Downloaded 78 times




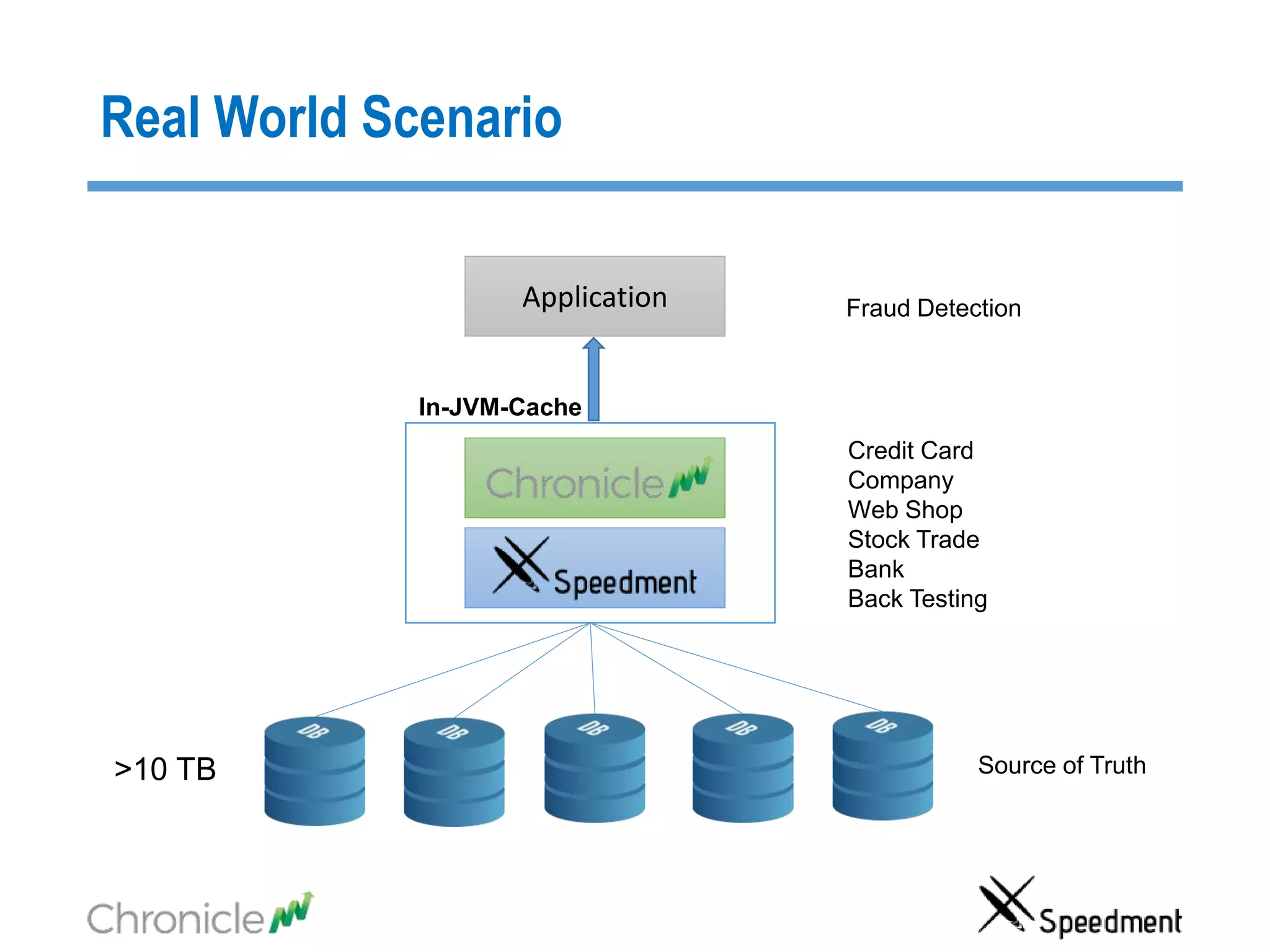



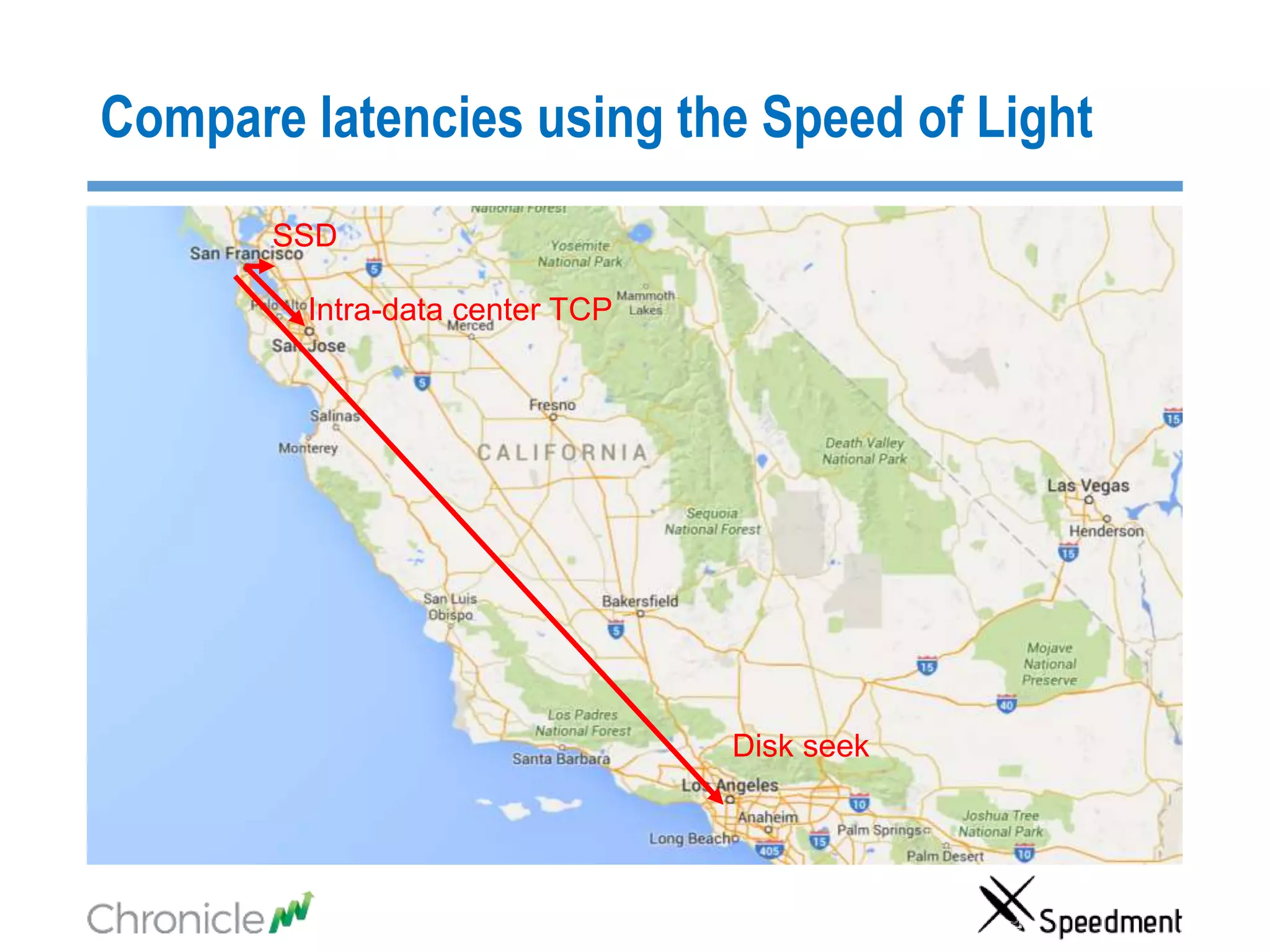


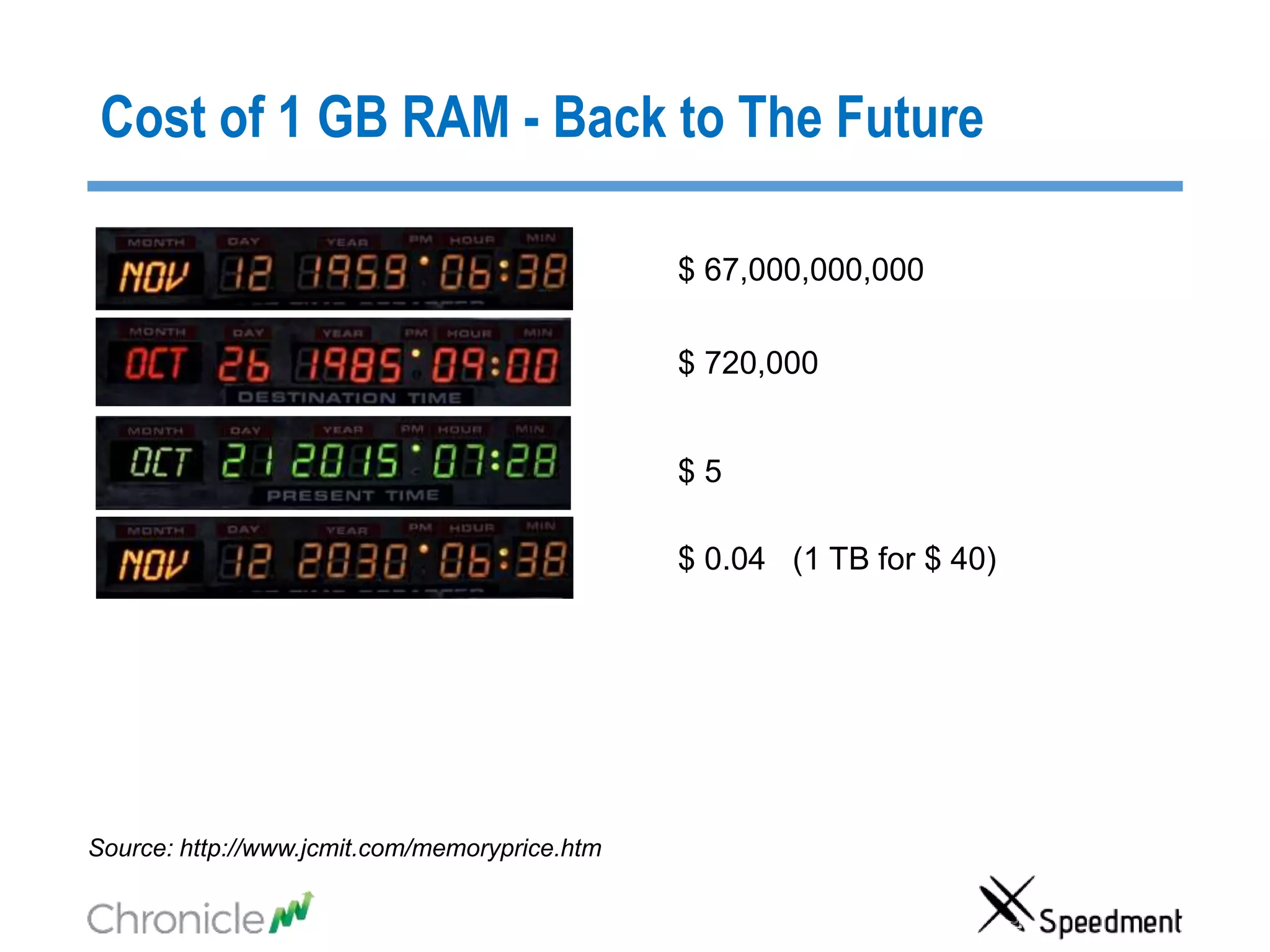




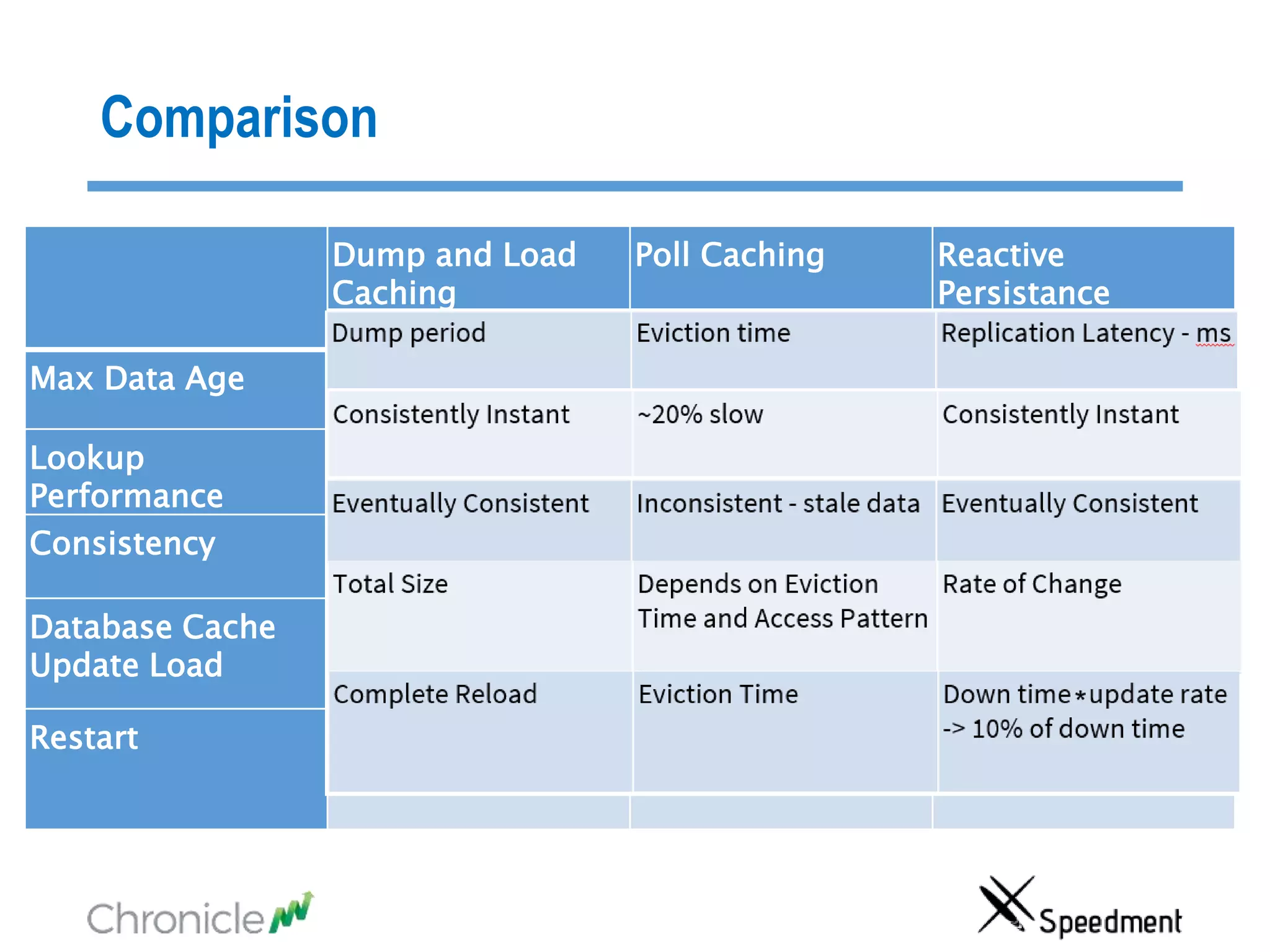
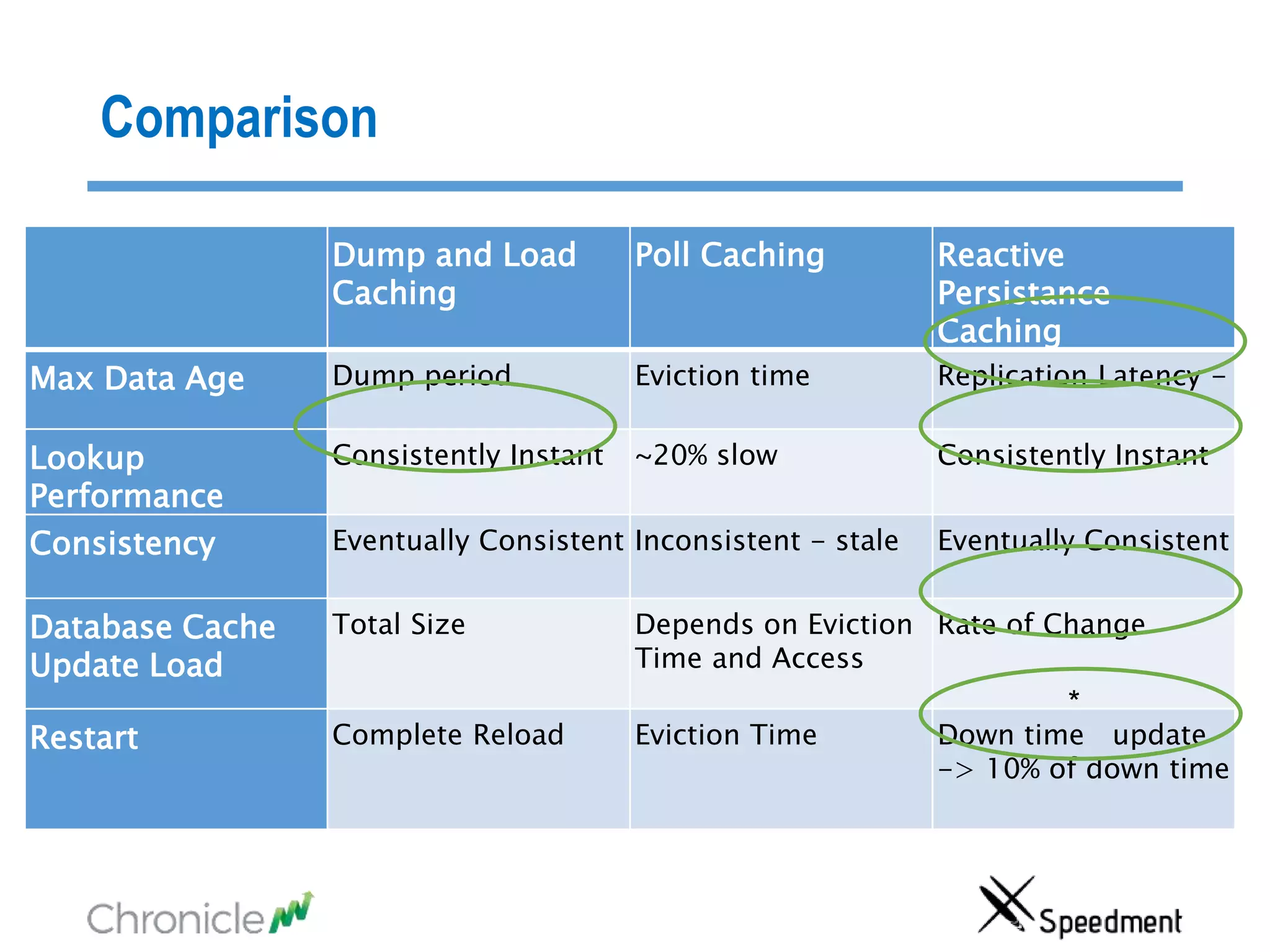




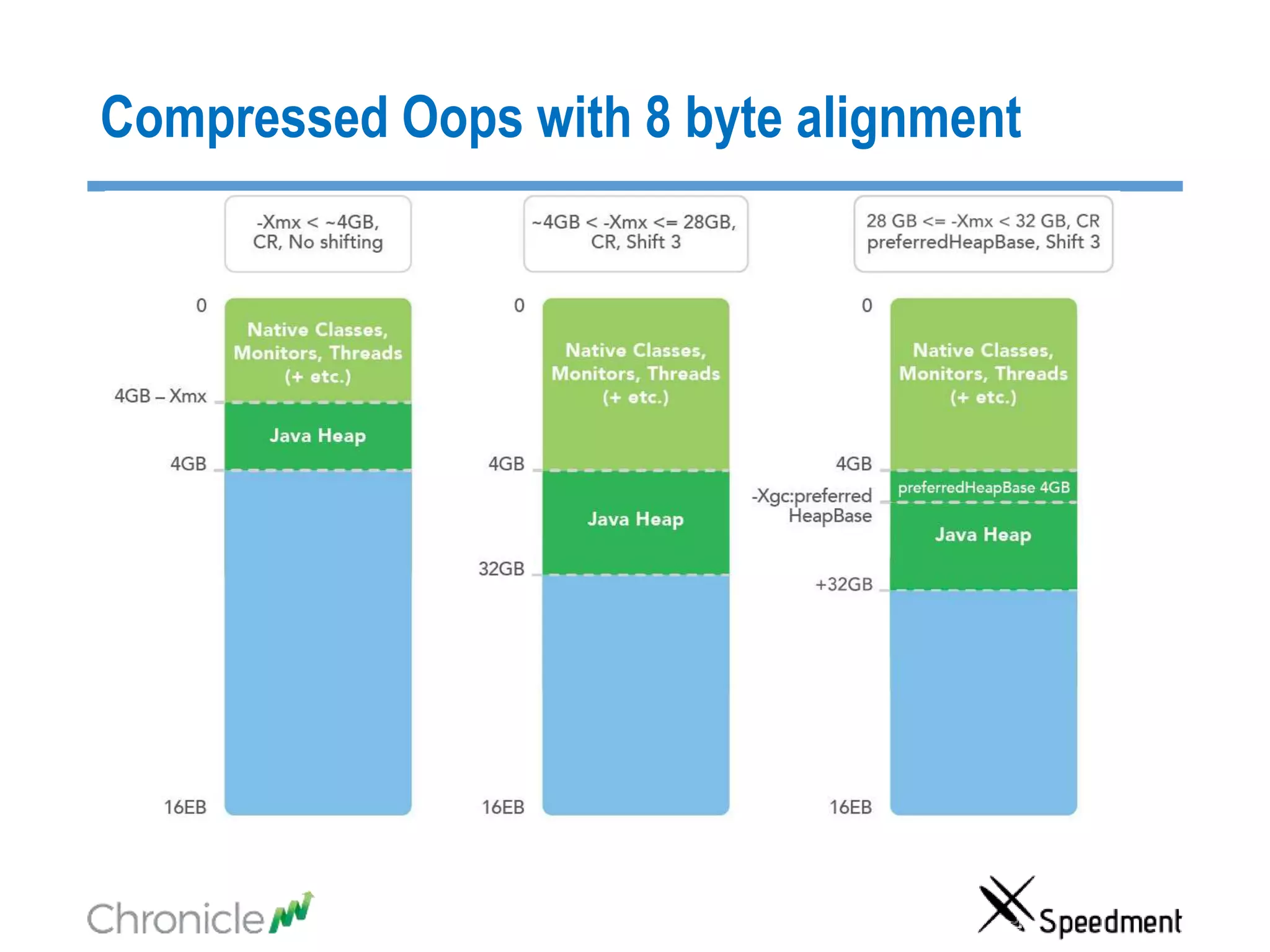



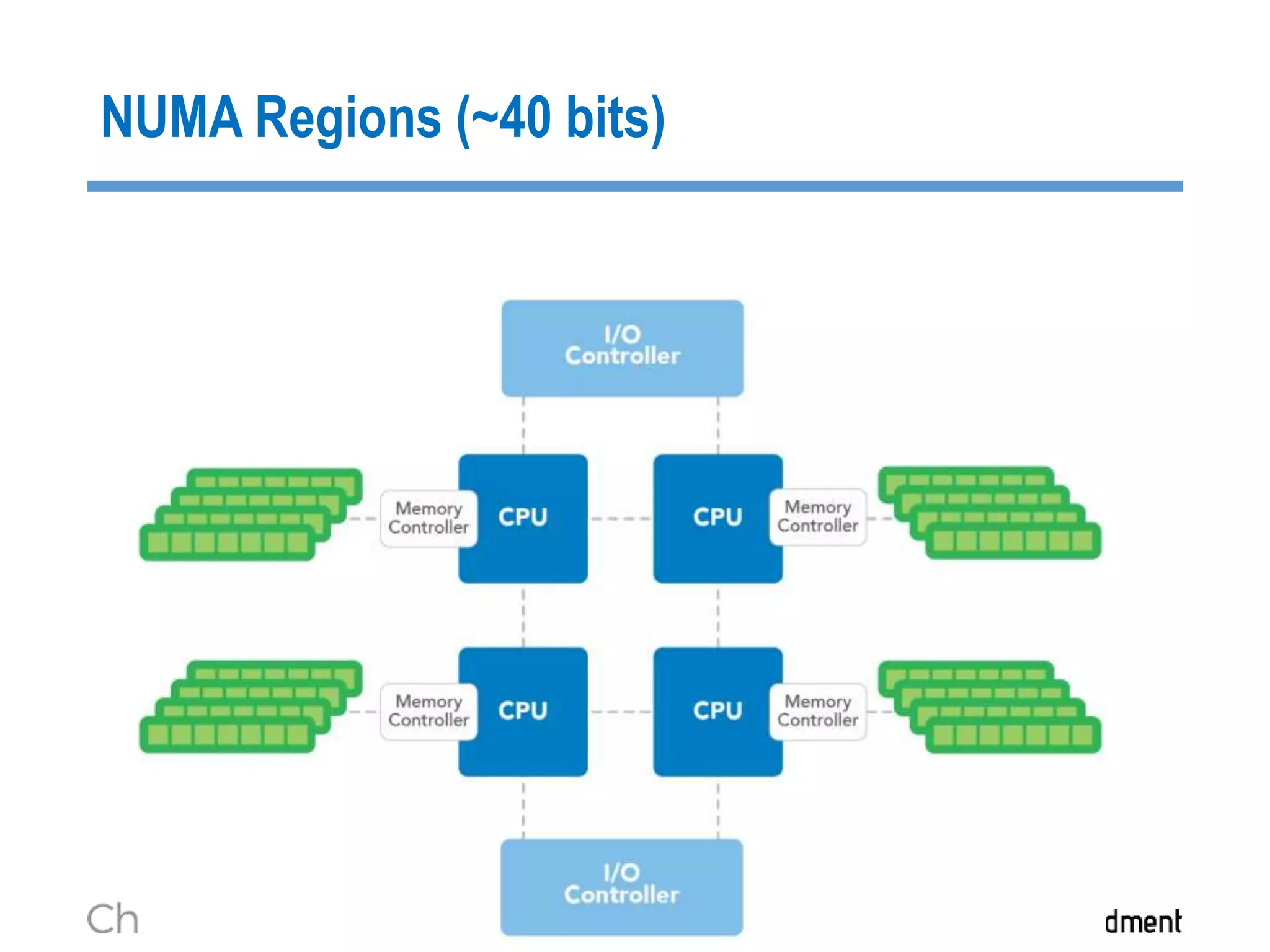
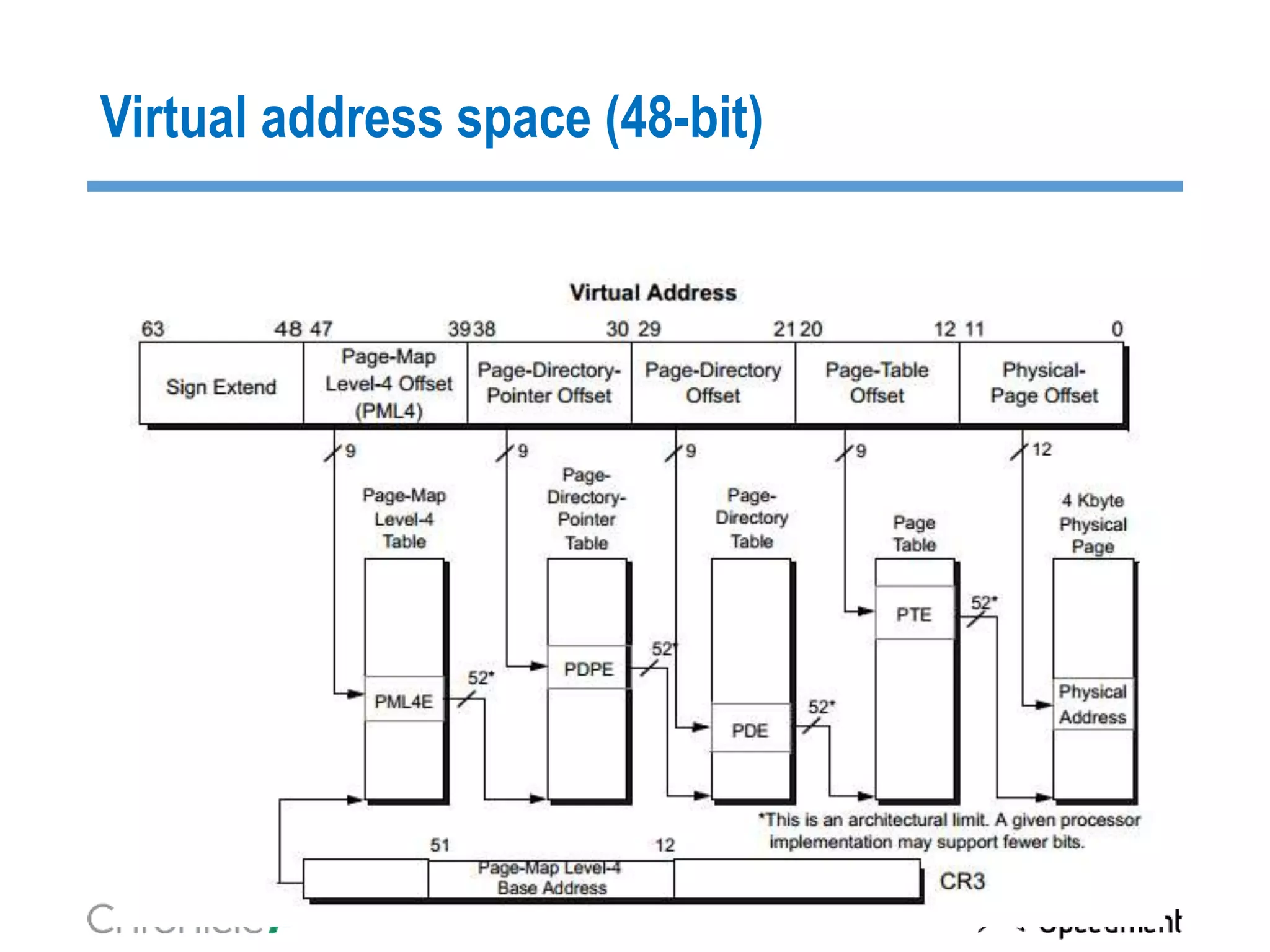
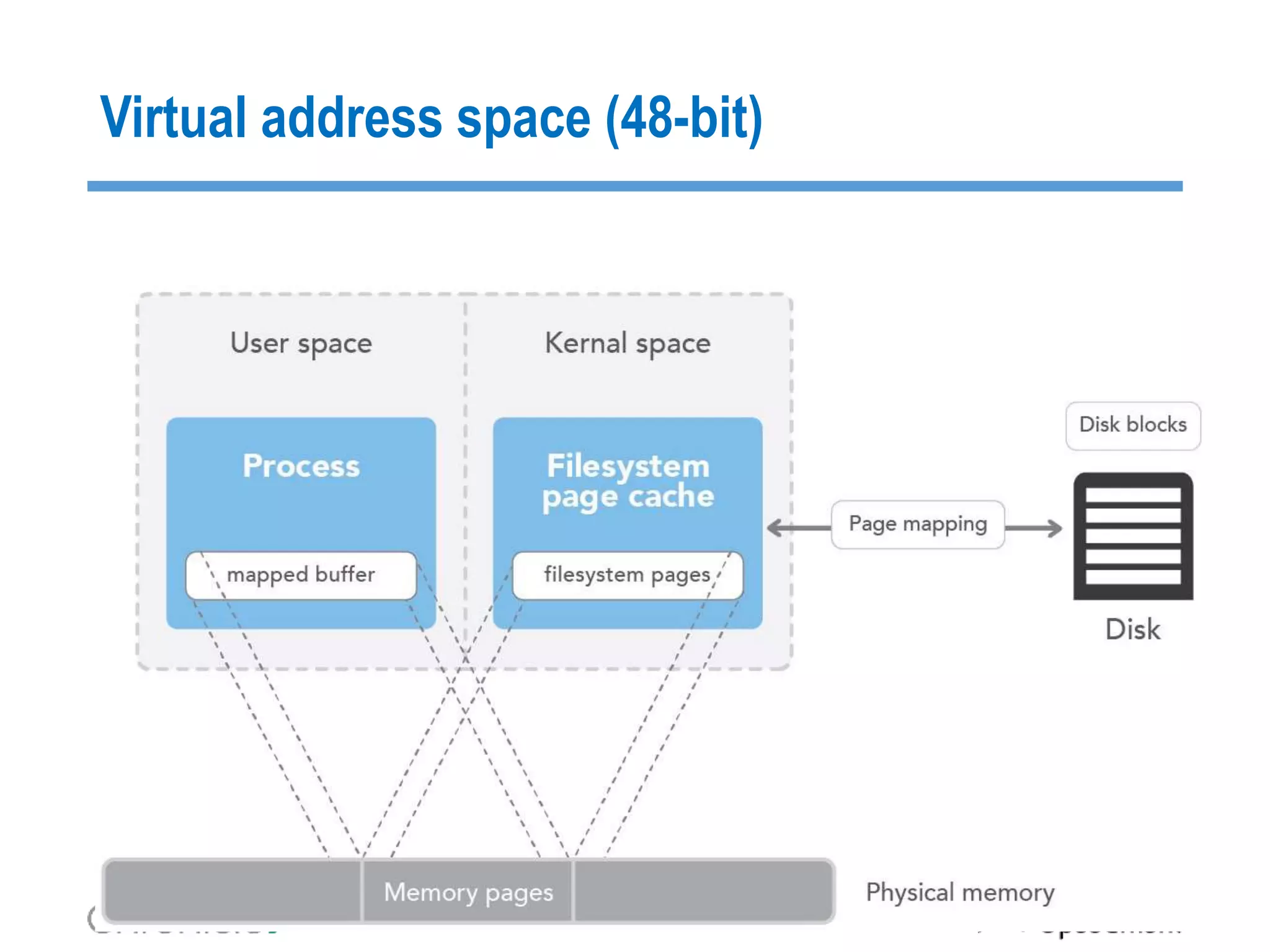


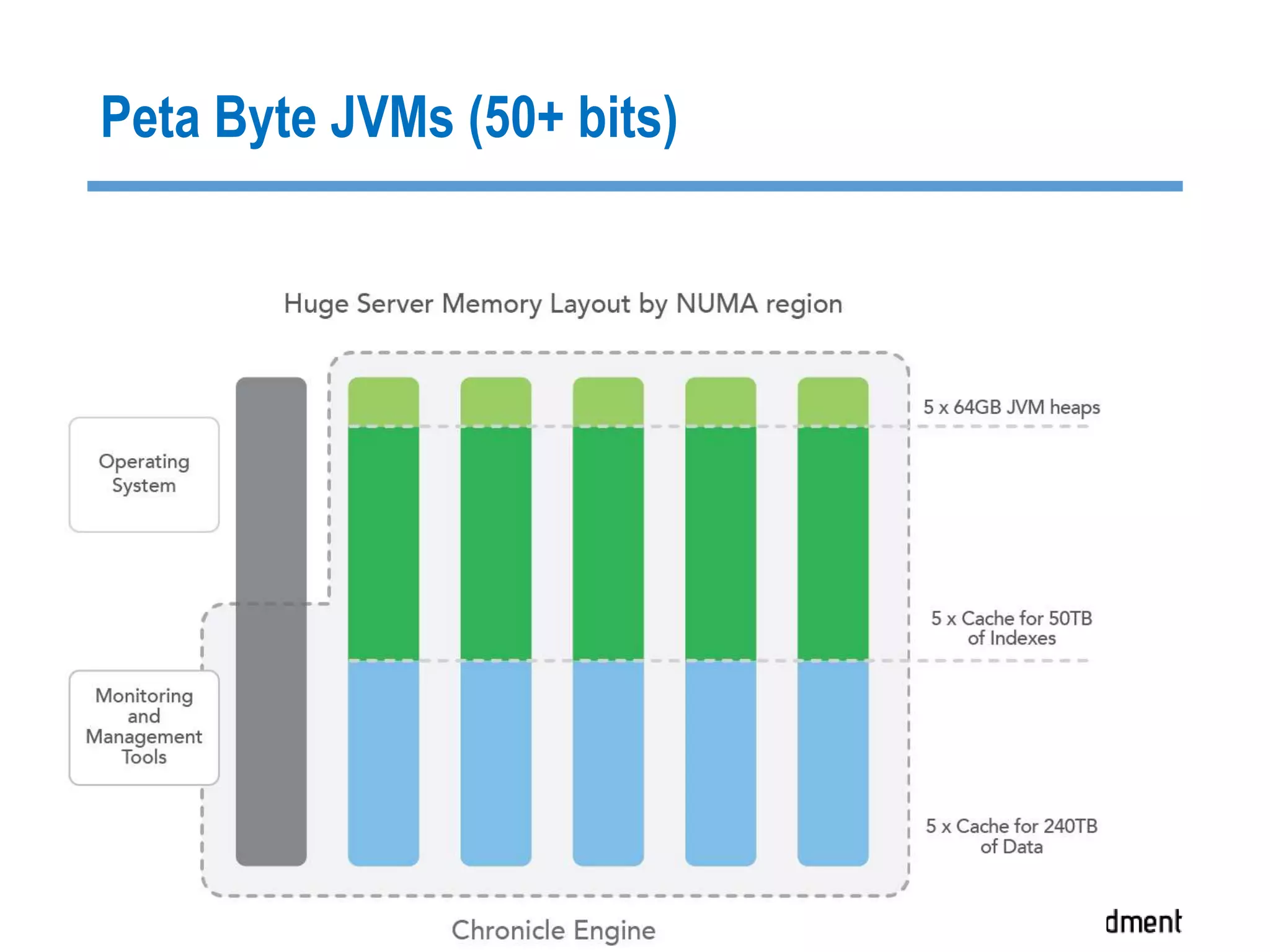
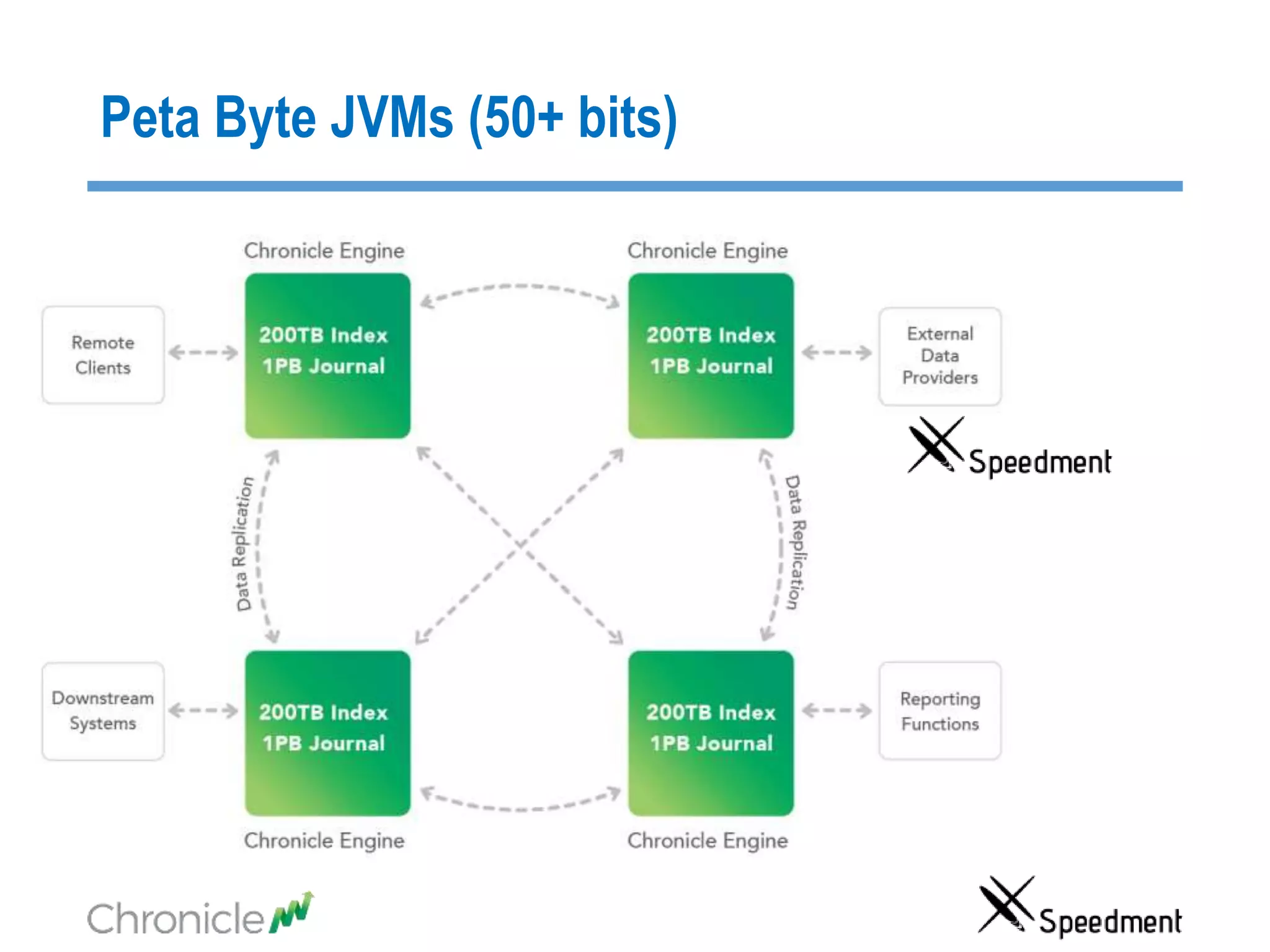




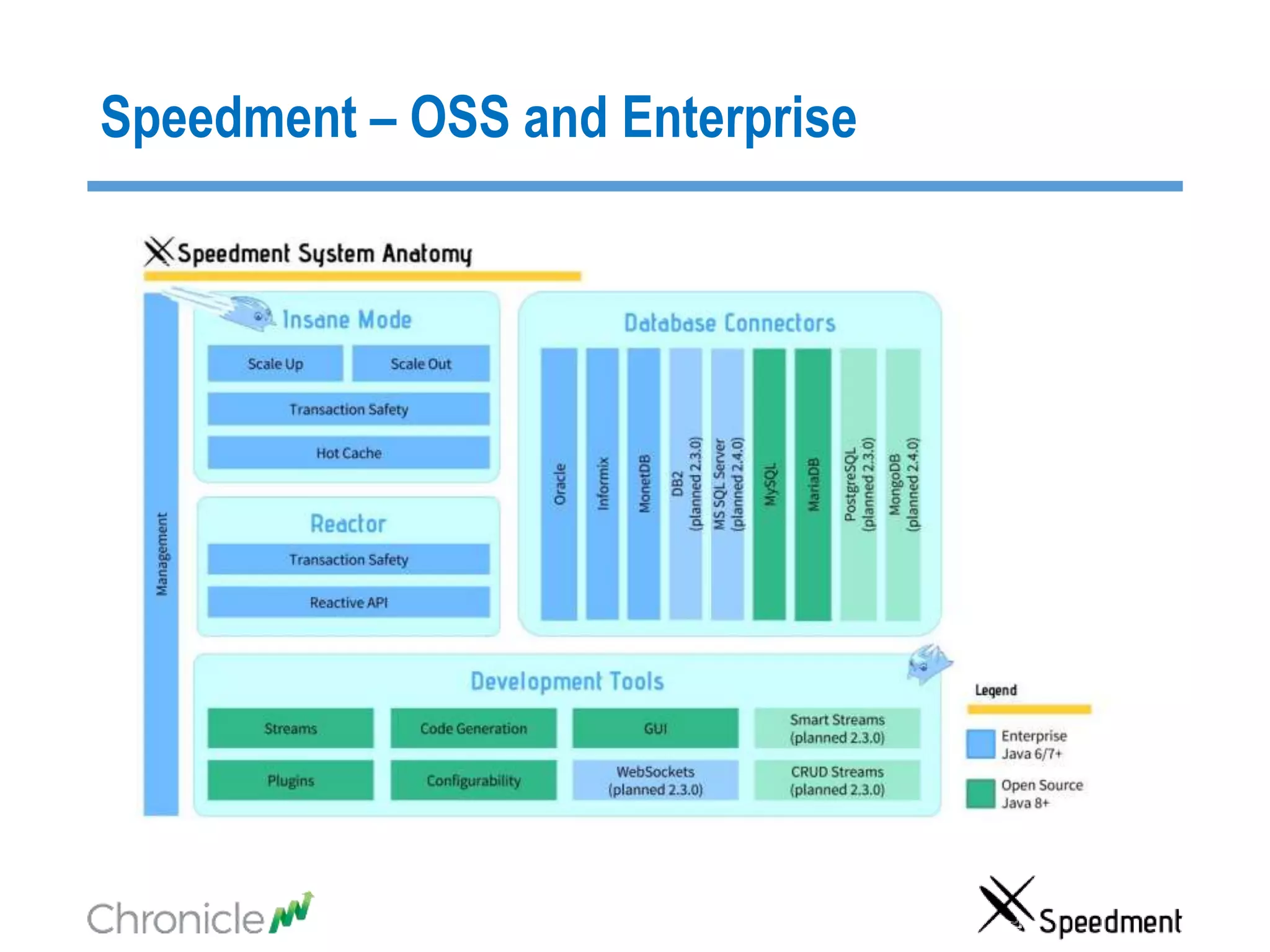




The document discusses strategies for managing big data latency and cache synchronization in JVMs, particularly focusing on in-memory technologies like Speedment and Chronicle. It emphasizes the importance of data locality, the decreasing cost of RAM, and techniques for efficient caching and data update management in high-frequency trading environments. Additionally, it highlights the complexities associated with handling petabyte-scale JVMs and the necessity for robust replication and recovery strategies in large systems.





























![JavaOne2016 - Microservices: Terabytes in Microseconds [CON4516]](https://cdn.slidesharecdn.com/ss_thumbnails/javaone2016microservicesfinal-160922165618-thumbnail.jpg?width=640&height=640&fit=bounds)
![JavaOne2016 - Microservices: Terabytes in Microseconds [CON4516]](https://cdn.slidesharecdn.com/ss_thumbnails/javaone2016microservicesfinal-160922163749-thumbnail.jpg?width=640&height=640&fit=bounds)















































