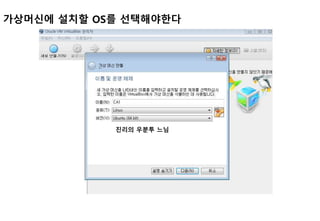
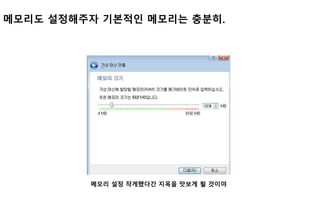
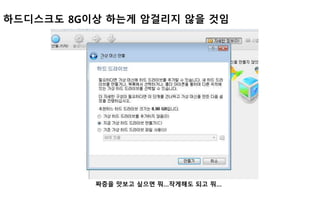
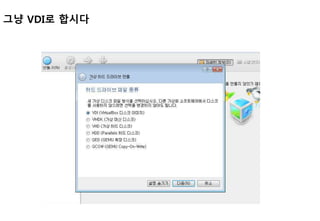
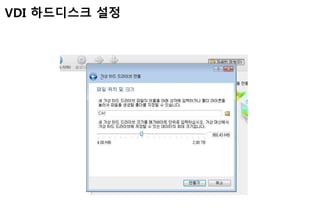
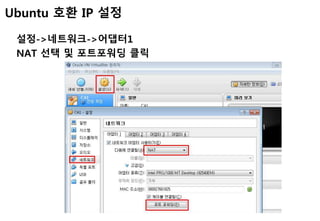
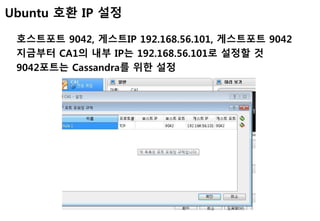
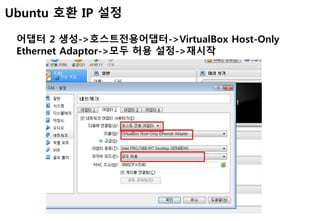
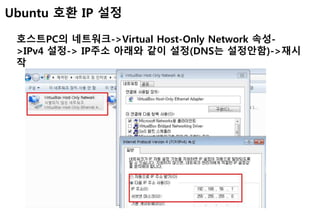
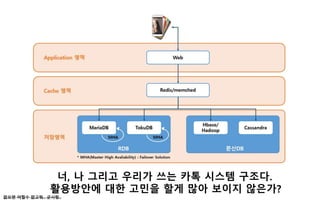
Ubuntu 호환 IP설정
호스트PC의 네트워크->Virtual Host-Only Network 속성-
>IPv4 설정-> IP주소 아래와 같이 설정(DNS는 설정안함)->재시
작
38.
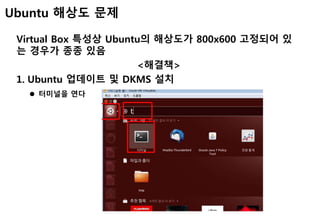
Ubuntu 내부 IP설정
터미널 열고 -> sudo vi /etc/network/interfaces [ENTER]
다음과 같이 입력 저장 및 리붓
앞으로 CA1은 IP가 192.168.56.101로 설정됨
추후 CA2는 IP가 192.168.56.102로 설정될 예정
주의 : 설정이후 호스트PC에서 ping 192.168.56.101하면 연결
불가됨 이는 나중에 포트포워딩으로 확인 가능
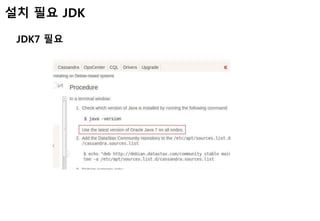
JDK 설치
설치되어있던 openjdk삭제
sudo apt-get purge openjdk*
apt-repository에 경로 추가
sudo apt-get install software-properties-common
ppa 추가
sudo add-apt-repository ppa:webupd8team/java
JDK 7 설치
sudo apt-get install oracle-java7-installer
43.
JDK 설치
설치되어있던 openjdk삭제
sudo apt-get purge openjdk*
apt-repository에 경로 추가
sudo apt-get install software-properties-common
ppa 추가
sudo add-apt-repository ppa:webupd8team/java
sudo apt-get update
JDK 7 설치
sudo apt-get install oracle-java7-installer
JDK 설치 확인
44.
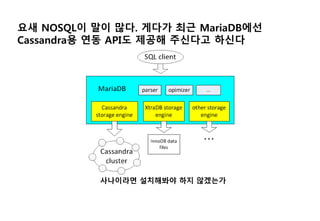
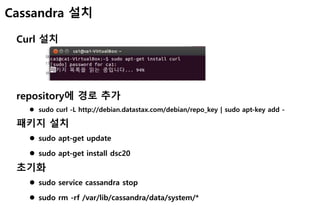
Cassandra 설치
Curl 설치
repository에경로 추가
sudo curl -L http://debian.datastax.com/debian/repo_key | sudo apt-key add -
패키지 설치
sudo apt-get update
sudo apt-get install dsc20
초기화
sudo service cassandra stop
sudo rm -rf /var/lib/cassandra/data/system/*
45.
Cassandra 환경 설정
환경설정 파일 경로
/etc/cassandra/conf/cassandra.yaml
설정 내역
Simple Data Center
RackInferringSnitch
IP 192.168.56.101
Client 연결 포트 9042(기본)
Cli 연결 9160(기본)
주의: cassandra.yaml에서 설정이 xxx : xxx 일 경우 띄어쓰기 잘 해줘야 함 붙여
쓸 경우 parse 에러 발생함
46.
Cassandra.yaml 설정
initial token설정(메인 0)
seeds 설정(192.168.56.101)
Listen Address 설정(192.168.56.101)
주의: 대부분의 사이트에서 listen_address를 0.0.0.0 잡으라고 하는데 이럴 경우 실행
하면 나중에 broadcast 를 잡지 않았다고 에러가 발생함
Cassandra.yaml 설정
로그 위치
/var/log/cassandra/
데이터 위치
/var/lib/cassandra/commitlog
/var/lib/cassandra/data
/var/lib/cassandra/saved_caches
주의: 나중에 token이 중복되었다니 등의 문제가 발생하면 이는 데이터를 지우기 전엔 복구
가 안되므로 위의 데이터 내의 파일을 모두 지우고 초기화를 하면 initial_token이 새로 적용
된다
49.
Cassandra.yaml 설정
서비스 시작및 동작상황 확인
sudo service cassandra start
node status
이미지 처럼 1개가 우선 동작하고 있는 것이 확인된다
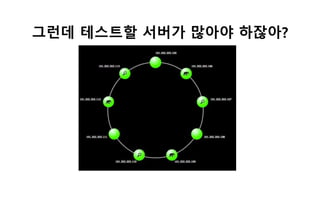
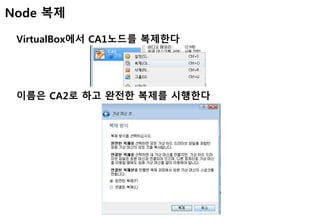
Node 복제
CA1을 종료하고CA2를 실행하여 IP를 192.168.56.102로 변경
한다
Cassandra.yaml의 IP부분중 seeds를 제외하고 나머지를 전부
102로 바꾼다
initial token 설정은 0이 아닌 다른 키로 입력한다(이거 충돌나
면 안됨)
52.
순서대로 재시작
CA1을 켜고CA2를 켠 다음 nodetool status를 확인한다
주의: 만약 error중 Cannot change the number of tokens from 1 to 256 에러 발생
하면 cassandra.yaml에서 num_tokens를 1로 바꾸고 data로그를 다 지운다
정상적인 동작상황이면 nodetool status를 통해 2개가 연결된
것을 확인할 수 있다
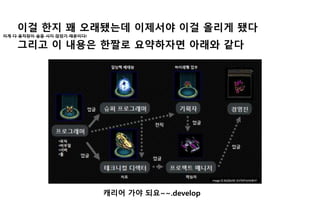
Client Lib
Client 종류는여러가지가 존재함
https://github.com/datastax/java-driver에서 드라이버를 다운
받음 driver-core.jar
이 파트는 아무래도 SQL쿼리문 처럼 사용할 수 있기때문에 사용
함.
다른Lib는 가능한지 확인 안함
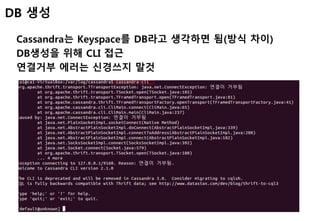
DB 생성
connect 192.168.56.101/9160; 실행
create keyspace demodb with placement_strategy
=‘org.apache.cassandra.locator.SimpleStrategy’ and
strategy_options = {replication_factor:1};
demodb라는 keyspace 생성
57.
demodb에 연결 시도
에러가나지 않으면 정상 연결
이 앞에 포트포워딩 한 포트와 해당 PC의 IP를 연결하여 테스트
Client Demo 접근 테스트
Insert Select Delete등에 대해서 각 기능과 Update는 왜 어려
운지 등에 대한 별도의 연구가 필요
->update는 인덱스의 재배치가 필요하므로 페이지 로드가
크기 때문이다
시스템적인 구성에 대한 연구 또한 필요
Client SQL
62.
껐다 켜면 cassandracannot change the number of tokens from 1 to 256 라는게
종종 뜨는데 이건 num_tokens 세팅 때문이다 이는 데이터센터가 1개이상 즉
NetworkTopologyStrategy 사용시에 virtual node가 사용되고 이 virtual node의 갯
수를 설정할때 쓰는 부분이다. 우린 SimpleStrategy라 별 의미가 없다. 자세한건 여기
참조
http://www.datastax.com/documentation/cassandra/2.0/cassandra/configuratio
n/configVnodesProduction_t.html?scroll=task_ds_jsd_xjd_2l__task_ds_jsd_xjd_2l_u
nique_1
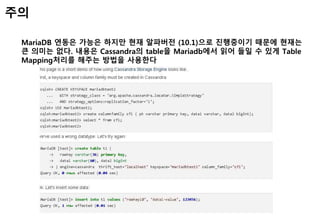
MariaDB 연동은 가능은 하지만 현재 알파버전 (10.1)으로 진행중이기 때문에 현재는
큰 의미는 없다. 내용은 Cassandra의 table을 Mariadb에서 읽어 들일 수 있게 Table
Mapping처리를 해주는 방법을 사용한다
주의
63.
MariaDB 연동은 가능은하지만 현재 알파버전 (10.1)으로 진행중이기 때문에 현재는
큰 의미는 없다. 내용은 Cassandra의 table을 Mariadb에서 읽어 들일 수 있게 Table
Mapping처리를 해주는 방법을 사용한다
주의
















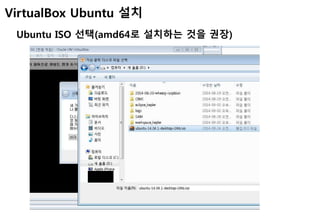


![Ubuntu 해상도 문제
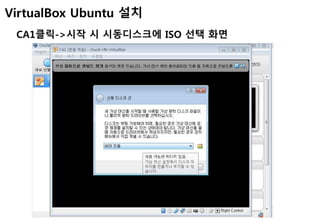
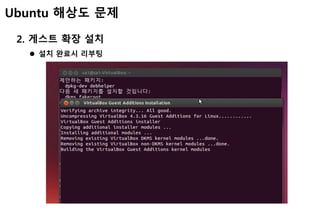
2. 게스트 확장 설치
Linux를 켜고 [게스트 확장 설치] 클릭(보통 virtual box 디렉토리에 존재함)](https://image.slidesharecdn.com/cassandra-141223081203-conversion-gate01/85/with-virtualbox-32-320.jpg)

![Ubuntu 내부 IP 설정
터미널 열고 -> sudo vi /etc/network/interfaces [ENTER]
다음과 같이 입력 저장 및 리붓
앞으로 CA1은 IP가 192.168.56.101로 설정됨
추후 CA2는 IP가 192.168.56.102로 설정될 예정
주의 : 설정이후 호스트PC에서 ping 192.168.56.101하면 연결
불가됨 이는 나중에 포트포워딩으로 확인 가능](https://image.slidesharecdn.com/cassandra-141223081203-conversion-gate01/85/with-virtualbox-38-320.jpg)









































![[D2]thread dump 분석기법과 사례](https://cdn.slidesharecdn.com/ss_thumbnails/d2threaddump-150522063949-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)

![[252] 증분 처리 플랫폼 cana 개발기](https://cdn.slidesharecdn.com/ss_thumbnails/225cana-150915052201-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)







![[H3 2012] Cloud Database Service - Hulahoop를 소개합니다.](https://cdn.slidesharecdn.com/ss_thumbnails/c1-hulahoop-121105214317-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)















![[OpenStack Days Korea 2016] Track3 - VDI on OpenStack with LeoStream Connecti...](https://cdn.slidesharecdn.com/ss_thumbnails/36gotocloud-160226174146-thumbnail.jpg?width=640&height=640&fit=bounds)
![[OpenStack Days Korea 2016] Track3 - OpenStack on 64-bit ARM with X-Gene](https://cdn.slidesharecdn.com/ss_thumbnails/32apm-160226173205-thumbnail.jpg?width=640&height=640&fit=bounds)
![[OpenStack Days Korea 2016] Track3 - Powered by OpenStack, Power to do more w...](https://cdn.slidesharecdn.com/ss_thumbnails/33dell-160226173435-thumbnail.jpg?width=640&height=640&fit=bounds)













![XECon2015 :: [1-5] 김훈민 - 서버 운영자가 꼭 알아야 할 Docker](https://cdn.slidesharecdn.com/ss_thumbnails/xecon2015-1-5docker-160316043822-thumbnail.jpg?width=640&height=640&fit=bounds)





