Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Mikiya Okuno
18,780 views
リレーショナルデータベースとの上手な付き合い方
まべ☆てっく Vol.1にて発表したスライドです。リレーショナルデータベースをどのように使うべきか、あるいはそもそも何故データベースを使うべきなのかといったことについて解説しています。
Software
◦
Read more
9
Save
Share
Embed
Embed presentation
Download
Downloaded 26 times
1
/ 39
2
/ 39
3
/ 39
4
/ 39
5
/ 39
6
/ 39
7
/ 39
8
/ 39
9
/ 39
10
/ 39
11
/ 39
12
/ 39
13
/ 39
14
/ 39
15
/ 39
16
/ 39
17
/ 39
18
/ 39
19
/ 39
20
/ 39
21
/ 39
22
/ 39
23
/ 39
24
/ 39
25
/ 39
26
/ 39
27
/ 39
28
/ 39
29
/ 39
30
/ 39
31
/ 39
32
/ 39
33
/ 39
34
/ 39
35
/ 39
36
/ 39
37
/ 39
38
/ 39
39
/ 39
More Related Content
PDF
リレーショナルデータベースとの上手な付き合い方 long version
by
Mikiya Okuno
PDF
私は如何にして詳解 MySQL 5.7を執筆するに至ったか
by
Mikiya Okuno
PDF
MySQLアーキテクチャ図解講座
by
Mikiya Okuno
PDF
データモデルについて知っておくべき7つのこと 〜NoSQLに手を出す前に〜
by
Mikiya Okuno
PDF
とあるギークのキーボード遍歴
by
Mikiya Okuno
PDF
RDBにおけるバリデーションをリレーショナルモデルから考える
by
Mikiya Okuno
PDF
なぜ、いま リレーショナルモデルなのか(理論から学ぶデータベース実践入門読書会スペシャル)
by
Mikiya Okuno
PDF
人類は如何にして大切な データベースを守るべきか
by
Mikiya Okuno
リレーショナルデータベースとの上手な付き合い方 long version
by
Mikiya Okuno
私は如何にして詳解 MySQL 5.7を執筆するに至ったか
by
Mikiya Okuno
MySQLアーキテクチャ図解講座
by
Mikiya Okuno
データモデルについて知っておくべき7つのこと 〜NoSQLに手を出す前に〜
by
Mikiya Okuno
とあるギークのキーボード遍歴
by
Mikiya Okuno
RDBにおけるバリデーションをリレーショナルモデルから考える
by
Mikiya Okuno
なぜ、いま リレーショナルモデルなのか(理論から学ぶデータベース実践入門読書会スペシャル)
by
Mikiya Okuno
人類は如何にして大切な データベースを守るべきか
by
Mikiya Okuno
What's hot
PDF
Database qpstudy-okuno
by
Mikiya Okuno
PDF
Database smells
by
Mikiya Okuno
PDF
What's New in MySQL 5.7 Replication
by
Mikiya Okuno
PDF
ActiveRecord::Enumのススメ
by
豊明 尾古
PDF
なぜ、いまリレーショナルモデルなのか
by
Mikiya Okuno
PDF
便利なHerokuと active recordの 速度改善tips
by
豊明 尾古
PPTX
pythonで始める筋トレ(競技プログラミング)
by
shunki fujiwara
PPT
Pythonで始める競技プログラミング
by
shunki fujiwara
PDF
PHPマニュアルの育て方
by
Masahiro Takagi
PPTX
20151205 中国地方db勉強会 dbm_fs
by
Takahiro Iwase
PDF
だれも教えてくれないJavaの世界。 あと、ぼくが会社員になったわけ。
by
なおき きしだ
PDF
JavaFXとRoboVMを使ってiOS上で動くアプリを試してみた
by
Satoshi Takami
PDF
そろそろJavaみなおしてもええんやで
by
なおき きしだ
PDF
2013 08-19 jjug
by
sk44_
PDF
あと一つプログラミング言語を 覚えたら死ぬ! 脳みそがパンクしそうな あなたのための nodeJSことはじめ
by
文樹 高橋
PDF
プロト〜サービスアウトまでの開発支援ツールの作り方〜CrystalFantasia〜
by
Keisuke Utsumi
PDF
MF GeeksNight pplogの話
by
Naoto Koshikawa
PDF
eZ Publish 2012年4月勉強会 - eZ Publish設計ベストプラクティス
by
ericsagnes
KEY
おーいみんな、JavaやろうぜJava
by
Kazumune Katagiri
PDF
入社1年目のプログラミング初心者がSpringを学ぶための手引き
by
土岐 孝平
Database qpstudy-okuno
by
Mikiya Okuno
Database smells
by
Mikiya Okuno
What's New in MySQL 5.7 Replication
by
Mikiya Okuno
ActiveRecord::Enumのススメ
by
豊明 尾古
なぜ、いまリレーショナルモデルなのか
by
Mikiya Okuno
便利なHerokuと active recordの 速度改善tips
by
豊明 尾古
pythonで始める筋トレ(競技プログラミング)
by
shunki fujiwara
Pythonで始める競技プログラミング
by
shunki fujiwara
PHPマニュアルの育て方
by
Masahiro Takagi
20151205 中国地方db勉強会 dbm_fs
by
Takahiro Iwase
だれも教えてくれないJavaの世界。 あと、ぼくが会社員になったわけ。
by
なおき きしだ
JavaFXとRoboVMを使ってiOS上で動くアプリを試してみた
by
Satoshi Takami
そろそろJavaみなおしてもええんやで
by
なおき きしだ
2013 08-19 jjug
by
sk44_
あと一つプログラミング言語を 覚えたら死ぬ! 脳みそがパンクしそうな あなたのための nodeJSことはじめ
by
文樹 高橋
プロト〜サービスアウトまでの開発支援ツールの作り方〜CrystalFantasia〜
by
Keisuke Utsumi
MF GeeksNight pplogの話
by
Naoto Koshikawa
eZ Publish 2012年4月勉強会 - eZ Publish設計ベストプラクティス
by
ericsagnes
おーいみんな、JavaやろうぜJava
by
Kazumune Katagiri
入社1年目のプログラミング初心者がSpringを学ぶための手引き
by
土岐 孝平
Similar to リレーショナルデータベースとの上手な付き合い方
PDF
経済学のための実践的データ分析 4.SQL ことはじめ
by
Yasushi Hara
PDF
データベースの使いどころ_「データ管理?Excelでよくね!」に選択肢を。データ管理をする際のデータベースとExcelの根本的な違いについて。
by
kobamasahighhigh
PDF
Japan.r 2データベース
by
sleipnir002
PPTX
データベース入門
by
拓 小林
PDF
20200629 データベース基礎~データベースの扱いとデータ設計~
by
Hikaru Tanaka
PDF
TAM 新人ディレクター システムスキルアップ プログラム 第6回 「データベース」
by
(株)TAM
PDF
データベース技術 1(Database_1)
by
Yuka Obu
PDF
mysql casual #4
by
kenji naito
PDF
InnoDBのすゝめ(仮)
by
Takanori Sejima
PDF
データベースシステム論02 - データベースの歴史と今
by
Shohei Yokoyama
PPT
今年こそ始めたい!SQL超入門 セミナー資料 2024年5月22日 富士通クラウドミートアップ
by
Toru Miyahara
PPT
今年こそ始めたい!SQL超入門 MIRACLE Linux Meetup版 0620
by
Toru Miyahara
PDF
データベース09 - データベース設計
by
Kenta Oku
PDF
Nosql
by
uenno
PPTX
2024年度_サイバーエージェント_新卒研修「データベースの歴史」.pptx
by
yassun7010
PDF
リレーショナルな正しいデータベース設計
by
Mikiya Okuno
PPTX
第4回 データベース
by
Sawada Makoto
PDF
あなたが知らない リレーショナルモデル
by
Mikiya Okuno
PDF
データベース技術について
by
yuu1988
PDF
Sql基礎の基礎
by
Satomi Tsujita
経済学のための実践的データ分析 4.SQL ことはじめ
by
Yasushi Hara
データベースの使いどころ_「データ管理?Excelでよくね!」に選択肢を。データ管理をする際のデータベースとExcelの根本的な違いについて。
by
kobamasahighhigh
Japan.r 2データベース
by
sleipnir002
データベース入門
by
拓 小林
20200629 データベース基礎~データベースの扱いとデータ設計~
by
Hikaru Tanaka
TAM 新人ディレクター システムスキルアップ プログラム 第6回 「データベース」
by
(株)TAM
データベース技術 1(Database_1)
by
Yuka Obu
mysql casual #4
by
kenji naito
InnoDBのすゝめ(仮)
by
Takanori Sejima
データベースシステム論02 - データベースの歴史と今
by
Shohei Yokoyama
今年こそ始めたい!SQL超入門 セミナー資料 2024年5月22日 富士通クラウドミートアップ
by
Toru Miyahara
今年こそ始めたい!SQL超入門 MIRACLE Linux Meetup版 0620
by
Toru Miyahara
データベース09 - データベース設計
by
Kenta Oku
Nosql
by
uenno
2024年度_サイバーエージェント_新卒研修「データベースの歴史」.pptx
by
yassun7010
リレーショナルな正しいデータベース設計
by
Mikiya Okuno
第4回 データベース
by
Sawada Makoto
あなたが知らない リレーショナルモデル
by
Mikiya Okuno
データベース技術について
by
yuu1988
Sql基礎の基礎
by
Satomi Tsujita
More from Mikiya Okuno
PDF
サポート一筋24+年のエンジニア、サポートのイロハは E4500に教わった。 Sun Microsystems 勉強会〜1994年頃から2000年頃の思い...
by
Mikiya Okuno
PDF
MySQL Cluster 新機能解説 7.5 and beyond
by
Mikiya Okuno
PDF
MySQL 5.7 トラブルシューティング 性能解析入門編
by
Mikiya Okuno
PDF
What's New in MySQL 5.7 Security
by
Mikiya Okuno
PDF
What's New in MySQL 5.7 InnoDB
by
Mikiya Okuno
PDF
What's New in MySQL 5.7 Optimizer @MySQL User Conference Tokyo 2015
by
Mikiya Okuno
PDF
MySQL Cluster 7.4で楽しむスケールアウト @DB Tech Showcase 2015/06
by
Mikiya Okuno
PDF
MySQLトラブル解析入門
by
Mikiya Okuno
PDF
データベース設計徹底指南
by
Mikiya Okuno
PDF
Mysql toranomaki
by
Mikiya Okuno
PDF
カジュアルにMySQL Clusterを使ってみよう@MySQL Cluster Casual Talks 2013.09
by
Mikiya Okuno
ODP
MySQl 5.6新機能解説@第一回 中国地方DB勉強会
by
Mikiya Okuno
PDF
Rdbms qpstudy-okuno
by
Mikiya Okuno
PDF
MySQL 5.6新機能解説@dbtechshowcase2012
by
Mikiya Okuno
PDF
MySQL日本語利用徹底入門
by
Mikiya Okuno
ODP
Performance Schema @ MySQL Casual #2
by
Mikiya Okuno
サポート一筋24+年のエンジニア、サポートのイロハは E4500に教わった。 Sun Microsystems 勉強会〜1994年頃から2000年頃の思い...
by
Mikiya Okuno
MySQL Cluster 新機能解説 7.5 and beyond
by
Mikiya Okuno
MySQL 5.7 トラブルシューティング 性能解析入門編
by
Mikiya Okuno
What's New in MySQL 5.7 Security
by
Mikiya Okuno
What's New in MySQL 5.7 InnoDB
by
Mikiya Okuno
What's New in MySQL 5.7 Optimizer @MySQL User Conference Tokyo 2015
by
Mikiya Okuno
MySQL Cluster 7.4で楽しむスケールアウト @DB Tech Showcase 2015/06
by
Mikiya Okuno
MySQLトラブル解析入門
by
Mikiya Okuno
データベース設計徹底指南
by
Mikiya Okuno
Mysql toranomaki
by
Mikiya Okuno
カジュアルにMySQL Clusterを使ってみよう@MySQL Cluster Casual Talks 2013.09
by
Mikiya Okuno
MySQl 5.6新機能解説@第一回 中国地方DB勉強会
by
Mikiya Okuno
Rdbms qpstudy-okuno
by
Mikiya Okuno
MySQL 5.6新機能解説@dbtechshowcase2012
by
Mikiya Okuno
MySQL日本語利用徹底入門
by
Mikiya Okuno
Performance Schema @ MySQL Casual #2
by
Mikiya Okuno
リレーショナルデータベースとの上手な付き合い方
1.
リレーショナルリレーショナル データベースデータベースとのとの 上手な付き合い方上手な付き合い方 奥野 幹也 Twitter: @nippondanji mikiya
(dot) okuno (at) gmail (dot) com @ まべ☆てっく vol.1
2.
免責事項 本プレゼンテーションにおいて示されている見解は、私 自身の見解であって、オラクル・コーポレーションの見 解を必ずしも反映したものではありません。ご了承くだ さい。
3.
自己紹介 ● MySQL サポートエンジニア – 日々のしごと ●
トラブルシューティング全般 ● Q&A 回答 ● パフォーマンスチューニング など ● ライフワーク – 自由なソフトウェアの普及 ● オープンソースではない ● GPL 万歳!! – 最近はまってる趣味はリカンベントに乗ること ● ブログ – 漢のコンピュータ道 – http://nippondanji.blogspot.com/
4.
なぜデータベースを 使うべきか
5.
一言で表すと・・・ 開発や運用で 楽をするため!!
6.
データに対する要求 ● 整理して格納しておきたい – データを構造化してどこに何があるか分かるようにしたい –
データに合った構造を選択 ● 好きなときに取り出したい – 容易にアクセスできる手段 – 正しい結果が欲しい!! ● 自由自在に更新したい – データの整合性を保ちたい – 複数のユーザーから同時に更新したい
7.
ファイルではダメなのか ● 構造が一切定義されていない – データの位置を先頭からのオフセットとしてバイト数で指 定 –
データは単なるバイト列 ● seek や read/write といった低レベルの API のみ – 複雑なアプリケーションによるデータ操作を表現するには 貧弱過ぎる – 高度なデータ操作はアプリケーション側で実装しなけれ ばならない – 壮大なる車輪の再発明の危険性 ● 同時アクセス時の排他制御 ● マシンクラッシュにおけるデータの完全性
8.
表計算ソフトではダメなのか ● 表計算ソフトはあくまでも二次元の表 – データの場所を列と行で指定 –
表同士の演算はできない ● JOIN 、 UNION 等 ● インデックスによる高速な検索や演算ができない ● 同時アクセスができない ● トランザクションがない
9.
データベースは便利な道具 ● 小難しいけれどもただの厄介者ではない。 – リレーショナルモデル –
トランザクション ● データ管理や操作における課題を解決するためのもの – データを矛盾なく格納したい – 安全に並列処理を行いたい – クラッシュしてもデータが失われないようにしたい
10.
トランザクションは なぜ必要か
11.
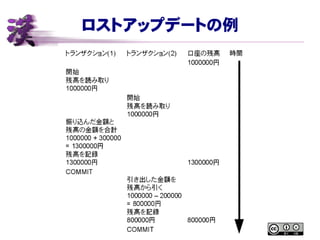
同時アクセスによる様々な異常 ● ロストアップデート ● インコンシステントリード ● ダーティーリード ●
ノンリピータブルリード ● ファントムリード トランザクションで 防げる!!
12.
ロストアップデートの例
13.
データの正しさを保証したい!! ● それがトランザクションの役割 – しかも超かんたん!! ●
トランザクションによってできること – 同時アクセスによる異常を防ぐ – システムがクラッシュしてもデータが失われない
14.
正しい結果 ● 並列で実行しているトランザクションが、ひとつずつ順番に 実行した場合と同じ結果になること。 – トランザクションの順序に保証はない。数ある順序の組み 合わせの中のひとつと同じになる。 –
アプリ側で排他制御を考えなくていい。 Tx1 Tx2 Tx3 = Tx2 Tx1 Tx3
15.
ACID ● トランザクションが満たすべき性質 – 原子性 ●
トランザクションに含まれる操作全てが成功 ( Commit )か失敗( Abort )になるという性質 – 一貫性 ● トランザクションを実行した前後ではデータの一貫性が 損なわれてはならないという性質 – 分離性(独立性) ● 同時に実行している複数のトランザクションが、互いに影 響を与えないという性質 – 永続性 ● いったんコミットが完了したトランザクションが消失しない という性質
16.
トランザクションがない場合に 起きること ● 排他制御が不在 – 同時に同じデータへアクセスする場合、更新異常を防ぐ にはどうする? –
アプリケーション側で大量のロックを記述する? ● トランザクションがあれば、分離性があるので勝手に やってくれる。 ● エラー処理が超複雑に – どこまで処理が進んだかによってエラー処理も場合分け ● 10 の更新から成るトランザクションは、 10 のケースにつ いてエラー処理が必要。 – トランザクションがあれば原始性があるので、処理が中 断するとすべての更新をロールバック。 – クラッシュ後のデータは正しいか? ● そもそもどうやって確かめる? – トランザクションの永続性があれば COMMIT したデータが 存在することが保証される。
17.
ACID の C ●
一貫性って何? ● トランザクション理論自体は一貫性を規定しない – 一貫性を定義するのはアプリケーションの役目 – 制約などを使う ● 制約という仕組みを使って一貫性を記述するのはアプリ ケーション
18.
つまりトランザクションを使うと・・・ 開発や運用が 楽!!
19.
リレーショナルモデル はなぜ必要か
20.
リレーショナルモデルがない世界 ● データモデルの不在 – データモデルはデータ取得のための演算を定義 ●
効率よくコンパクトにデータの問い合わせを記述できる – データの演算をアプリケーションで自前で記述する? ● データベースはただの入れ物という考え ● 実際そういう現場が多いからデスマーチに・・・ ● 正規化理論の不在 – 正規化理論は、更新によって生じるデータの矛盾を、 データベース設計そのものにより防ぐ理論。 ● ACID の C – データの矛盾をアプリケーションで自前で記述する? ● チェックのための処理が大量に必要に・・・
21.
そもそも データモデルとは
22.
データモデルとは ● データの論理的な表現方法 – データを表現するためにどんな方法が使えるか ●
データを構成する要素 ● データに対する演算 – 物理じゃないよ!! ● 物理的な表現方法は、データがどのようなレイアウトで ファイルに格納されているか等 ● データベース設計のことじゃないよ!!
23.
データは格納するだけで 終わりではない ● 格納して終わりではない!! – アプリケーションから利用してこそ意味がある –
入れっぱなしで OK なら、そもそもデータを格納する意味 はあるのか? ● どのように出し入れするかが重要 – できるだけ簡単かつ的確に出し入れしたい – 必要なデータは何かを簡潔に定義できること – ≒ データに対する演算
24.
データモデルと演算 ● データモデル上に定義された演算 – データの意味から演算の種類が必然的に決まる ●
整数の四則演算、文字列の分解・連結 ● リレーショナルモデルの射影、制限、結合 etc – 処理系に最初から用意されている ● 高速で信頼できる操作 ● 用意された演算を適切に使えば簡素に書ける – 反例:文字列で配列を実装するケースを考えよ ● 遅い ● 実装できてもバグだらけ ● そもそも実装する意味がない
25.
プログラミングパラダイムと データモデル ● プログラミングパラダイム – 手続き型 –
オブジェクト指向 – 関数型 etc etc ● プログラミング言語にはそれぞれ適した書き方がある!! – Java はオブジェクト指向で使うべき ● main メソッドに全てのロジックを記述するべきではない ● データモデルにはそれぞれ適した DB 設計がある!! – 「データベースは単なるデータの入れ物だ」という考え 方は、 Java で main メソッドに全てを記述するのに等し い
26.
つまりリレーショナルモデルを 使うと・・・ 開発やメンテが 楽!!
27.
リレーショナルモデルを マスターしたい方へ・・・
28.
パフォーマンス パフォーマンス パフォーマンス パフォーマンス パフォーマンス パフォーマンス
29.
パフォーマンスは超重要 ● データモデルに沿って DB を設計するだけでは片手落ち –
満足な性能が出るとは限らない ● 何を表現したかということと、その表現がどのように処理 されるかは別 ● 性能が出ないアプリケーションは役に立たない!! – アプリケーションは実用的であってこそ意味がある – 実用的なレスポンスが得られることは絶対条件
30.
性能を向上させるためのポイント ● 己を知る – 利用可能な機能を知る –
製品の実装を知る ● どんな処理が得意なのか ● 敵を知る – 遅いクエリを特定する ● クエリの仕事量を測定する ● 仕事量を減らすようチューニング – ボトルネックを特定する ● 時間が掛かっている箇所 ● アクセスが集中している箇所 彼を知り己を知れば百戦殆うからず (孫子)
31.
データがどのように アクセスされるかを知る ● 行データがどのようにクライアントへ届くか – オプティマイザー –
インデックス – I/O – バッファプール – ネットワーク – それぞれの処理の仕事量は? ● それぞれの時点での改善点はないか – 実行計画は適切か? – もっと良いインデックスはないか? – I/O の効率は改善できるか? – より速いディスクが必要か? – バッファプールその他のキャッシュは十分か? – ネットワーク帯域は十分か? – ボトルネックはどこか?
32.
クエリの改善 ● 不必要なデータにアクセスしていないか – 不要な結果をクライアントへ送信していないか ●
アプリケーション側で結果を絞り込む等 – 効率の悪い書き方をしていないか ● RDBMS の機能を活用する – より効率的な実行計画のクエリへの書き換え ● 非効率な書き方を避ける – ストアドファンクションを使わない ● 同じ結果を産む、より良い実行計画 – サブクエリを JOIN に書き換える
33.
クエリの改善 その 2 ● インデックスを活用する –
基本中の基本 – 意外と何とかなることが多い ● そもそも DB 設計は問題ないか? – クエリはテーブルを入力とした演算 – 入力の設計が良くなければ、クエリが遅くなるのは必然 – 更新は正規化でシンプルに
34.
ベンチマークのすすめ ● コンピュータシステムは複雑過ぎて、実際にどの程度の性 能が出るかということの予測は極めて難しい ● やってみるのが早い!! ● 測定可能な結果が数値で分かる –
改善の具体的な目標に – 具体的な数値無しに性能改善はあり得ない ● システムの限界性能を知る – キャパシティプランニングの指標に
35.
まとめ
36.
RDBMS と上手に付き合う ためのポイント ● リレーショナルモデルを知ろう –
道具を使うには、使い方を理解する必要がある – 使い方を知ることで、正しい用途も見えてくる – なぜその使い方が良いのか、あるいは良くないのかを説 明できる ● トランザクションを知ろう – トランザクションは開発を大幅に効率化する – エラー処理が簡略化 ● パフォーマンスを向上するための仕組みを知ろう – RDBMS の実装 – クエリの改善 アーキテクチャや 理論の理解は超重要
37.
これからもデータベースと 上手く付き合うには ● テクノロジーは進化する – CPU
、メモリ、ディスク、 OS 、言語・・・ etc – 最新テクノロジーは次々登場する ● 原理原則は変わらない – リレーショナルモデル – トランザクション – アーキテクチャ ● CPU がどのように命令を実行するか ● データベースの基本的な仕組み 理論+トレンド
38.
宣伝: 新書籍「詳解 MySQL 5.7
」 ● MySQL 5.7 の新機能を網羅 – 175 もの新機能を解説 – 新機能の理解に欠かせ ないアーキテクチャの話 も盛りだくさん – MySQL の実装について 詳しくなれる!!
39.
Q&Aご静聴ありがとうございました。
Download