Single server durabilitySingleserver durability 지원이 취약한 이유일부러 하지 않는 않았다.이유는?기존의 DBMS도 single server durability를 보장 못하는 경우가 많다.물리적 파괴와 같은 상황에서 복구가 힘들다.그래서?Multi-server durability를 사용하시라.2
복제 상태와 로컬데이터베이스local databaseMongodb에서 사용하는 databaseReplica set에 대한 정보Replica set 관련 collectionlocal.system.replset : config정보local.oplog.rs : oploglocal.replset.minvalid : 내부용, 동기화정보를 추적하기 위한 정보 보관Master/Slave replication 관련 collectionMaster nodelocal.oplog.$main : oploglocal.slavesSlave nodelocal.sourcesOtherlocal.me22
23.
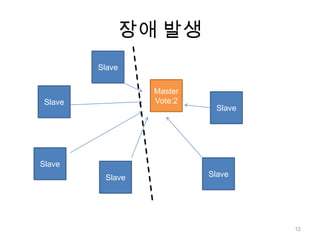
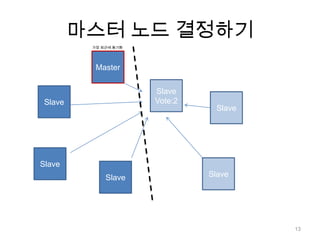
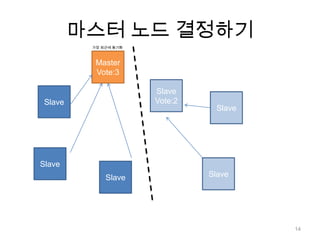
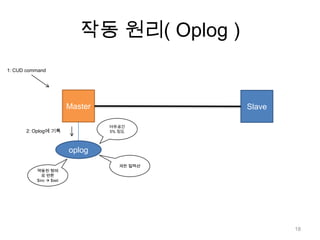
노드 동기화N개의 노드들이쓰기 연산 복제 완료까지 대기보통 N을 2 ~ 3으로 설정 ( 효율성 / 안정성 trade-off )> db.runCommand( {getLastError: 1, w : N } )23
24.
관리진단Oplog변경> db.printReplicationInfo()configured oplogsize: 944.1375732421875MBlog length start to end: 1266secs (0.35hrs)oplog first event time: Thu Aug 04 2011 23:47:12 GMT+0900oplog last event time: Fri Aug 05 2011 00:08:18 GMT+0900now: Fri Aug 05 2011 23:44:46 GMT+0900> db.printSlaveReplicationInfo()source: localhost:27017syncedTo: Fri Aug 05 2011 23:46:11 GMT+0900$ rm /data/db/local.*$ mongod --master --oplogSizesize//slave들을 --autosync로 재시작하거나 수동으로 재 동기화 필요함24
25.
관리인증을 통한 복제마스터/ 슬레이브의local db에 동일한 사용자와 비밀번호 추가Slave 접속 시도“repl”이라는 사용자로 접속시도local.system.users의 제일 처음 이름을 사용> use localSwitched to db local> db.add.User( “repl”, password );{“user” : “repl”, “readOnly” : false, “pwd” : “…” }25
26.
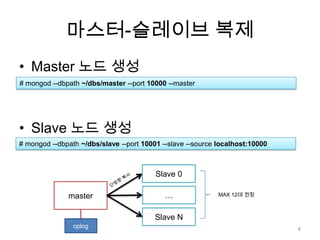
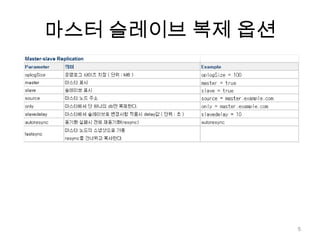
정리복제를 하는 두가지방법.Master-slaveReplica set ( 편하다 )Oplog사이즈를 적당히 크게 잡아주자.재동기화 방지Slave에 query를 날리려면?--master or --slaveOkey옵션으로 생성26






![레플리카 셋 초기화( ver 1.8+ )Replica set 작동$ mongod --replSetsetname--restReplica set 초기화> rs.initiate()> rs.initiate( <config-object> )> db.runCommand( { replSetInitiate : <config-object> } )Configobject> cfg= { ... _id : "acme_a", ... members : [ ... { _id : 0, host : "sf1.acme.com" }, ... { _id : 1, host : "sf2.acme.com" }, ... { _id : 2, host : "sf3.acme.com" } ] } > rs.initiate(cfg) > rs.status()> rs.add("sf2.acme.com"); > rs.add("sf3.acme.com"); > rs.status(); http://www.mongodb.org/display/DOCS/Replica+Set+Configuration8](https://image.slidesharecdn.com/mongodb-110805100619-phpapp02/85/Mongo-db-Replication-8-320.jpg)


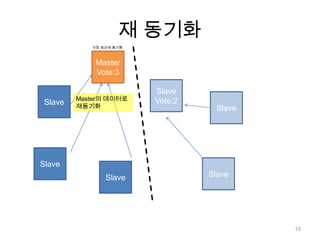


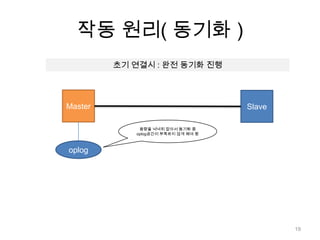
![작동 원리( 동기화 )동기화 완료 이후…MasterSlave[N초마다]복제 요청oplog20](https://image.slidesharecdn.com/mongodb-110805100619-phpapp02/85/Mongo-db-Replication-20-320.jpg)





















![[110730/아꿈사발표자료] mongo db 완벽 가이드 : 7장 '고급기능'](https://cdn.slidesharecdn.com/ss_thumbnails/110730mongodb7-110729214130-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)









![[125]웹 성능 최적화에 필요한 브라우저의 모든 것](https://cdn.slidesharecdn.com/ss_thumbnails/125webproc-181011045612-thumbnail.jpg?width=640&height=640&fit=bounds)














![[야생의 땅: 듀랑고] 서버 아키텍처 Vol. 2 (자막)](https://cdn.slidesharecdn.com/ss_thumbnails/vol2-160427160825-thumbnail.jpg?width=640&height=640&fit=bounds)

![[스마트스터디]MongoDB 의 역습](https://cdn.slidesharecdn.com/ss_thumbnails/mongodb-171107063223-thumbnail.jpg?width=640&height=640&fit=bounds)






![[스마트스터디]모바일 애플리케이션 서비스에서의 로그 수집과 분석](https://cdn.slidesharecdn.com/ss_thumbnails/redismongodbmysql-171107063045-thumbnail.jpg?width=640&height=640&fit=bounds)
![분산 트랜잭션 - 큰힘에는 큰 책임이 따른다 [MongoDB]](https://cdn.slidesharecdn.com/ss_thumbnails/distributedtransacationsjohnyu-190916180044-thumbnail.jpg?width=640&height=640&fit=bounds)

![[넥슨] kubernetes 소개 (2018)](https://cdn.slidesharecdn.com/ss_thumbnails/gcdkubernetes-190419130148-thumbnail.jpg?width=640&height=640&fit=bounds)


