
Download to read offline




























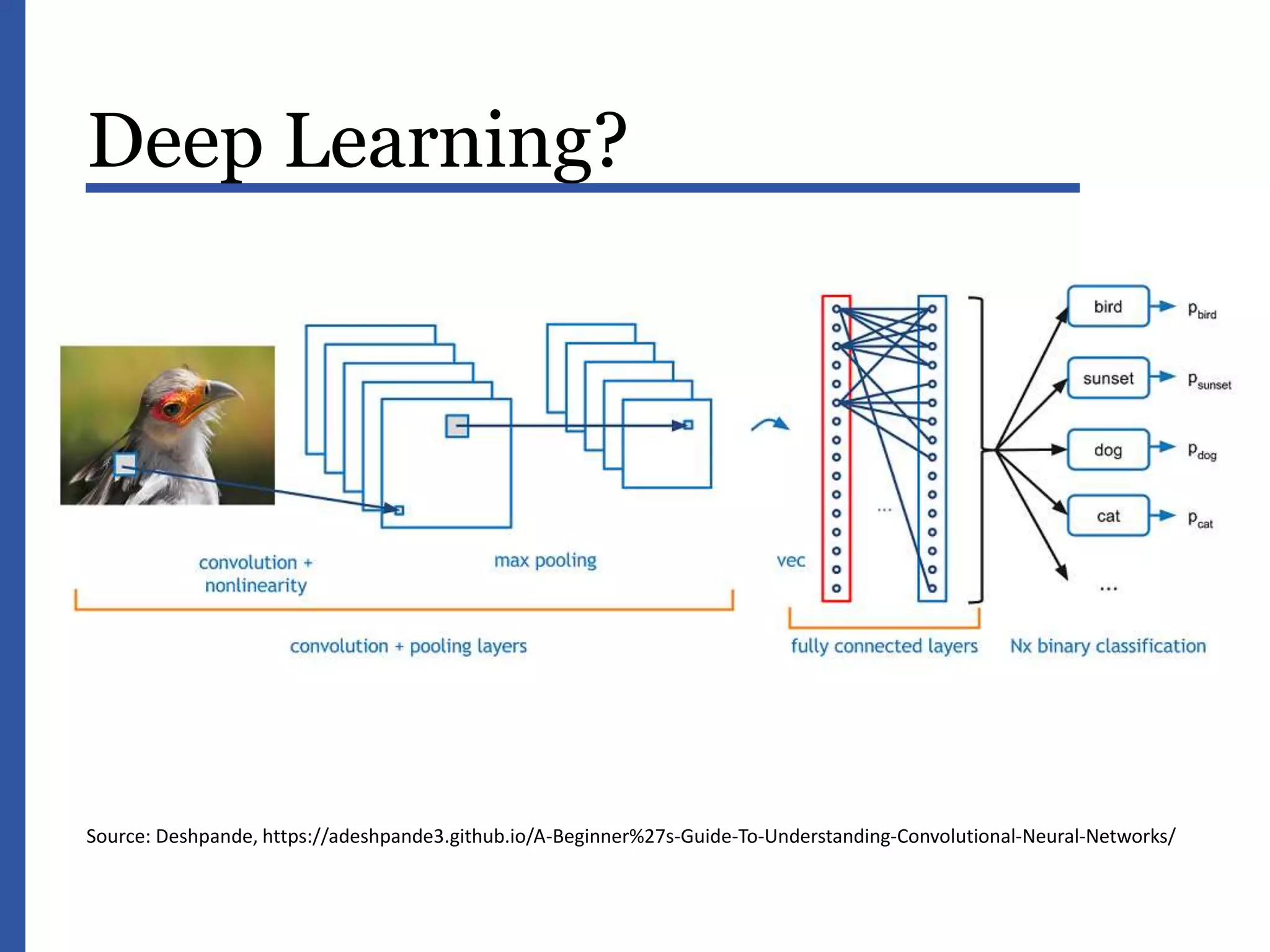

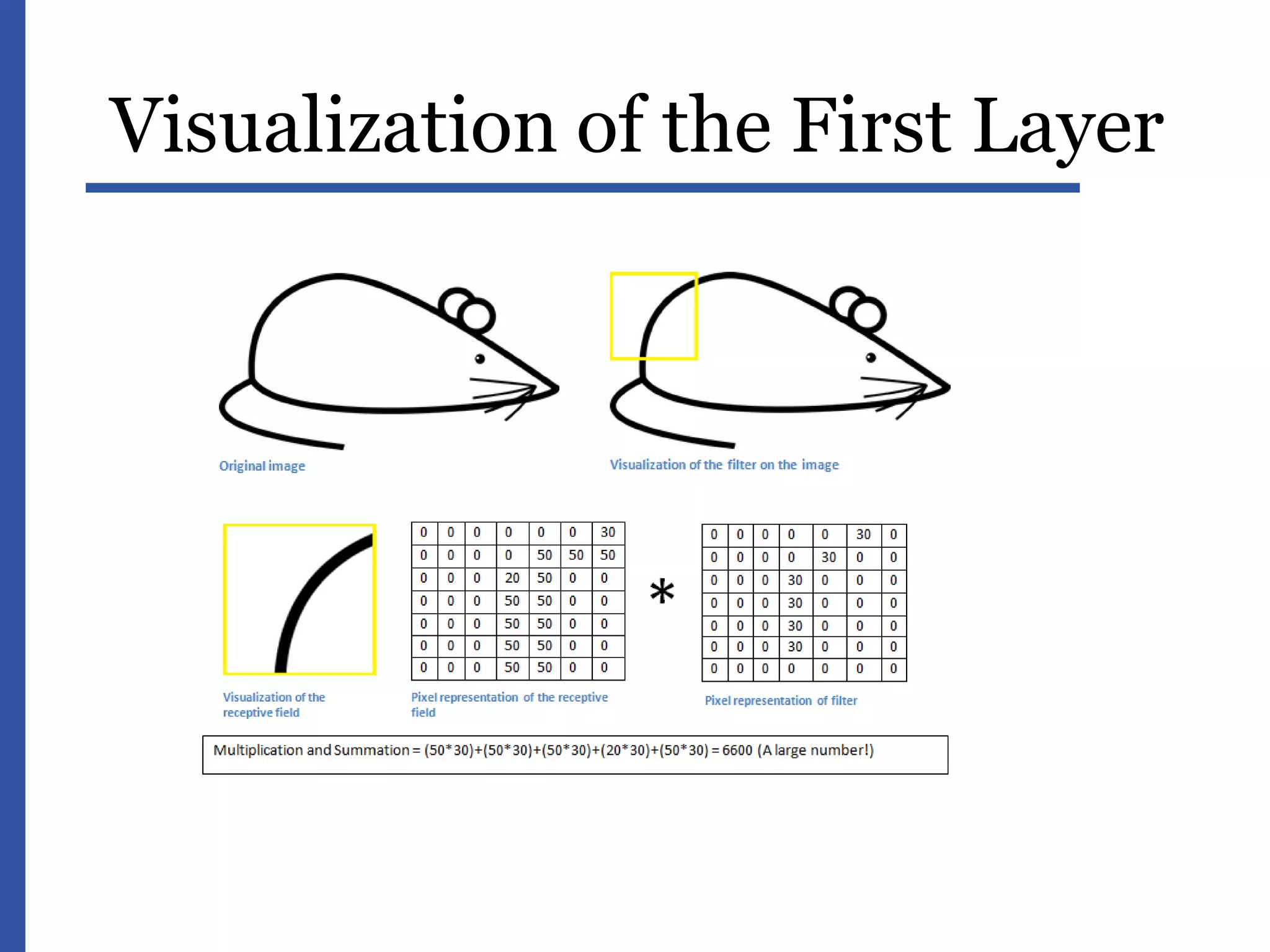



This document provides an introduction to data science and machine learning. It discusses the era of big data and jobs in data science. It defines data science as an interdisciplinary field at the interface of statistics, computer science, and mathematics. The document describes supervised and unsupervised machine learning algorithms such as linear regression, decision trees, support vector machines, and clustering. It also discusses applications of machine learning like recommendations and content filtering. Deep learning and neural networks are explained with examples of image analysis. Common data issues are identified such as data integration, quality, and value.






















































































