Download as PDF, PPTX










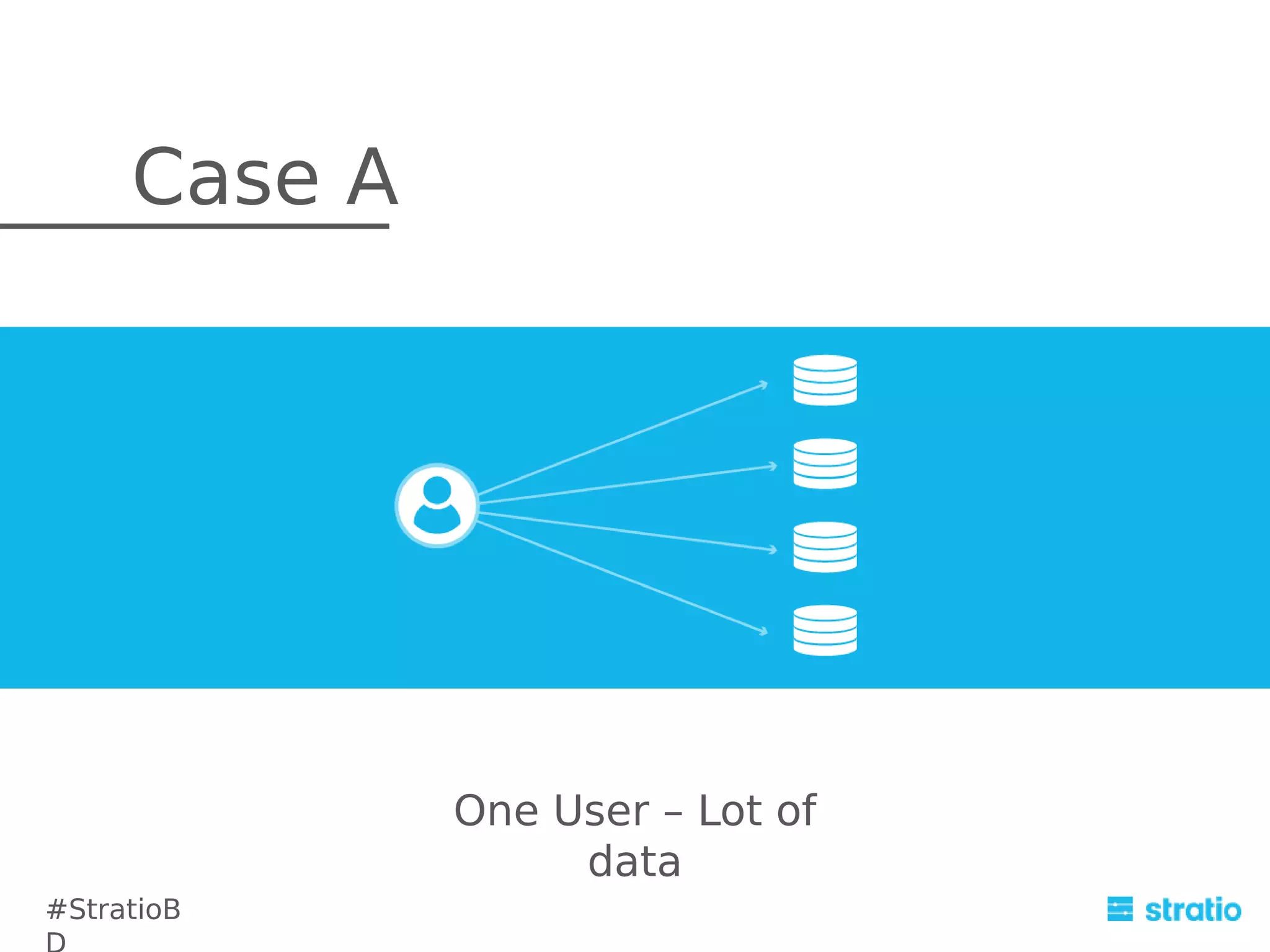
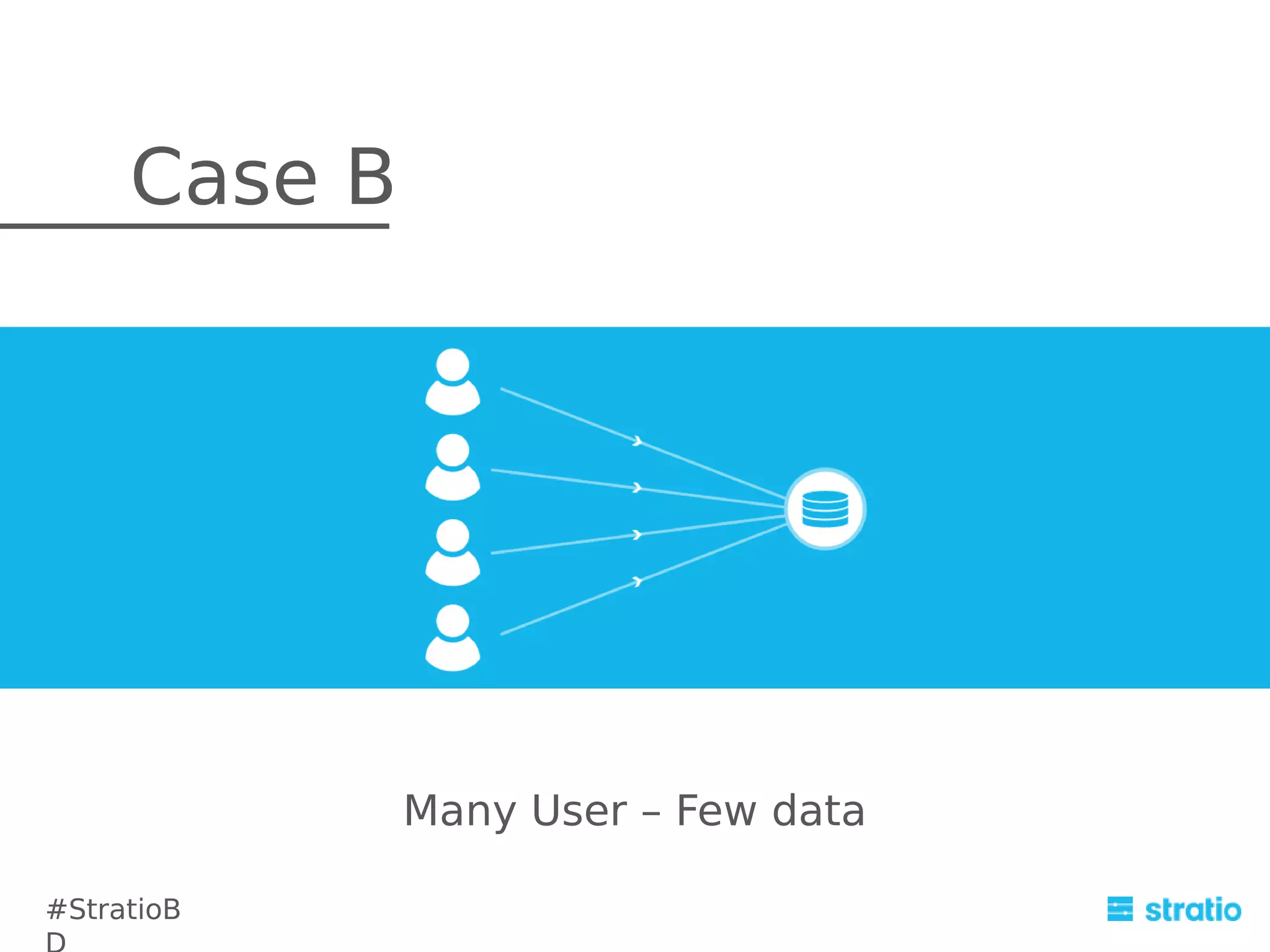
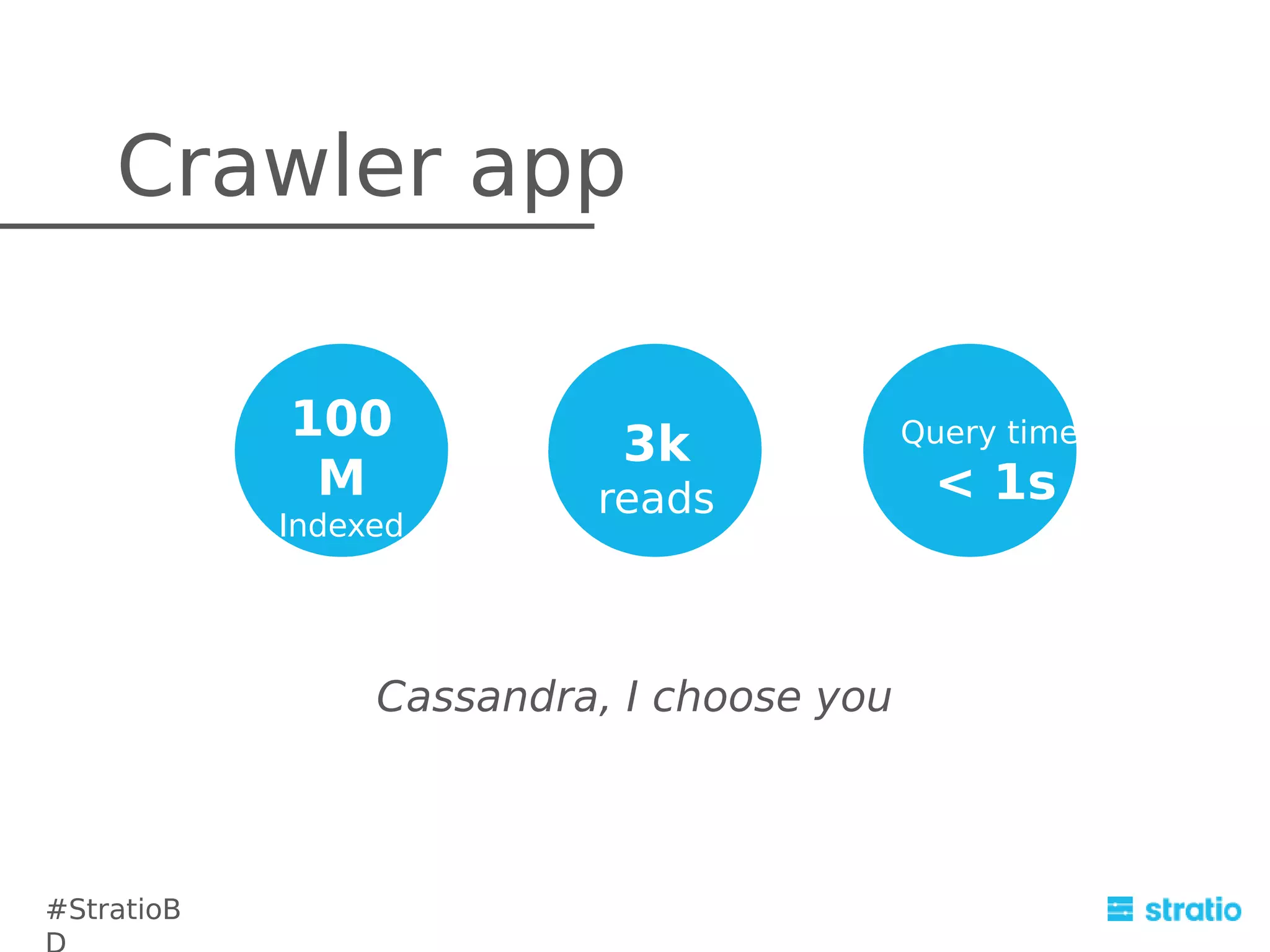









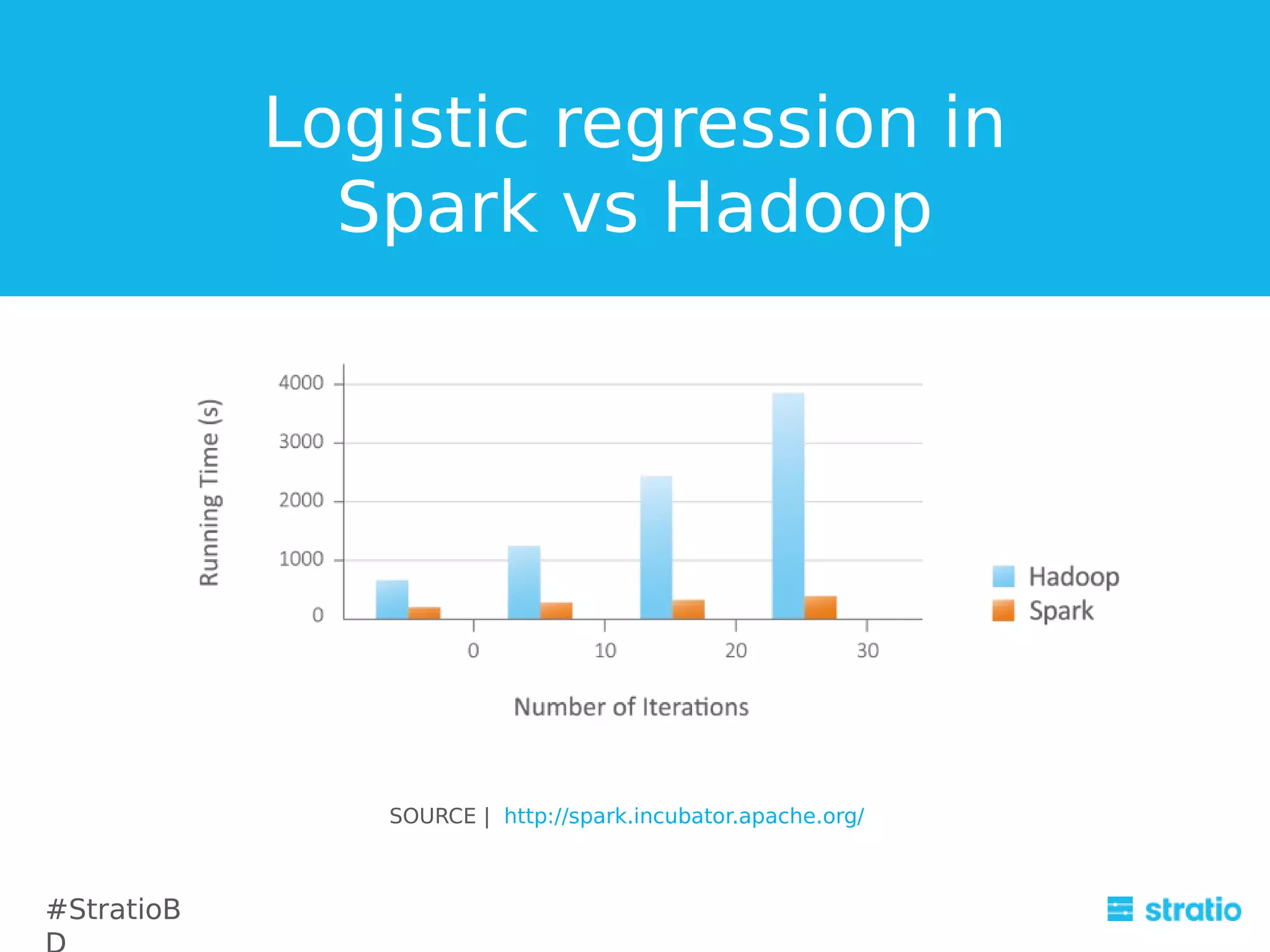










The document discusses the integration and challenges of using Cassandra and Spark for efficient data mining solutions. It highlights Cassandra's strengths and weaknesses in handling queries, and proposes alternative solutions such as using Hive queries or ETL scripts. The document also covers the advantages and drawbacks of integrating Cassandra with Spark, while suggesting future improvements for better performance.


![[Strata] Sparkta](https://cdn.slidesharecdn.com/ss_thumbnails/stratasparktav3-150507092440-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
















































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)



