Downloaded 106 times





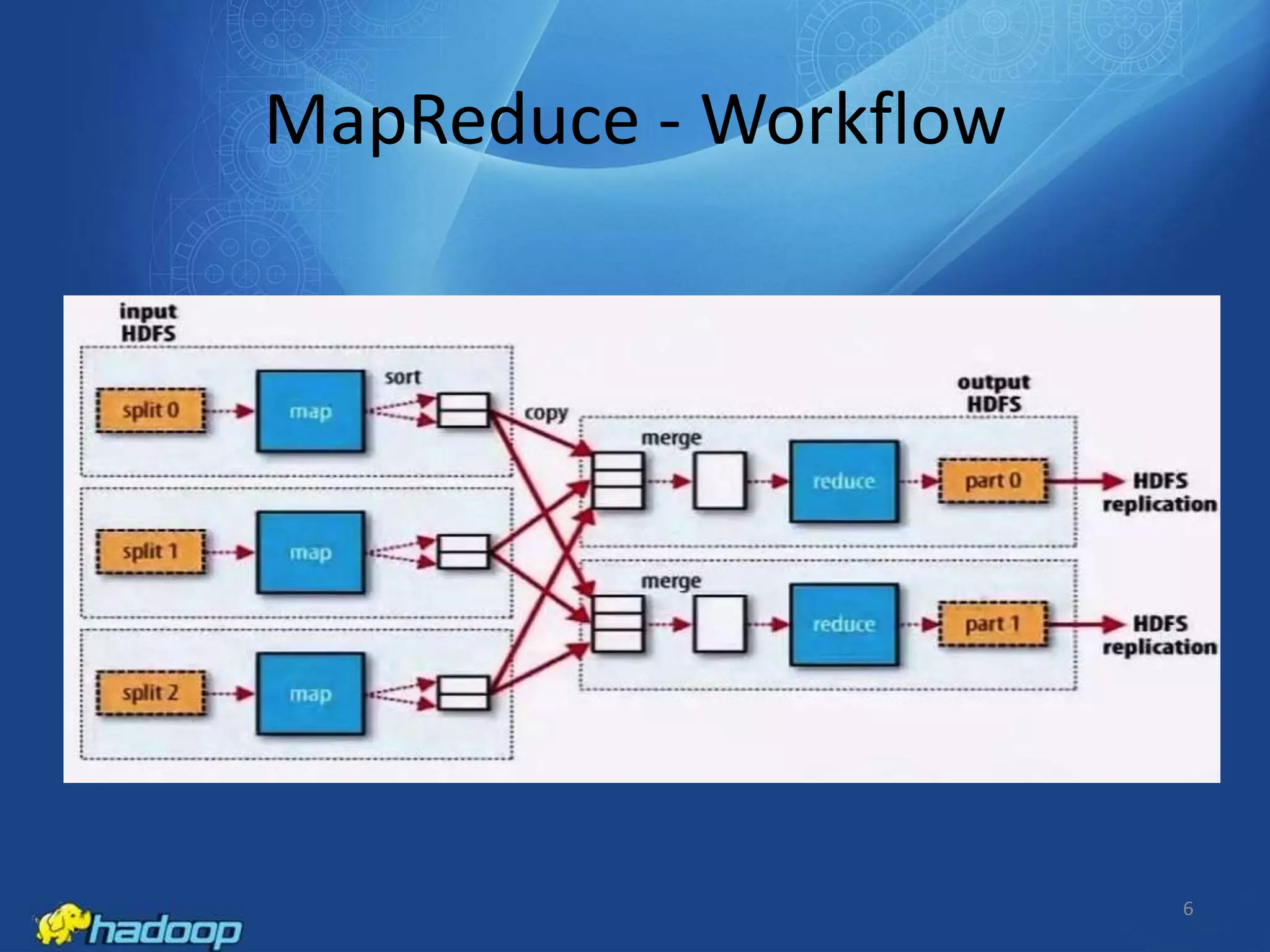
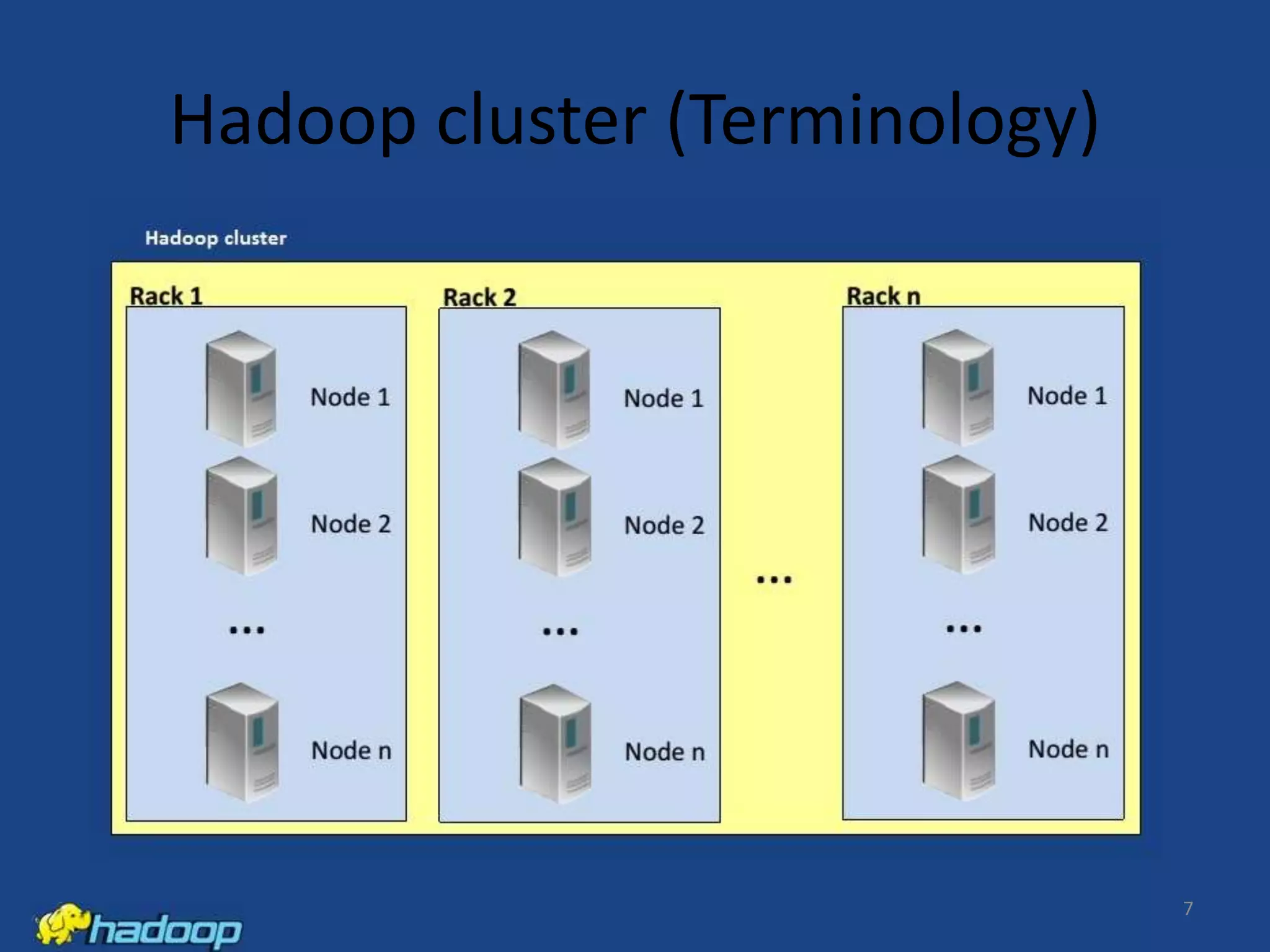

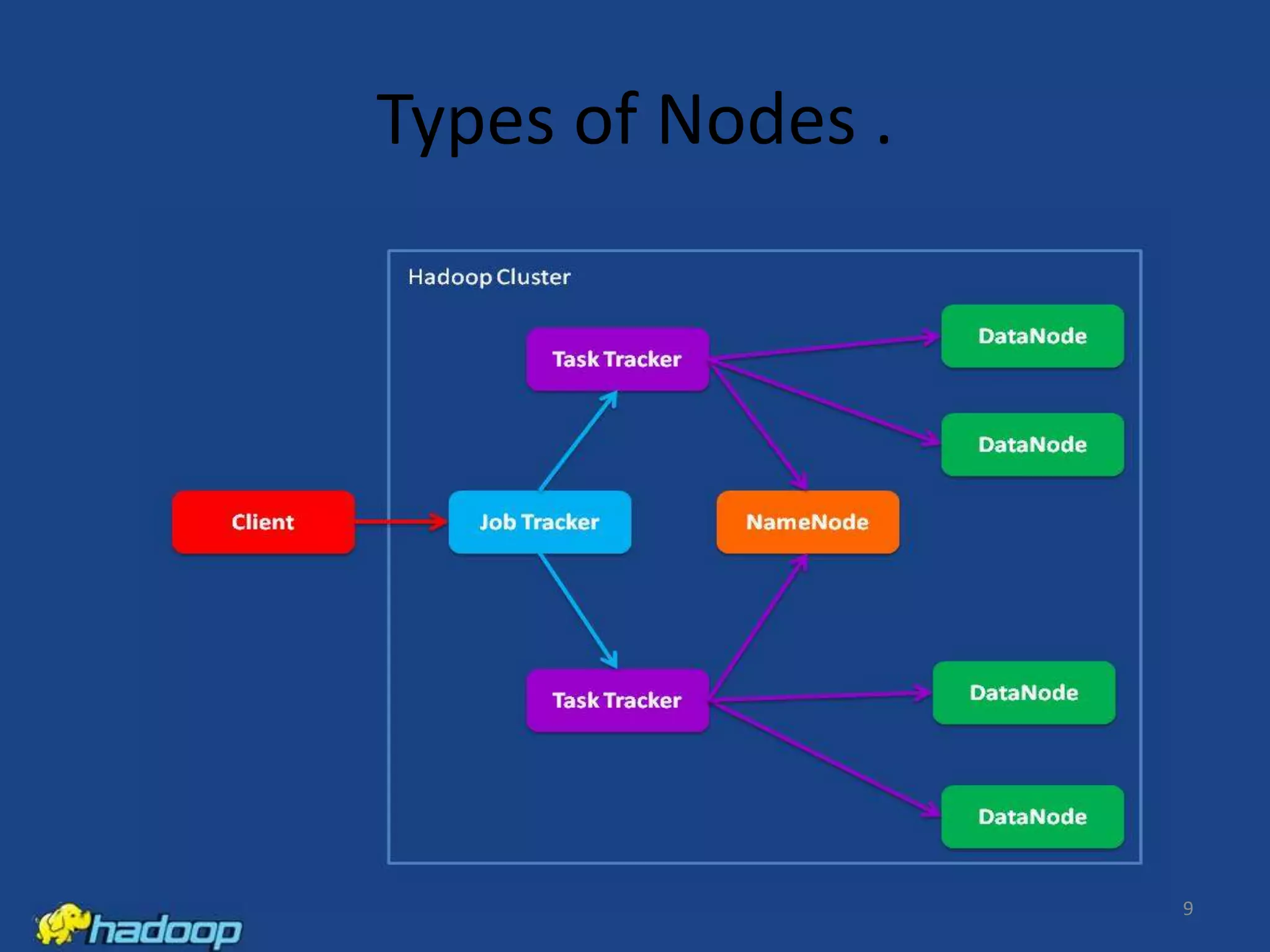


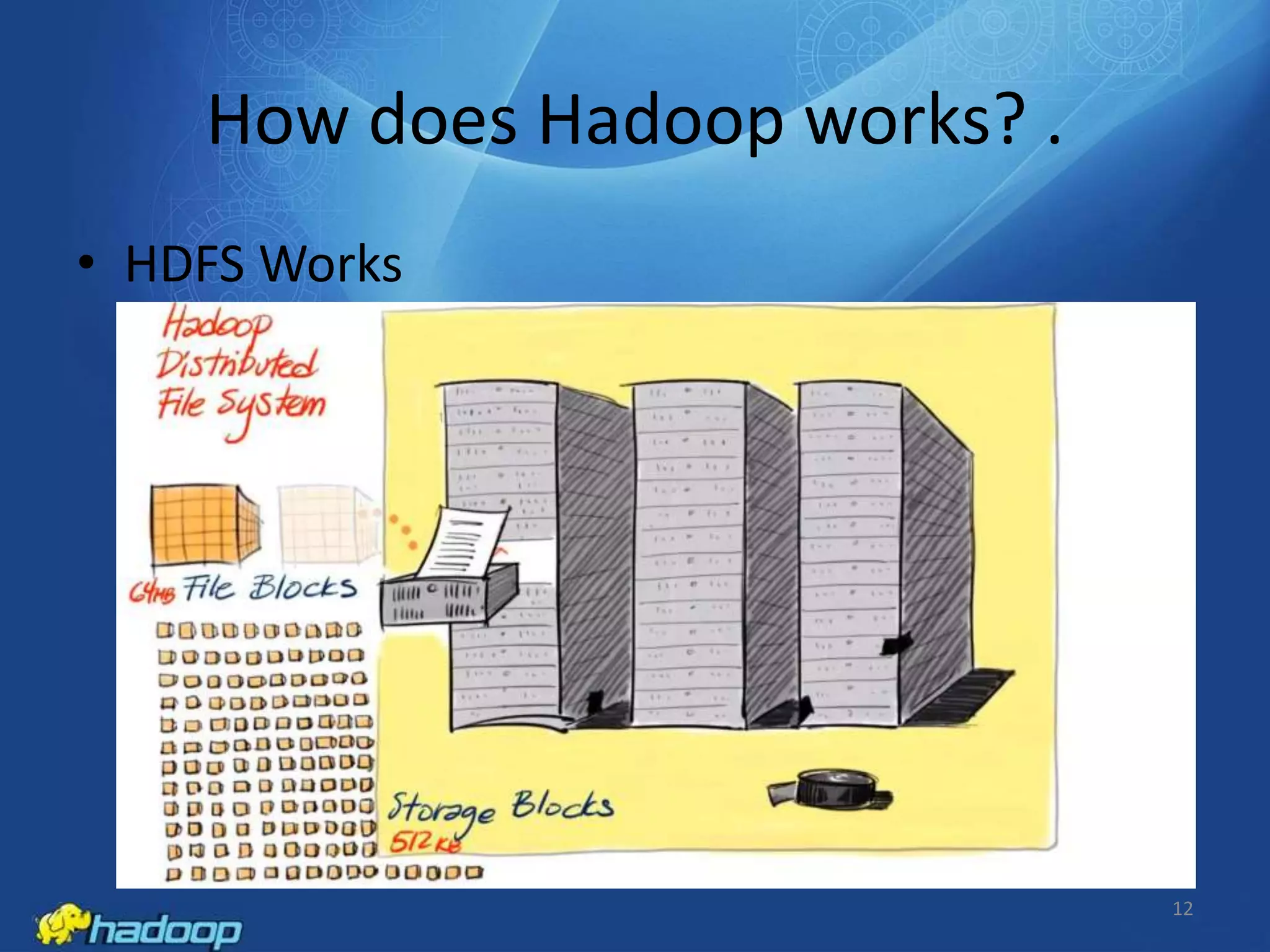
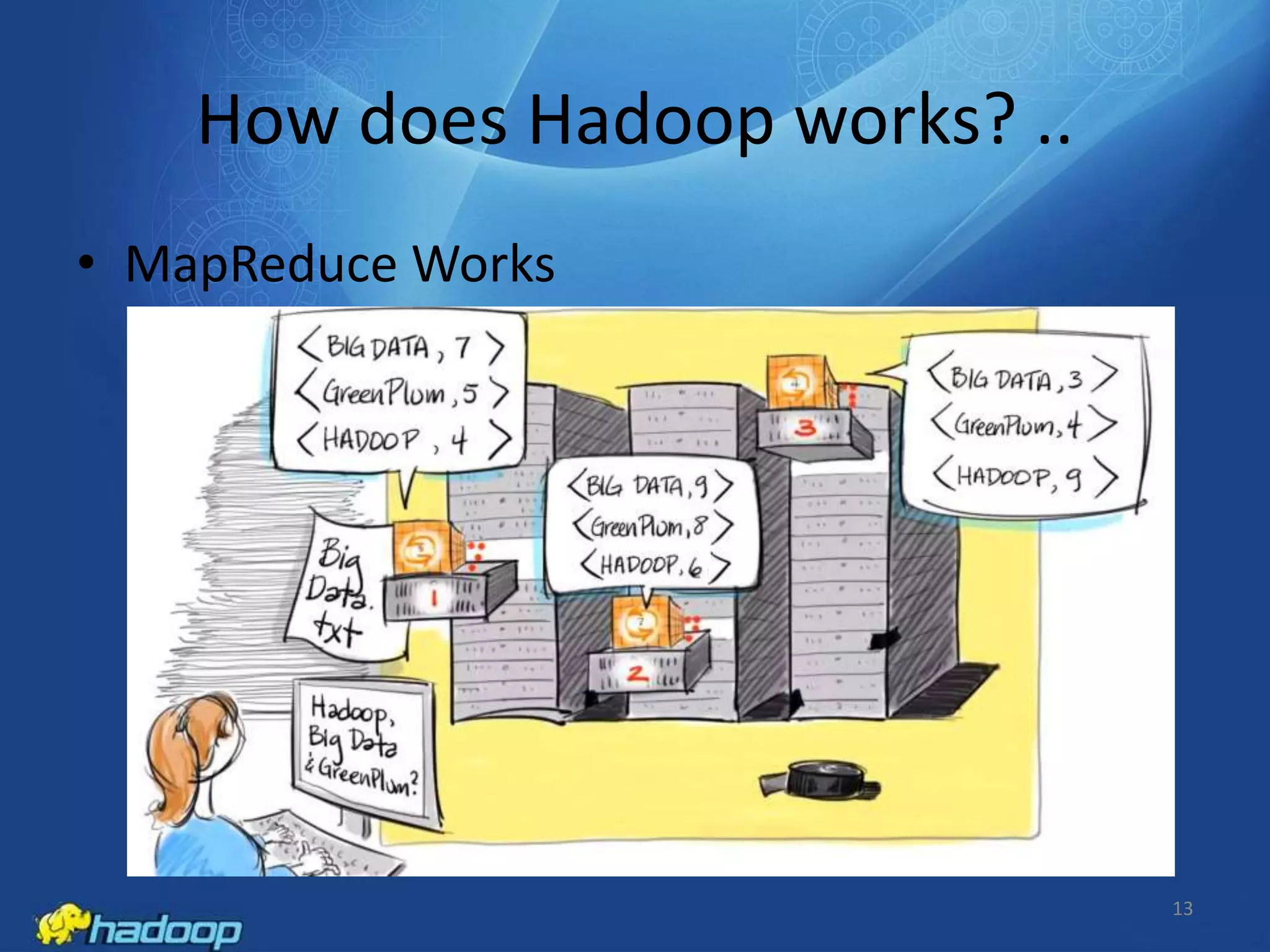








Apache Hadoop is an open-source distributed processing framework that stores data across computer clusters and allows for the distributed processing of large data sets across clusters of computers using simple programming models. It includes HDFS for storage and MapReduce for distributed computing. HDFS replicates blocks of data across multiple nodes for reliability, while MapReduce allows distributed filtering and sorting of large datasets using map and reduce functions. Common applications of Hadoop include log analysis, data mining, and web indexing.








































































