータベース設計
by
Mikiya Okuno
PDF
ドメインロジックに集中せよ 〜ドメイン駆動設計 powered by Spring
by
増田 亨
PDF
AWS Black Belt Online Seminar - Amazon Lightsail
by
Amazon Web Services Japan
PDF
今こそ知りたい!Microsoft Azureの基礎
by
Trainocate Japan, Ltd.
PDF
JJUG CCC リクルートの Java に対する取り組み
by
Recruit Technologies
PDF
Virtual Machine Scale Sets 概要
by
Yui Ashikaga
PDF
【de:code 2020】 監視と管理を自動化するサンプル Center of Excellence Starter Kit 概説
by
日本マイクロソフト株式会社
なぜ、いま リレーショナルモデルなのか(理論から学ぶデータベース実践入門読書会スペシャル)
by
Mikiya Okuno
リレーショナルな正しいデータベース設計
by
Mikiya Okuno
ドメインロジックに集中せよ 〜ドメイン駆動設計 powered by Spring
by
増田 亨
AWS Black Belt Online Seminar - Amazon Lightsail
by
Amazon Web Services Japan
今こそ知りたい!Microsoft Azureの基礎
by
Trainocate Japan, Ltd.
JJUG CCC リクルートの Java に対する取り組み
by
Recruit Technologies
Virtual Machine Scale Sets 概要
by
Yui Ashikaga
【de:code 2020】 監視と管理を自動化するサンプル Center of Excellence Starter Kit 概説
by
日本マイクロソフト株式会社
What's hot
PDF
あなたが知らない リレーショナルモデル
by
Mikiya Okuno
PDF
イミュータブルデータモデル(世代編)
by
Yoshitaka Kawashima
PDF
chatGPTの驚くべき対話能力.pdf
by
YamashitaKatsushi
PPTX
明日からはじめられる Docker + さくらvpsを使った開発環境構築
by
MILI-LLC
PDF
日本語テストメソッドについて
by
kumake
PDF
20190828 AWS Black Belt Online Seminar Amazon Aurora with PostgreSQL Compatib...
by
Amazon Web Services Japan
PDF
実録Blue-Green Deployment導入記
by
Hiroyuki Ohnaka
PDF
AWS Black Belt Online Seminar 2016 AWS CloudFormation
by
Amazon Web Services Japan
PDF
ブラック企業から学ぶMVCモデル
by
Yuta Hiroto
PPTX
比較サイトの検索改善(SPA から SSR に変換)
by
gree_tech
PDF
データ仮想化を活用したデータ分析のフローと分析モデル作成の自動化のご紹介
by
Denodo
PDF
データファブリック実現のためのプロジェクトの進め方とは
by
Denodo
PPTX
エンタープライズRuby on Rails ~エンプラでぶち当たった2つの壁と突破法~
by
hiroki tanaka
PDF
もしOracleDBAがMySQLを管理することになったときの注意点など
by
Kentaro Kitagawa
PDF
Oracle WebLogic Server製品紹介資料(2020年/3月版)
by
オラクルエンジニア通信
PDF
今改めて学ぶ Microsoft Azure 基礎知識
by
Minoru Naito
PDF
Developers Summit 2023 9-D-1「もう悩まされない開発環境、プロジェクトで統一した環境をいつでもどこでも」
by
Kazumi OHIRA
PDF
Azure Network 概要
by
Takeshi Fukuhara
PDF
Azure App Service Overview
by
Takeshi Fukuhara
PDF
JavaでCPUを使い倒す! ~Java 9 以降の CPU 最適化を覗いてみる~(NTTデータ テクノロジーカンファレンス 2019 講演資料、2019...
by
NTT DATA Technology & Innovation
あなたが知らない リレーショナルモデル
by
Mikiya Okuno
イミュータブルデータモデル(世代編)
by
Yoshitaka Kawashima
chatGPTの驚くべき対話能力.pdf
by
YamashitaKatsushi
明日からはじめられる Docker + さくらvpsを使った開発環境構築
by
MILI-LLC
日本語テストメソッドについて
by
kumake
20190828 AWS Black Belt Online Seminar Amazon Aurora with PostgreSQL Compatib...
by
Amazon Web Services Japan
実録Blue-Green Deployment導入記
by
Hiroyuki Ohnaka
AWS Black Belt Online Seminar 2016 AWS CloudFormation
by
Amazon Web Services Japan
ブラック企業から学ぶMVCモデル
by
Yuta Hiroto
比較サイトの検索改善(SPA から SSR に変換)
by
gree_tech
データ仮想化を活用したデータ分析のフローと分析モデル作成の自動化のご紹介
by
Denodo
データファブリック実現のためのプロジェクトの進め方とは
by
Denodo
エンタープライズRuby on Rails ~エンプラでぶち当たった2つの壁と突破法~
by
hiroki tanaka
もしOracleDBAがMySQLを管理することになったときの注意点など
by
Kentaro Kitagawa
Oracle WebLogic Server製品紹介資料(2020年/3月版)
by
オラクルエンジニア通信
今改めて学ぶ Microsoft Azure 基礎知識
by
Minoru Naito
Developers Summit 2023 9-D-1「もう悩まされない開発環境、プロジェクトで統一した環境をいつでもどこでも」
by
Kazumi OHIRA
Azure Network 概要
by
Takeshi Fukuhara
Azure App Service Overview
by
Takeshi Fukuhara
JavaでCPUを使い倒す! ~Java 9 以降の CPU 最適化を覗いてみる~(NTTデータ テクノロジーカンファレンス 2019 講演資料、2019...
by
NTT DATA Technology & Innovation
Viewers also liked
PDF
データベース設計徹底指南
by
Mikiya Okuno
PDF
リレーショナルデータベースとの上手な付き合い方 long version
by
Mikiya Okuno
PPTX
理論から学ぶデータベース実践入門Night(mvccでちょっとハマった話)
by
Hironori Miura
PDF
NULLとの戦い RDBMS実装編
by
Meiji Kimura
PDF
Datalogからsqlへの トランスレータを書いた話
by
Yuki Takeichi
ODP
集合演算を真っ向から否定するアレの話
by
Kouhei Aoyagi
PPTX
ならば(その弐)
by
Tomoaki Hiramoto
データベース設計徹底指南
by
Mikiya Okuno
リレーショナルデータベースとの上手な付き合い方 long version
by
Mikiya Okuno
理論から学ぶデータベース実践入門Night(mvccでちょっとハマった話)
by
Hironori Miura
NULLとの戦い RDBMS実装編
by
Meiji Kimura
Datalogからsqlへの トランスレータを書いた話
by
Yuki Takeichi
集合演算を真っ向から否定するアレの話
by
Kouhei Aoyagi
ならば(その弐)
by
Tomoaki Hiramoto
Similar to なぜ、いまリレーショナルモデルなのか
PPTX
データベース入門
by
拓 小林
PPTX
SQLアンチパターン メンター用資料
by
Hironori Miura
PDF
リレーショナルデータベースとの上手な付き合い方
by
Mikiya Okuno
PDF
Database smells
by
Mikiya Okuno
PDF
「データベース実践入門」から学ぶリレーショナルモデル
by
Sota Sugiura
PPTX
ならば
by
Tomoaki Hiramoto
PDF
ハンドアウト(配布用資料:佐藤正美)
by
聡 鳥谷部
PDF
データモデルについて知っておくべき7つのこと 〜NoSQLに手を出す前に〜
by
Mikiya Okuno
PDF
データベース技術 4(Database_4)
by
Yuka Obu
PDF
Rdbms qpstudy-okuno
by
Mikiya Okuno
データベース入門
by
拓 小林
SQLアンチパターン メンター用資料
by
Hironori Miura
リレーショナルデータベースとの上手な付き合い方
by
Mikiya Okuno
Database smells
by
Mikiya Okuno
「データベース実践入門」から学ぶリレーショナルモデル
by
Sota Sugiura
ならば
by
Tomoaki Hiramoto
ハンドアウト(配布用資料:佐藤正美)
by
聡 鳥谷部
データモデルについて知っておくべき7つのこと 〜NoSQLに手を出す前に〜
by
Mikiya Okuno
データベース技術 4(Database_4)
by
Yuka Obu
Rdbms qpstudy-okuno
by
Mikiya Okuno
More from Mikiya Okuno
PDF
MySQLアーキテクチャ図解講座
by
Mikiya Okuno
PDF
RDBにおけるバリデーションをリレーショナルモデルから考える
by
Mikiya Okuno
PDF
What's New in MySQL 5.7 InnoDB
by
Mikiya Okuno
PDF
MySQL 5.7 トラブルシューティング 性能解析入門編
by
Mikiya Okuno
PDF
MySQLトラブル解析入門
by
Mikiya Okuno
PDF
MySQL日本語利用徹底入門
by
Mikiya Okuno
PDF
What's New in MySQL 5.7 Replication
by
Mikiya Okuno
PDF
What's New in MySQL 5.7 Optimizer @MySQL User Conference Tokyo 2015
by
Mikiya Okuno
PDF
私は如何にして詳解 MySQL 5.7を執筆するに至ったか
by
Mikiya Okuno
PDF
MySQL Cluster 7.4で楽しむスケールアウト @DB Tech Showcase 2015/06
by
Mikiya Okuno
PDF
MySQL Cluster 新機能解説 7.5 and beyond
by
Mikiya Okuno
PDF
とあるギークのキーボード遍歴
by
Mikiya Okuno
PDF
Mysql toranomaki
by
Mikiya Okuno
PDF
サポート一筋24+年のエンジニア、サポートのイロハは E4500に教わった。 Sun Microsystems 勉強会〜1994年頃から2000年頃の思い...
by
Mikiya Okuno
ODP
MySQl 5.6新機能解説@第一回 中国地方DB勉強会
by
Mikiya Okuno
PDF
MySQL 5.6新機能解説@dbtechshowcase2012
by
Mikiya Okuno
PDF
Database qpstudy-okuno
by
Mikiya Okuno
PDF
人類は如何にして大切な データベースを守るべきか
by
Mikiya Okuno
PDF
カジュアルにMySQL Clusterを使ってみよう@MySQL Cluster Casual Talks 2013.09
by
Mikiya Okuno
PDF
What's New in MySQL 5.7 Security
by
Mikiya Okuno
MySQLアーキテクチャ図解講座
by
Mikiya Okuno
RDBにおけるバリデーションをリレーショナルモデルから考える
by
Mikiya Okuno
What's New in MySQL 5.7 InnoDB
by
Mikiya Okuno
MySQL 5.7 トラブルシューティング 性能解析入門編
by
Mikiya Okuno
MySQLトラブル解析入門
by
Mikiya Okuno
MySQL日本語利用徹底入門
by
Mikiya Okuno
What's New in MySQL 5.7 Replication
by
Mikiya Okuno
What's New in MySQL 5.7 Optimizer @MySQL User Conference Tokyo 2015
by
Mikiya Okuno
私は如何にして詳解 MySQL 5.7を執筆するに至ったか
by
Mikiya Okuno
MySQL Cluster 7.4で楽しむスケールアウト @DB Tech Showcase 2015/06
by
Mikiya Okuno
MySQL Cluster 新機能解説 7.5 and beyond
by
Mikiya Okuno
とあるギークのキーボード遍歴
by
Mikiya Okuno
Mysql toranomaki
by
Mikiya Okuno
サポート一筋24+年のエンジニア、サポートのイロハは E4500に教わった。 Sun Microsystems 勉強会〜1994年頃から2000年頃の思い...
by
Mikiya Okuno
MySQl 5.6新機能解説@第一回 中国地方DB勉強会
by
Mikiya Okuno
MySQL 5.6新機能解説@dbtechshowcase2012
by
Mikiya Okuno
Database qpstudy-okuno
by
Mikiya Okuno
人類は如何にして大切な データベースを守るべきか
by
Mikiya Okuno
カジュアルにMySQL Clusterを使ってみよう@MySQL Cluster Casual Talks 2013.09
by
Mikiya Okuno
What's New in MySQL 5.7 Security
by
Mikiya Okuno
Recently uploaded
PPTX
JavaScript/TypeScript実力強化書 2章のアップデート Forkwell Library
by
Yoshiki Shibukawa
PDF
20251122_OWASPNagoya_takei_ITU-T,X.1060,security
by
OWASP Nagoya
PDF
N2WS Backup & Recovery と Veeam Backup for AWS
by
株式会社クライム
PDF
Gluesync:RDBMS、NoSQL,データレイク間のリアルタイム・データレプリケーション
by
株式会社クライム
PDF
Veeam&WasabiでトリプルV: クラウドへのランサムウエア対策の決定コンビ
by
株式会社クライム
PDF
最高峰のストレージとバックアップ:ARTESCA+Veeam:統合型ソフトウェア
by
株式会社クライム
JavaScript/TypeScript実力強化書 2章のアップデート Forkwell Library
by
Yoshiki Shibukawa
20251122_OWASPNagoya_takei_ITU-T,X.1060,security
by
OWASP Nagoya
N2WS Backup & Recovery と Veeam Backup for AWS
by
株式会社クライム
Gluesync:RDBMS、NoSQL,データレイク間のリアルタイム・データレプリケーション
by
株式会社クライム
Veeam&WasabiでトリプルV: クラウドへのランサムウエア対策の決定コンビ
by
株式会社クライム
最高峰のストレージとバックアップ:ARTESCA+Veeam:統合型ソフトウェア
by
株式会社クライム
なぜ、いまリレーショナルモデルなのか
1.
なぜ、いまなぜ、いま リレーショナルモデルリレーショナルモデル なのかなのか 奥野 幹也 Twitter: @nippondanji mikiya
(dot) okuno (at) gmail (dot) com @ 理論から学ぶデータベース 実践入門 Night
2.
免責事項 本プレゼンテーションにおいて示されている見解は、私 自身の見解であって、オラクル・コーポレーションの見 解を必ずしも反映したものではありません。ご了承くだ さい。
3.
自己紹介 ● MySQL サポートエンジニア – 日々のしごと ●
トラブルシューティング全般 ● Q&A 回答 ● パフォーマンスチューニング など ● ライフワーク – 自由なソフトウェアの普及 ● オープンソースではない ● GPL 万歳!! – 最近はまってる趣味はリカンベントに乗ること ● ブログ – 漢のコンピュータ道 – http://nippondanji.blogspot.com/
4.
なぜ、いま リレーショナルモデル なのか?
5.
リレーショナルモデルは枯れた理論 なのに何で今さら? ● 40 年以上前(!)から存在する理論 ● RDBMS
が主流とはいうけれども・・・ – 現代的な課題はスケーラビリティ!! – 勢力を拡大する NoSQL !! ● 理論の話なので実践よりまず座学 – エキサイティングな要素無し!! – 小難しい話ばかり!!
6.
巷に溢れるあやふやな情報 ● リレーショナルモデルに触れない SQL
の解説 – SQL は書けるようになるけれども・・・ ● 理論に基づかないノウハウの解説 – リレーションは 2 次元の表です – データベースは単なる入れ物です – 正規化の目的は冗長性の排除です – 正規形は第 3 までで OK です – すべてのテーブルにサロゲートキーをつけるべきです – ORM を使えば SQL は知らなくても良い etc etc
7.
そして、真実を知る者は 現場からいなくなった・・・ ● それでも世の中回ってる – 率直なところ「意外といけるもんだね・・・」という感想 ●
とはいえ効率は悪い – クエリの実行効率 – RDBMS を用いた開発効率 – 無駄三昧!!デスマーチ三昧!!
8.
どげんかせんと いかん・・・・・!!
9.
そこで、私はペンを取り 立ち上がった!!
10.
皆さんに本書で伝えたいこと ● リレーショナルモデルの重要性 ● リレーショナルモデルの本当の姿 ● リレーショナルモデルの使い方 ●
リレーショナルモデルの限界 ● リレーショナルモデル以外に必要な知識 ※ 入門書なのでさらなる勉強のとっっかかりにしてもらえると嬉しいです。偉 そうに本なんか出してますが、私も道半ばです。ともに道を歩んでいきましょ う!!入門なのに難しいとか間違いがあるという声をよく耳にしますが、私の 至らなさが原因です。すみません。 サポートページ⇒ http://gihyo.jp/book/2015/978-4-7741-7197-5/support
11.
リレーショナルモデルは道具 ● 道具には道具に合った使い方、使いみちがある ● 道具の性質や使い方を知らずして、使いみちは分からない – RDB
を使うべきかどうか – 使うとしたらどう使うのがベストなのか ● 世の中の間違った使い方を正したい
12.
データモデルとは!
13.
データモデルとは ● データの論理的な表現方法 – データを表現するためにどんな方法が使えるか ●
データを構成する要素 ● データに対する演算 – 物理じゃないよ!! ● 物理的な表現方法は、データがどのようなフォーマット でファイルに格納されているか等 ● データベース設計のことじゃないよ!!
14.
データモデル=データ設計? ● データモデルという言葉は二通りの意味で使われる – データの論理的な表現 –
データ設計 ● 意味は全く違う – 両者を混同すると意味不明!!
15.
データは格納するだけで 終わりではない ● 格納して終わりではない!! – アプリケーションから利用してこそ意味がある –
入れっぱなしで OK なら、そもそもデータを格納する意味 はあるのか? ● どのように出し入れするかが重要 – できるだけ簡単かつ的確に出し入れしたい – 必要なデータは何かを簡潔に定義できること – ≒ データに対する演算
16.
データモデルと演算 ● データモデル上に定義された演算 – データの意味から演算の種類が必然的に決まる ●
整数の四則演算、文字列の分解・連結 ● リレーショナルモデルの射影、制限、結合 etc – 処理系に最初から用意されている ● 高速で信頼できる操作 ● 用意された演算を適切に使えば簡素に書ける – 反例:文字列で配列を実装するケースを考えよ ● 遅い ● 実装できてもバグだらけ ● そもそも実装する意味がない
17.
データベースを単なる入れ物だと 考えてはいけない理由 ● データベースはデータモデルを意識して作られている – データモデルに沿った演算が用意されている ●
データモデルに沿った使い方が得意 ● そうでない処理は苦手 – データモデルを実践できるかどうかで、データベースのパ ワーを利用できるかどうかが決まる ● データベースが単なる入れ物だと考える背景 – 「自分で書けば何でもできる」という考え – データモデルを知らない
18.
プログラミングパラダイムと データモデル ● プログラミングパラダイム – 手続き型 –
オブジェクト指向 – 関数型 etc etc ● プログラミング言語にはそれぞれ適した書き方がある!! – Java はオブジェクト指向で使うべき ● main メソッドに全てのロジックを記述するべきではない ● データモデルにはそれぞれ適した DB 設計がある!! – 「データベースは単なるデータの入れ物だ」という考え 方は、 Java で main メソッドに全てを記述するのに等しい
19.
様々なデータモデル
20.
代表的なデータモデル ● リレーショナルモデル ● グラフ ● 階層型 ●
キーバリュー ● オブジェクト ● XML ● ドキュメント
21.
適切なデータモデルを選ぶ ● 双方向でマッチングする – そのデータモデルはどのような演算が得意か –
アプリケーションが必要とする演算は何か ● 最大公約数を取る – データモデルは万能ではない ● 演算がうまく表現できないものも存在する – データモデルに合致しない部分はアプリケーション側で作 りこむ ● データベースソフトウェアが備えている、データモデルか ら逸脱した演算を活用する – ソートやストアドプロシージャ、マテリアライズドビューなど
22.
一つのデータモデルでは 足りない場合 ● 複数の製品を組み合わせる – 異なるデータモデルを持つ製品を組み合わせる –
データの同期が課題 ● 分散トランザクションがあれば理想 ● トランザクションがない製品はキャッシュとして ● マルチモデル – ひとつの製品が複数のデータモデルを持つ ● RDB + JSON etc – データの同期について考える必要がない – スケーラビリティが課題
23.
リレーショナルモデル
24.
リレーショナルモデルとは! ● 集合に根ざしたデータモデル ● リレーションという名前のデータ構造を用いてデータを表現 する – リレーションを単位として様々な演算を行う ●
リレーション=集合 ● 集合演算+ α – リレーションはデータそのもの – テーブル同士の関係性(リレーションシップ)ではない
25.
リレーションとは ● 現実世界のある物事に対する事実の集合 テーブル ≒ リレーション
26.
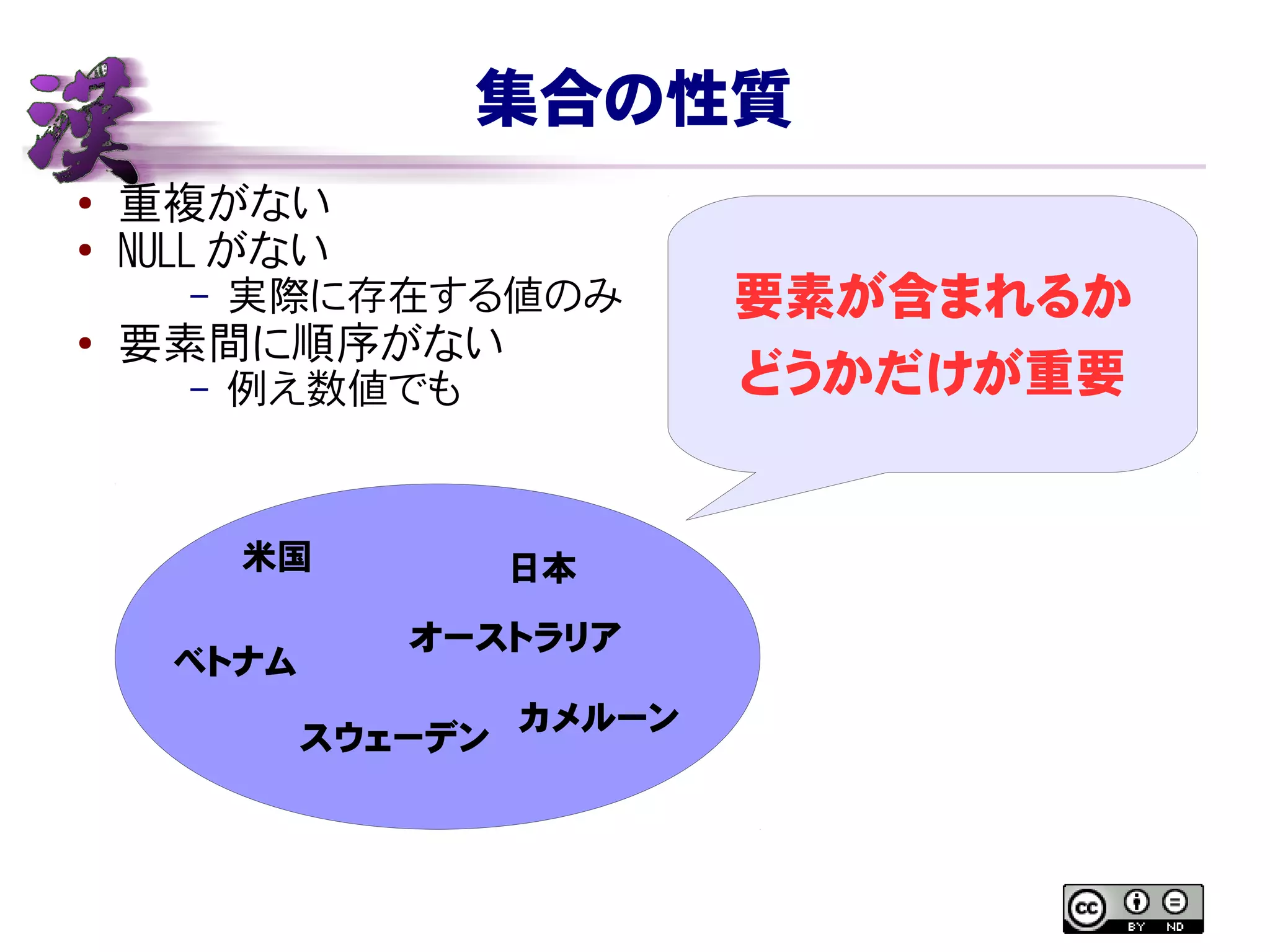
集合の性質 ● 重複がない ● NULL がない –
実際に存在する値のみ ● 要素間に順序がない – 例え数値でも 米国 ベトナム 日本 オーストラリア スウェーデン カメルーン 要素が含まれるか どうかだけが重要
27.
リレーションの構成部品 ● リレーション=見出し(ヘッダ)+本体(ボディ) ● 見出し(ヘッダ、 headding
) – 属性の集合 ● 属性(アトリビュート) – 名前と型(タイプ) ● 属性値 – 属性で定義された型を持つ値 – ≒ 列(カラム) ● 組(タプル) – 見出しに対応した属性値の集合 – ≒ 行(ロー) ● 本体(ボディ) – 組(タプル)の集合
28.
リレーショナルモデル≠ SQL リレーショナルモデル SQL 関係(リレーション)
表(テーブル) 属性 [ 値 ] (アトリビュート) 列(カラム) 組(タプル) 行(ロー) 対応する概念だが性質は異なる。
29.
つづきは本で・・・
30.
データモデルを知ることは超重要 ● データモデルを知らずにデータベースは使いこなせない ● データにはそれぞれの性質にあった演算がある – リレーションに対してしかリレーショナルモデルの演算は適 用できない!! –
リレーションとしてデータを表現することが重要 ● ただしリレーショナルモデルには適さないデータがある – リレーショナルモデルを適用すべきではない – 適するかどうかはリレーショナルモデルを知らずして判断 できない
31.
SQL と リレーショナルモデル
32.
SQL にあって リレーショナルモデルにないもの ● 行データの重複 ● 行データの順序 ●
カラムの順序 ● テーブル(リレーション)の更新 ● ストアドプロシージャ、トリガー ● トランザクション ● NULL
33.
なぜ SQL と リレーショナルモデルは違うのか ●
リレーショナルモデルには限界がある – 格納できるデータは集合として表現できるものに限る – 実行できる演算はリレーションの演算のみ ● 集合演算+ α ● アプリケーションが必要とするデータは多種多様 – リレーショナルモデルだけでは足りなかった – 更新という概念が実装上どうしても必要だった ● トランザクション ● つまり、純粋なリレーショナルモデルよりも SQL のほうが適用 範囲が広い
34.
ただしそれは 諸刃の剣だった・・・
35.
NULL の功罪 ● NULL
によって、 SQL はリレーショナルモデル以上の表現力を 手に入れた!! ● しかしその代償は大きかった・・・ – Unknown な値とは一体何なのか – 3 値論理による複雑さの上昇 – 閉世界仮設の崩壊 – オプティマイザも真価を発揮できない ● 今扱っているデータがリレーショナルモデルの範疇かどうか を見極めることが重要!! – NULL があってもいいかどうか
36.
データの正しさに ついての考察
37.
正しいデータを得られない データベースは無価値 ● 正しい答えが欲しいからデータベースを使う – デタラメな答えで良いのなら
/dev/urandom でも使ったほう がマシ ● 速いしリソース食わないし文句なし!! ● データの正しさとは一体何か?
38.
RDB 上でデータの正しさを保つ ● トランザクション –
同時アクセス時の整合性 – クラッシュリカバリ ● リレーショナルモデル – リレーション = 論理的に真となる命題の集合 ● 正規化理論 – 重複を排除することによる論理的な矛盾の回避 ● 制約 – ビジネスロジック
39.
NoSQL 上でデータの正しさを保つ ● RDB
のような便利な道具はない – トランザクションなし – リレーショナルモデルなし – 制約なし ● データの正しさの保証はアプリケーションに委ねられる – データの正しさを保証するためのコードを量産 – バグはデータの不整合に直結する – テストコードが増殖する
40.
分離レベルとデータの正しさ ● 分離レベルはトランザクションの概念であって、リレーショナ ルモデル上にはそんな概念はない – リレーショナルモデルでは、データは全てある瞬間のス ナップショットであり、同時アクセスによって他のセッション から変更されることは考慮されていない ● 分離レベルと整合性 –
SERIALIZABLE: リレーショナルモデルをもっとも忠実に体現 できる。ただしロック多し。 – REPEATABLE-READ: 少し時間が遅れても良いのなら、参照 系処理においてリレーショナルモデルを体現できる。ただ しファントムを除いて。 – READ-COMMITTED: 本当は使うのが難しいんだけど、みんな 分かって使ってるのか・・・ – READ-UNCOMMITTED: 一体何に使うのか。
41.
分離レベルの注意点 ● 製品によって違いがあるんだな、これが。 – 名称が違ったり、
4 つ以上のレベルがあったり – RR でファントムが出ない( SQL 標準上は出るのが正しいけ ど、実際にアプリを作る上ではこっちのほうが好ましい) – RC が読むのはどのデータ? – ロッキングリード vs ノンロッキングリード – RU は本当に性能が高いのか 各製品の実装に 詳しくなろう!
42.
リレーショナルモデルの 恩恵
43.
開発効率が上がる ● クエリの記述がシンプルになる – 単一のクエリで欲しいデータが得られる ●
ループ無し ● 分岐無し – クエリが宣言的に – 論理演算なので結果にゆるぎがない ● データを検査するコードが減る – スキーマがしっかり決まっている – 正規化によって重複が排除される ● 不整合なし!! – 便利な制約やトランザクション – データを検査するコードが減れば、テストも減る
44.
つまり、 デスマーチ回避!!
45.
クエリが効率的になる ● スパゲティクエリ撲滅!! – シンプルなクエリはインデックスが効きやすい –
1 回のクエリで必要なデータが取れる ● クライアント⇔サーバー間のトラフィック減 ● 更新のロジックがシンプルに – 正規化によってデータの所在がひとつに ● 論理的な矛盾をチェックする必要なし – チェックするコード不要=テスト減
46.
つまり、 RDB が真価を発揮!!
47.
デメリットは特に無い ● 道具を正しく使うことのデメリットは何だろう? ● リレーショナルモデルが適用できないデータ – 今扱っているデータがリレーショナルモデルと合わないの なら、リレーショナルモデルを使おうとすると徒労に終わる が、そういうケースはそもそも
RDB を使うべきではない – もともと RDB が必要な領域ではデメリットなし!!
48.
実装について意識する
49.
データモデルは論理的な表現 論理的な表現 = データモデル 物理的な表現
= 実装
50.
実装の例 ● データがテーブルスペースに格納される ● データは高速化のためにメモリ上にキャッシュされる ● インデックスによって高速にアクセスできる ●
オプティマイザが最適な実行計画を立てる ● データがパーティションに分かれている ● データが複数のノードにまたがって複製されている これらは実装であって データモデルではない!
51.
実装について知ることの意義 その1 ● 性能は超重要!! – データモデルを使って表現するだけでは片手落ち ●
満足な性能が出るとは限らない ● 性能が出ないアプリケーションは役に立たない!! – 実装を知り、仕事の量を見積もる ● それぞれの処理は十分に高速なのか ● どのリソースをどれだけ消費するか – I/O 処理 – メモリ – CPU ● アーキテクチャから推測する – ベンチマークするべし!! ● 机上の計算では全てはわからない
52.
実装について知ることの意義 その2 ● 想定通りの動作になるか – SQL
標準 ≠ 実装 ● 製品によって微妙に挙動が異なる ● SQL 標準から逸脱している場合もあり ● 実装を知っておくことは重要 – テスト重要 ● 想定通りになるかどうかは実行してみれば分かる
53.
実装と理論の混同 ダメ、ゼッタイ。 ● 実装はデータモデルの一部ではない ● 理論と実装は別々に考える – 論理データの設計はデータモデルに沿って行う –
データモデルの要求を満たせるように実装を考える ● すなわち、設計する順序は論理設計>物理設計
54.
まとめ
55.
結論:なぜ、今 リレーショナルモデルなのか ● リレーショナルモデルは古くからある技術 – エキサイティングな要素は・・・ない!! –
実践できていないのに現場では蔑ろに – 巷にあふれるあやふやな情報 ● リレーショナルモデルを知ろう – 道具を使うには、使い方を理解する必要がある – 使い方を知ることで、正しい用途も見えてくる – 続きは本で ● リレーショナルモデルは変わらない!! – 流行り・廃りで理論が変わるわけではない – 代替の理論なし。今後も世の中には必要!!
56.
Q&Aご静聴ありがとうございました。
Download



























![リレーショナルモデル≠ SQL
リレーショナルモデル SQL
関係(リレーション) 表(テーブル)
属性 [ 値 ] (アトリビュート) 列(カラム)
組(タプル) 行(ロー)
対応する概念だが性質は異なる。](https://image.slidesharecdn.com/why-relational-model-now-151008102312-lva1-app6892/75/slide-28-2048.jpg)