Downloaded 101 times
























![MSSQL Win-Back in 2010
Dual
Read/Writer
MS SQL
Application
CUBRID
Read
Write
[Step1] Dual Write
Dual
Read/Writer
MS SQL
Application
CUBRID
ReadWrite
[Step2] Dual Write and Read
Application
CUBRID
Read
Write
[Step3] Win-back Complete
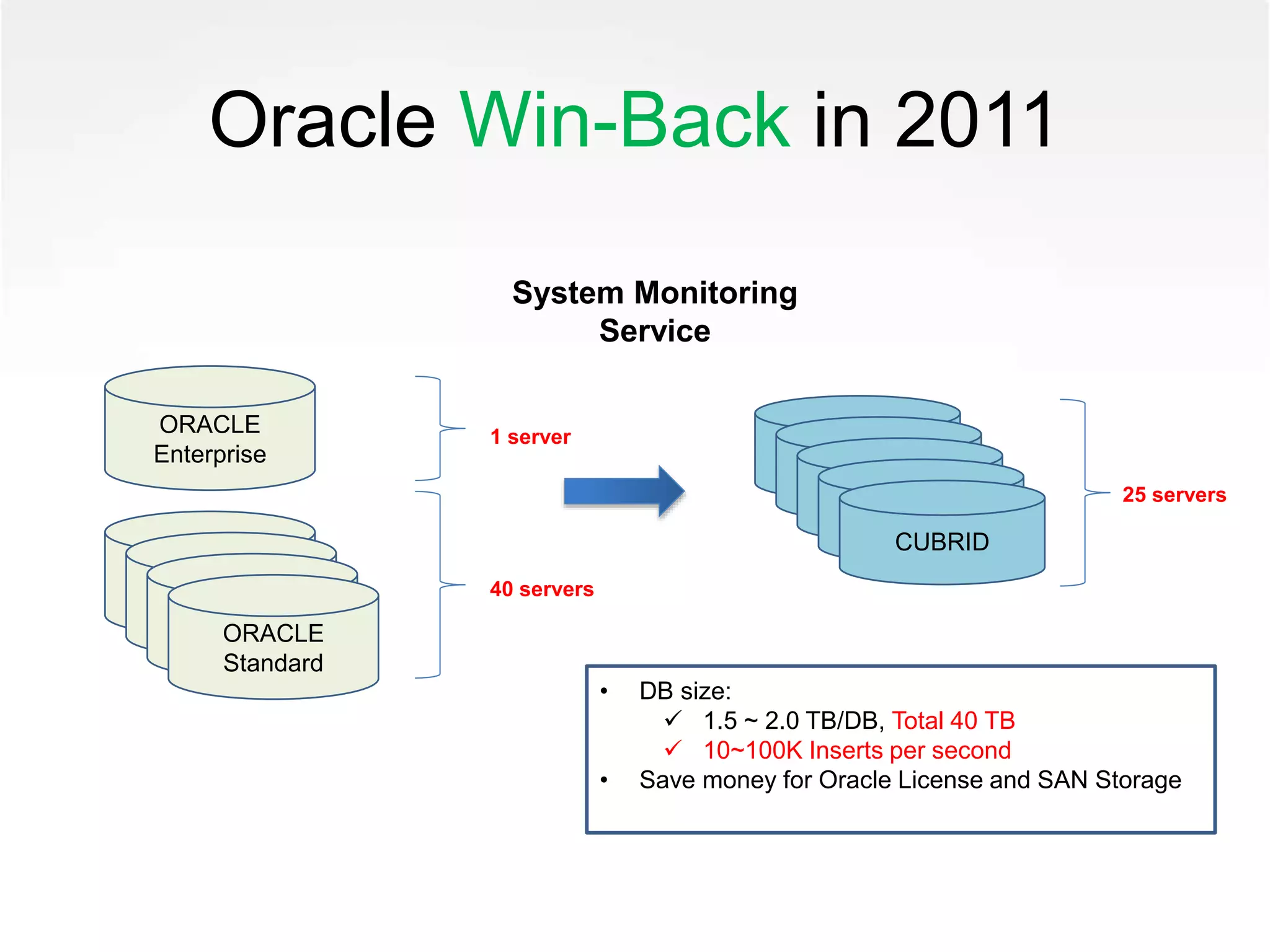
• 16 Master/Slave servers and 1 Archive server
• DB size:
0.4~0.5 billion/DB, Total 4 billion records
Total 3.2 TB
Total 4,000 ~ 5,000 QPS
• Save money for MSSQL License and SAN Storage](https://image.slidesharecdn.com/growinginthewild-thestorybycubriddatabasedevelopers-120320002758-phpapp01/75/Growing-in-the-Wild-The-story-by-CUBRID-Database-Developers-45-2048.jpg)


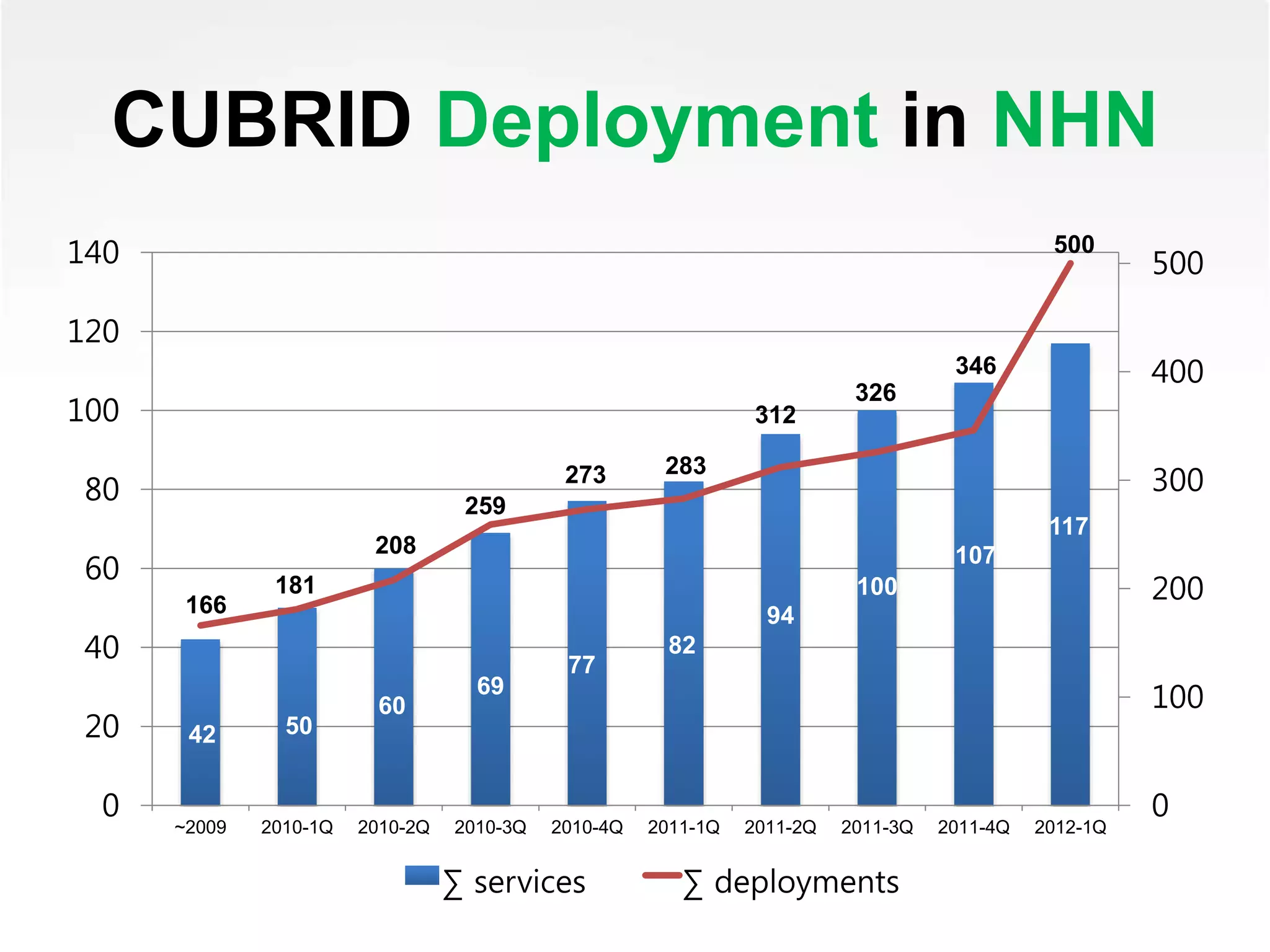
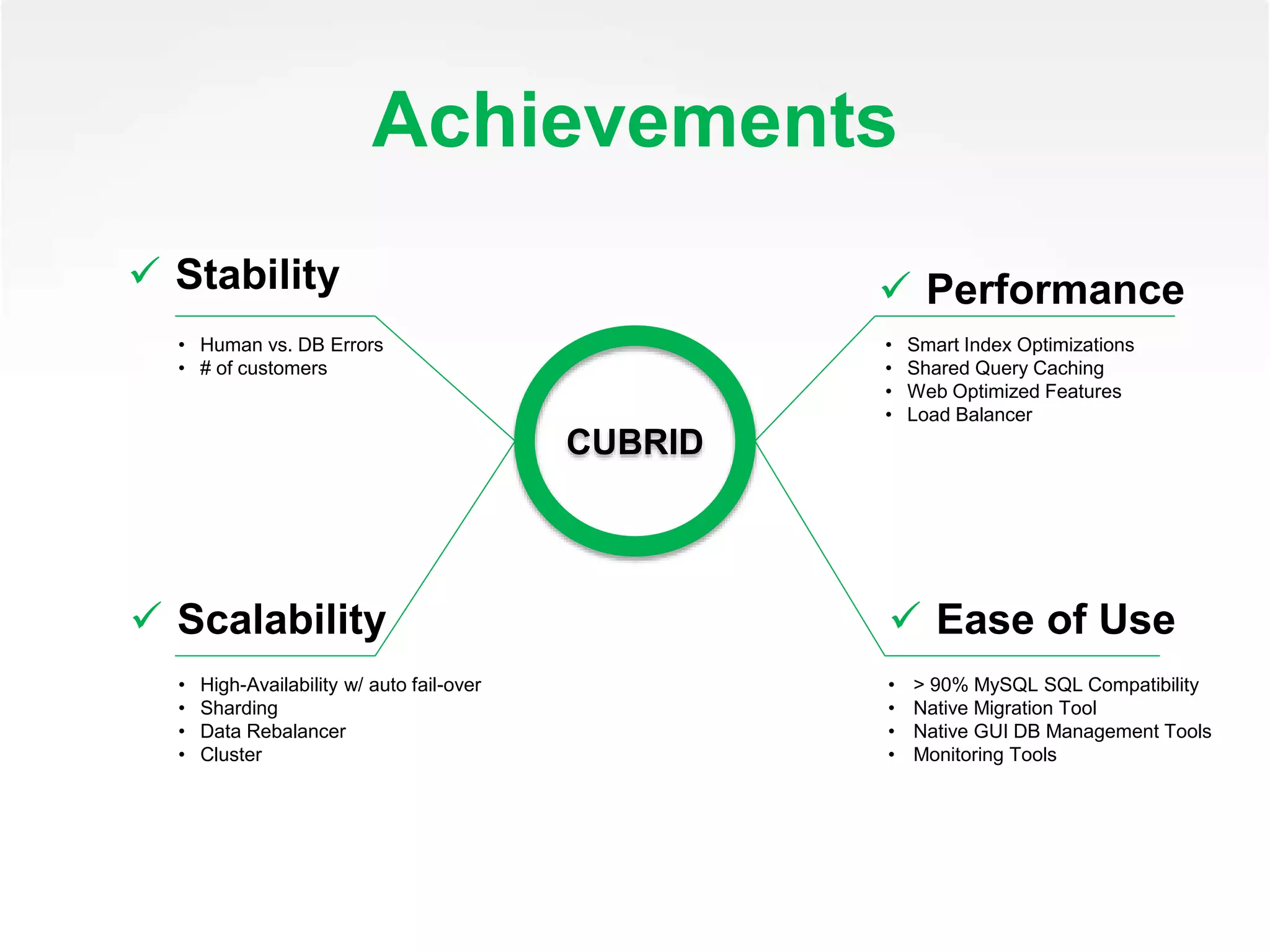
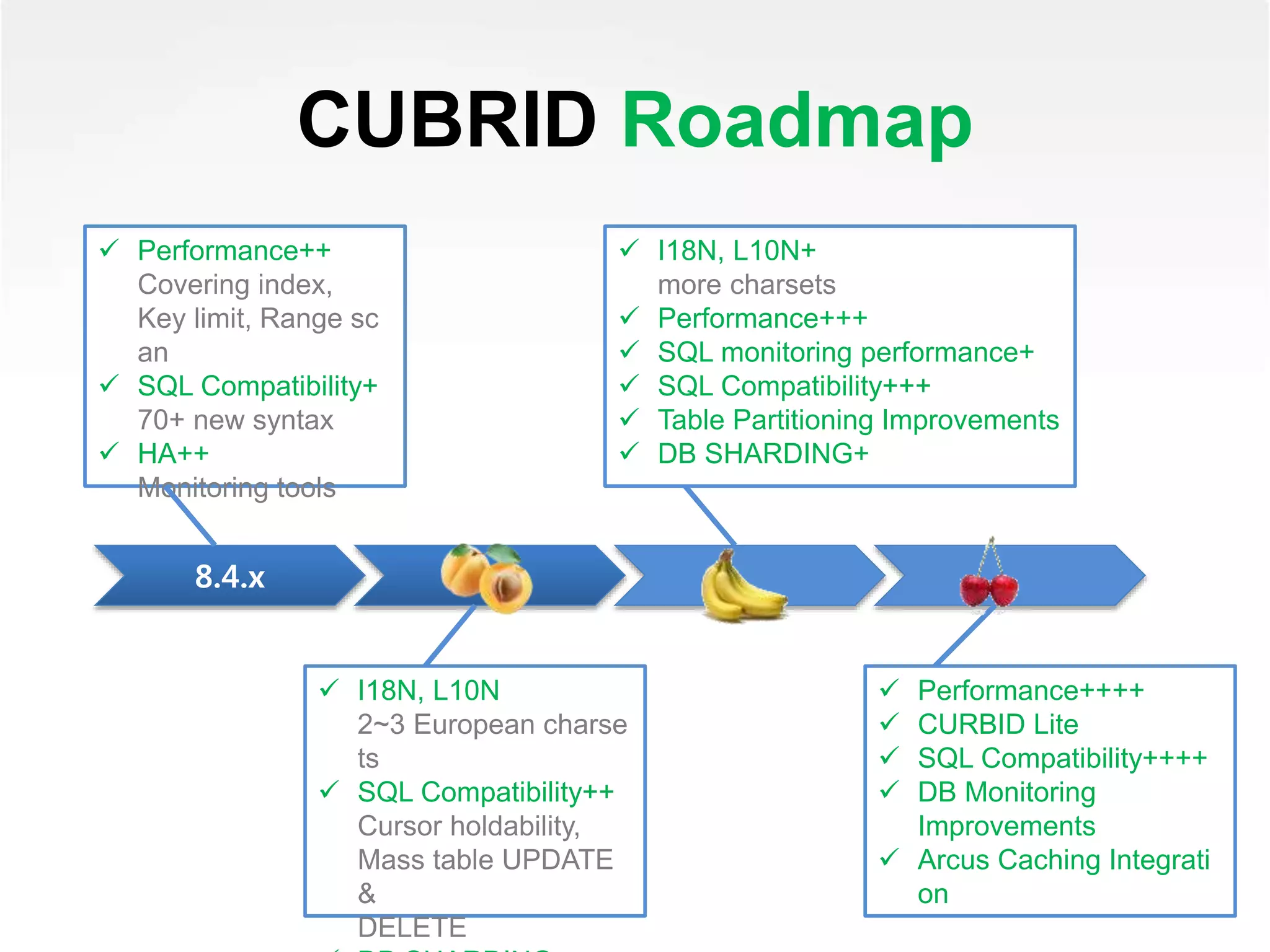



The presentation discusses the development and advantages of Cubrid, an open-source relational database management system optimized for web services. Key features include high performance, scalability, and support for MySQL compatible SQL syntax, along with solutions to address the limitations of existing database solutions. It outlines the roadmap for future improvements and encourages community engagement with the platform.


![[223]rye, 샤딩을 지원하는 오픈소스 관계형 dbms](https://cdn.slidesharecdn.com/ss_thumbnails/223ryedbms-171016104435-thumbnail.jpg?width=640&height=640&fit=bounds)























































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)