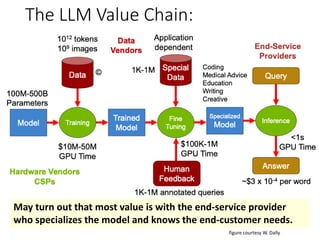
This document provides a technical introduction to large language models (LLMs). It explains that LLMs are based on simple probabilities derived from their massive training corpora, containing trillions of examples. The document then discusses several key aspects of how LLMs work, including that they function as a form of "lossy text compression" by encoding patterns and relationships in their training data. It also outlines some of the key elements in the architecture and training of the most advanced LLMs, such as GPT-4, focusing on their huge scale, transformer architecture, and use of reinforcement learning from human feedback.








![“There is no moat?” (Some insiders think that the technology
can be miniaturized and will leak via open source availability to
individuals and thence startups.)
• Meta/Facebook’s entire LLM was leaked online in March, 2023.
• and later released publicly
• A May, 2023, leaked Google document (one engineer’s private
view):
• People are now running foundation models on a Pixel 6 at 5 tokens/s
• You can fine-tune a personalized AI on your laptop in an evening.
• Open-source models are [he says] faster, more customizable, more
private, and pound-for-pound more capable.
• “They are doing things with $100 and 13B params that we struggle with
at $10M and 540B.”
• LORa (low-rank factorization of large models) saves factor ~103
• and is composable to train new models, no need to go back to full model
• Big companies might be held liable for copyright infringement on
training data, or have to buy it
• Open-source leaked models might (de-facto) not be
• Scenario: A bunch of (LORa?) matrices appear on a Discord server](https://image.slidesharecdn.com/chatbotsexplainedwilliamhpress-230520152258-64279b30/85/How-Does-Generative-AI-Actually-Work-a-quick-semi-technical-introduction-to-Large-Language-Models-10-320.jpg)