1) The University of Michigan Library has been migrating older digital collections to HathiTrust for preservation purposes over the past 5 years.
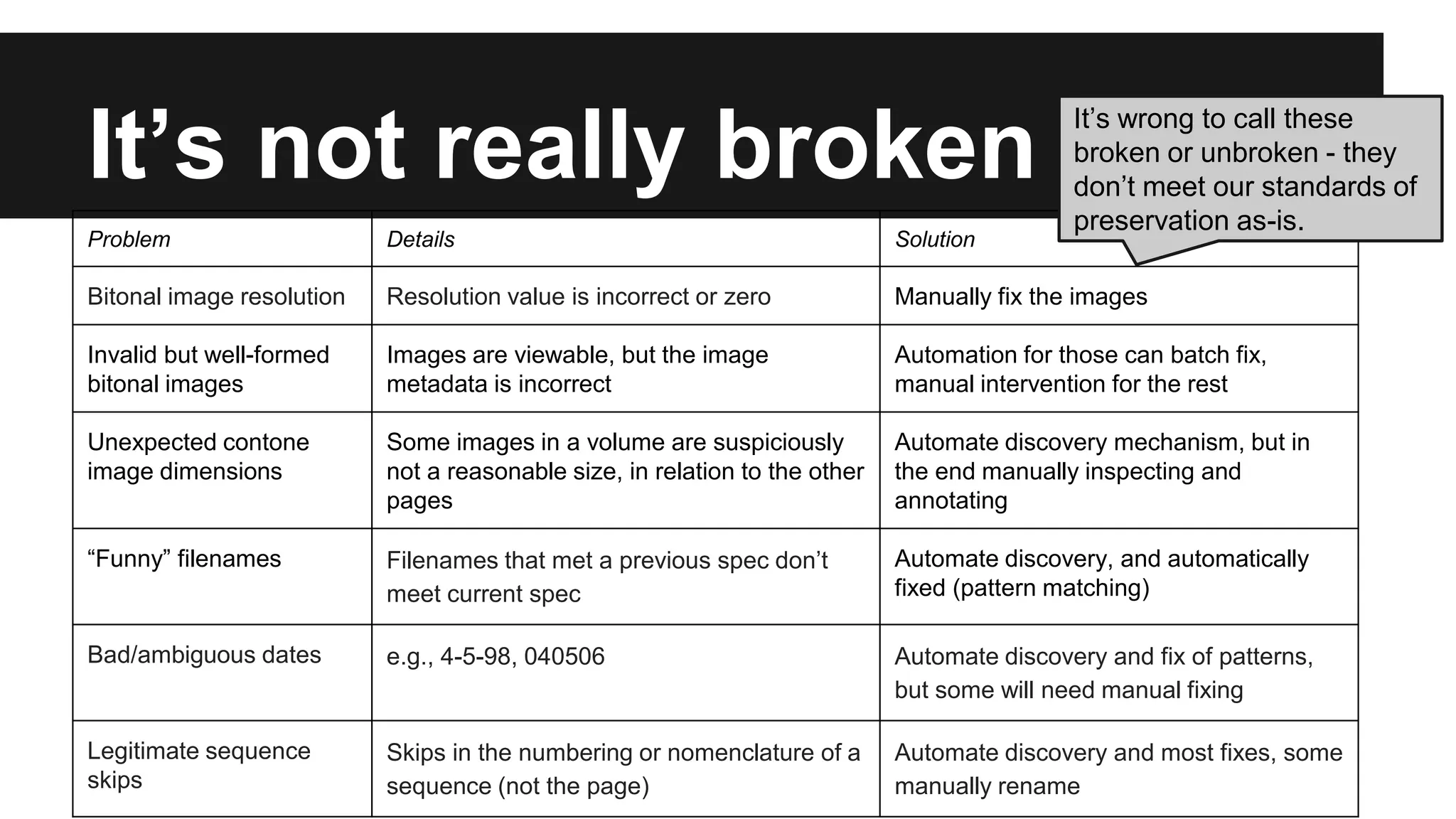
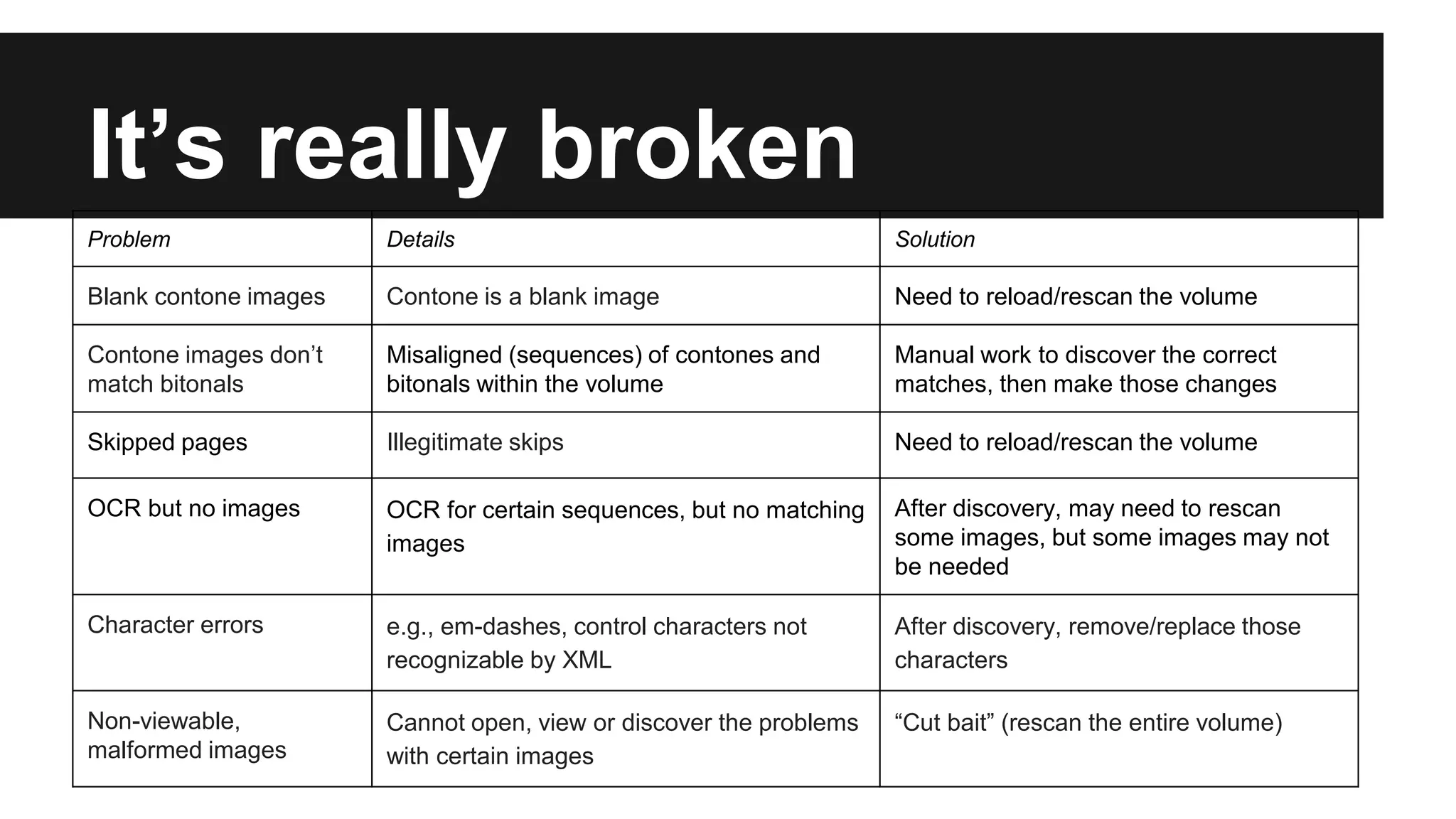
2) Validating and migrating the content has been an intensive multi-year process involving several technical challenges and manual review.
3) Of over 167,000 volumes in their text collections, they have so far validated and migrated 15% (25,339) volumes to HathiTrust, with many more to still address.













![Way back in 1995...
● Content was created with long term
preservation in mind, but…
o Ingest validation was minimal
o Relied on vendors creating correct
content [pause for laughter]
o Metadata that was to become
engine of management at scale
was inconsistent or incorrect
#digpres14](https://image.slidesharecdn.com/digitalpreservation2014-presentationslides-140818112252-phpapp01/75/The-Great-Migration-Moving-First-Generation-Digital-Texts-to-HathiTrust-Digital-Preservation-2014-16-2048.jpg)























































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)

















