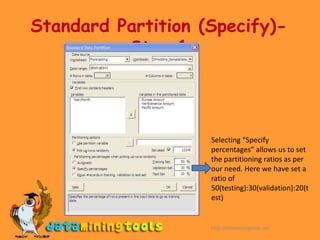
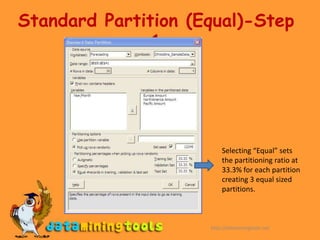
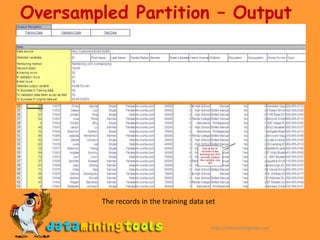
This document introduces data partitioning in XLMiner. Partitioning divides a large dataset into training, validation, and test sets. The training set builds a model, the validation set checks the model's accuracy, and the test set determines real-world performance. XLMiner allows standard partitioning with random assignment or specifying percentages, as well as oversampling to balance low-success outputs.