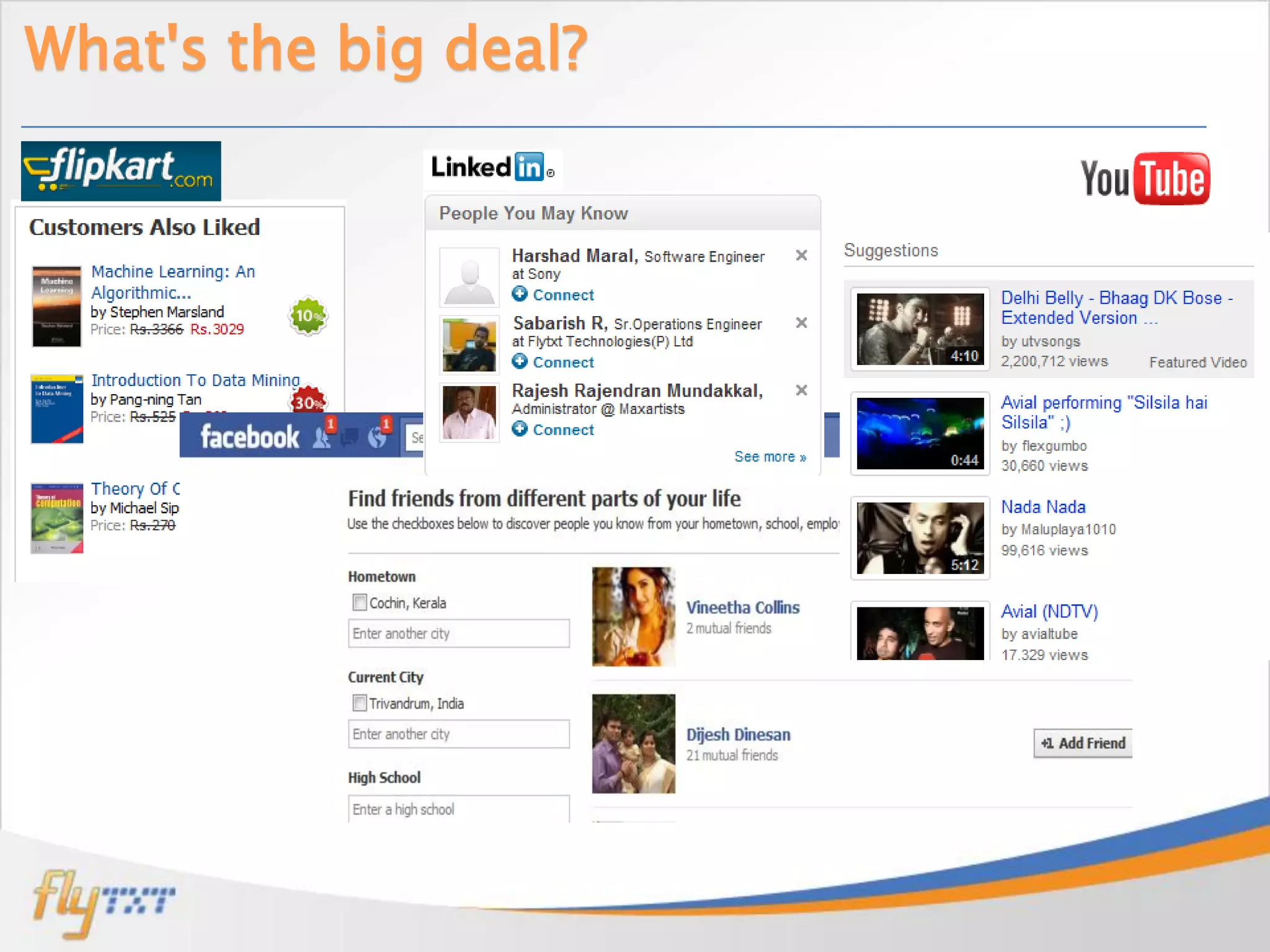
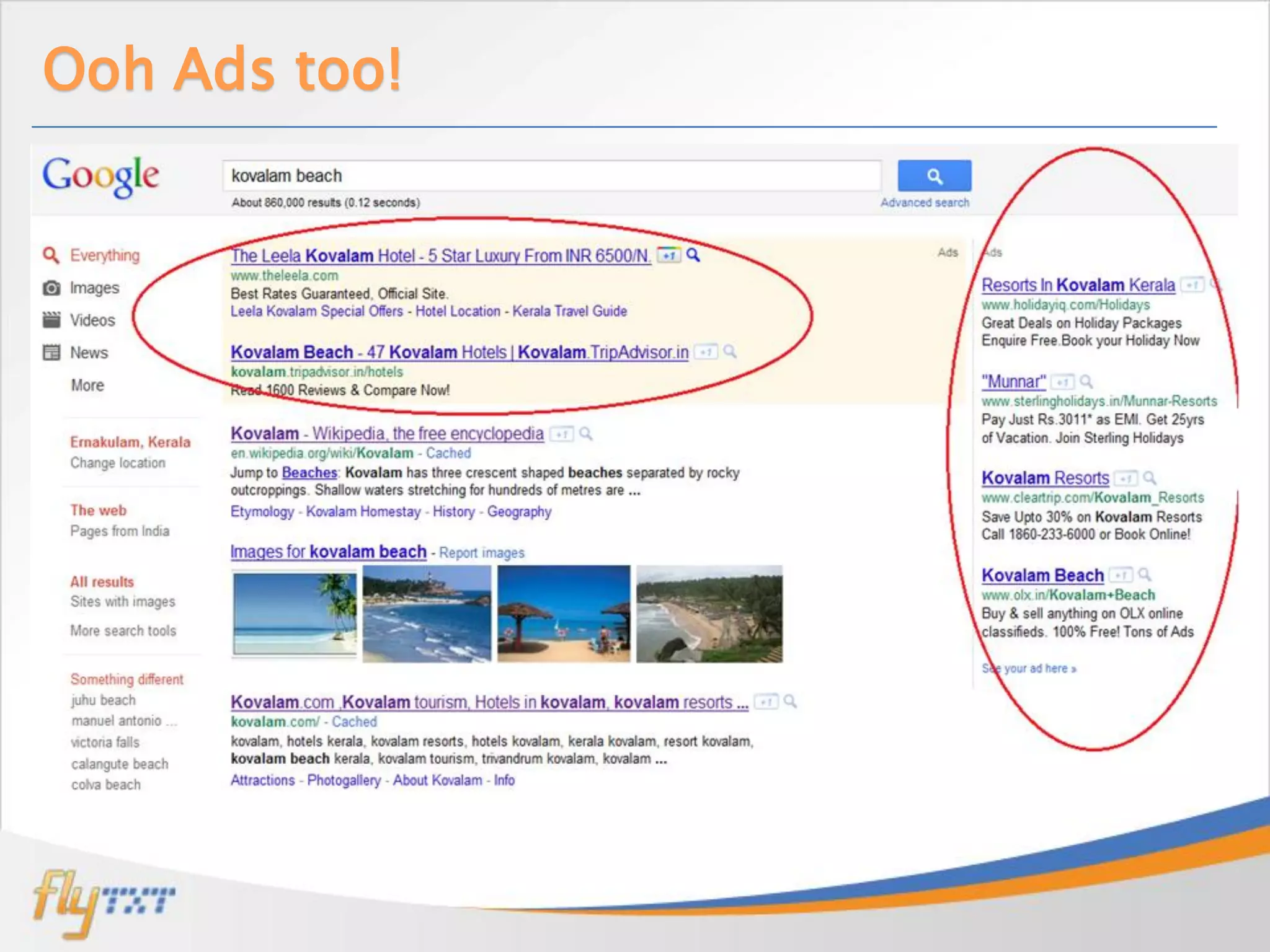
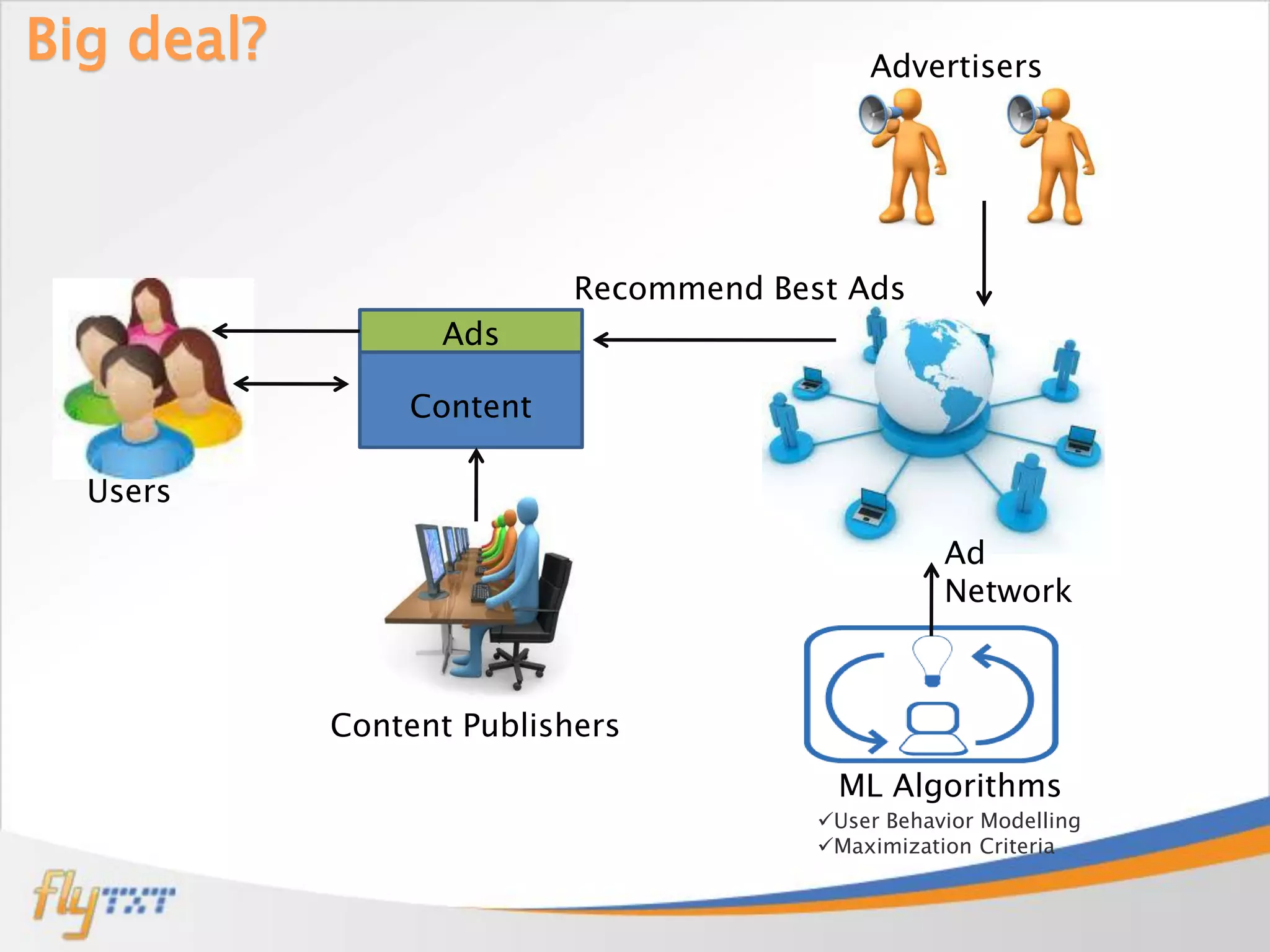
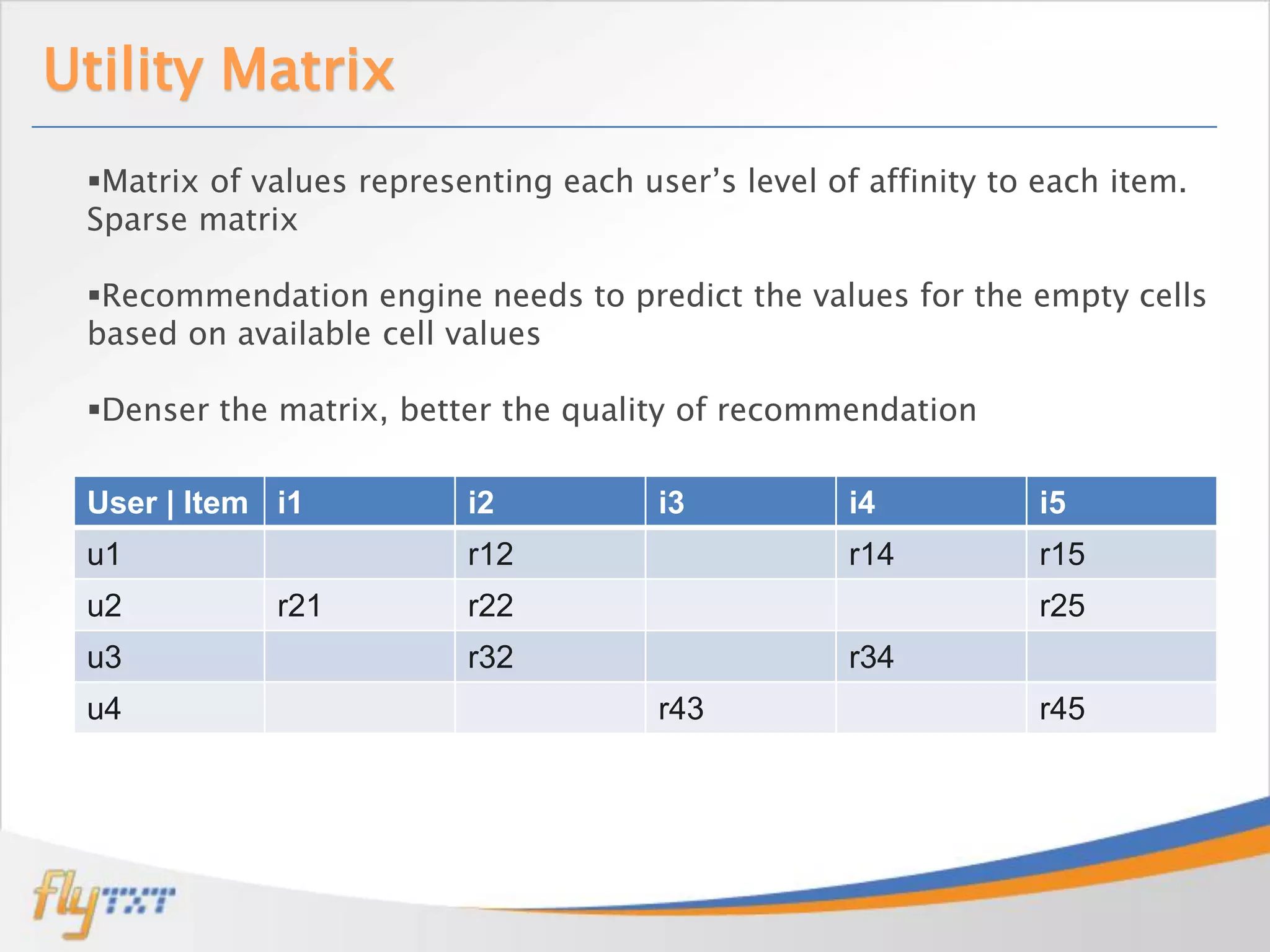
Jobin Wilson is an architect at Flytxt, where he works on big data analytics and automation projects. He has previous experience with virtualization, cloud management, data center automation, and workflow systems. In this presentation, he discusses recommendation engines, how they work using collaborative filtering techniques, and the challenges of implementing them at scale using Apache Mahout and distributed computing frameworks. He also covers strategies for taking recommendation systems into production.




























![[Trabalho Acadêmico]Relançamento de Forrest Gump](https://cdn.slidesharecdn.com/ss_thumbnails/marcellocaetano-160615170805-thumbnail.jpg?width=640&height=640&fit=bounds)


































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)

















