Downloaded 41 times














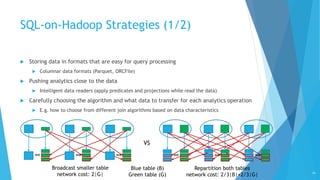
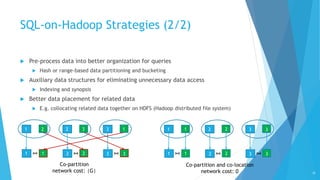


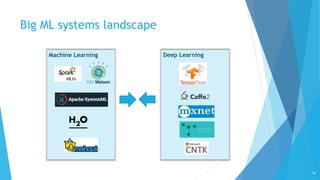







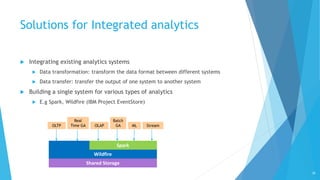



This document discusses big data analytics and different types of analytics that can be performed on big data, including SQL, machine learning, and graph analytics. It provides an overview of various big data analytics systems and techniques for different data types and complexity levels. Integrated analytics that combine multiple types of analytics are also discussed. The key challenges of big data analytics and how different systems address them are covered.


































































