Downloaded 41 times




![THANK YOU FOR YOUR ATTENTION ! Jouffe Lionel Managing Director [email_address] Craignou Fabien Data Mining Department Manager [email_address]](https://image.slidesharecdn.com/reperes-sensometrics-08-driver-studies-using-bayesian-networks-1217332975407558-8/75/Reperes-Sensometrics-08-Driver-Studies-Using-Bayesian-Networks-18-2048.jpg)

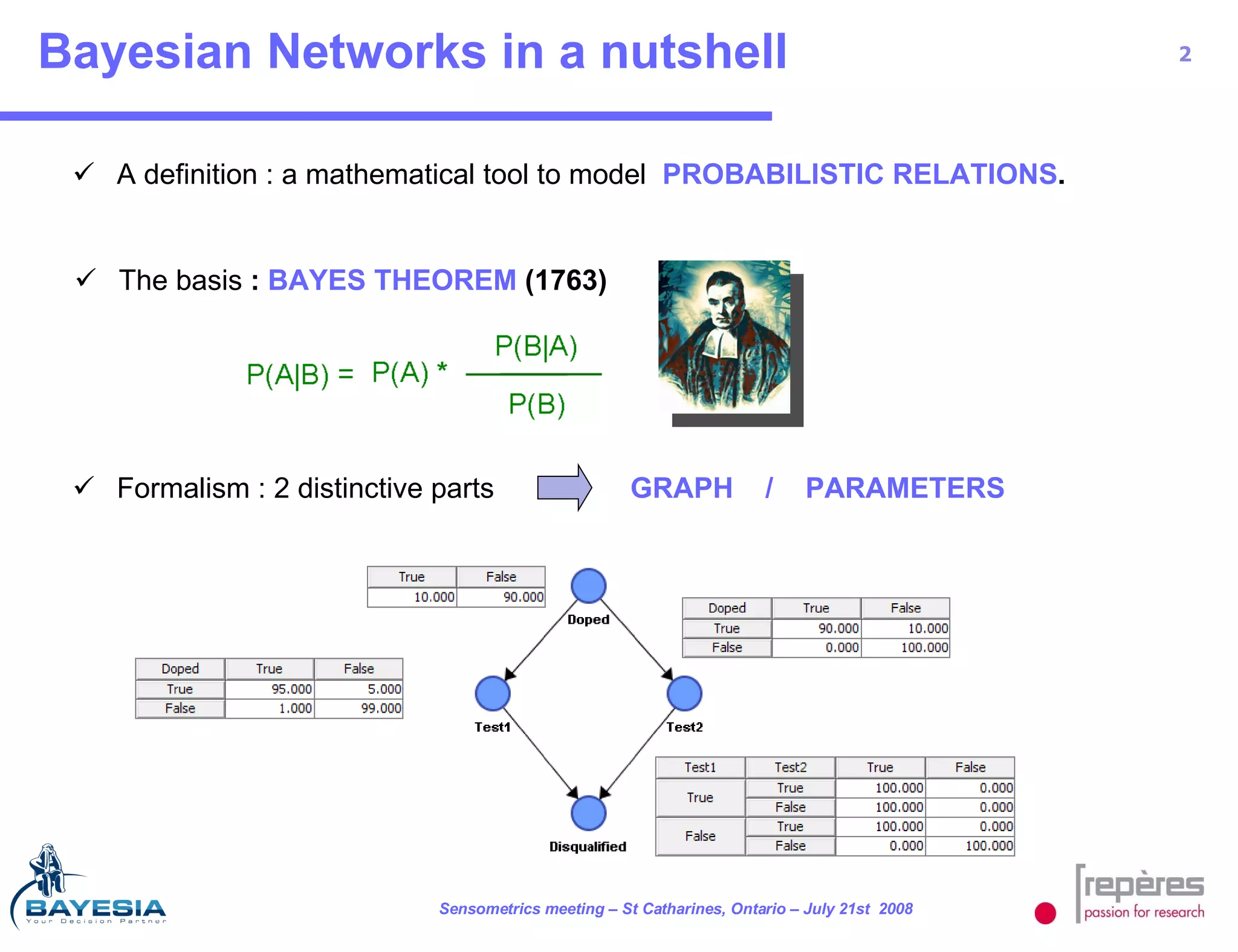
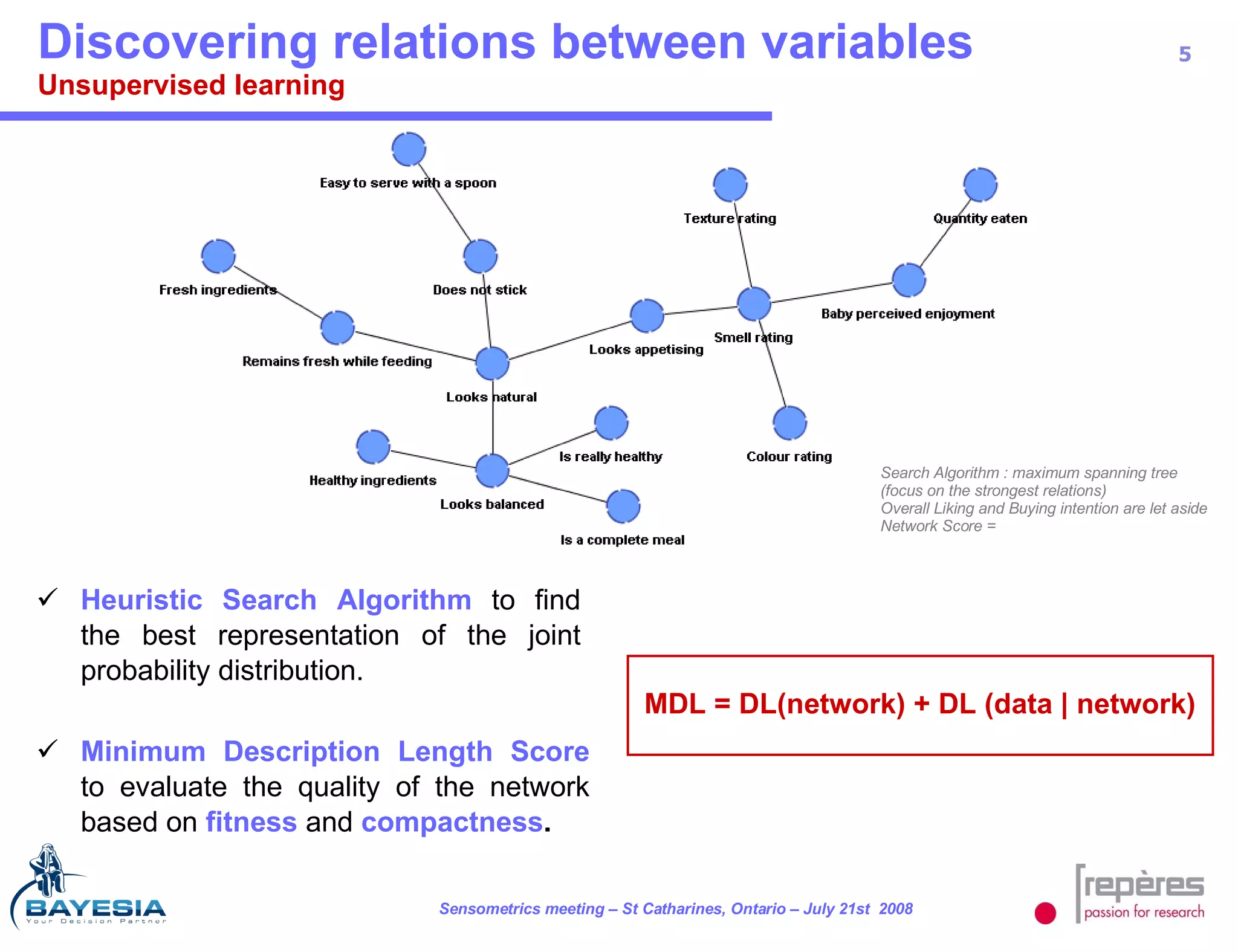
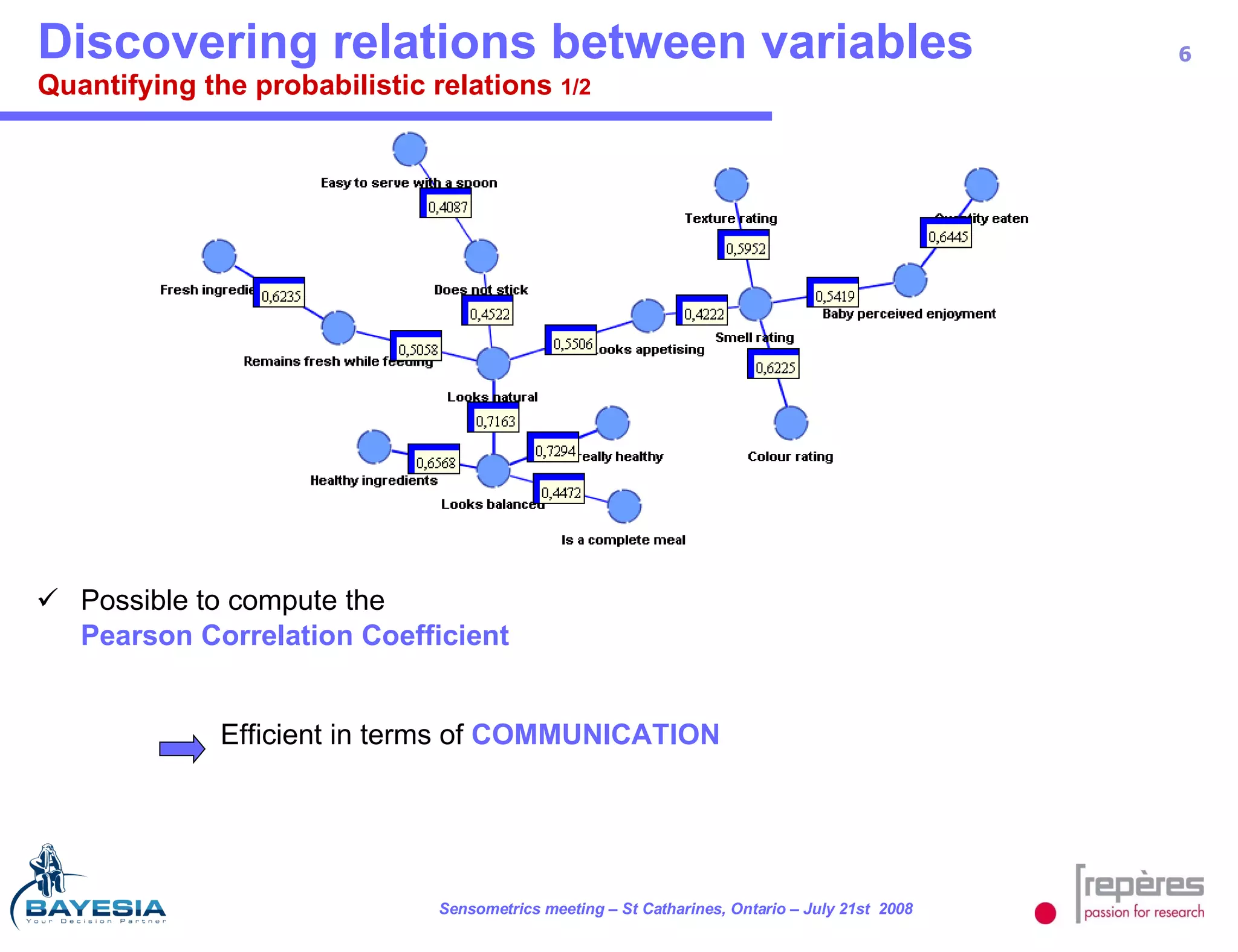
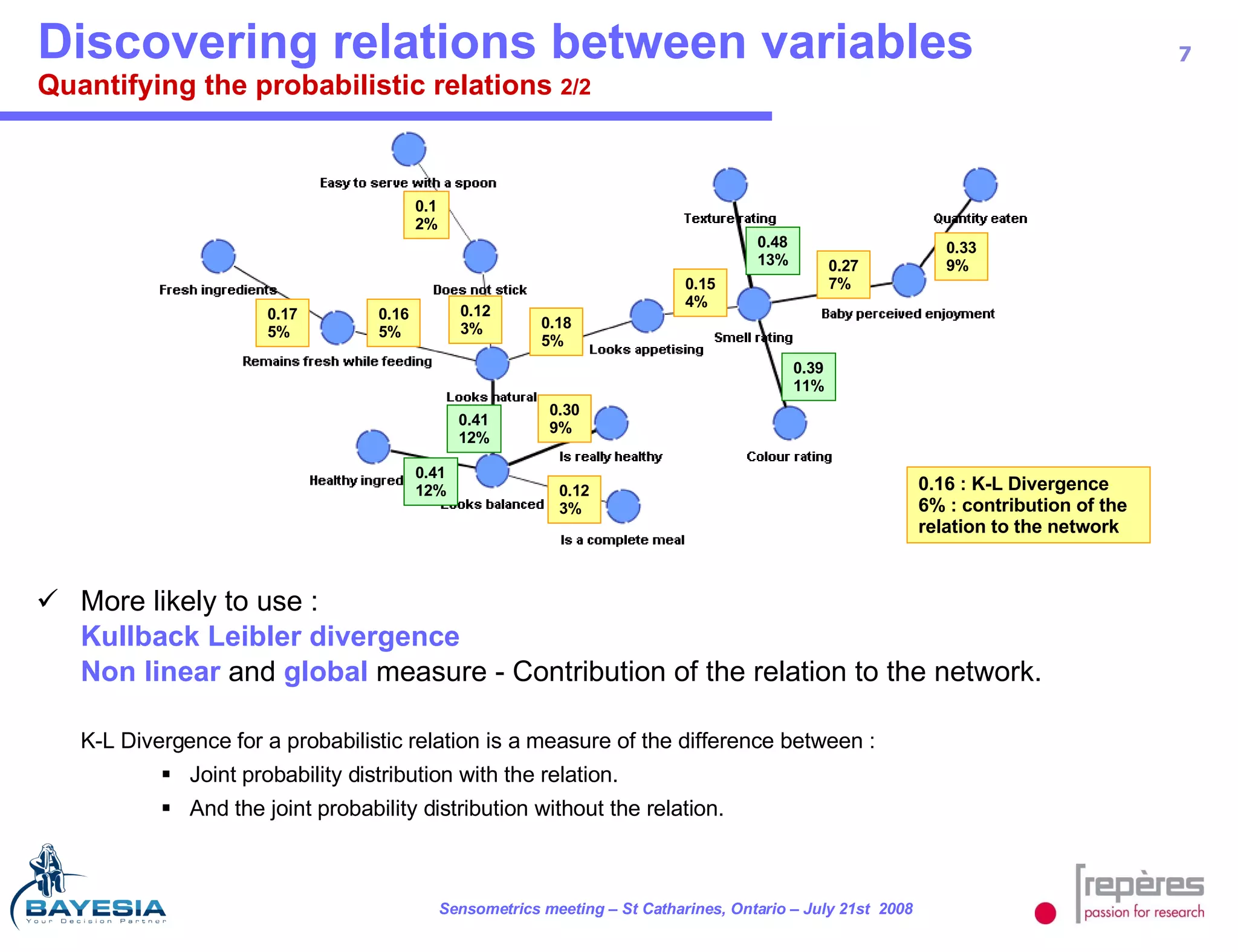
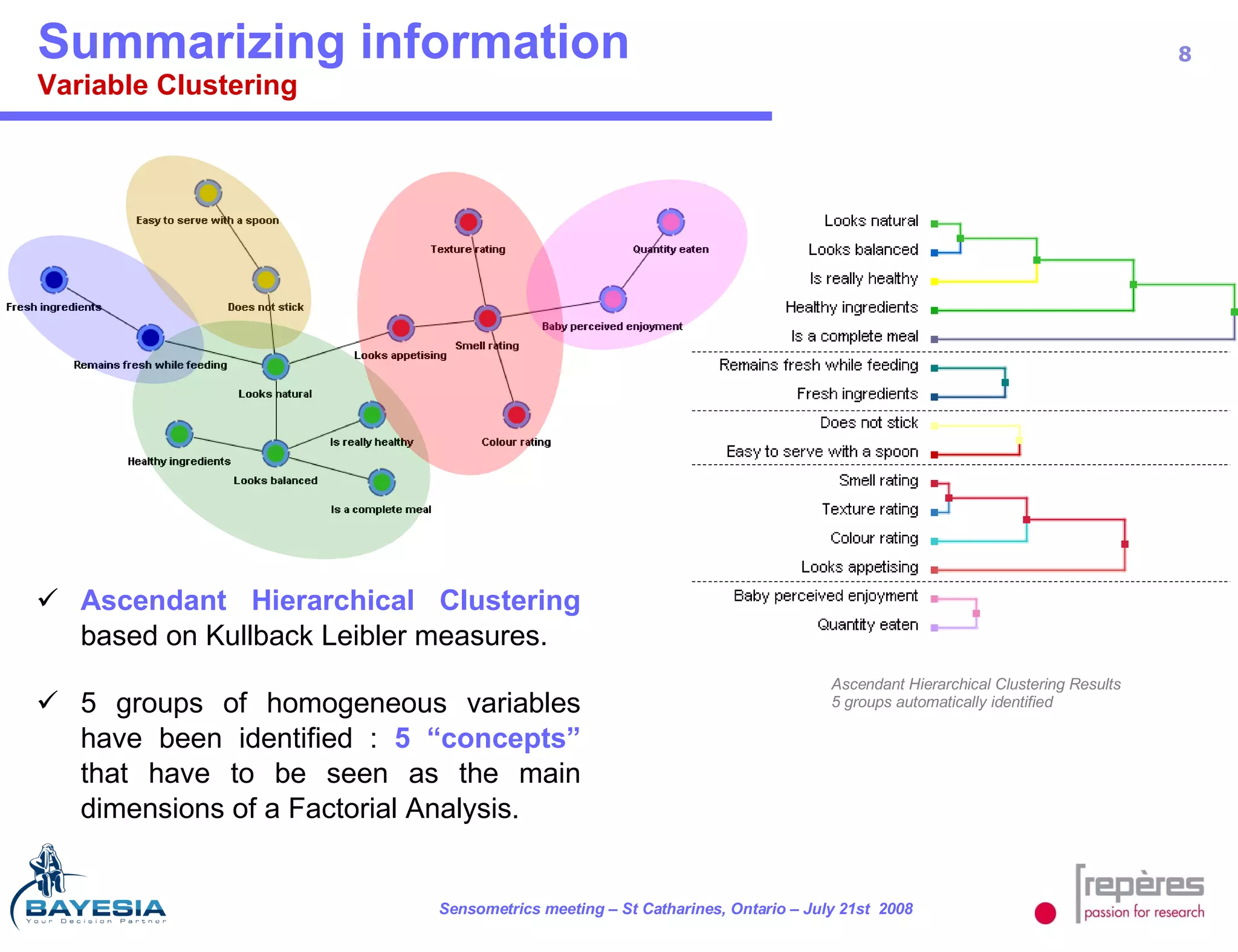
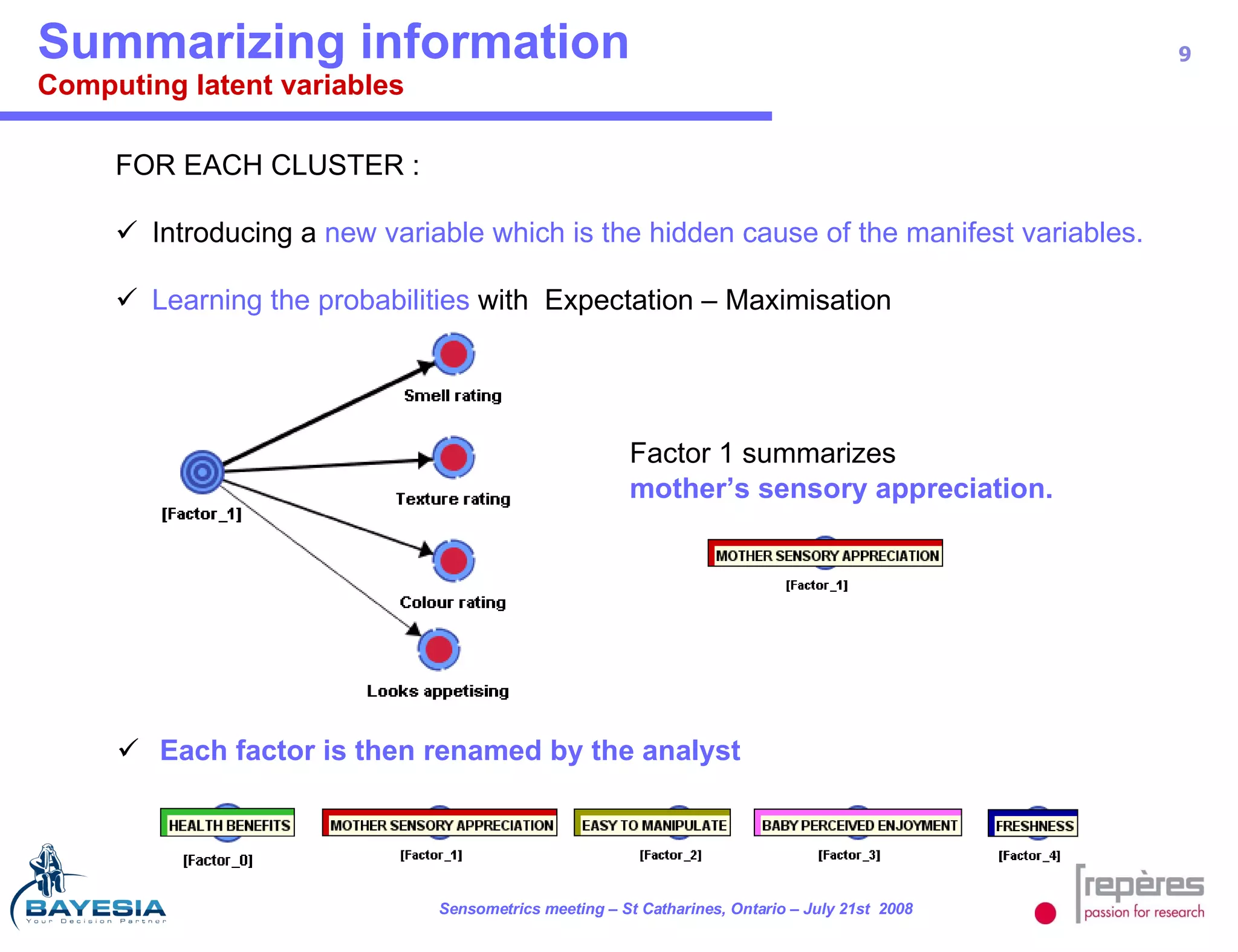
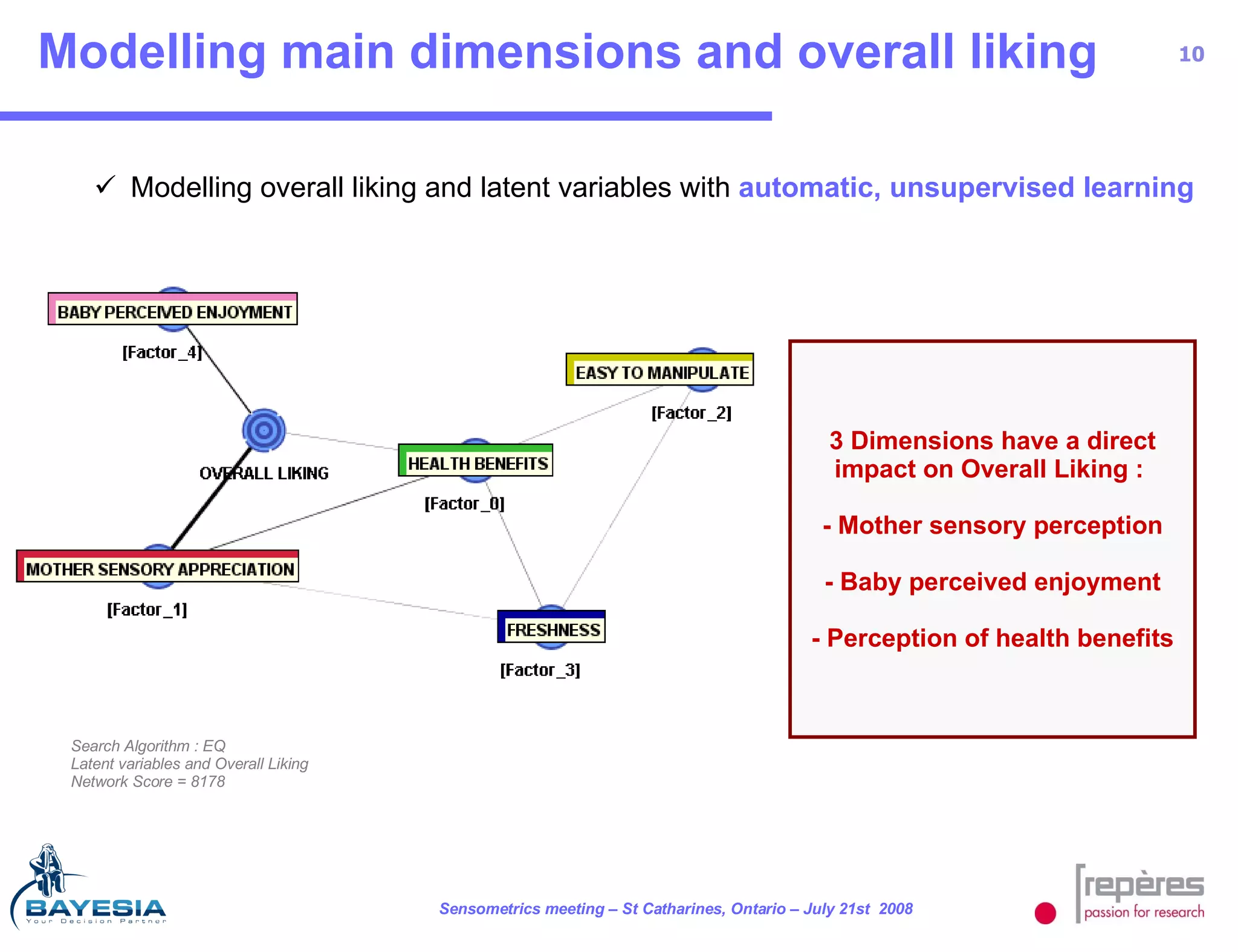
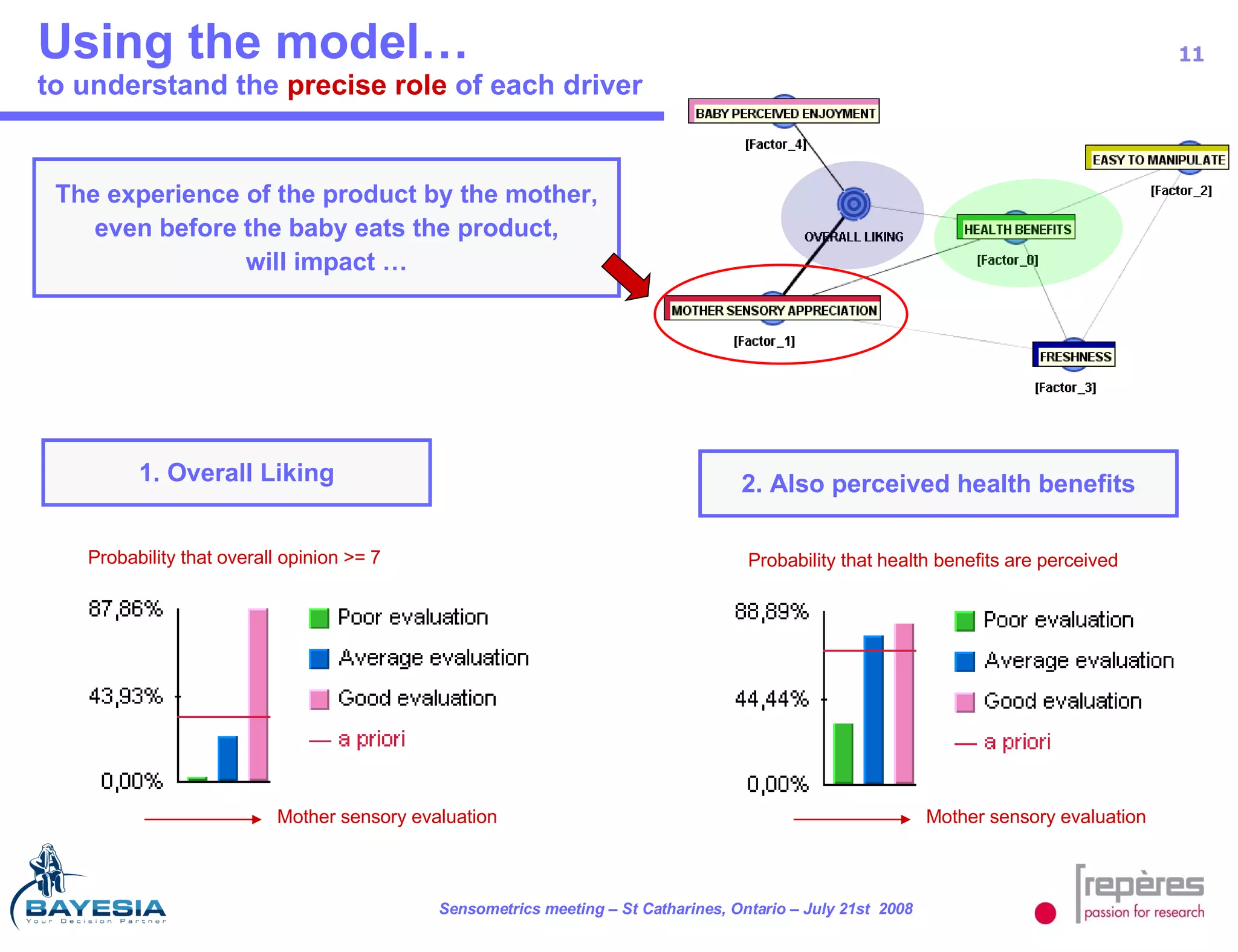
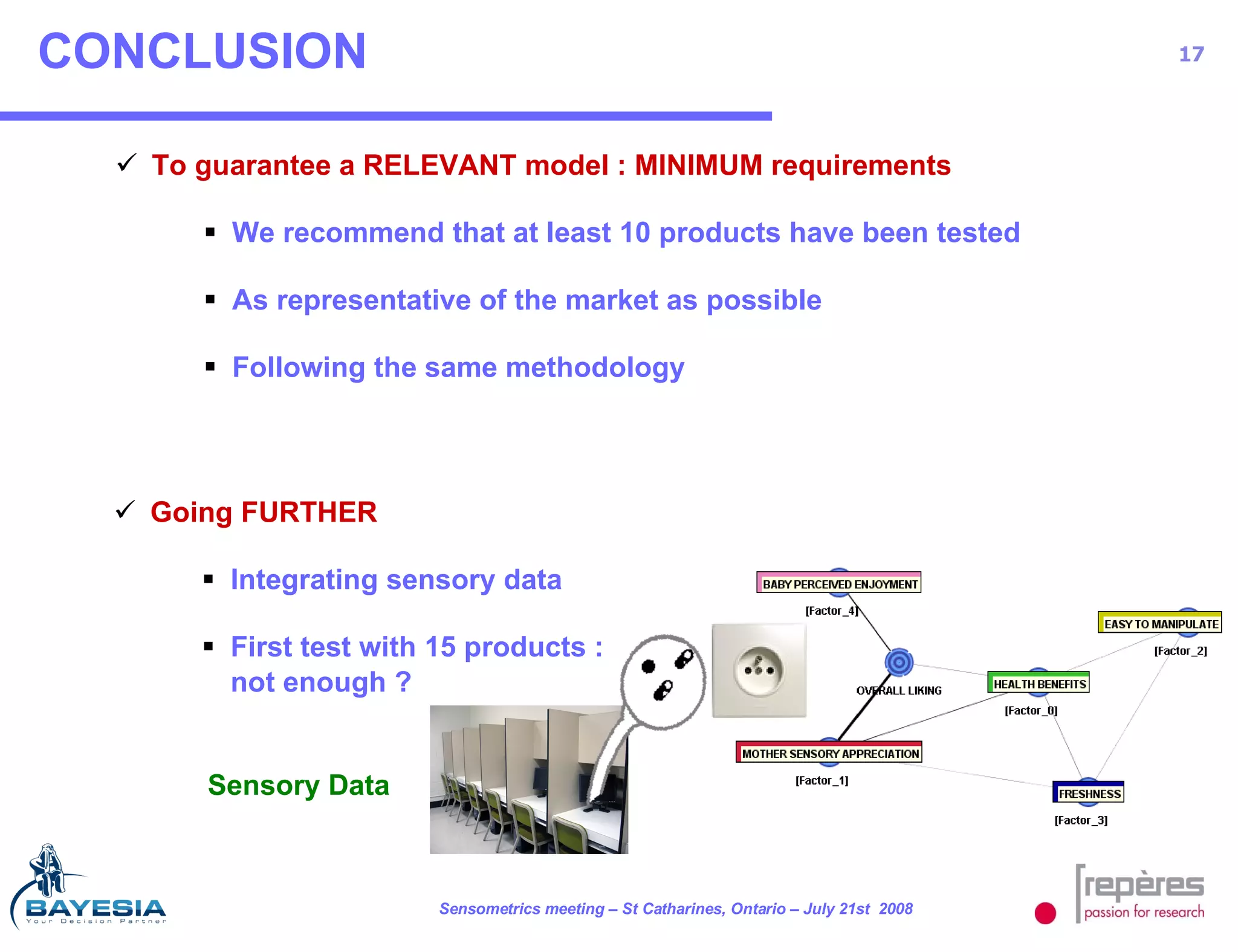
The document summarizes a study that used Bayesian networks to understand the consumer drivers of liking for baby food products. It analyzed survey data from 1770 mothers who tested 15 baby food products. The Bayesian network identified 5 key consumer dimensions that impact overall liking: 1) mother's sensory perception, 2) baby's perceived enjoyment, and 3) perception of health benefits. The model found that a mother's sensory evaluation, even before feeding the baby, impacts overall liking. Optimizing aspects like color could significantly increase the likelihood that mothers rate products positively. Validation tests confirmed the model's ability to understand and predict consumer behavior.



















































































