Download as ODP, PPTX







































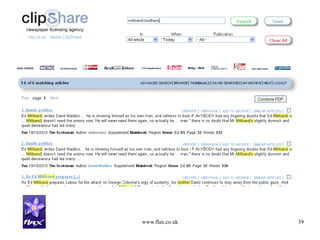
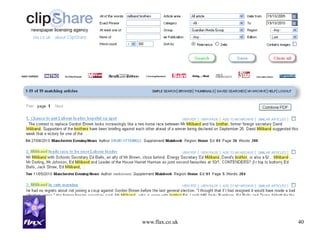
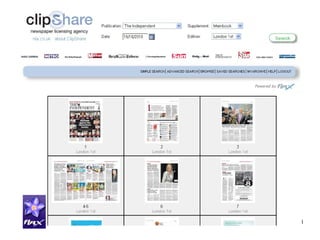


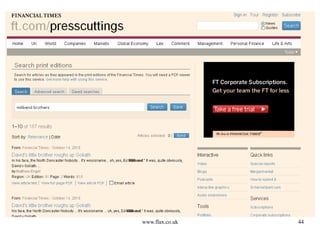
























This document discusses building news search systems using open source technologies. It describes indexing news content at high volumes, searching with filters and facets, and ensuring systems can scale as content grows. Examples given include the NLA Clipshare system with 20 million news stories and the Financial Times press cuttings search web service. Monitoring news also requires non-traditional search to reflect complex client needs.





















































