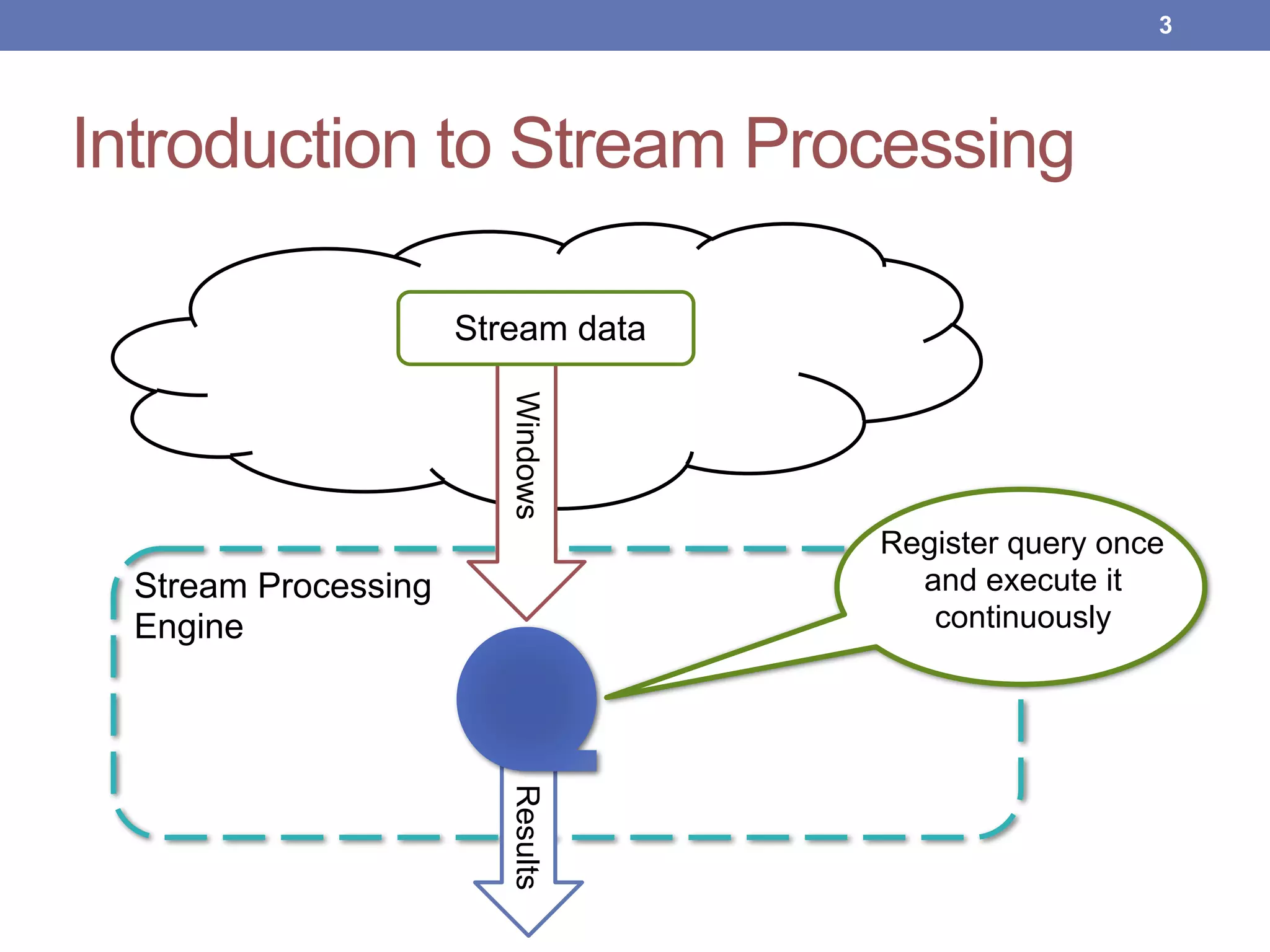
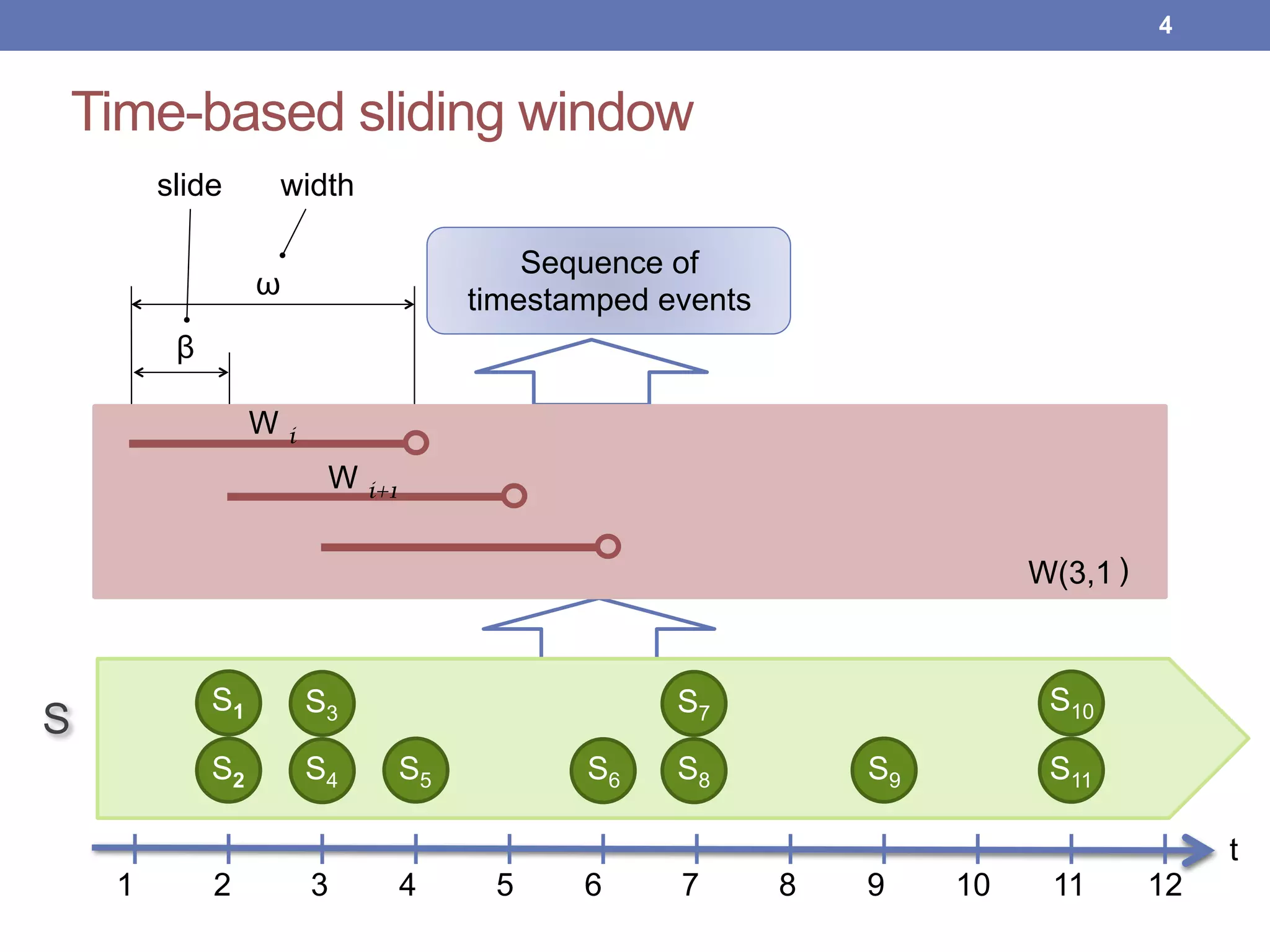
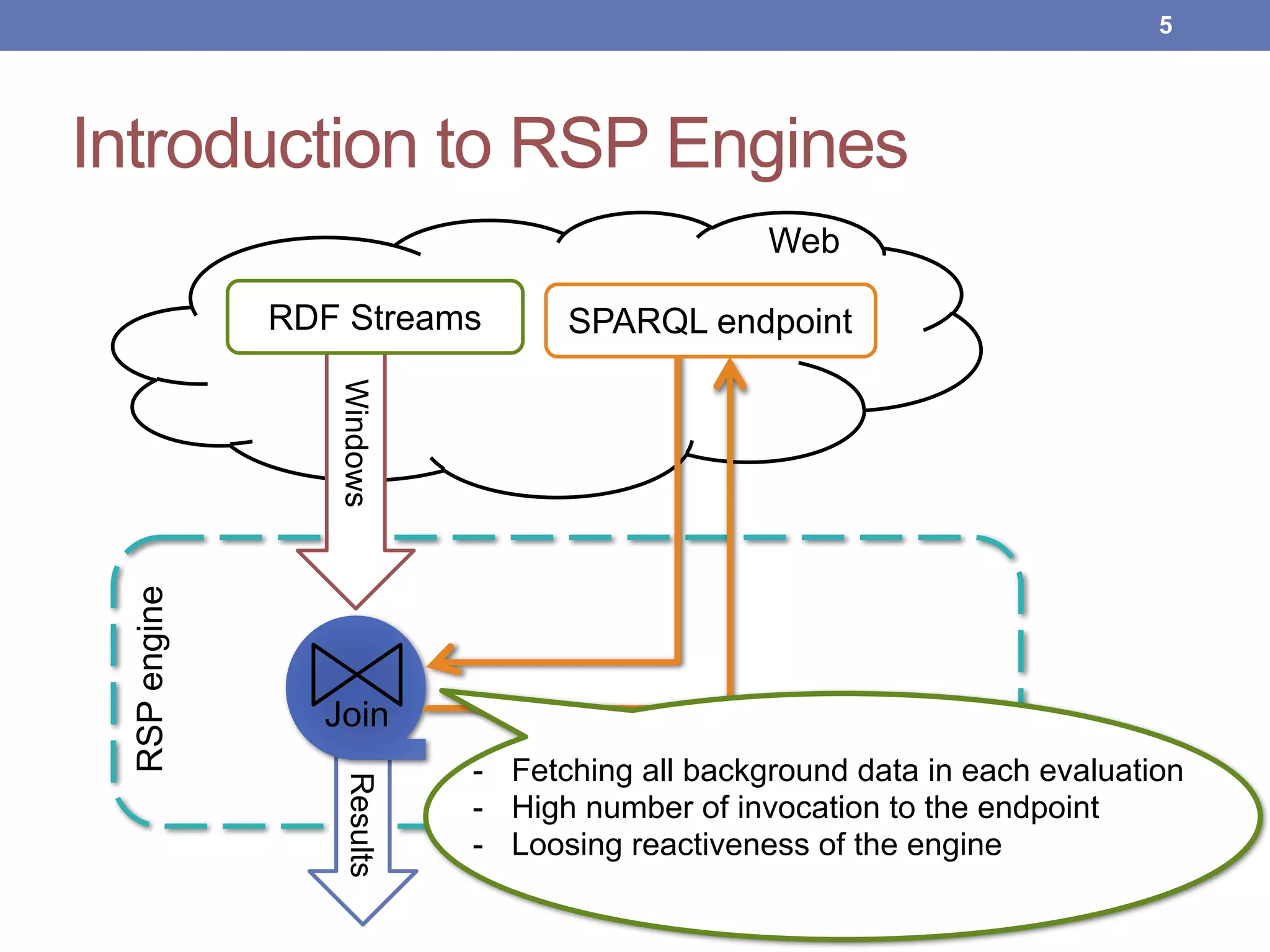
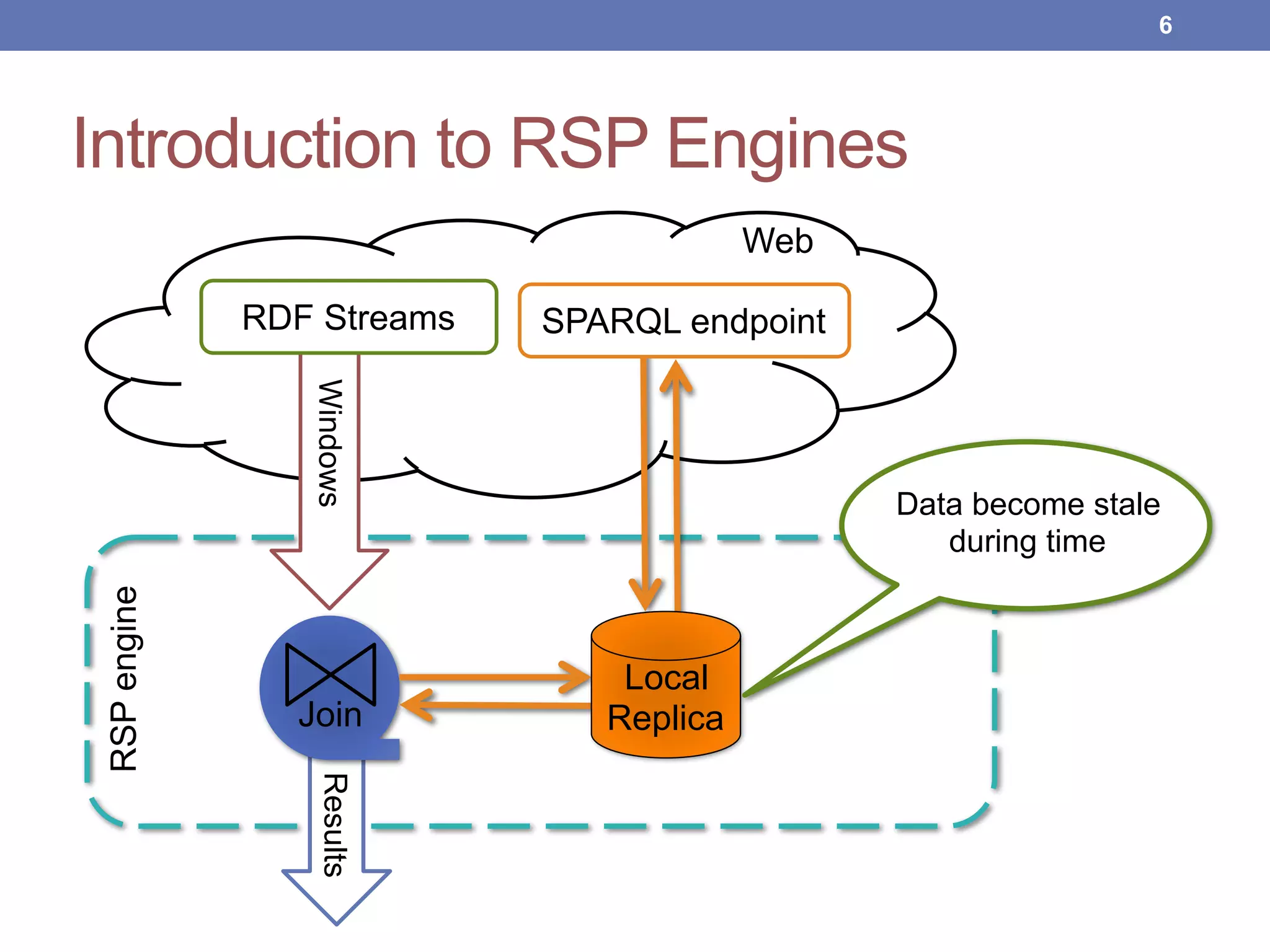
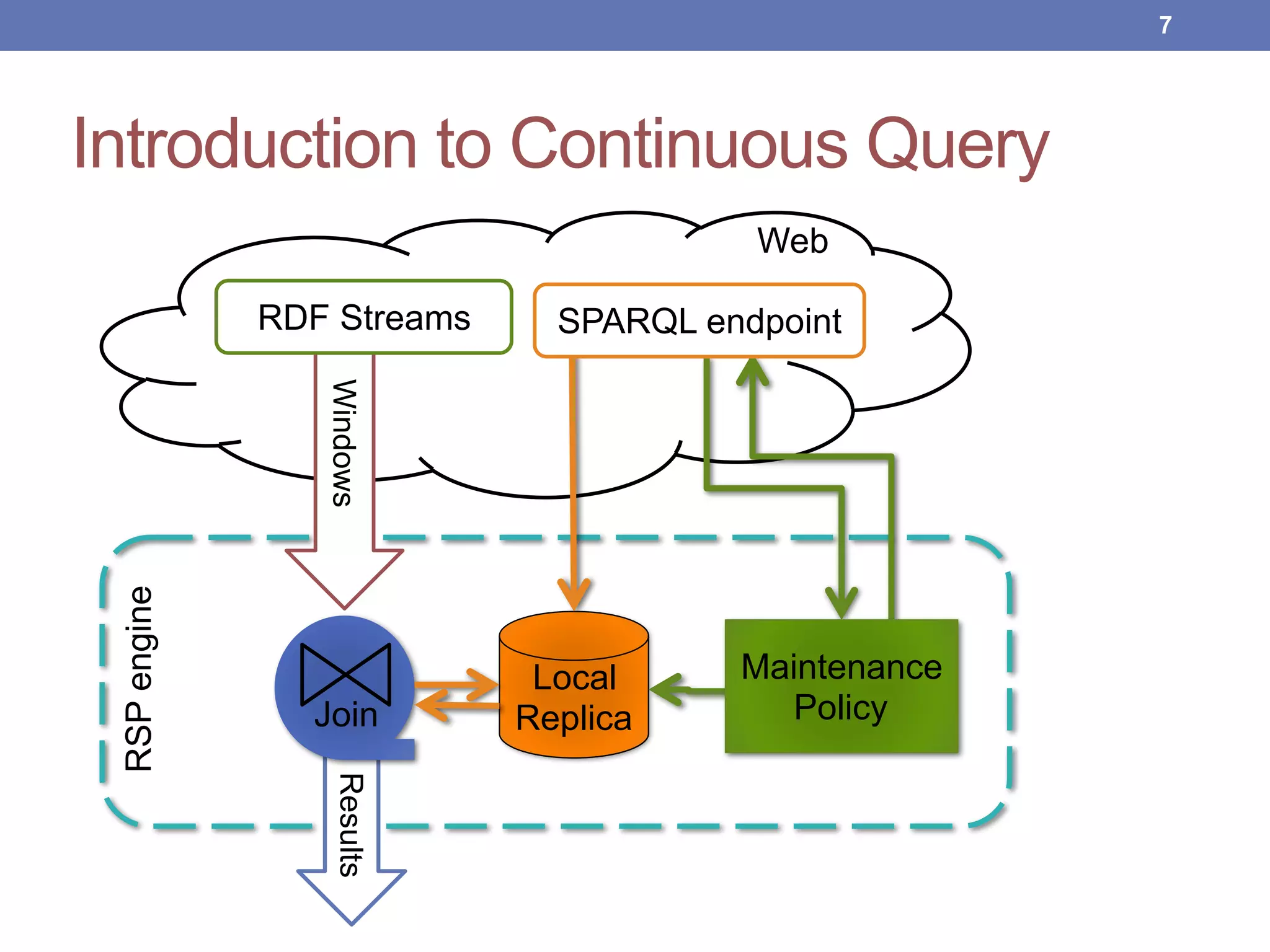
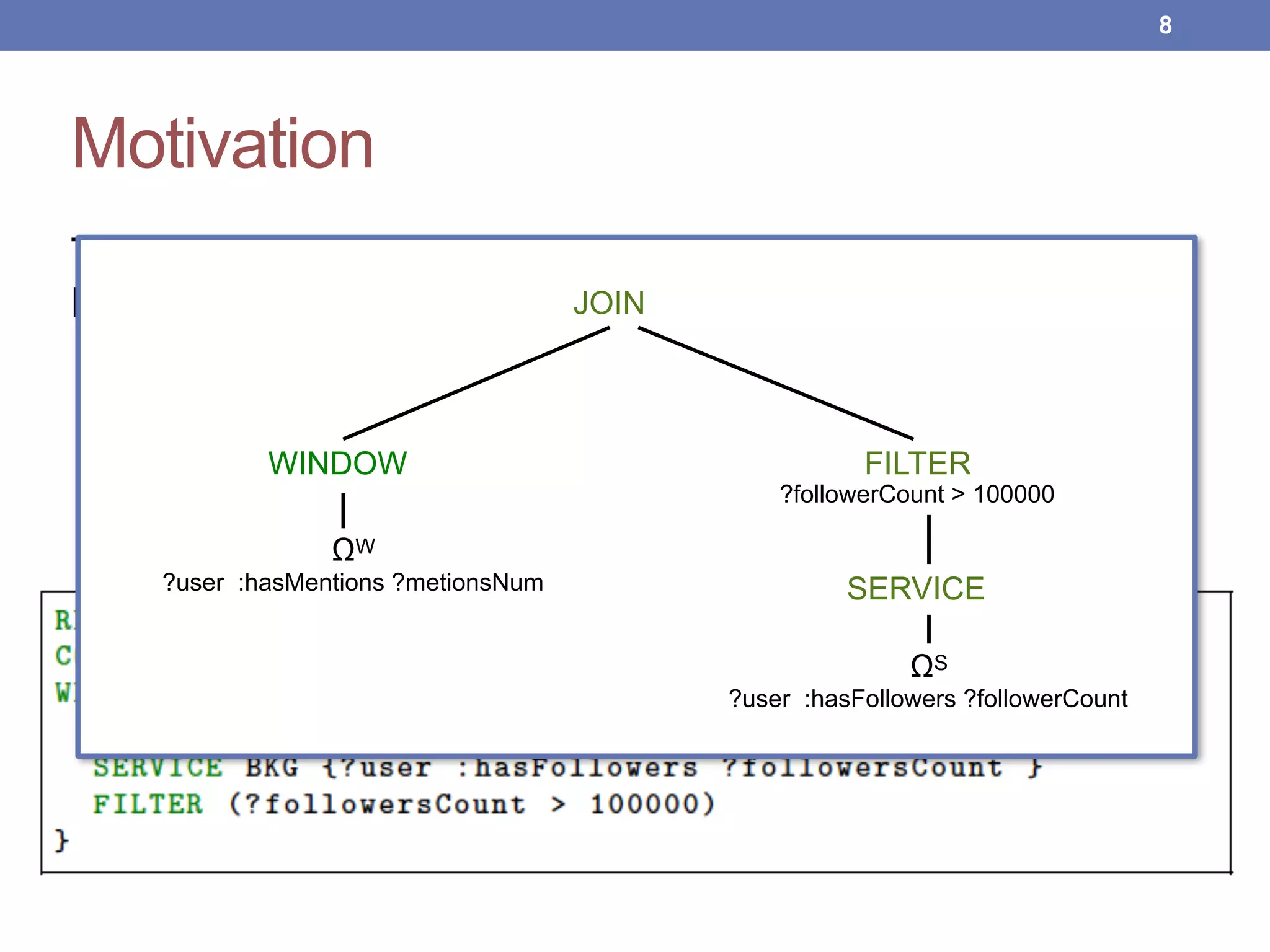
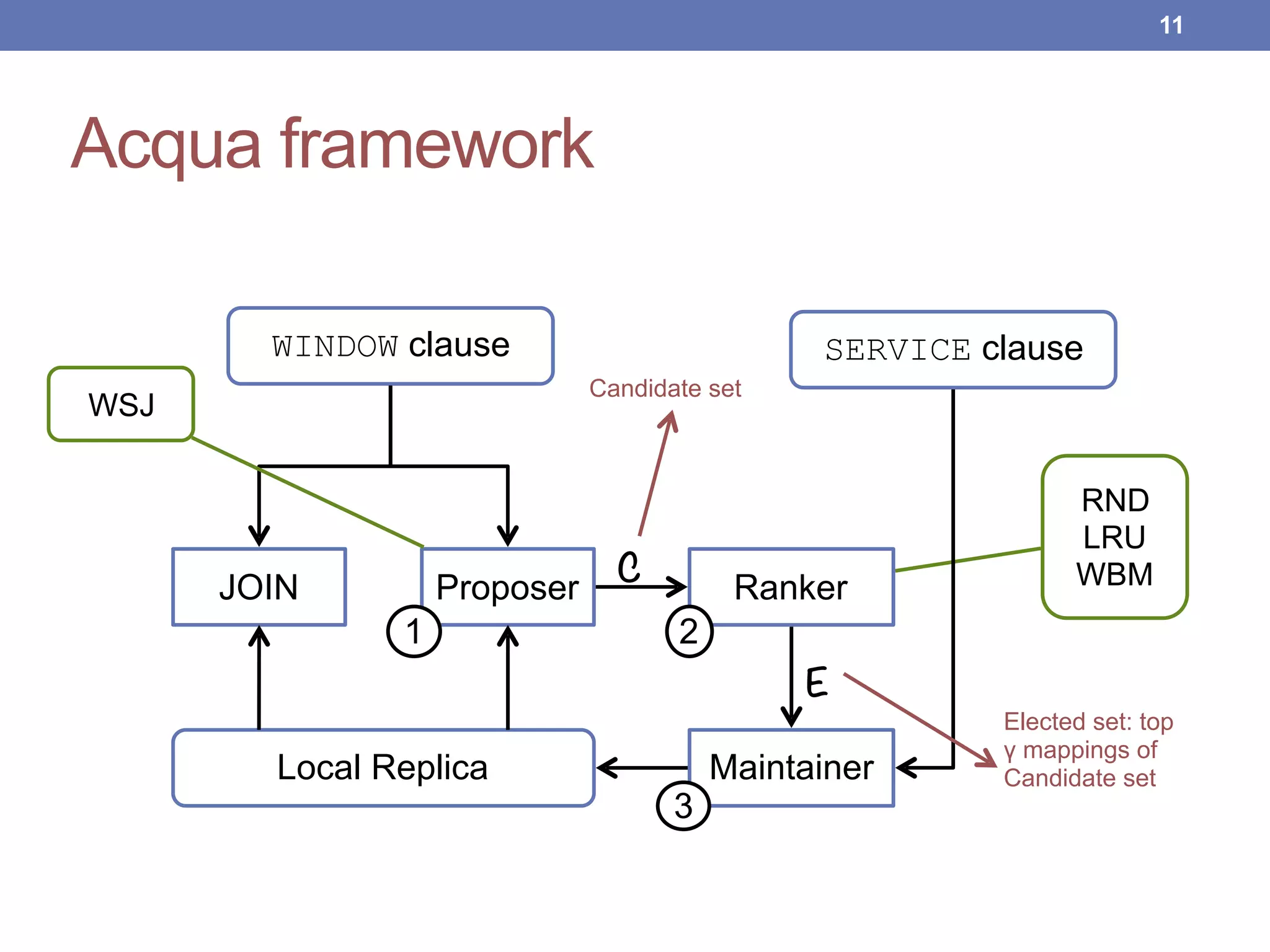
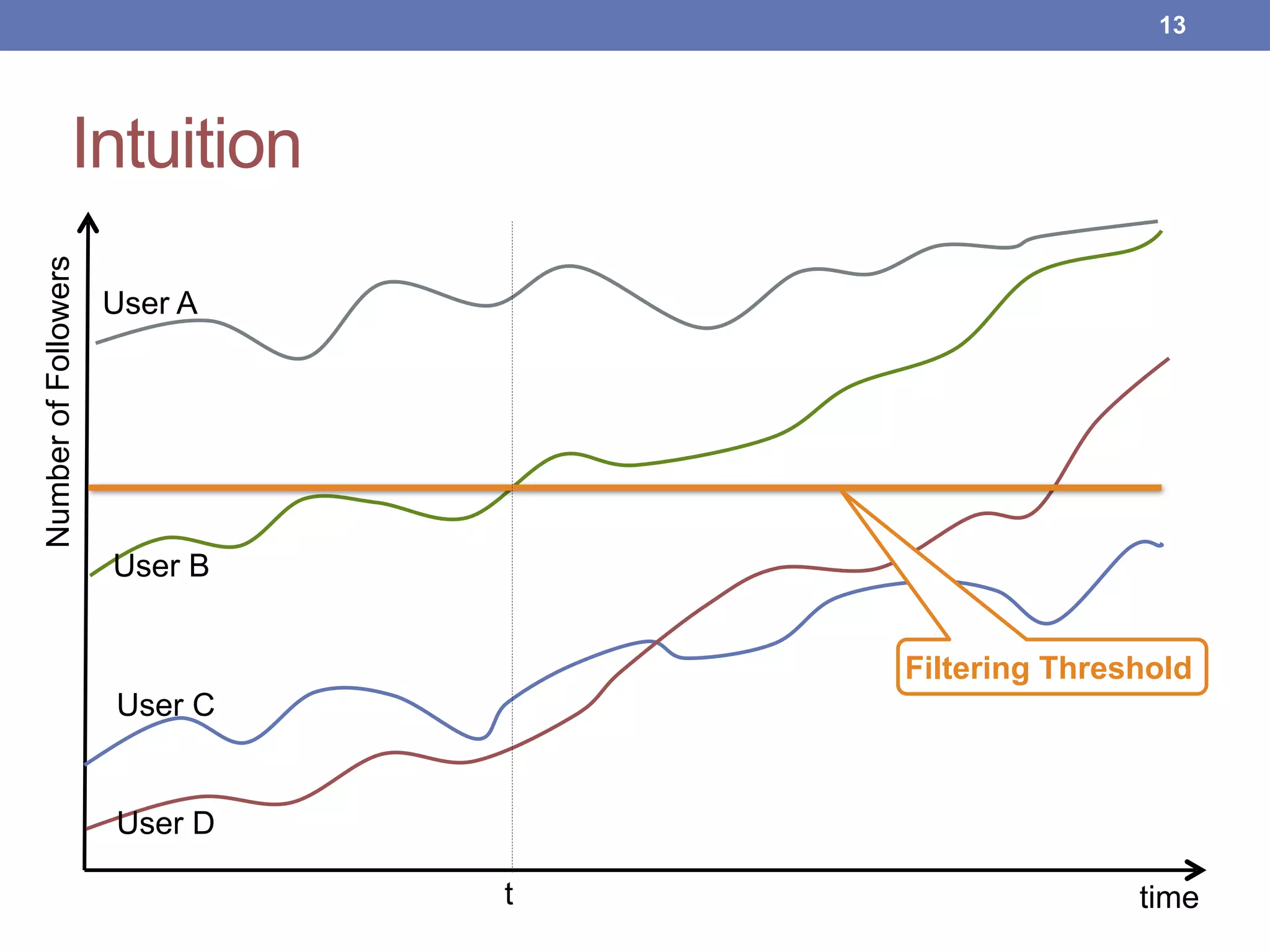
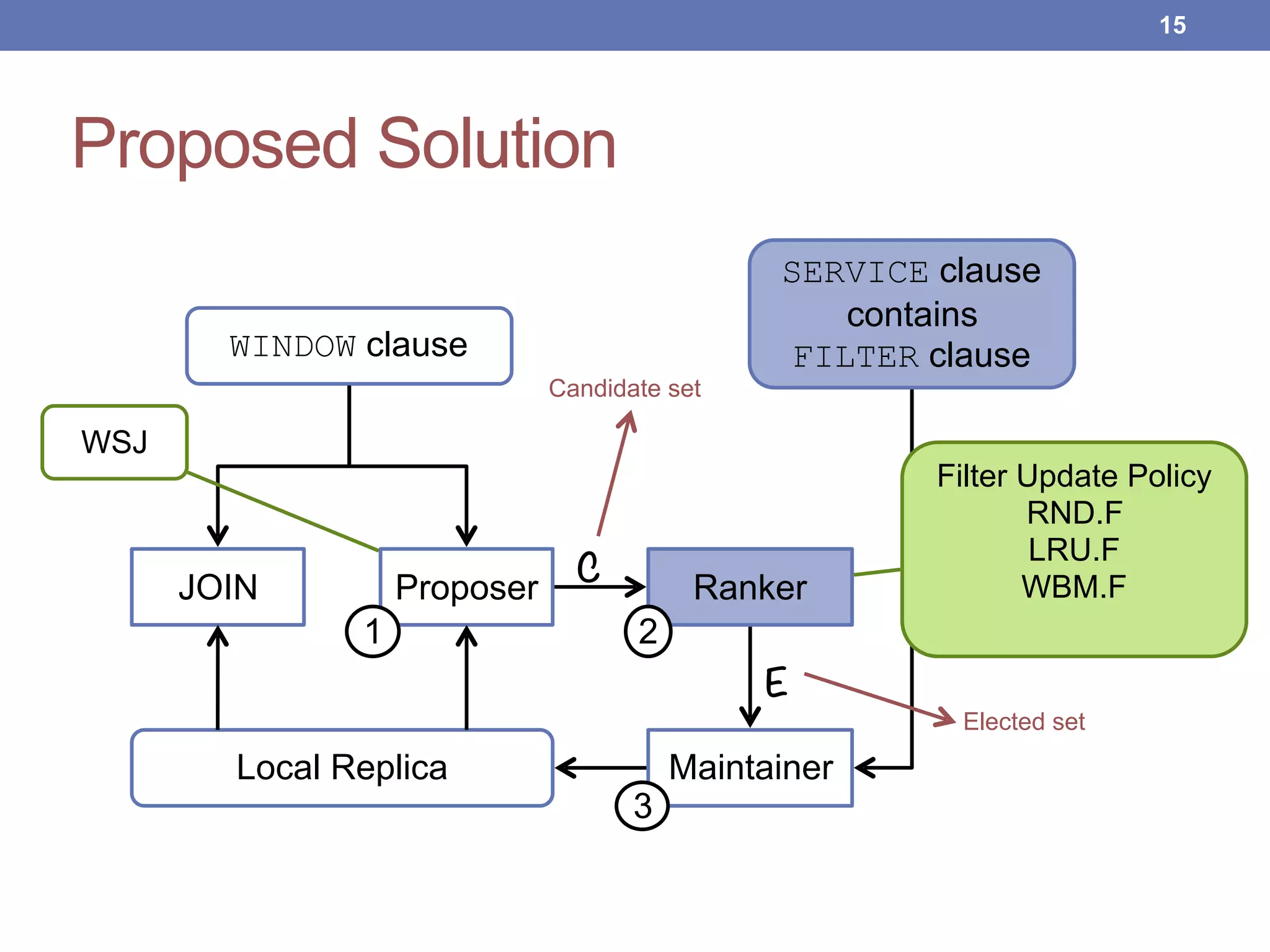
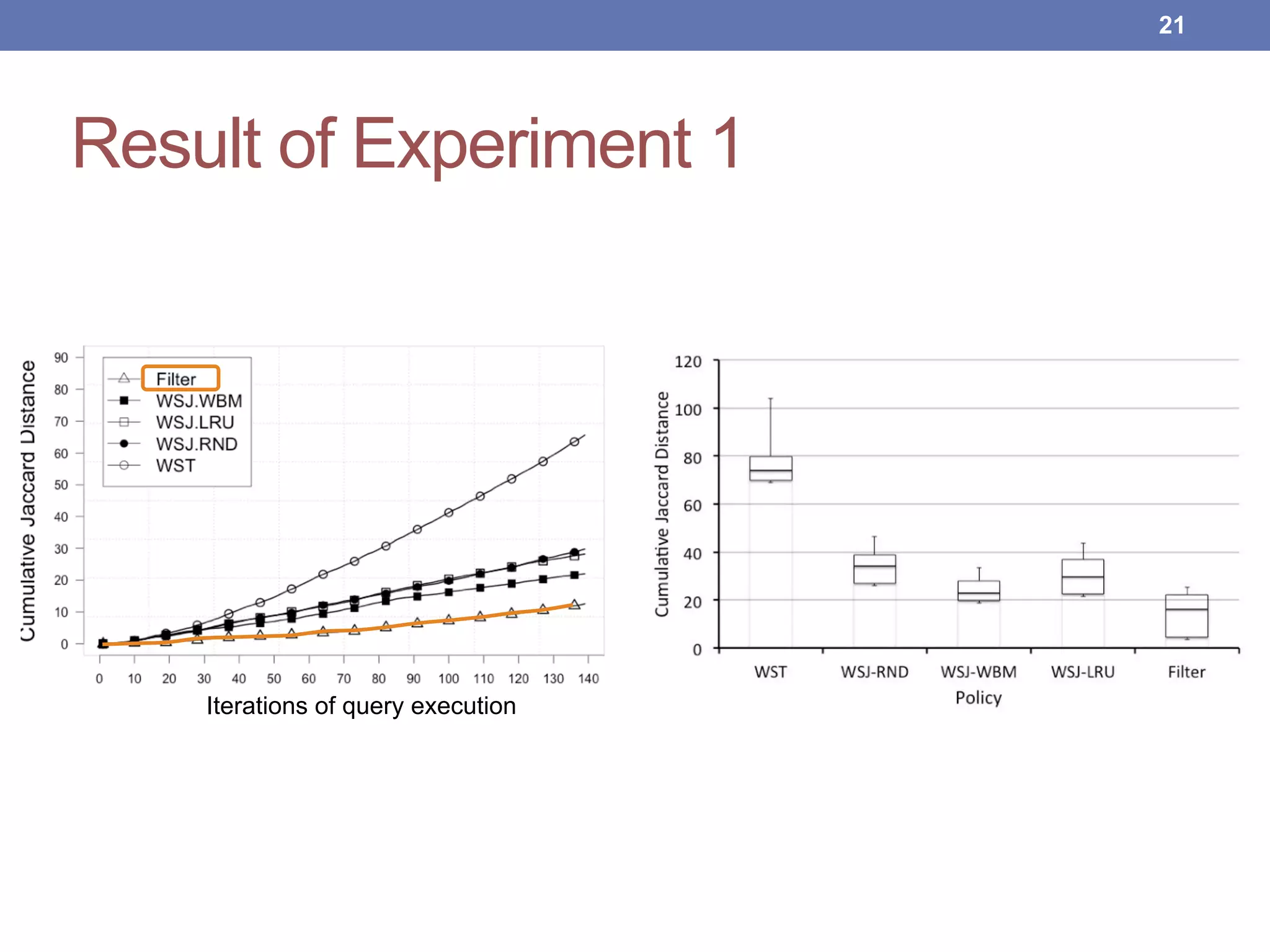
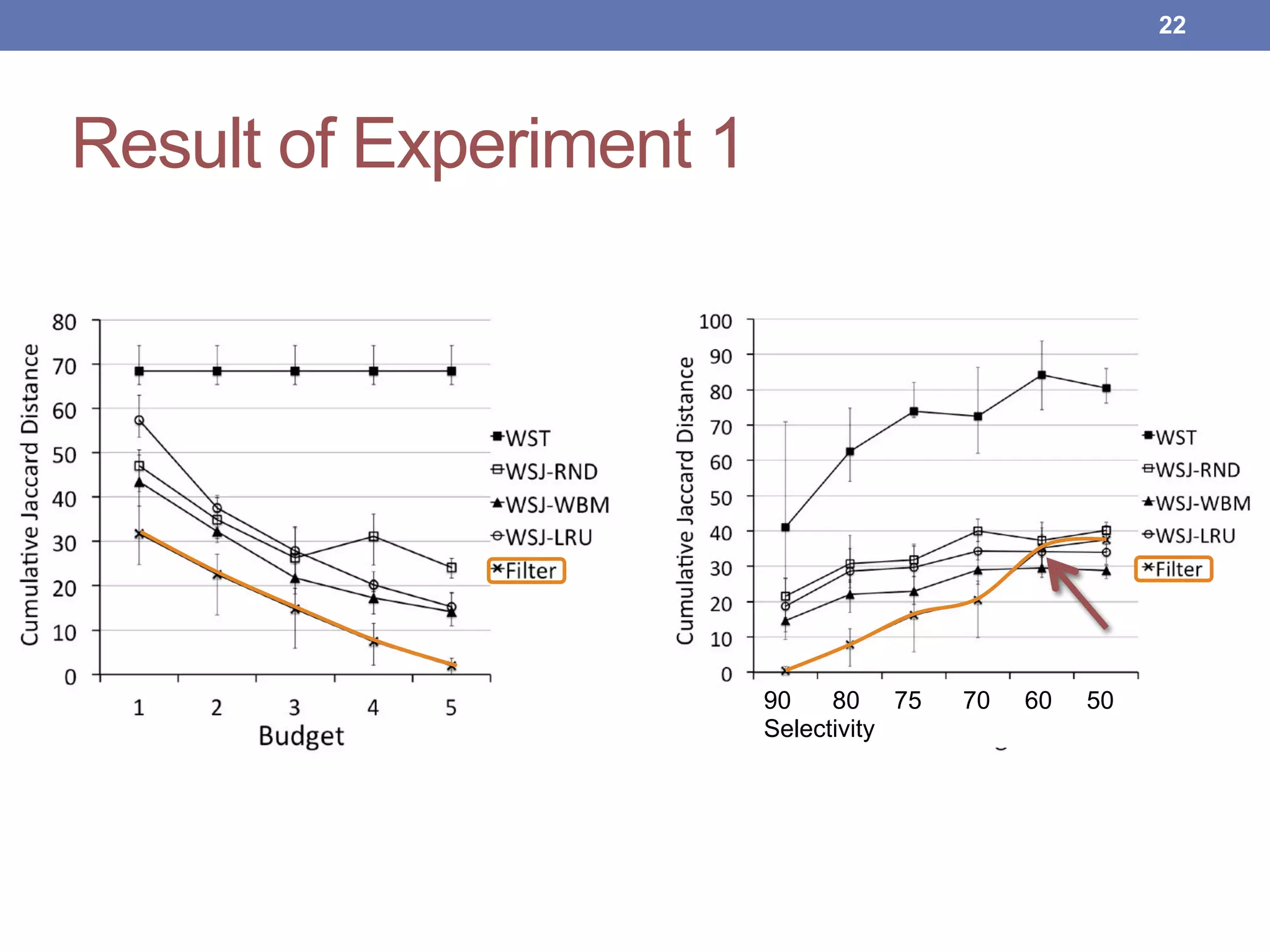
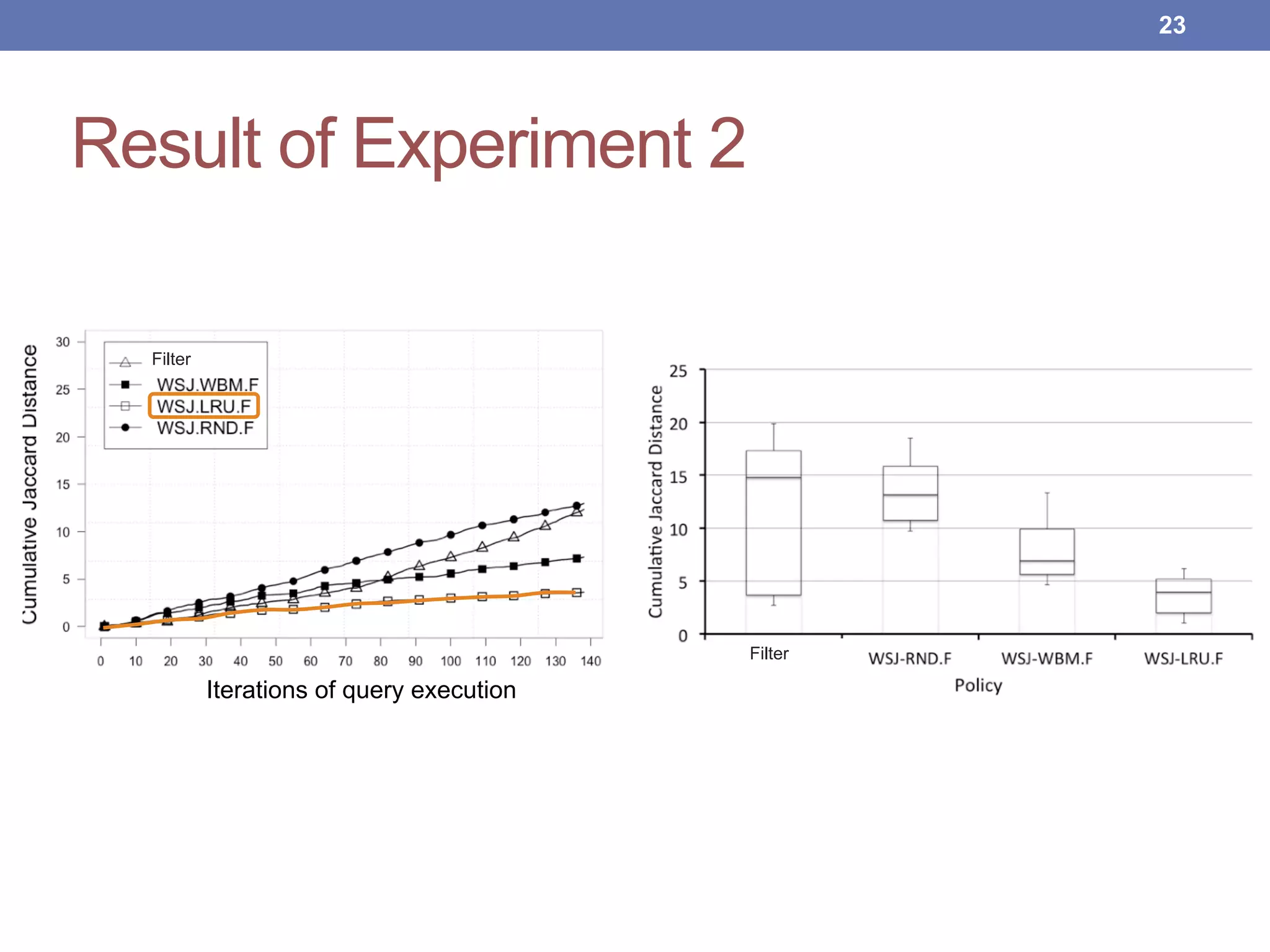
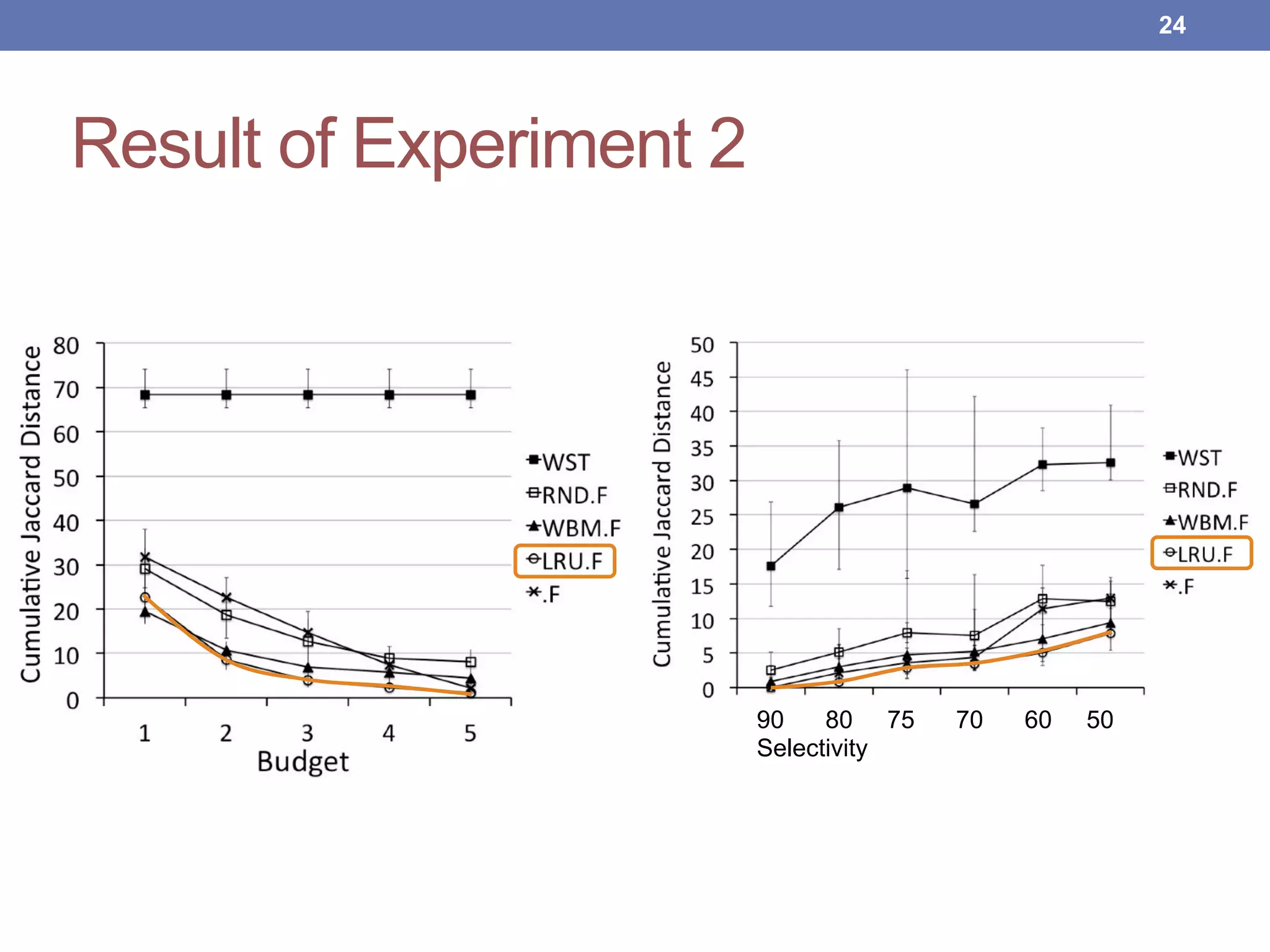
This document proposes new maintenance policies for refreshing a local replica used to continuously evaluate SPARQL queries over streaming and background linked data when the queries contain a FILTER clause. It introduces the problem, motivates the research question, and hypothesizes that policies focusing on mappings close to the filter threshold will keep the replica fresher. Experimental results show the proposed "Filter Update Policy" outperforms existing policies from state-of-the-art approaches when selectivity is over 60%, and combining it with other policies performs even better. Future work is outlined to broaden the class of supported queries.