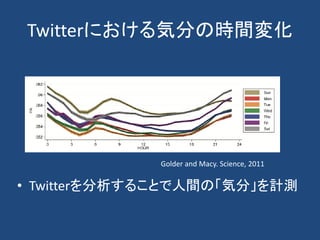
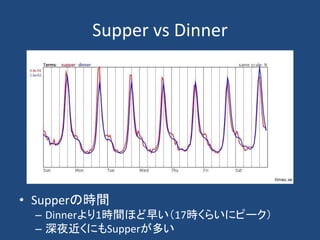
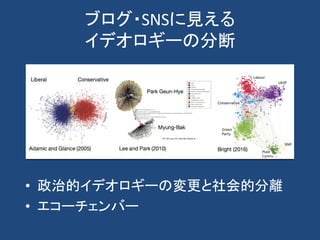
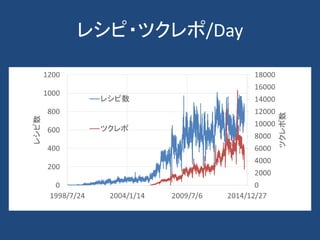
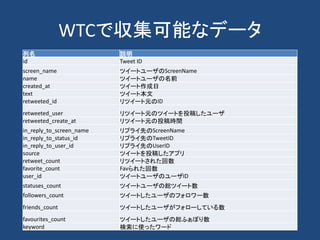
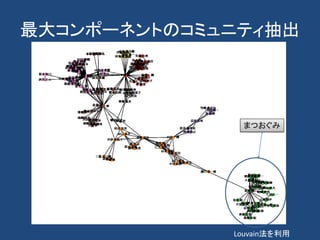
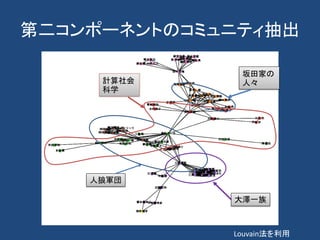
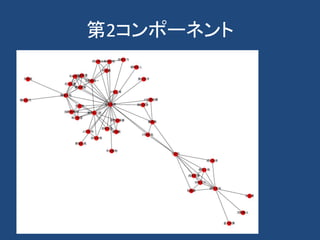
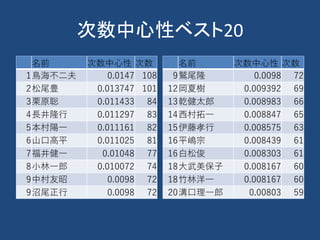
計算社会科学
• Computational socialscience refers to the
academic sub-disciplines concerned with
computational approaches to the social sciences.
• This means that computers are used to model,
simulate, and analyze social phenomena.
• Fields include computational economics and
computational sociology.
• It focuses on investigating social and behavioral
relationships and interactions through social
simulation, modeling, network analysis, and
media analysis.
From wikipedia.org




















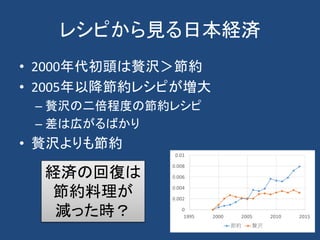
![恵方巻きの躍進
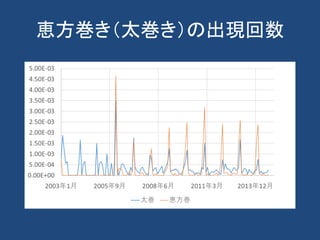
• 2006年恵方巻きの投稿が増加
– 恵方巻の認知度全国平均[1]
• 2002年:53%
• 2005年:88%
• 2000年代から恵方巻き戦略
• 2006年には一般家庭で作るレベルで浸透
[1]ミツカングループ (2006年1月13日). “「節分には“恵方巻”」全国に定着”](https://image.slidesharecdn.com/webminingforcss-180606101524/85/Web-25-320.jpg)































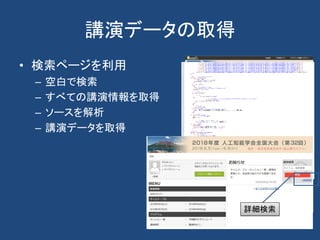
![ソースコード
<div class="sbjtitle">
<h1>
<span class="headicon"></span>
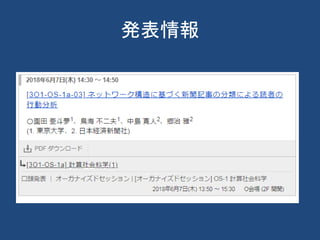
<a href="/guide/event/jsai2018/subject/3O1-OS-1a-03/advanced">
[3O1-OS-1a-03] ネットワーク構造に基づく新聞記事の分類による読者の行動分析</a>
</h1>
</div>
<div class="sbjcontent">
<p class="personals">
<span title="発表者">〇園田 亜斗夢<sup>1</sup>、鳥海 不二夫<sup>1</sup>、中島 寛人<sup>2</sup>、郷治 雅
<sup>2</sup></span>
<span title="所属">(1. 東京大学、2. 日本経済新聞社)</span>
</p>
</div>](https://image.slidesharecdn.com/webminingforcss-180606101524/85/Web-72-320.jpg)

































![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)





















































