More Related Content

PDF
Once upon a time in Tsukuba.R 
PPTX

PPT

PDF

PDF
Tokyo.R #22 Association Rules 
PDF

PDF
Tokyor45 カーネル多変量解析第2章 カーネル多変量解析の仕組み 
PDF
R言語による アソシエーション分析-組合せ・事象の規則を解明する-(第5回R勉強会@東京) Viewers also liked

PDF

PPTX

PDF

PDF
ロジスティック回帰の考え方・使い方 - TokyoR #33 
PDF
R言語で学ぶマーケティング分析 競争ポジショニング戦略 
PDF
Similar to Data Mining with R algae bloom case

PDF
「plyrパッケージで君も前処理スタ☆」改め「plyrパッケージ徹底入門」 
DOCX

PPTX
Tokyo r24 r_graph_tutorial 
PDF
ビジネス基礎講座:統計学入門 introduction to statistics 
PDF

PDF
Normalization of microarray 
PPT
Model seminar koba_and_student_100710_ch2 
PDF

PDF

PDF

PPTX

PDF

PDF
R入門(dplyrでデータ加工)-TokyoR42 More from Tadayuki Onishi

PDF

PDF
そろそろSublime Text 2を熱く語ろうと思う 
PDF

PDF

PDF

PDF

PDF

PDF
Data Mining with R algae bloom case
- 1.
- 2.
- 3.
- 4.
Data Mining withR
Learning with Case Studies
Luis Torgo(2010)
• 導入
• 藻類の予測
• 株式市場のリターンの予測
• 不正行為の検知
• マクロアレイの分類
- 5.
Data Mining withR
Learning with Case Studies
Luis Torgo(2010)
• 導入
• 藻類の予測
• 株式市場のリターンの予測 の 機会
た次 ま
• 不正行為の検知 の 機会
た次 ま
• マクロアレイの分類機会
次の
また
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
Predicting Algae Blooms
(直訳:藻類の予測)
川に有害な藻類が発生してます
http://digimaga.net/uploads/2008/07/player-
performs-sailing-competition-in-an-alga-in-the-
dirty-sea.jpg
藻類の大繁殖の予測は川の質の向上に必要
不可欠
じゃあ藻類の発生頻度を予測しましょう
- 12.
- 13.
- 14.
- 15.
- 16.
mxPH・・・ ph値の最大値
mnO2・・・ 酸素の最小値
Cl・・・ 塩化物の平均値
NO3 ・・・ 硝酸イオンの平均値
NH4 ・・・ アンモニウムイオンの平均値
oPO4 ・・・ オルソリン酸イオンの平均
PO4 ・・・ リン酸の合計の平均値
Chla ・・・ 葉緑素の平均
a1∼a7 ・・・ 異なる7つの藻類の発生頻度
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
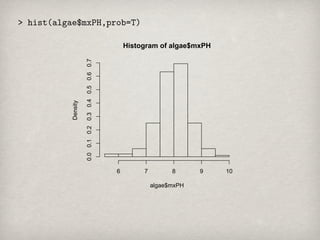
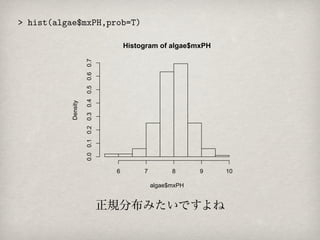
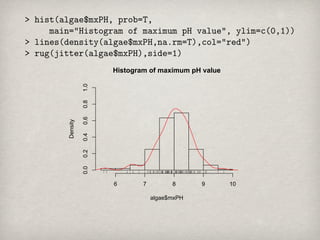
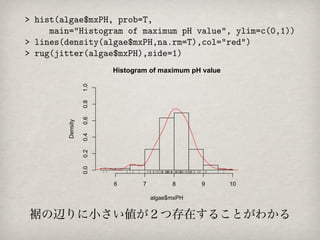
Histogram of maximumpH value
1.0
0.8
0.6
Density
0.4
0.2
0.0
6 7 8 9 10
algae$mxPH
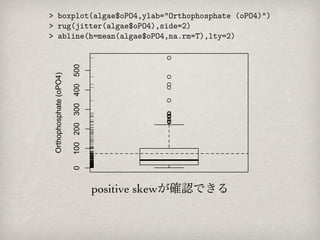
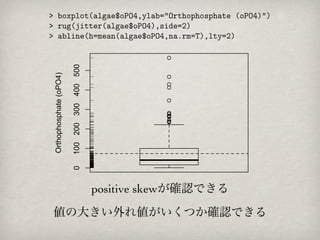
裾の辺りに小さい値が2つ存在することがわかる
- 27.
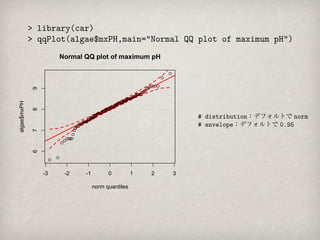
Normal QQ plotof maximum pH
9
algae$mxPH
8
# distribution:デフォルトで norm
# envelope:デフォルトで 0.95
7
6
-3 -2 -1 0 1 2 3
norm quantiles
- 28.
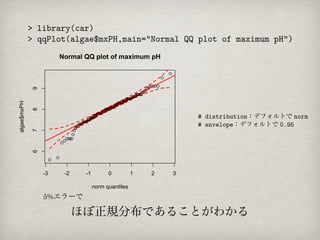
Normal QQ plotof maximum pH
9
algae$mxPH
8
# distribution:デフォルトで norm
# envelope:デフォルトで 0.95
7
6
-3 -2 -1 0 1 2 3
norm quantiles
5%エラーで
ほぼ正規分布であることがわかる
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
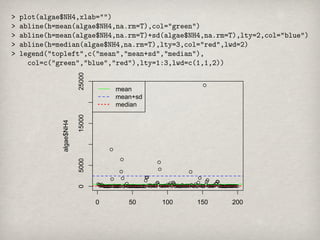
25000
mean
mean+sd
median
15000
algae$NH4
5000
0
0 50 100 150 200
- 35.
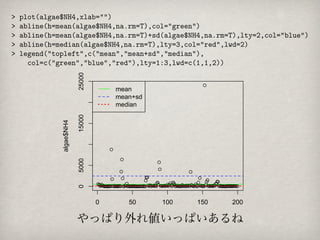
25000
mean
mean+sd
median
15000
algae$NH4
5000
0
0 50 100 150 200
やっぱり外れ値いっぱいあるね
- 36.
- 37.
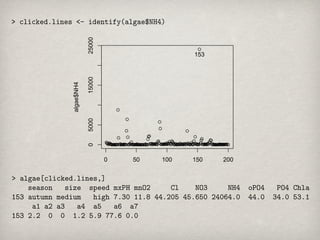
algae$NH4
0 5000 15000 25000
0
50
100
150
153
200
- 38.
- 39.
- 40.
- 41.
NAを処理する方法
manyNAs()
is.na()
complete.cases()
na.omit()
mean()やsd()などのna.rmオプション
- 42.
- 43.
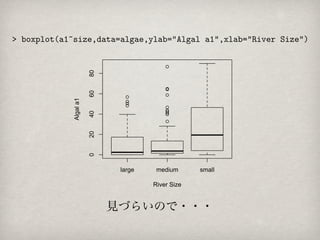
80
60
Algal a1
40
20
0
large medium small
River Size
見づらいので・・・
- 44.
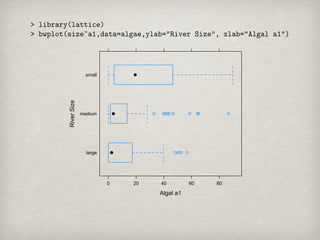
River Size small
medium
large
0 20 40 60 80
Algal a1
- 45.
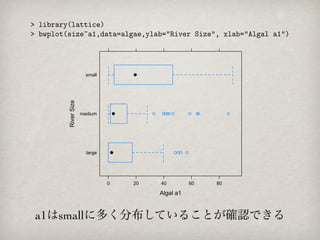
River Size small
medium
large
0 20 40 60 80
Algal a1
a1はsmallに多く分布していることが確認できる
- 46.
- 47.
small
River Size
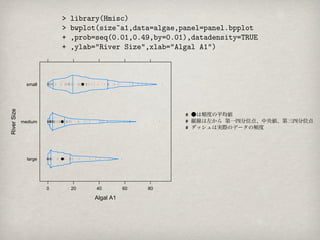
# ●は頻度の平均値
medium # 縦線は左から 第一四分位点、中央値、第三四分位点
# ダッシュは実際のデータの頻度
large
0 20 40 60 80
Algal A1
- 48.
small
River Size
# ●は頻度の平均値
medium # 縦線は左から 第一四分位点、中央値、第三四分位点
# ダッシュは実際のデータの頻度
large
0 20 40 60 80
Algal A1
頻度も確認できるので便利
- 49.
0 10 20 30 40
minO2 minO2
winter
summer
spring
autumn
# number:データを何個に分けるか
minO2 minO2 # overlap:分けた時にデータをどのくらい重複させるか
winter
# striplot は lattice パッケージ
summer
spring
autumn
0 10 20 30 40
a3
- 50.
0 10 20 30 40
minO2 minO2
winter
summer
spring
autumn
# number:データを何個に分けるか
minO2 minO2 # overlap:分けた時にデータをどのくらい重複させるか
winter
# striplot は lattice パッケージ
summer
spring
autumn
0 10 20 30 40
a3
a3とseasonの関係とminO2を表している
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 60.
- 61.
- 62.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
- 72.
- 73.
- 75.
- 76.
- 77.
- 78.
- 79.
80
Linear Model Regression Tree
80
60
60
True Values
True Values
40
40
20
20
0
0
-10 0 10 30 10 20 30 40
Predictions Predictions
正直、微妙
- 80.
- 82.
- 83.
- 84.
言い訳をすると
この本は
「モデル選択の段階でとても興味深い得点を得ることができた」
と終わらせています
- 85.
- 86.