Downloaded 26 times





































![Code Sample – Cont’
#3. main logic
#fetching rows by id
#execute_single (index id, cond, cond value, max rows, offset)
$res = $hs->execute_single(0, '=', [ '101' ], 1, 0);
die $hs->get_error() if $res->[0] != 0;
shift(@$res);
for (my $row = 0; $row < 1; ++$row) {
my $user_name= $res->[$row + 0];
my $user_email= $res->[$row + 1];
my $created= $res->[$row + 2];
print "$user_namet$user_emailt$createdn";
}
#4. closing the connection
$hs->close();](https://image.slidesharecdn.com/lesson-120606010056-phpapp02/75/Handling-Massive-Writes-47-2048.jpg)










![JSON Sample Doc
{ _id : ObjectId("4c4ba5c0672c685e5e8aabf3"),
author : "roger",
date : "Sat Jul 24 2010 19:47:11 GMT-0700 (PDT)",
text : ”MongoSF",
tags : [ ”San Francisco", ”MongoDB" ] }
Notes:
- _id is unique, but can be anything you’d like](https://image.slidesharecdn.com/lesson-120606010056-phpapp02/75/Handling-Massive-Writes-61-2048.jpg)



![Places v2
location1 = {
name: "10gen East Coast”,
address: "17 West 18th Street 8th Floor”,
city: "New York”,
zip: "10011”,
tags: [“business”, “mongodb”]
}](https://image.slidesharecdn.com/lesson-120606010056-phpapp02/75/Handling-Massive-Writes-65-2048.jpg)
![Places v2
location1 = {
name: "10gen East Coast”,
address: "17 West 18th Street 8th Floor”,
city: "New York”,
zip: "10011”,
tags: [“business”, “mongodb”]
}
db.locations.find({zip:”10011”, tags:”business”})](https://image.slidesharecdn.com/lesson-120606010056-phpapp02/75/Handling-Massive-Writes-66-2048.jpg)
![Places v3
location1 = {
name: "10gen East Coast”,
address: "17 West 18th Street 8th Floor”,
city: "New York”,
zip: "10011”,
tags: [“business”, “mongodb”],
latlong: [40.0,72.0]
}](https://image.slidesharecdn.com/lesson-120606010056-phpapp02/75/Handling-Massive-Writes-67-2048.jpg)
![Places v3
location1 = {
name: "10gen East Coast”,
address: "17 West 18th Street 8th Floor”,
city: "New York”,
zip: "10011”,
tags: [“business”, “cool place”],
latlong: [40.0,72.0]
}
db.locations.ensureIndex({latlong:”2d”})](https://image.slidesharecdn.com/lesson-120606010056-phpapp02/75/Handling-Massive-Writes-68-2048.jpg)
![Places v3
location1 = {
name: "10gen HQ”,
address: "17 West 18th Street 8th Floor”,
city: "New York”,
zip: "10011”,
tags: [“business”, “cool place”],
latlong: [40.0,72.0]
}
db.locations.ensureIndex({latlong:”2d”})
db.locations.find({latlong:{$near:[40,70]}})](https://image.slidesharecdn.com/lesson-120606010056-phpapp02/75/Handling-Massive-Writes-69-2048.jpg)
![Places v4
location1 = {
name: "10gen HQ”,
address: "17 West 18th Street 8th Floor”,
city: "New York”,
zip: "10011”,
latlong: [40.0,72.0],
tags: [“business”, “cool place”],
tips: [
{user:"nosh", time:6/26/2010, tip:"stop by for
office hours on Wednesdays from 4-6pm"},
{.....},
]
}](https://image.slidesharecdn.com/lesson-120606010056-phpapp02/75/Handling-Massive-Writes-70-2048.jpg)
![Querying your Places
Creating your indexes
db.locations.ensureIndex({tags:1})
db.locations.ensureIndex({name:1})
db.locations.ensureIndex({latlong:”2d”})
Finding places:
db.locations.find({latlong:{$near:[40,70]}})
With regular expressions:
db.locations.find({name: /^typeaheadstring/)
By tag:
db.locations.find({tags: “business”})](https://image.slidesharecdn.com/lesson-120606010056-phpapp02/75/Handling-Massive-Writes-71-2048.jpg)


![Users
user1 = {
name: “nosh”
email: “nosh@10gen.com”,
.
.
.
checkins: [{ location: “10gen HQ”,
ts: 9/20/2010 10:12:00,
…},
…
]
}](https://image.slidesharecdn.com/lesson-120606010056-phpapp02/75/Handling-Massive-Writes-74-2048.jpg)

![Alternative
user1 = {
name: “nosh”
email: “nosh@10gen.com”,
.
.
.
checkins: [4b97e62bf1d8c7152c9ccb74, 5a20e62bf1d8c736ab]
}
checkins [] = ObjectId reference to locations collection](https://image.slidesharecdn.com/lesson-120606010056-phpapp02/75/Handling-Massive-Writes-76-2048.jpg)







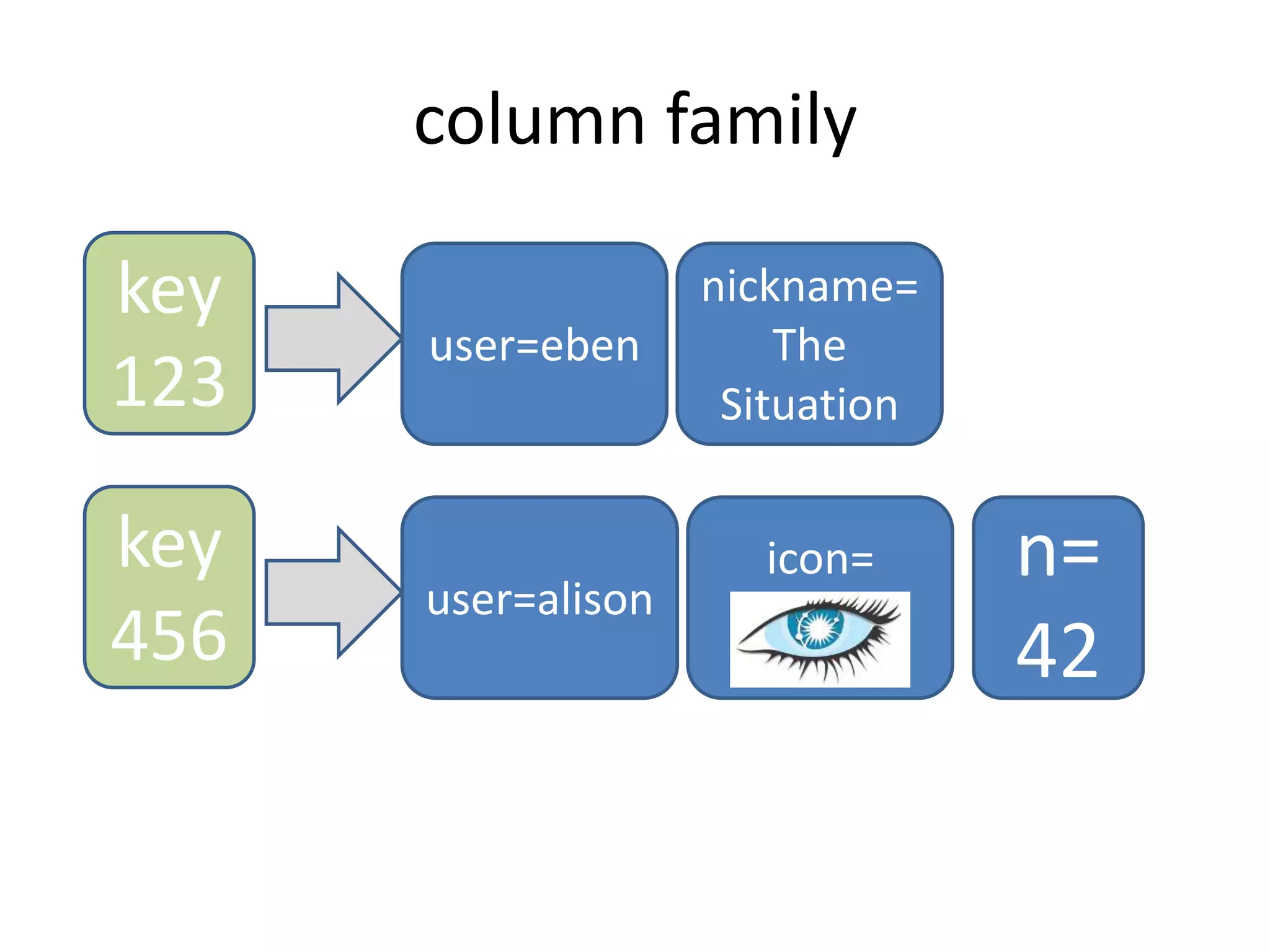
![structure
keyspace
column family
settings
(eg,
partitioner) settings (eg,
column
comparator,
type [Std]) name value clock](https://image.slidesharecdn.com/lesson-120606010056-phpapp02/75/Handling-Massive-Writes-88-2048.jpg)




![example
$cassandra –f
$bin/cassandra-cli
cassandra> connect localhost/9160
cassandra> set
Keyspace1.Standard1[‘eben’][‘age’]=‘29’
cassandra> set
Keyspace1.Standard1[‘eben’][‘email’]=‘e@e.com’
cassandra> get Keyspace1.Standard1[‘eben'][‘age']
=> (column=6e616d65, value=39,
timestamp=1282170655390000)](https://image.slidesharecdn.com/lesson-120606010056-phpapp02/75/Handling-Massive-Writes-94-2048.jpg)
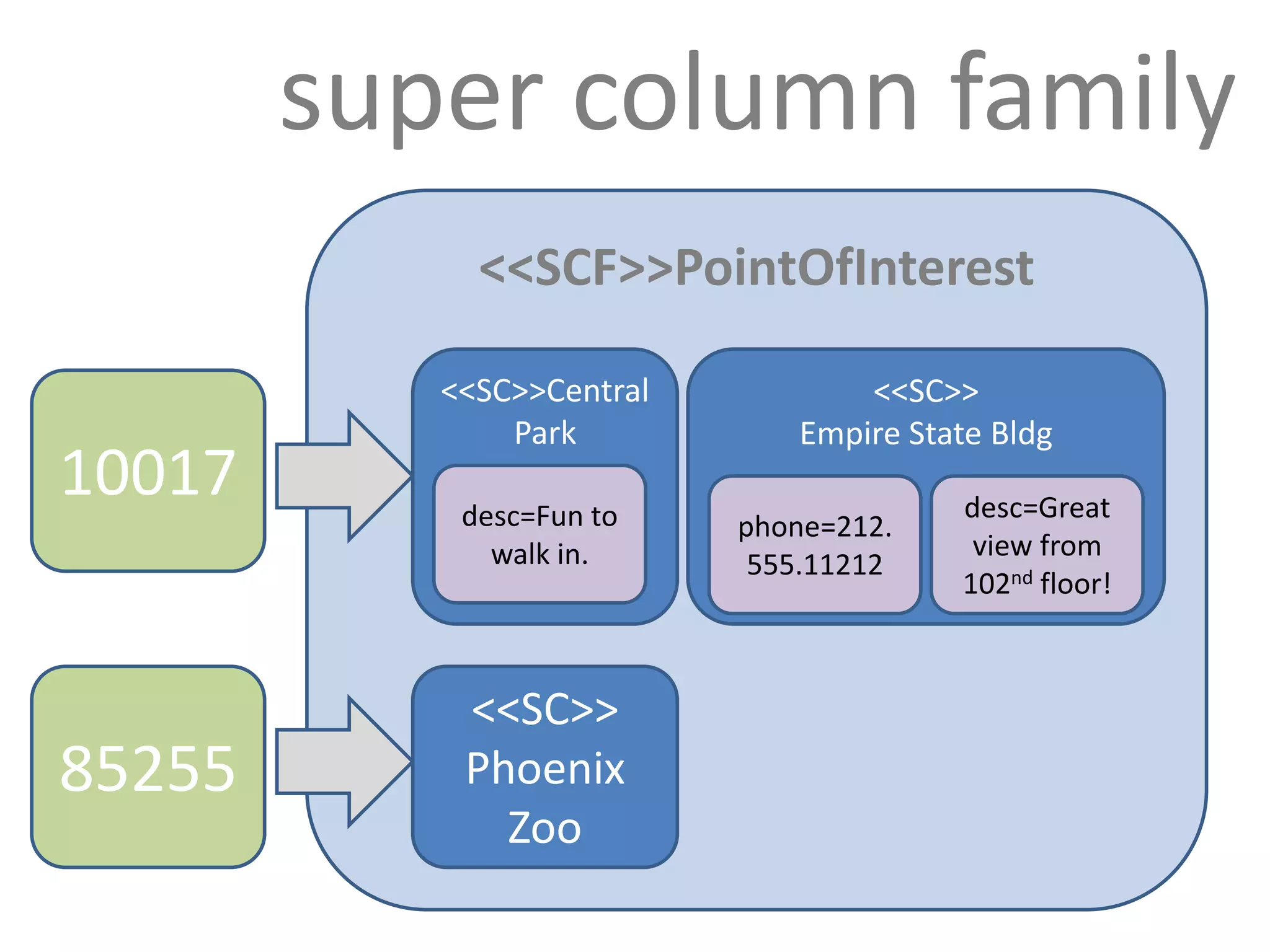
![a column has 3 parts
1. name
– byte[]
– determines sort order
– used in queries
– indexed
2. value
– byte[]
– you don’t query on column values
3. timestamp
– long (clock)
– last write wins conflict resolution](https://image.slidesharecdn.com/lesson-120606010056-phpapp02/75/Handling-Massive-Writes-95-2048.jpg)





![• get() : Column
– get the Col or SC at given ColPath
read api
COSC cosc = client.get(key, path, CL);
• get_slice() : List<ColumnOrSuperColumn>
– get Cols in one row, specified by SlicePredicate:
List<ColumnOrSuperColumn> results =
client.get_slice(key, parent, predicate, CL);
• multiget_slice() : Map<key, List<CoSC>>
– get slices for list of keys, based on SlicePredicate
Map<byte[],List<ColumnOrSuperColumn>> results =
client.multiget_slice(rowKeys, parent, predicate, CL);
• get_range_slices() : List<KeySlice>
– returns multiple Cols according to a range
– range is startkey, endkey, starttoken, endtoken:
List<KeySlice> slices = client.get_range_slices(
parent, predicate, keyRange, CL);](https://image.slidesharecdn.com/lesson-120606010056-phpapp02/75/Handling-Massive-Writes-102-2048.jpg)
![client.insert(userKeyBytes, parent, write api
new Column(“band".getBytes(UTF8),
“Funkadelic".getBytes(), clock), CL);
batch_mutate
– void batch_mutate(
map<byte[], map<String, List<Mutation>>> , CL)
remove
– void remove(byte[],
ColumnPath column_path, Clock, CL)](https://image.slidesharecdn.com/lesson-120606010056-phpapp02/75/Handling-Massive-Writes-103-2048.jpg)
![//create param
batch_mutate
Map<byte[], Map<String, List<Mutation>>> mutationMap =
new HashMap<byte[], Map<String, List<Mutation>>>();
//create Cols for Muts
Column nameCol = new Column("name".getBytes(UTF8),
“Funkadelic”.getBytes("UTF-8"), new Clock(System.nanoTime()););
Mutation nameMut = new Mutation();
nameMut.column_or_supercolumn = nameCosc; //also phone, etc
Map<String, List<Mutation>> muts = new HashMap<String, List<Mutation>>();
List<Mutation> cols = new ArrayList<Mutation>();
cols.add(nameMut);
cols.add(phoneMut);
muts.put(CF, cols);
//outer map key is a row key; inner map key is the CF name
mutationMap.put(rowKey.getBytes(), muts);
//send to server
client.batch_mutate(mutationMap, CL);](https://image.slidesharecdn.com/lesson-120606010056-phpapp02/75/Handling-Massive-Writes-104-2048.jpg)





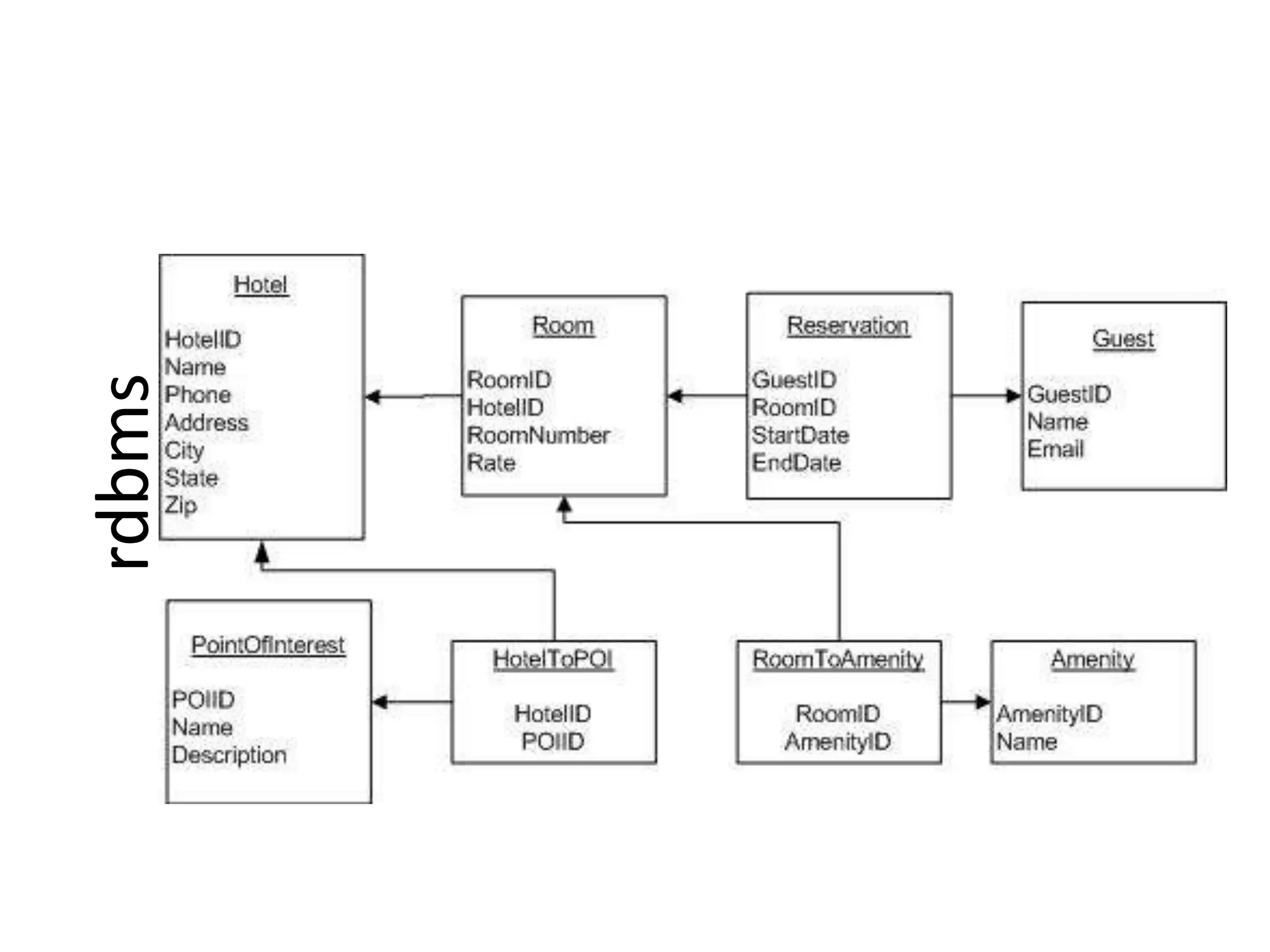
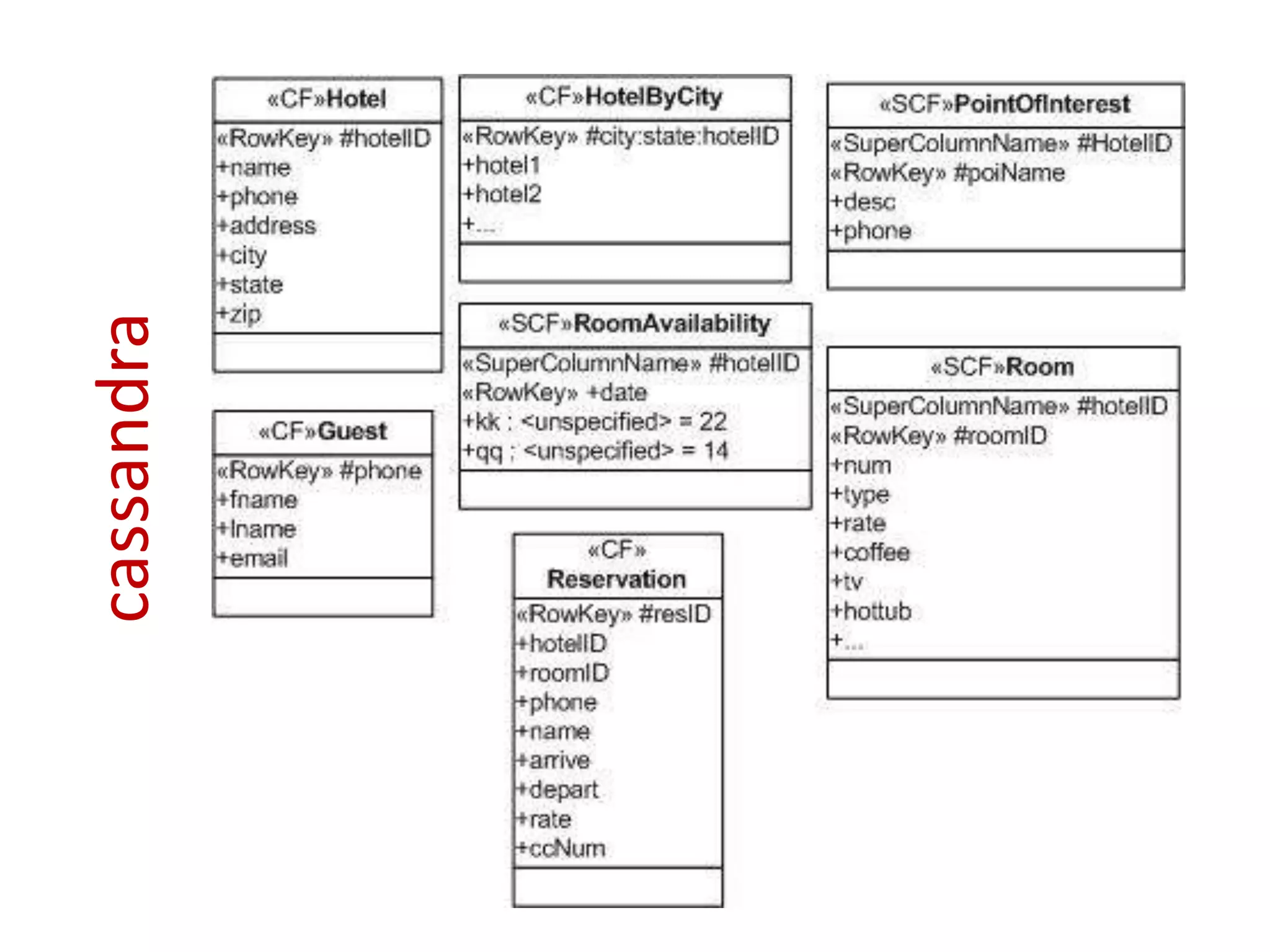













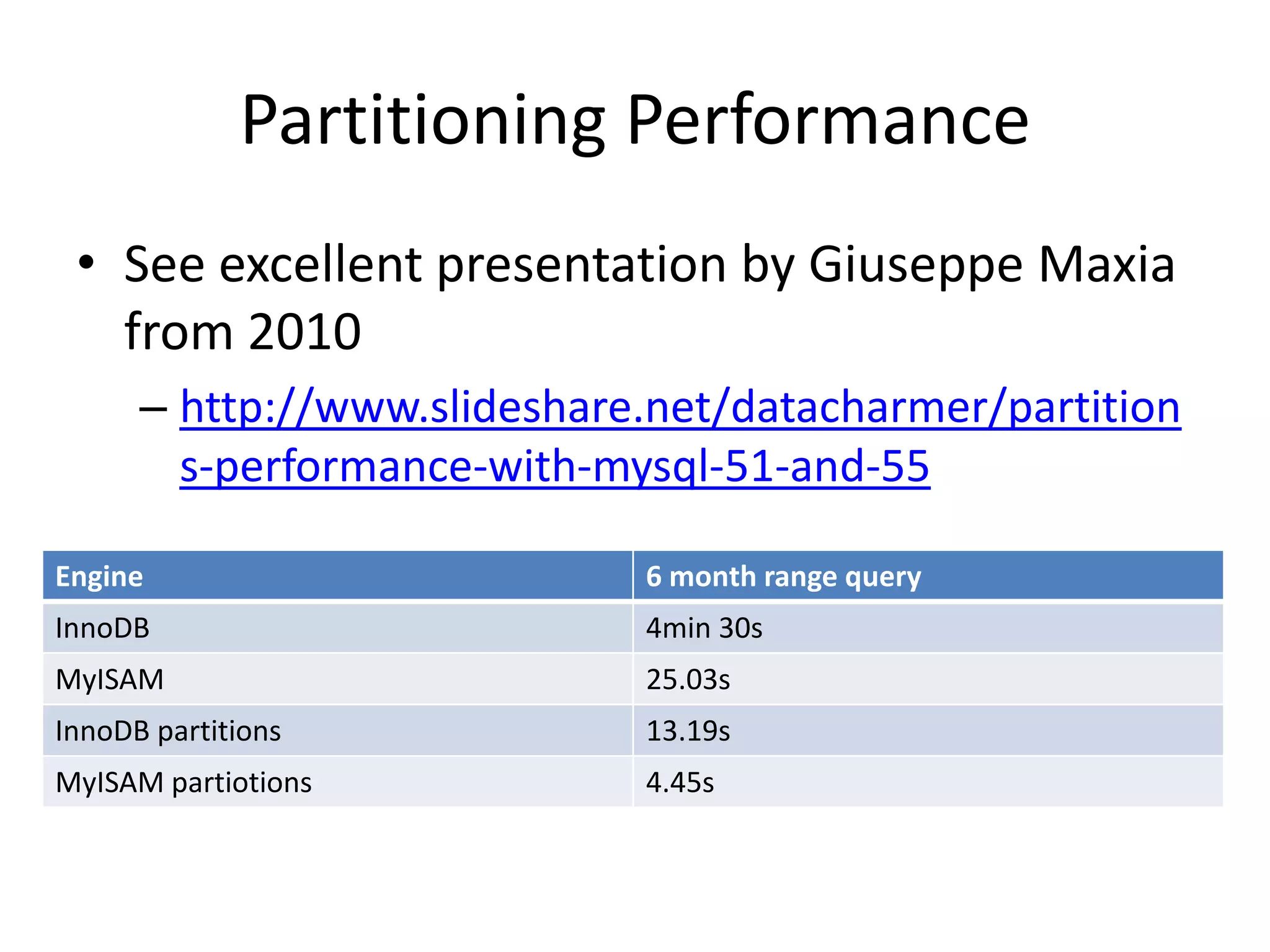
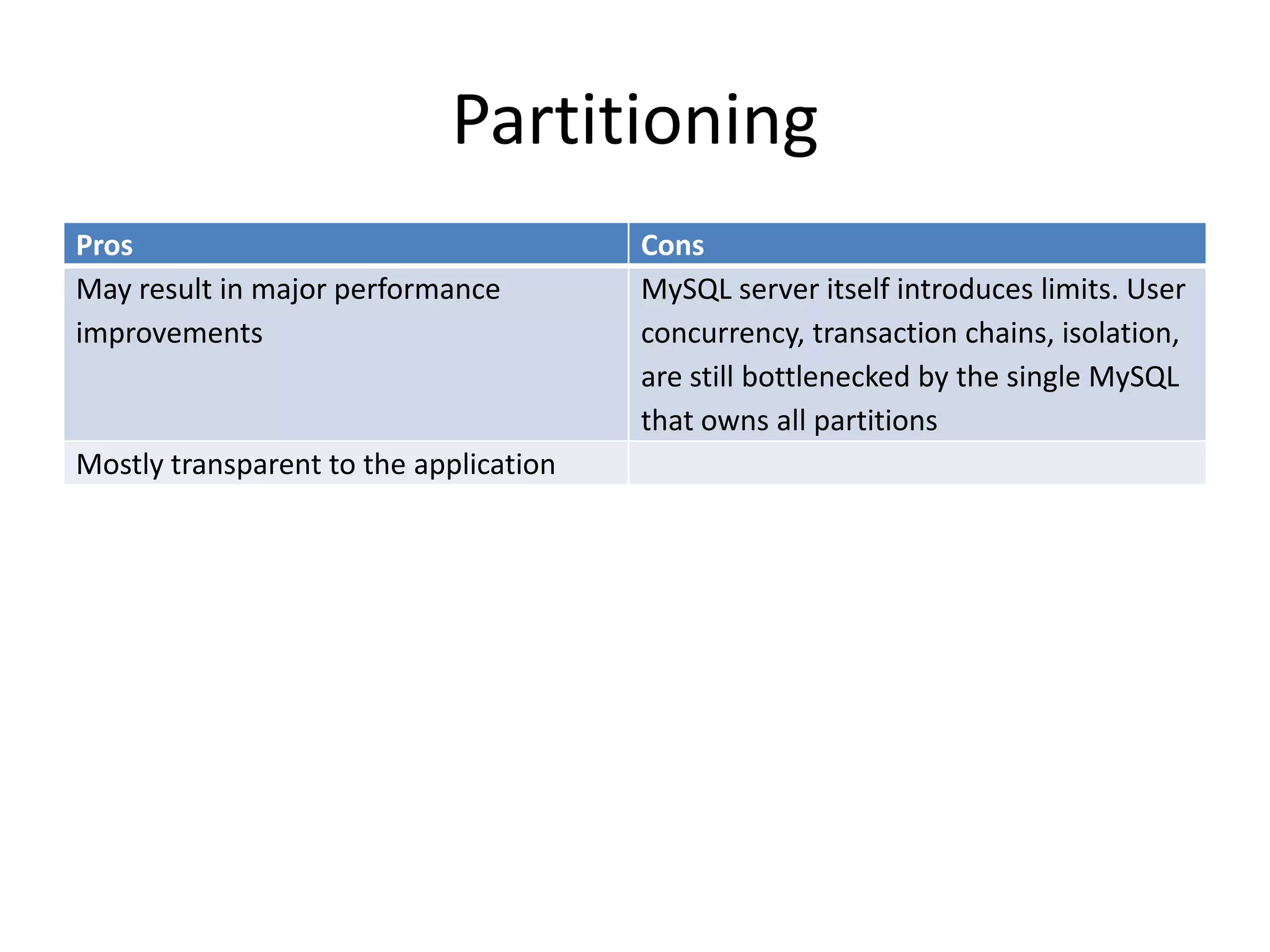
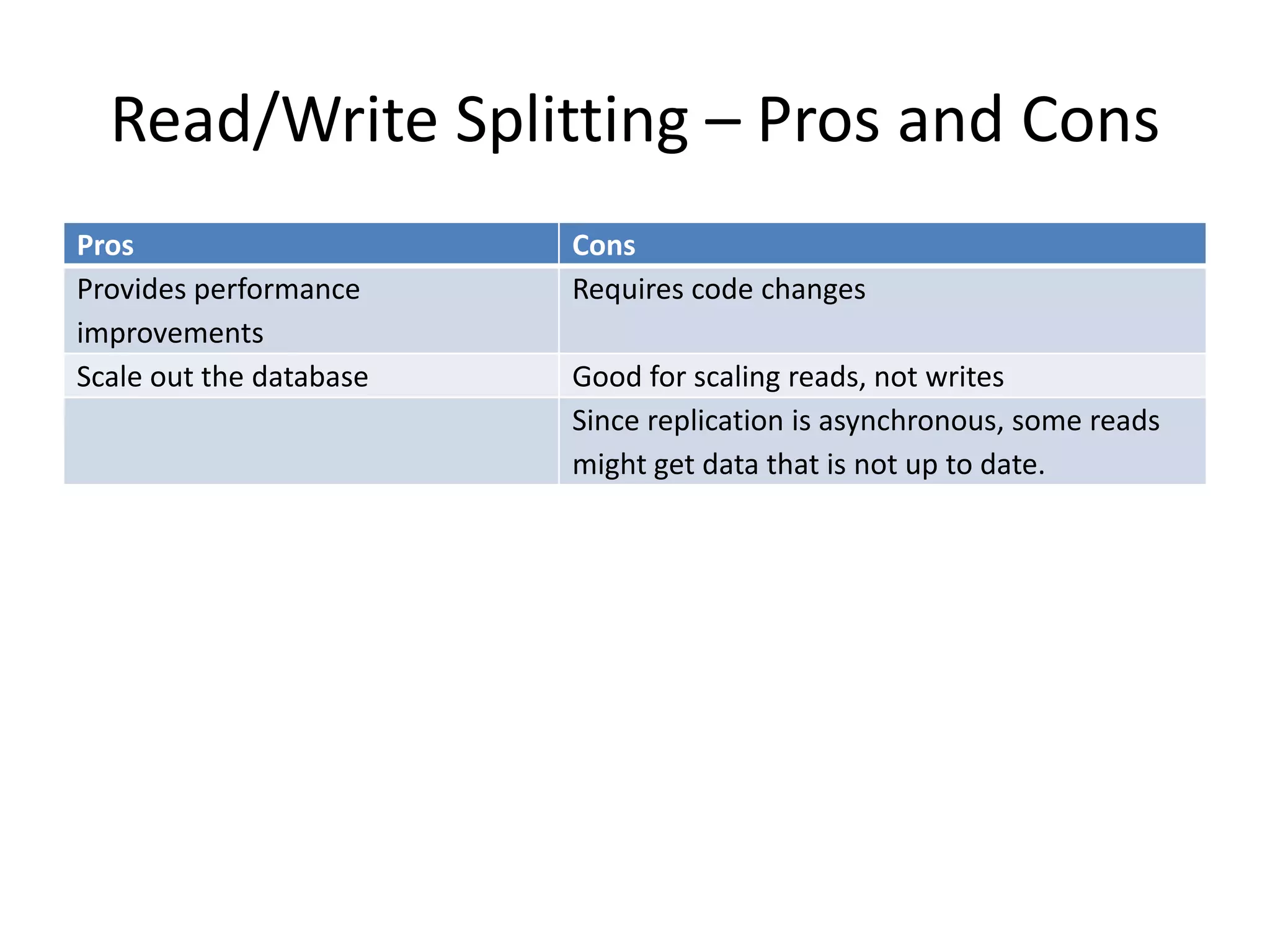
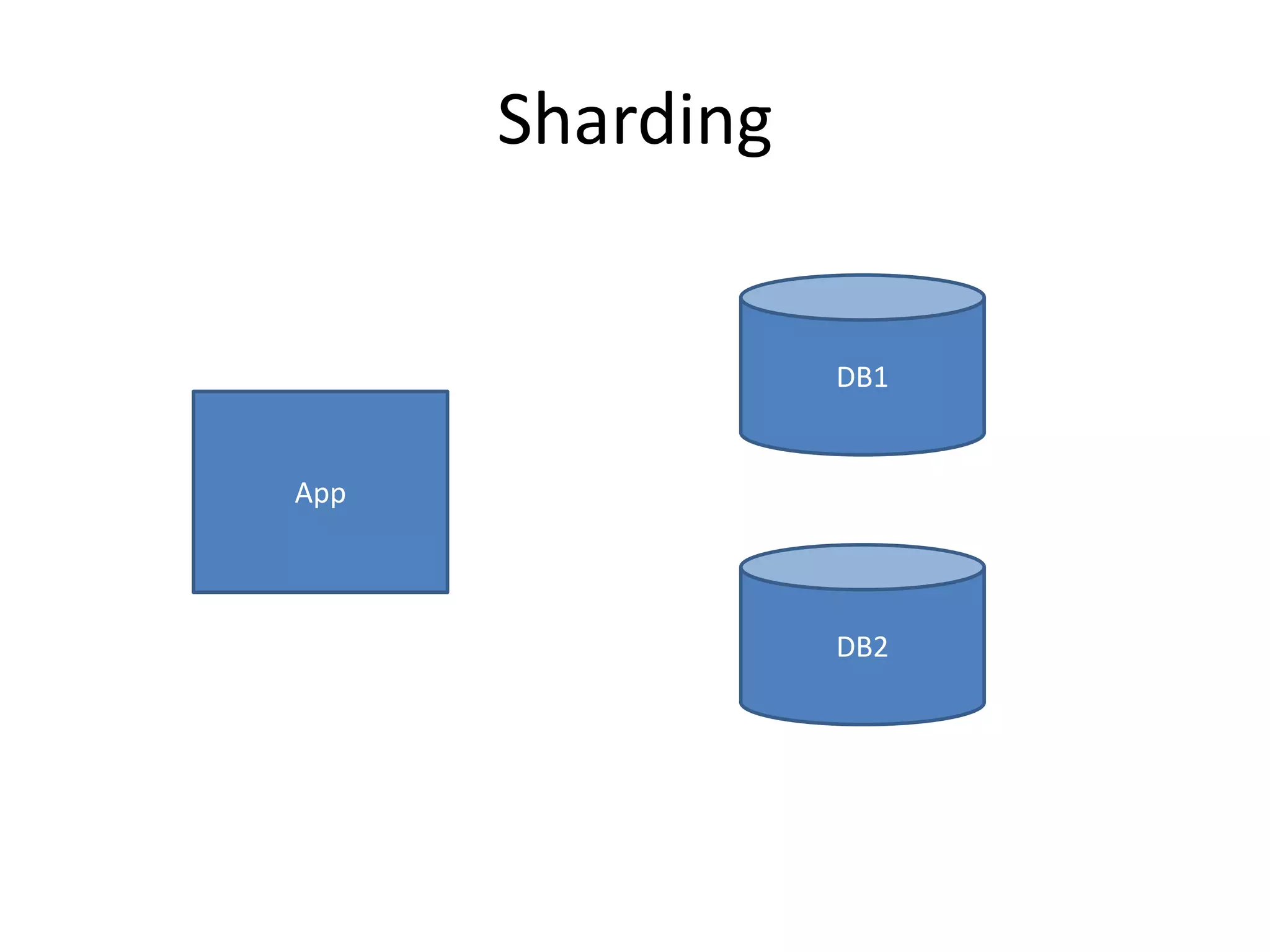
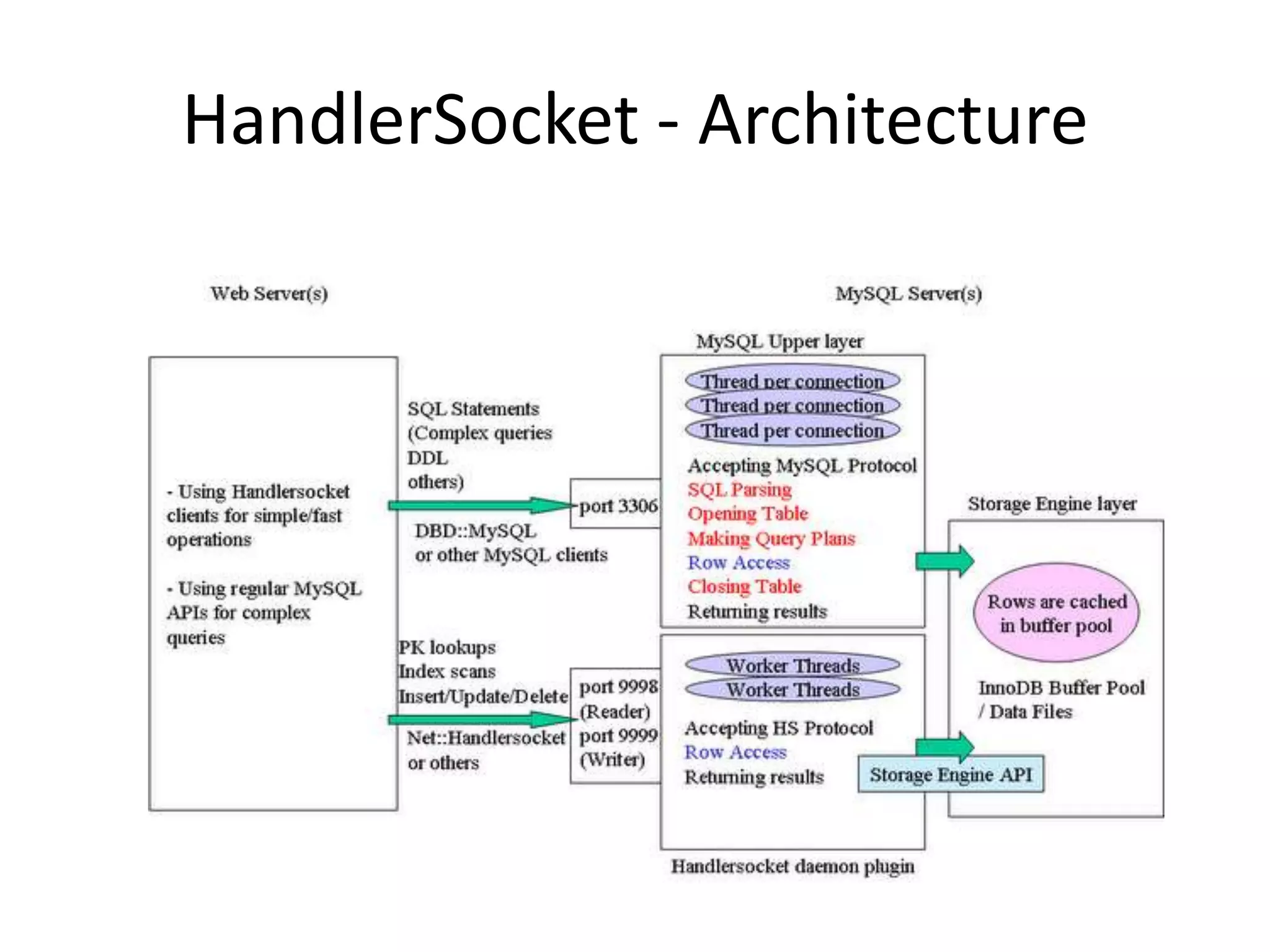
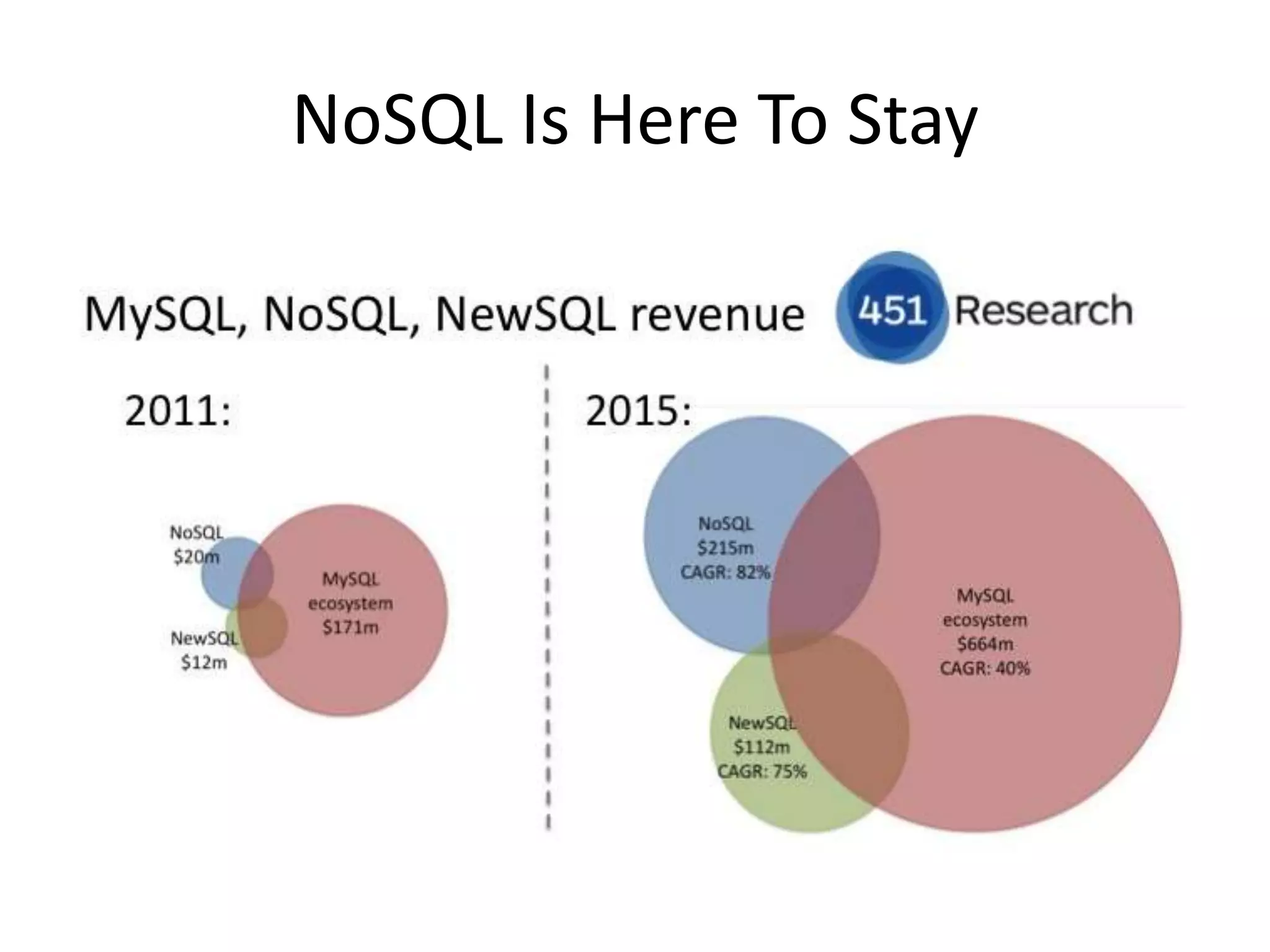
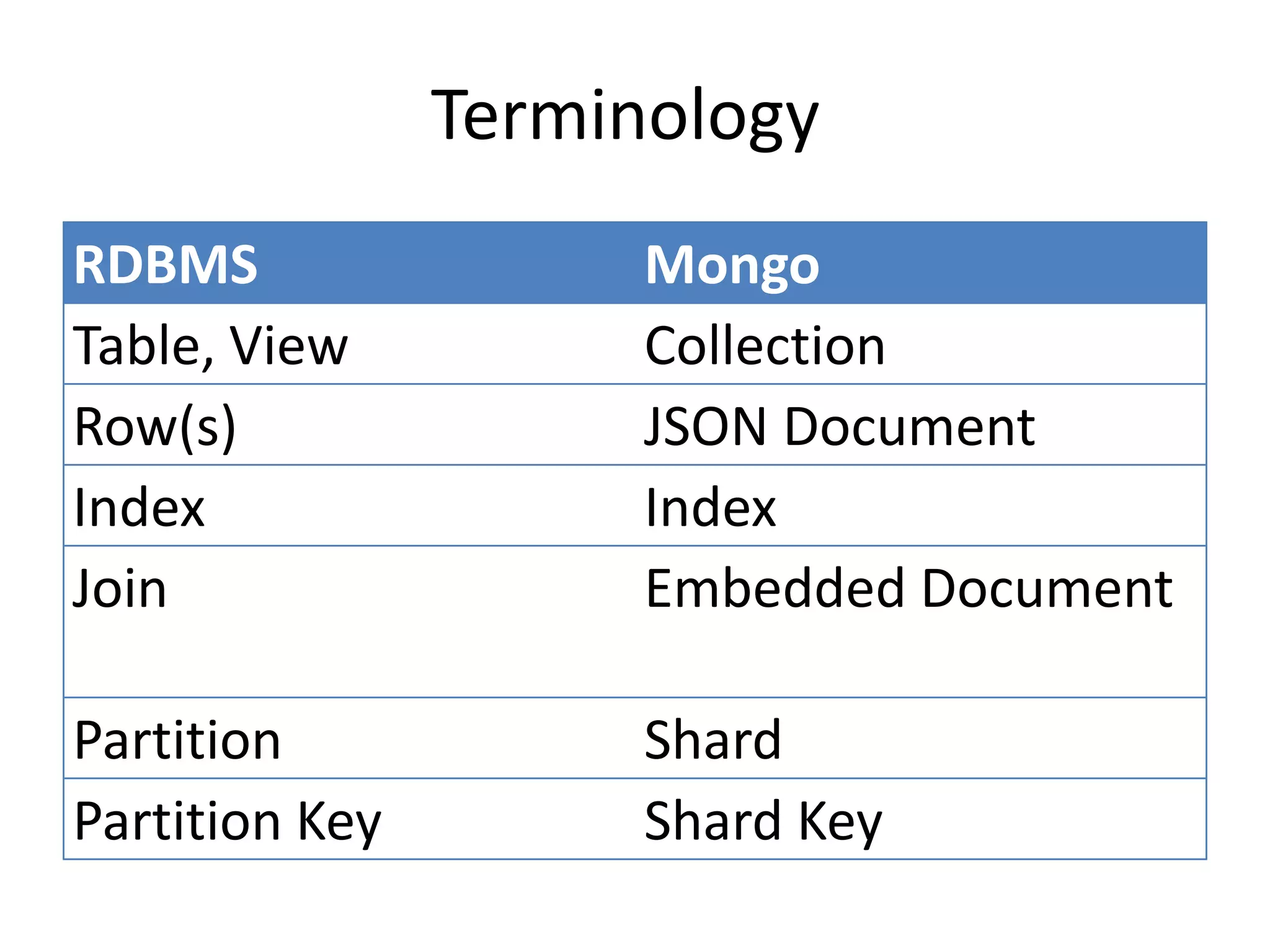
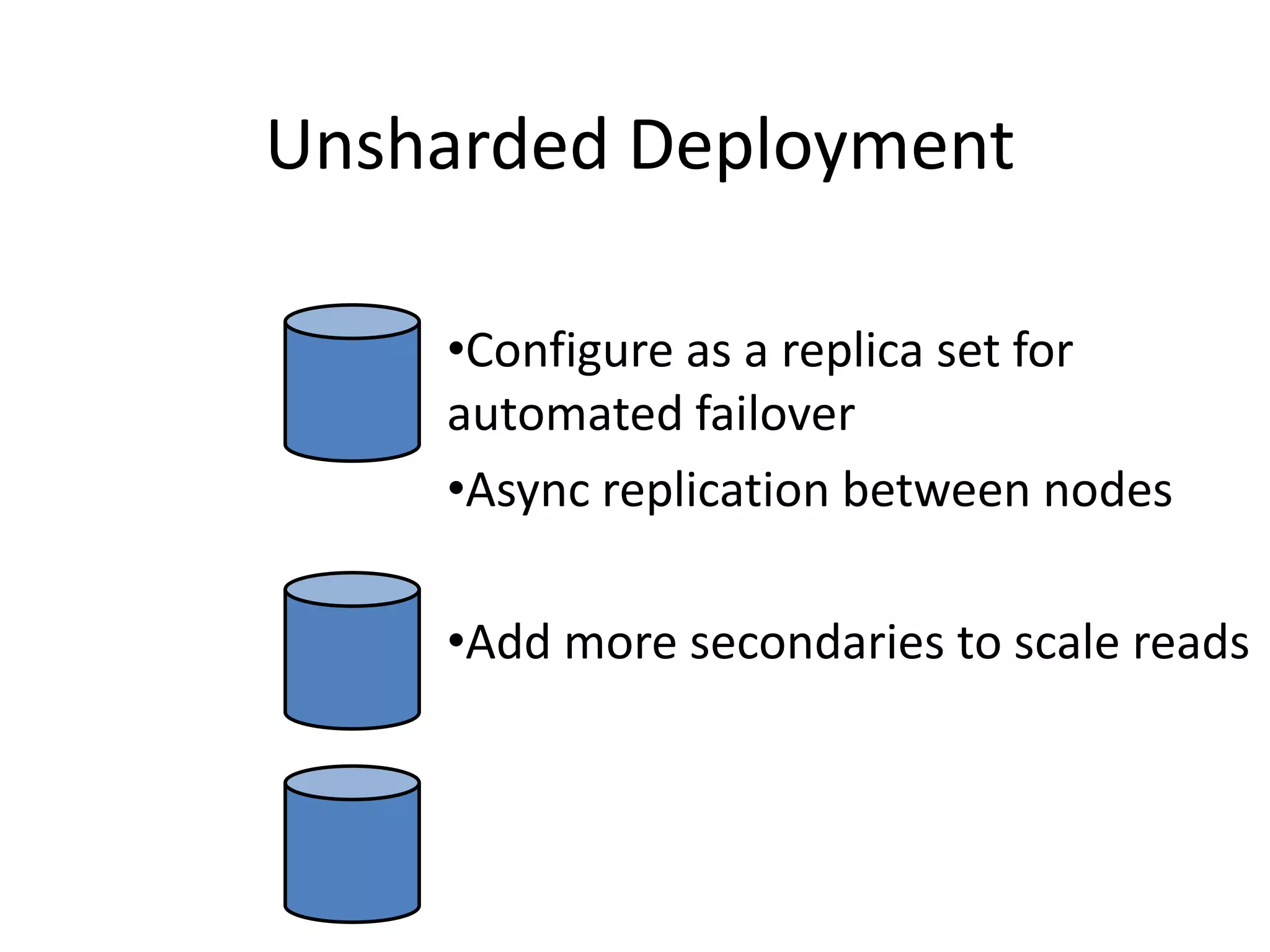
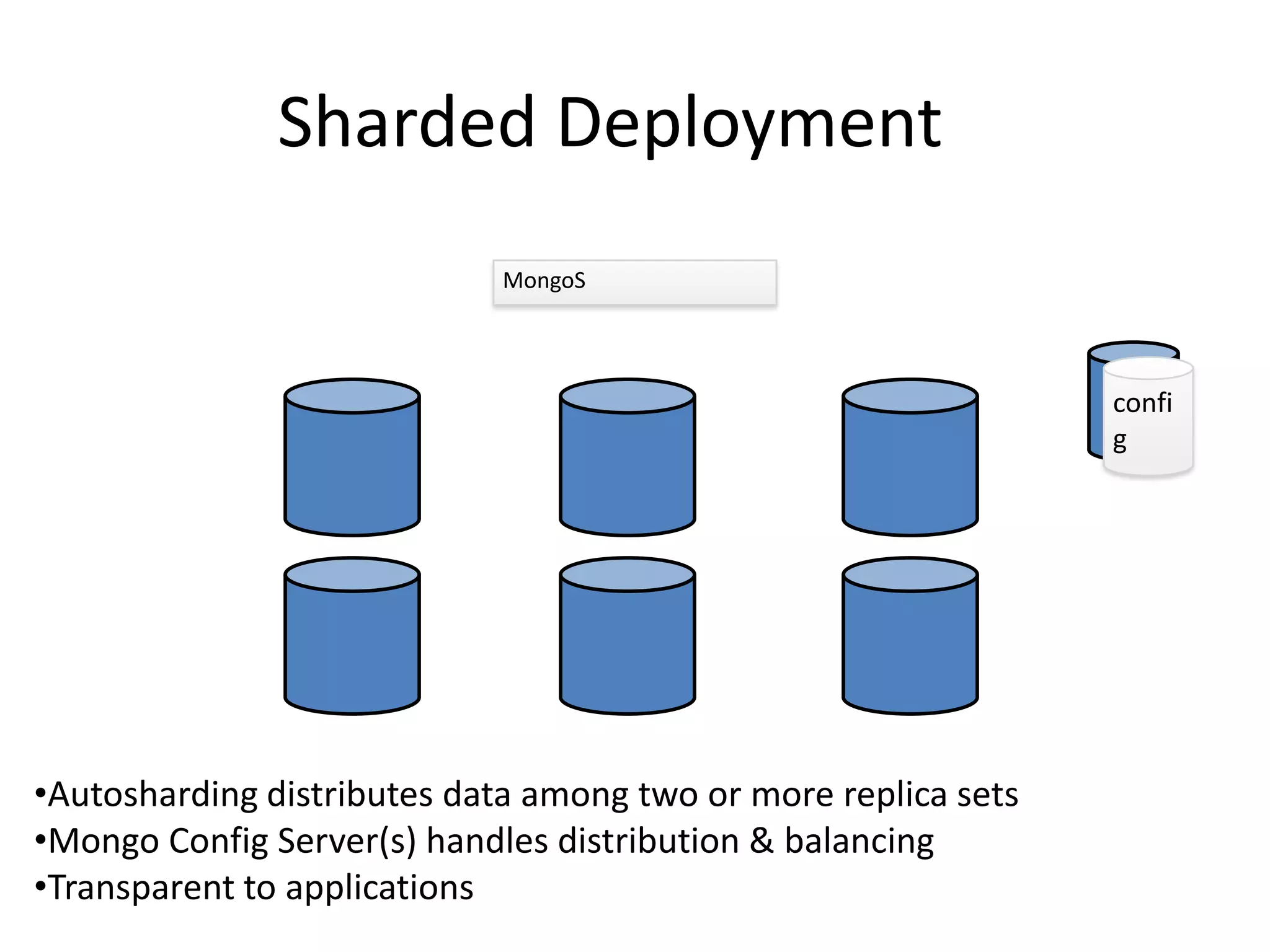
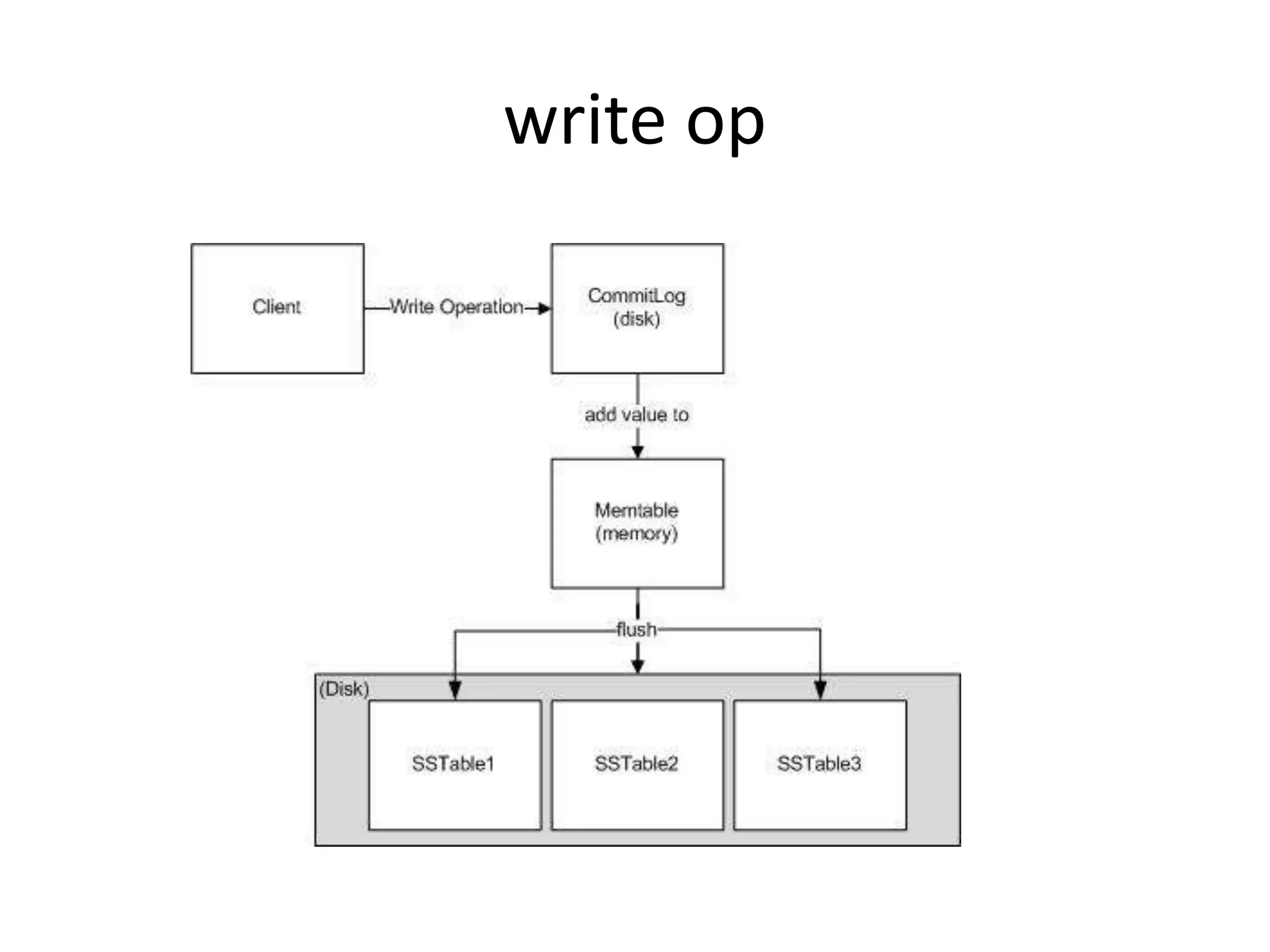
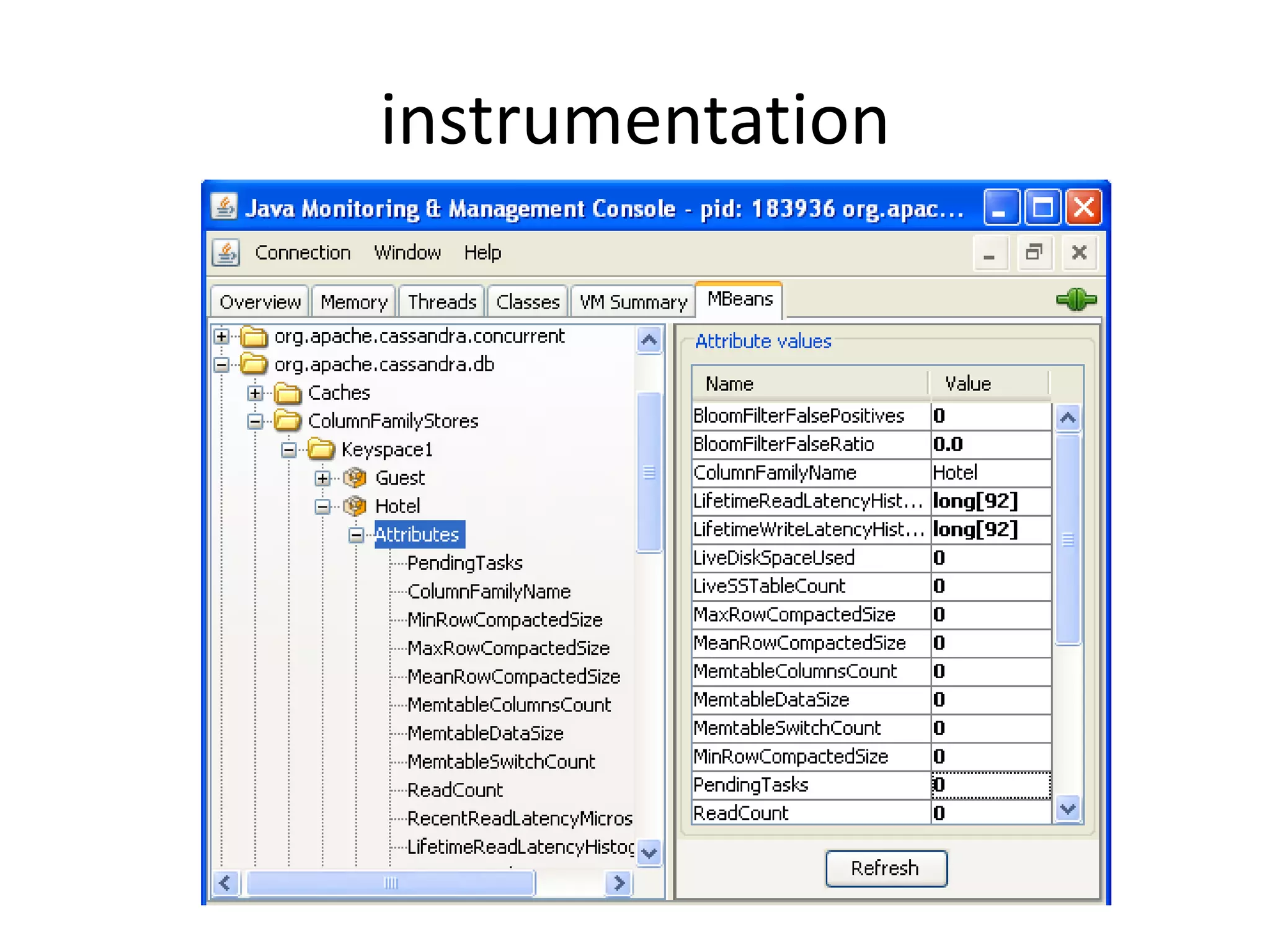
This document discusses handling massive writes for online transaction processing (OLTP) systems. It begins with an introduction and overview of the topics to be covered, including terminology, differences between massive reads versus writes, and potential solutions using relational databases, NoSQL databases, and code optimizations. Specific solutions discussed for massive writes include using memory, fast disks, caching, column-oriented databases, SQL tuning, database partitioning, reading from slaves, and sharding or splitting data across multiple databases. The document provides pros and cons of each approach and examples of performance improvements observed.







































![개발과 디자인은 재미있어 [141025 한국우분투커뮤니티 발표]](https://cdn.slidesharecdn.com/ss_thumbnails/random-141026013311-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)






![[NHN NEXT] Java 강의 - Week4](https://cdn.slidesharecdn.com/ss_thumbnails/plinjava-week04-140812103158-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)







































