Download as PDF, PPTX
![About me :)
● Computer Programmer,
● Coding in Python for last 3 years,
● Part of the Team at HP that developed an early
warning software that parses over 40+TB of
data annually to find problems before they
happen, (Coded in Python)
● Skills in Django, PyQt,
● Http://uptosomething.in [ Homepage ]](https://image.slidesharecdn.com/presentation-110925023216-phpapp01/85/Python-Performance-101-1-320.jpg)



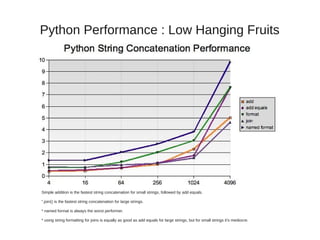
![Python Performance : Low Hanging Fruits
● String concatenation Benchmark ( http://sprocket.io/blog/2007/10/string-concatenation-performance-in-
python/ )
add: a + b + c + d
add equals: a += b; a += c; a += d
format strings: ‘%s%s%s%s’ % (a, b, c, d)
named format strings:‘%(a)s%(b)s%(c)s%(d)s’ % {‘a’: a, ‘b’: b, ‘c’: c, ‘d’: d}”
join: ”.join([a,b,c,d])
#!/usr/bin/python
# benchmark various string concatenation methods. Run each 5*1,000,000 times
# and pick the best time out of the 5. Repeats for string lengths of
# 4, 16, 64, 256, 1024, and 4096. Outputs in CSV format via stdout.
import timeit
tests = {
'add': "x = a + b + c + d",
'join': "x = ''.join([a,b,c,d])",
'addequals': "x = a; x += b; x += c; x += d",
'format': "x = '%s%s%s%s' % (a, b, c, d)",
'full_format': "x = '%(a)s%(b)s%(c)s%(d)s' % {'a': a, 'b': b, 'c': c, 'd': d}"
}
count = 1
for i in range(6):
count = count * 4
init = "a = '%s'; b = '%s'; c = '%s'; d = '%s'" %
('a' * count, 'b' * count, 'c' * count, 'd' * count)
for test in tests:
t = timeit.Timer(tests[test], init)
best = min(t.repeat(5, 1000000))
print "'%s',%s,%s" % (test, count, best)](https://image.slidesharecdn.com/presentation-110925023216-phpapp01/85/Python-Performance-101-6-320.jpg)
![Python Performance : Low Hanging Fruits
newlist = [] newlist = map(str.upper, oldlist)
for word in oldlist:
newlist.append(word.upper())
newlist = [s.upper() for s in oldlist]
upper = str.upper
newlist = []
append = newlist.append
I wouldn't do this
for word in oldlist:
append(upper(word))
Exception for branching
wdict = {}
wdict = {}
for word in words:
for word in words:
try:
if word not in wdict:
wdict[word] += 1
wdict[word] = 0
except KeyError:
wdict[word] += 1
wdict[word] = 1](https://image.slidesharecdn.com/presentation-110925023216-phpapp01/85/Python-Performance-101-8-320.jpg)


![Python : Multi-core Architecture
● In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native threads from
executing Python bytecodes at once. This lock is necessary mainly because CPython's memory
management is not thread-safe. (However, since the GIL exists, other features have grown to depend on the
guarantees that it enforces.) More here http://wiki.python.org/moin/GlobalInterpreterLock
● Use Multi Processing to overcome GIL
from multiprocessing import Process, Queue
def f(iq,oq):
if not iq.empty():
values = iq.get()
oq.put(sum(values))
if __name__ == '__main__':
inputQueue = Queue()
outputQueue = Queue()
values = range(0,1000000)
processOne = Process(target=f, args=(inputQueue,outputQueue))
processTwo = Process(target=f, args=(inputQueue,outputQueue))
inputQueue.put(values[0:len(values)/2])
inputQueue.put(values[len(values)/2:])
processOne.start()
processTwo.start()
processOne.join()
processTwo.join()
outputOne = outputQueue.get()
outputTwo = outputQueue.get()
print sum([outputOne, outputTwo])](https://image.slidesharecdn.com/presentation-110925023216-phpapp01/85/Python-Performance-101-11-320.jpg)




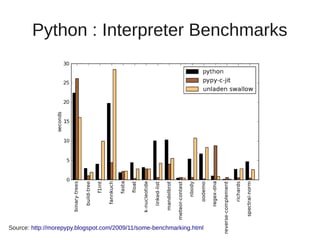
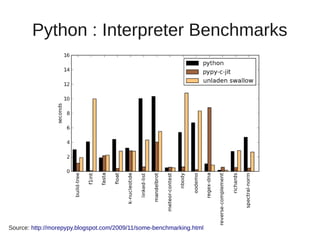
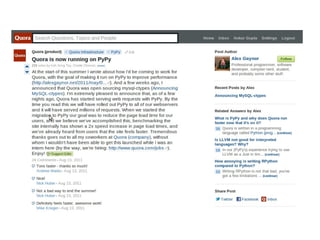



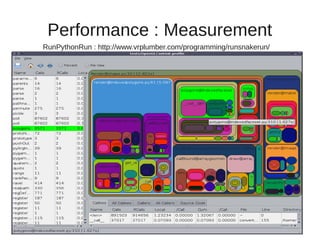
The document discusses various Python interpreters: - CPython is the default interpreter but has a Global Interpreter Lock (GIL) limiting performance on multi-core systems. - Jython and IronPython run Python on the JVM and CLR respectively, allowing true concurrency but can be slower than CPython. - PyPy uses a just-in-time (JIT) compiler which can provide huge performance gains compared to CPython as shown on speed.pypy.org. - Unladen Swallow aimed to add JIT compilation to CPython but was merged into Python 3.






















![[Let'Swift 2019] 실용적인 함수형 프로그래밍 워크샵](https://cdn.slidesharecdn.com/ss_thumbnails/practicalfunctionalprogramming-191113054017-thumbnail.jpg?width=640&height=640&fit=bounds)










































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)














