Web Semantics. Cutting Edge and Future Directions in Healthcare Sarika Jain
Web Semantics. Cutting Edge and Future Directions in Healthcare Sarika Jain
Web Semantics. Cutting Edge and Future Directions in Healthcare Sarika Jain
Web Semantics. Cutting Edge and Future Directions in Healthcare Sarika Jain
Web Semantics. Cutting Edge and Future Directions in Healthcare Sarika Jain
1.
Visit https://ebookmass.com todownload the full version and
browse more ebooks or textbooks
Web Semantics. Cutting Edge and Future Directions
in Healthcare Sarika Jain
_____ Press the link below to begin your download _____
https://ebookmass.com/product/web-semantics-cutting-edge-
and-future-directions-in-healthcare-sarika-jain/
Access ebookmass.com now to download high-quality
ebooks or textbooks
2.
We believe theseproducts will be a great fit for you. Click
the link to download now, or visit ebookmass.com
to discover even more!
Cutting Edge. Starter Student's Book Sarah Cunningham
https://ebookmass.com/product/cutting-edge-starter-students-book-
sarah-cunningham/
Semantic Web for Effective Healthcare Systems Vishal Jain
https://ebookmass.com/product/semantic-web-for-effective-healthcare-
systems-vishal-jain/
Power-Sharing in Europe: Past Practice, Present Cases, and
Future Directions Soeren Keil
https://ebookmass.com/product/power-sharing-in-europe-past-practice-
present-cases-and-future-directions-soeren-keil/
Cutting Edge Intermediate Students' Book with DVD and
MyEnglishLab Pack 3rd Revised edition Edition Peter Moor
https://ebookmass.com/product/cutting-edge-intermediate-students-book-
with-dvd-and-myenglishlab-pack-3rd-revised-edition-edition-peter-moor/
3.
Human Resource InformationSystems: Basics, Applications,
and Future Directions 4th Edition, (Ebook PDF)
https://ebookmass.com/product/human-resource-information-systems-
basics-applications-and-future-directions-4th-edition-ebook-pdf/
Sports, exercise, and nutritional genomics: Current status
and future directions 1st Edition Ildus I. Ahmetov
https://ebookmass.com/product/sports-exercise-and-nutritional-
genomics-current-status-and-future-directions-1st-edition-ildus-i-
ahmetov/
Breast MRI: State of the Art and Future Directions 1st
Edition Katja Pinker (Editor)
https://ebookmass.com/product/breast-mri-state-of-the-art-and-future-
directions-1st-edition-katja-pinker-editor/
Beyond Semantics and Pragmatics Gerhard Preyer
https://ebookmass.com/product/beyond-semantics-and-pragmatics-gerhard-
preyer/
Cutting Teeth: A Novel Chandler Baker
https://ebookmass.com/product/cutting-teeth-a-novel-chandler-baker/
WEB
SEMANTICS
Cutting Edge andFuture Directions
in Healthcare
Edited by
SARIKA JAIN
Department of Computer Applications, National Institute of Technology Kurukshetra, Haryana, India
VISHAL JAIN
Department of Computer Science and Engineering, School of Engineering and Technology, Sharda University,
Greater Noida, Uttar Pradesh, India
VALENTINA EMILIA BALAS
Faculty of Engineering, Aurel Vlaicu University of Arad, Romania
Contents
List of contributorsix
Preface xi
1. Semantic intelligence - An overview
Sarika Jain
1.1 Overview 1
Section I
Representation
2. Convology: an ontology
for conversational agents in
digital health
Mauro Dragoni, Giuseppe Rizzo and Matteo A. Senese
2.1 Introduction 7
2.2 Background 9
2.3 The construction of convology 10
2.4 Inside convology 12
2.5 Availability and reusability 16
2.6 Convology in action 17
2.7 Resource sustainability and maintenance 19
2.8 Conclusions and future work 20
References 21
3. Conversion between semantic
data models: the story so far, and the
road ahead
Shripriya Dubey, Archana Patel and Sarika Jain
3.1 Introduction 23
3.2 Resource Description Framework as a semantic
data model 24
3.3 Related work 25
3.4 Conceptual evaluation 27
3.5 Findings 28
3.6 Concluding remarks 29
References 30
4. Semantic interoperability: the future of
healthcare
Rashmi Burse, Michela Bertolotto, Dympna O’Sullivan
and Gavin McArdle
4.1 Introduction 31
4.2 Semantic web technologies 32
4.3 Syntactic interoperability 37
4.4 Semantic interoperability 40
4.5 Contribution of semantic web
technology to aid healthcare
interoperability 46
4.6 Discussion and future work 49
4.7 Conclusion 51
References 51
5. A knowledge graph of medical
institutions in Korea
Haklae Kim
5.1 Introduction 55
5.2 Related work 56
5.3 Medical institutions in Korea 57
5.4 Knowledge graph of medical institutions 60
5.5 Conclusion 66
References 67
6. Resource description framework based
semantic knowledge graph for clinical
decision support systems
Ravi Lourdusamy and Xavierlal J. Mattam
6.1 Introduction 69
6.2 Knowledge representation using RDF 71
6.3 Simple knowledge organization system 75
6.4 Semantic knowledge graph 77
6.5 Semantic knowledge graph for clinical
decision support systems 81
6.6 Discussion and future possibilities 83
6.7 Conclusion 84
References 84
v
9.
7. Probabilistic, syntactic,and semantic
reasoning using MEBN, OWL, and PCFG
in healthcare
Shrinivasan Patnaikuni and Sachin R. Gengaje
7.1 Introduction 87
7.2 Multientity Bayesian networks 89
7.3 Semantic web and uncertainty 90
7.4 MEBN and ontology web language 91
7.5 MEBN and probabilistic context-free
grammar 92
7.6 Summary 93
References 93
Section II
Reasoning
8. The connected electronic health record:
a semantic-enabled, flexible, and unified
electronic health record
Salma Sassi and Richard Chbeir
8.1 Introduction 97
8.2 Motivating scenario: smart health unit 99
8.3 Literature review 100
8.4 Our connected electronic health record system
approach 105
8.5 Implementation 110
8.6 Experimental results 111
8.7 Conclusion and future works 113
References 114
9. Ontology-supported rule-based
reasoning for emergency management
Sarika Jain, Sonia Mehla and Jan Wagner
9.1 Introduction 117
9.2 Literature review 119
9.3 System framework 120
9.4 Inference of knowledge 122
9.5 Conclusion and future work 127
References 127
10. Health care cube integrator for health
care databases
Shivani A Trivedi, Monika Patel and Sikandar Patel
10.1 Introduction: state-of-the-art health care
system 129
10.2 Research methods and literature findings of
research publications 131
10.3 HCI conceptual framework and designing
framework 136
10.4 Implementation framework and experimental
setup 140
10.5 Result analysis, conclusion, and future
enhancement of work 148
Acknowledgment 149
References 149
11. Smart mental healthcare systems
Sumit Dalal and Sarika Jain
11.1 Introduction 153
11.2 Classification of mental healthcare 154
11.3 Challenges of a healthcare environment 155
11.4 Benefits of smart mental healthcare 158
11.5 Architecture 159
11.6 Conclusion 161
References 162
12. A meaning-aware information
search and retrieval framework for
healthcare
V.S. Anoop, Nikhil V. Chandran and S. Asharaf
12.1 Introduction 165
12.2 Related work 167
12.3 Semantic search and information retrieval in
healthcare 170
12.4 A framework for meaning-aware healthcare
information extraction from unstructured
text data 170
12.5 Future research dimensions 174
12.6 Conclusion 174
Key terms and definitions 174
References 175
vi Contents
10.
13. Ontology-based intelligent
decisionsupport systems:
A systematic approach
Ramesh Saha, Sayani Sen, Jayita Saha, Asmita Nandy,
Suparna Biswas and Chandreyee Chowdhury
13.1 Introduction 177
13.2 Enabling technologies to implement decision
support system 178
13.3 Role of ontology in DSS for knowledge
modeling 182
13.4 QoS and QoE parameters in decision
support systems for healthcare 187
13.5 Conclusion 190
References 191
14. Ontology-based decision-making
Mark Douglas de Azevedo Jacyntho and Matheus D. Morais
14.1 Introduction 195
14.2 Issue-Procedure Ontology 198
14.3 Issue-Procedure Ontology for Medicine 203
14.4 Conclusion 208
References 208
15. A new method for profile
identification using ontology-based
semantic similarity
Abdelhadi Daoui, Noreddine Gherabi and Abderrahim Marzouk
15.1 Introduction 211
15.2 Proposed method 212
15.3 Conclusion 218
References 218
16. Semantic similarity based descriptive
answer evaluation
Mohammad Shaharyar Shaukat, Mohammed Tanzeem,
Tameem Ahmad and Nesar Ahmad
16.1 Introduction 221
16.2 Literature survey 222
16.3 Proposed system 223
16.4 Algorithm 227
16.5 Data set 227
16.6 Results 228
16.7 Conclusion and discussion 229
Acknowledgments 230
References 230
17. Classification of genetic mutations
using ontologies from clinical documents
and deep learning
Punam Bedi, Shivani, Neha Gupta,
Priti Jagwani and Veenu Bhasin
17.1 Introduction 233
17.2 Clinical Natural Language Processing 234
17.3 Clinical Natural Language Processing
(Clinical NLP) techniques 235
17.4 Clinical Natural Language Processing and
Semantic Web 242
17.5 Case study: Classification of Genetic
Mutation using Deep Learning and Clinical
Natural Language Processing 245
17.6 Conclusion 249
References 249
Section III
Security
18. Security issues for the Semantic Web
Prashant Pranav, Sandip Dutta and Soubhik Chakraborty
18.1 Introduction 253
18.2 Related work 258
18.3 Security standards for the Semantic
Web 259
18.4 Different attacks on the Semantic Web 262
18.5 Drawbacks of the existing privacy and
security protocols in W3C social web
standards 263
18.6 Semantic attackers 264
18.7 Privacy and Semantic Web 264
18.8 Directions for future security protocols
for the Semantic Web 265
18.9 Conclusion 266
References 266
Index 269
vii
Contents
11.
List of contributors
NesarAhmad Department of Computer
Engineering, Zakir Husain College of
Engineering and Technology, Aligarh
Muslim University, Aligarh, India
Tameem Ahmad Department of Computer
Engineering, Zakir Husain College of
Engineering and Technology, Aligarh
Muslim University, Aligarh, India
V.S. Anoop Kerala Blockchain Academy,
Indian Institute of Information Technology
and Management Kerala (IIITM-K),
Thiruvananthapuram, India
S. Asharaf Indian Institute of Information
Technology and Management - Kerala
(IIITM-K), Thiruvananthapuram, India
Punam Bedi Department of Computer Science,
University of Delhi, Delhi, India
Michela Bertolotto School of Computer Science,
University College Dublin, Dublin, Ireland
Veenu Bhasin P.G.D.A.V. College, University
of Delhi, Delhi, India
Suparna Biswas Department of Computer
Science & Engineering, Maulana Abul Kalam
Azad University of Technology, Kolkata, India
Rashmi Burse School of Computer Science,
University College Dublin, Dublin, Ireland
Soubhik Chakraborty Department of
Mathematics, Birla Institute of Technology,
Mesra, Ranchi, India
Nikhil V. Chandran Data Engineering Lab,
Indian Institute of Information Technology
and Management - Kerala (IIITM-K),
Thiruvananthapuram, India
Richard Chbeir Univ Pau & Pays Adour, E2S/
UPPA, LIUPPA, EA3000, Anglet, France
Chandreyee Chowdhury Department of
Computer Science & Engineering, Jadavpur
University, Kolkata, India
Sumit Dalal National Institute of Technology
Kurukshetra, Haryana, India
Abdelhadi Daoui Department of Mathematics
and Computer Science, Hassan 1st
University, FST, Settat, Morocco
Matheus D. Morais Coordination of
Informatics, Fluminense Federal Institute,
Campos dos Goytacazes, Rio de Janeiro,
Brazil
Mark Douglas de Azevedo Jacyntho
Coordination of Informatics, Fluminense
Federal Institute, Campos dos Goytacazes,
Rio de Janeiro, Brazil
Mauro Dragoni Fondazione Bruno Kessler,
Trento, Italy
Shripriya Dubey Department of Computer
Applications, National Institute of
Technology Kurukshetra, Haryana, India
Sandip Dutta Department of Computer
Science and Engineering, Birla Institute of
Technology, Mesra, Ranchi, India
Sachin R. Gengaje Department of Computer
Science and Engineering, Walchand Institute
of Technology, Solapur, Maharashtra, India
Noreddine Gherabi Sultan Moulay Slimane
University, ENSAK, LASTI Laboratory,
Khouribga, Morocco
Neha Gupta Department of Computer Science,
University of Delhi, Delhi, India
Priti Jagwani Aryabhatta College, University
of Delhi, Delhi, India
Sarika Jain Department of Computer
Applications, National Institute of
Technology Kurukshetra, Haryana, India
Haklae Kim Chung-Ang University, Seoul,
South Korea
Ravi Lourdusamy Sacred Heart College
(Autonomous), Tirupattur, India
ix
12.
Abderrahim Marzouk Departmentof
Mathematics and Computer Science,
Hassan 1st University, FST, Settat, Morocco
Xavierlal J. Mattam Sacred Heart College
(Autonomous), Tirupattur, India
Gavin McArdle School of Computer Science,
University College Dublin, Dublin, Ireland
Sonia Mehla National Institute of Technology
Kurukshetra, Haryana, India
Asmita Nandy Department of Computer
Science & Engineering, Jadavpur University,
Kolkata, India
Dympna O’Sullivan School of Computer
Science, Technological University Dublin,
Dublin, Ireland
Archana Patel Institute of Computer Science,
Freie Universität, Berlin, Germany
Monika Patel S.K. Patel Institute of Management
and Computer Studies-MCA, Kadi Sarva
Vishwavidyalaya, India
Sikandar Patel National Forensic Sciences
University, Gandhinagar, India
Shrinivasan Patnaikuni Department of
Computer Science and Engineering,
Walchand Institute of Technology, Solapur,
Maharashtra, India
Prashant Pranav Department of Computer
Science and Engineering, Birla Institute of
Technology, Mesra, Ranchi, India
Giuseppe Rizzo LINKS Foundation, Torino,
Italy
Jayita Saha Department of Artificial Intelligence
and Data Science, Koneru Lakshmaiah
Education Foundation Deemed to be
University, Hyderabad, India
Ramesh Saha Department of Information
Technology, Gauhati University, Guwahati,
Assam, India
Salma Sassi VPNC Lab., FSJEGJ, University of
Jendouba, Jendouba, Tunisia
Sayani Sen Department of Computer
Application, Sarojini Naidu College for
Women, Kolkata, India
Matteo A. Senese LINKS Foundation, Torino,
Italy
Mohammad Shaharyar Shaukat Technical
University of Munich, Germany
Shivani Department of Computer Science,
University of Delhi, Delhi, India
Mohammed Tanzeem Adobe, India
Shivani A Trivedi S.K. Patel Institute of
Management and Computer Studies-MCA,
Kadi Sarva Vishwavidyalaya, India
Jan Wagner RheinMain University of Applied
Sciences, Germany
x List of contributors
13.
Preface
Over the lastdecade, we have witnessed
an increasing use of Web Semantics as a
vital and ever-growing field. It incorporates
various subject areas contributing to the
development of a knowledge-intensive data
web. In parallel to the movement of con-
cept from data to knowledge, we are now
also experiencing the movement of web
from document model to data model where
the main focus is on data compared to the
process. The underlying idea is making the
data machine understandable and process-
able. In light of these trends, conciliation of
Semantic and the Web is of paramount
importance for further progress in the area.
The 17 chapters in this volume, authored
by key scientists in the field are preceded
by an introduction written by one of the
volume editors, making a total of 18 chap-
ters. Chapter 1, Introduction, by Sarika Jain
provides an overview of technological
trends and perspectives in Web Semantics,
defines Semantic Intelligence, and discusses
the technologies encompassing the same in
view of their application within enterprises
as well as in web. In all, 76 chapter propo-
sals were submitted for this volume mak-
ing a 22% acceptance rate. The chapters
have been divided into three sections as
Representation, Reasoning, and Security.
• Representation: The semantics have to be
encoded with data by virtue of
technologies that formally represent
metadata. When semantics are
embedded in data, it offers significant
advantages for reasoning and
interoperability.
• Reasoning: When “Semantic Web” will
finally happen, machine will be able to
talk to machines materializing the so-
called “intelligent agents.” The services
offered will be useful for web as well as
for the management of knowledge
within an organization.
• Security: In this new setting, traditional
security measures will not be
suitable anymore; and the focus will
move to trust and provenance. The
semantic security issues are required to
be addressed by the security
professionals and the semantic
technologists.
This book will help the instructors and
students taking courses of Semantic Web
getting abreast of cutting edge and future
directions of semantic web, hence provid-
ing a synergy between healthcare processes
and semantic web technologies. Many
books are available in this field with two
major problems. Either they are very
advanced and lack providing a sufficiently
detailed explanation of the approaches, or
they are based on a specific theme with
limited scope, hence not providing details
on crosscutting areas applied in the web
semantic. This book covers the research
and practical issues and challenges, and
Semantic Web applications in specific con-
texts (in this case, healthcare). This book
has varied audience and spans industrial
professionals, researchers, and academi-
cians working in the field of Web
Semantics. Researchers and academicians
will find a comprehensive study of the state
xi
14.
of the artand an outlook into research chal-
lenges and future perspectives. The industry
professionals and software developers will
find available tools and technologies to use,
algorithms, pseudocodes, and implementa-
tion solutions. The administrators will find a
comprehensive spectrum of the latest view-
point in different areas of Web Semantics.
Finally, lecturers and students require all of
the above, so they will gain an interesting
insight into the field. They can benefit in
preparing their problem statements and
finding ways to tackle them.
The book is structured into three sections
that group chapters into three otherwise
related disections:
Representation
The first section on Representation com-
prises six chapters that specifically focus on
the problem of choosing a data model for
representing and storage of data for the Web.
Chapter 2, Convology: an ontology for con-
versational agents in digital health by
Dragoni et al. propose an ontology, namely,
Convology, aiming to describe conversational
scenarios with the scope of providing a tool
that, once deployed into a real-world applica-
tion, allows to ease the management and
understanding of the entire dialog workflow
between users, physicians, and systems. The
authors have integrated Convology into a liv-
ing lab concerning the adoption of conversa-
tional agents for supporting the self-
management of patients affected by asthma.
Dubey et al. in Chapter 3, Conversion
between semantic data models: the story so
far, and the road ahead, provide the trends in
converting between various semantic data
models and reviews the state of the art of the
same. In Chapter 4, Semantic interoperability:
the future of healthcare Burse et al. have
beautifully elaborated the syntactic and
semantic interoperability issues in healthcare.
They have reviewed the various healthcare
standards in an attempt to solve the interop-
erability problem at a syntactic level and then
moves on to examine medical ontologies
developed to solve the problem at a semantic
level. The chapter explains the features of
semantic web technology that can be lever-
aged at each level. A literature survey is car-
ried out to gage the current contribution of
semantic web technologies in this area along
with an analysis of how semantic web tech-
nologies can be improved to better suit the
health-informatics domain and solve the
healthcare interoperability challenge. Haklae
Kim in his Chapter 5, A knowledge graph of
medical institutions in Korea, has proposed a
knowledge model for representing medical
institutions and their characteristics based on
related laws. The author also constructs a
knowledge graph that includes all medical
institutions in Korea with an aim to enable
users to identify appropriate hospitals or
other institutions according to their require-
ments. Chapter 6, Resource description
framework based semantic knowledge graph
for clinical decision support systems, by
Lourdusamy and Mattam advocates the use
of Semantic Knowledge Graphs as the repre-
sentation structure for Clinical Decision
Support Systems. Patnaikuni and Gengaje in
Chapter 7, Probabilistic, syntactic, and seman-
tic reasoning using MEBN, OWL, and PCFG
in healthcare, exploit the key concepts and
terminologies used for representing and rea-
soning uncertainties structurally and semanti-
cally with a case study of COVID-19 Corona
Virus. The key technologies are Bayesian net-
works, Multi-Entity Bayesian Networks,
Probabilistic Ontology Web Language, and
probabilistic context-free grammars.
xii Preface
15.
Reasoning
At the scaleof www, logic-based reason-
ing is not appropriate and poses numerous
challenges. As already stated in different
chapters of Section 1, RDF provides a
machine-processable syntax to the data on
the web. Reasoning on Semantic Web
involves deriving facts and relationships
that are not explicit in the knowledge base.
This section groups 10 contributions based
on reasoning within the knowledge bases.
There is an absence of a reference model
for describing the health data and their
sources and linking these data with their
contexts. Chapter 8, The connected elec-
tronic health record: a semantic-enabled,
flexible, and unified electronic health
record, by Sassi and Chbeir addresses this
problem and introduces a semantic-
enabled, flexible, and unified electronic
health record (EHR) for patient monitoring
and diagnosis with Medical Devices. The
approach exploits semantic web technolo-
gies and the HL7 FHIR standard to provide
semantic connected EHR that will facilitate
data interoperability, integration, informa-
tion search and retrieval, and automatic
inference and adaptation in real-time. Jain
et al. in Chapter 9, Ontology-supported
rule-based reasoning for emergency man-
agement, have proposed an ontology-
supported rule-based reasoning approach
to automate the process of decision support
and recommending actions faster than a
human being and at any time. Chapter 10,
Healthcare-Cube Integrator for Healthcare
Databases by Trivedi et al. proposes the
Healthcare-cube integrator as a knowledge
base that is storing health records collected
from various healthcare databases. They
also propose a processing tool to extract
data from assorted databases. Chapter 11,
Smart mental healthcare systems, by Dalal
and Jain provides an architecture for a
smart mental healthcare system along with
the challenges and benefits incurred.
Chapter 12, A meaning-aware information
search and retrieval framework for health-
care, by Anoop et al. discusses a frame-
work for building a meaning-aware
information extraction from unstructured
EHRs. The proposed framework uses medi-
cal ontologies, a medical catalog-based ter-
minology extractor and a semantic
reasoner to build the medical knowledge
base that is used for enabling a semantic
information search and retrieval experience
in the healthcare domain. In Chapter 13,
Ontology-based intelligent decision sup-
port systems: a systematic approach, Saha
et al. emphasize several machine learning
algorithms and semantic technologies to
design and implement intelligent decision
support system for effective healthcare
support satisfying quality of service and
quality of experience requirements.
Jacyntho and Morais in Chapter 14,
Ontology-based decision-making, have
described the architecture and strengths of
knowledge-based decision support sys-
tems. They have defined a method for the
creation of ontology-based knowledge
bases and a corresponding fictitious health
care case study but with real-world chal-
lenges. As the data are exploding over the
web, Daoui et al. in Chapter 15, A new
method for profile identification using
ontology-based semantic similarity, aim to
treat and cover a new system in the
domain of tourism in order to offer users
of the system a set of interesting places
and tourist sites according to their prefer-
ences. The authors focus on the design of a
new profile identification method by defin-
ing a semantic correspondence between
xiii
Preface
16.
keywords and theconcepts of an ontology
using an external resource WordNet.
Compared to the objective type assessment,
the descriptive assessment has been found
to be more uniform and at a higher level of
Bloom’s taxonomy. In Chapter 16, Semantic
similarity-based descriptive answer evalua-
tion, Shaukat et al. have put in efforts to
deal with the problem of automated com-
puter assessment in the descriptive exami-
nation. Lastly in this section, Chapter 17,
Classification of genetic mutations using
ontologies from clinical documents and
deep learning, by Bedi et al. have pre-
sented a framework for classifying cancer-
ous genetic mutation reported in EHRs.
They have utilized clinical NLP, Ontologies
and Deep Learning for the same over
Catalog of Somatic Mutations in Cancer
Mutation data and Kaggle’s cancer-
diagnosis dataset.
Security
Though posed as the future of web, is
semantic web secure? In the semantic web set-
ting, traditional security measures are no
more suitable. This section closes the book by
providing Chapter 18, Security issues for the
semantic web, by Pranav et al. providing the
security issues in the semantic web. This chap-
ter also suggested ways of potentially aligning
the protocols so as to make them more robust
to be used for semantic web services.
As the above summary shows, this book
summarizes the trends and current research
advances in web semantics, emphasizing
the existing tools and techniques, methodol-
ogies, and research solutions.
Sarika Jain (India)
Vishal Jain (India)
Valentina Emilia Balas (Romania)
xiv Preface
important ingredient inbuilding artificially intelligent knowledge-based systems as they
aid machines in integrating and processing resources contextually and intelligently.
This book describes the three major compartments of the study of Web Semantics, namely
representation, reasoning, and security. It also covers the issues related to the successful deploy-
ment of semantic web. This chapter addresses the key knowledge and information needs of the
audience of this book. It provides easily comprehensible information on Web Semantics includ-
ing semantics for data and semantics for services. Further, an effort has been made to cover the
innovative application areas semantic web goes hand in hand with a focus on Health Care.
1.2 Semantic Intelligence
Semantic Intelligence refers to filling the semantic gap between the understanding of
humans and machines by making a machine look at everything in terms of object-oriented
concepts as a human look at it. Semantic Intelligence helps us make sense of the most vital
resource, that is, data; by virtue of making it interpretable and meaningful. The focus is on
information as compared to the process. To whatever application, the data will be put to; it is
to be represented in a manner that is machine-understandable and hence human-usable. All
the important relationships (including who, what, when, where, how, and why) in the
required data from any heterogeneous data source are required to be made explicit.
The primary technology standards of the SITs are RDF (Resource Description
Framework) and SPARQL (SPARQL Protocol and RDF Query Language). RDF is the data
model/format/serialization used to store data. SPARQL is the query language designed to
query, retrieve, and process data stored as RDF across various systems and databases.
Both of these technologies are open-ended making them a natural fit for iterative, flexible,
and adaptable software development in a dynamic environment; hence suitable for a myr-
iad of open-ended problems majorly including unstructured information. It is even benefi-
cial to wrap up the existing relational data stores with the SPARQL end points to integrate
them with any intelligent application. This all is possible because semantic web operates
on the principle of Open World Assumption; wherein all the facts are not anticipated in
the beginning; and in the absence of some fact, it cannot be assumed false.
Semantics is no more than discovering “relationships between things.” These relation-
ships when discovered and represented explicitly help manage the data more efficiently
by making sense of it. In addition to storing and retrieving information, semantic intelli-
gence provides a flexible model by acting as an enabler for machines to infer new facts
and derive new information from existing facts and data. In all such systems with a large
amount of unstructured and unpredictable data, SITs prove to be less cost-intensive and
maintainable. By virtue of being able to interpret all the data, machines are able to perform
sophisticated tasks for the mankind. In today’s world SITs are serving a very broad range
of applications, across multiple domains, within enterprises, and on the web. A full-
fledged industry in its own sense has emerged in the last 20 years when these technologies
were merely drafts. In addition to publishing and consuming data on the web, SITs are
being used in enterprises for various purposes.
2 1. Semantic intelligence: An overview
Web Semantics
19.
1.2.1 Publishing andconsuming data on the web
Publishing data on the web involves deciding upon the format and the schema to use.
Best practices exist to publish, disseminate, use, and perform reasoning on high-quality
data over the web. RDF data can be published in different ways including the linked data
(DBPedia), SPARQL endpoint, metadata in HTML (SlideShare, LinkedIn, YouTube,
Facebook), feeds, GRDDL, and more. Semantic interlinked data is being published on the
web in all the domains including e-commerce, social data, and scientific data. People are
consuming this data through search engines and specific applications. Publishing semantic
web data about the web pages, an organization ensures that the search results now also
include related information like reviews, ratings, and pricing for the products. This added
information in search results does not increase ranking of a web page but significantly
increases the number of clicks this web page can get. Here are some popular domains
where data is published and consumed on the semantic web.
• E-commerce: The Schema.org and the GoodRelations vocabulary are global schema for
commerce data on the web. They are industry-neutral, syntax-neutral, and valid across
different stages of value chain.
• Health care and life sciences: HealthCare is a novel application domain of semantic web
that is of prime importance to human civilization as a whole. It has been predicted as
the next big thing in personal health monitoring by the government. Big pharma
companies and various scientific projects have published a significant amount of life
sciences and health care data on the web.
• Media and publishing: The BBC, The FT, SpringerNature, and many other media and
publishing sector companies are benefitting their customers by providing an ecosystem
of connected content to provide more meaningful navigation paths across the web.
• Social data: A social network is a two-way social structure made up of individuals
(persons, products, or anything) and their relationships. The Facebook’s “social graph”
represents connections between people. Social networking data using friend-of-a-friend
as vocabulary make up a significant portion of all data on the web.
• Linked Open Data: A powerful data integration technology is the practical side of
semantic web. DBPedia is a very large-linked dataset making the content of Wikipedia
available to the public as RDF. It incorporates links to various other datasets as
Geonames; thus allowing applications to exploit the extra and more precise knowledge
from other datasets. In this manner, applications can provide a high user experience by
integrating data from multiple linked datasets.
• Government data: For the overall development of the society, the governments around
the world have taken initiatives for publishing nonpersonal data on the web making the
government services transparent to the public.
1.2.2 Semantic Intelligence technologies applied within enterprises
Enterprise information systems comprise complex, distributed, heterogeneous, and
voluminous data sources. Enterprises are leveraging SITs to achieve interoperability and
implement solutions and applications. All documents are required to be semantically
tagged with the associated metadata.
3
1.1 Overview
Web Semantics
20.
• Information classification:The knowledge bases as are used by the giants Facebook,
Google, and Amazon today are said to shape up and classify data and information in
the same manner as the human brain does. Along with data, a knowledge base also
contains expert knowledge in the form of rules transforming this data and information
into knowledge. Various organizations represent their information by combining the
expressivity of ontologies with the inference support.
• Content management and situation awareness: The organizations reuse the available
taxonomic structures to leverage their expressiveness to enable more scalable
approaches to achieve interoperability of content.
• Efficient data integration and knowledge discovery: The data is scaling up in size
giving rise to heterogeneous datasets as data silos. The semantic data integration allows
the data silos to be represented, stored, and accessed using the same data model; hence
all speaking the same universal language, that is, SITs. The value of data explodes
when it is linked with other data providing more flexibility compared to the traditional
data integration approaches.
1.3 About the book
This book contains the latest cutting-edge advances and future directions in the field of
Web Semantics, addressing both original algorithm development and new applications of
semantic web. It presents a comprehensive up-to-date research employing semantic web
and its health care applications, providing a critical analysis of the relative merit, and
potential pitfalls of the technique as well as its future outlook.
This book focuses on a core area of growing interest, which is not specifically or com-
prehensively covered by other books. This book describes the three major compartments
of the study of Web Semantics, namely Representation, Reasoning, and security. It covers
the issues related to the successful deployment of semantic web. Further, an effort has
been made to cover the innovative application areas semantic web goes hand in hand with
focus on HealthCare by providing a separate section in every chapter for the case study of
health care, if not explicitly mentioned. The book will help the instructors and students
taking courses of semantic web getting abreast of cutting edge and future directions of
semantic web, hence providing a synergy between health care processes and semantic
web technologies.
4 1. Semantic intelligence: An overview
Web Semantics
While this istrue for most of the current conversational agents, the one made by
Google seems to be more aware of the possibility of multiturn conversation. In fact, in
some particular situations, it is capable of carry a context between one user question
and the following ones. An example could be asking “Who is the current US president?”
and then “Where he lives?;” in this particular case, the agent resolves the “he” pronoun
carrying the context of the previous step. Anyway this behavior is not general and is
exploited only in some common situations and for a limited amount of steps. An
evidence of this is the limit of the DialogFlow platform (a rapid prototyping platform for
creating conversational agents based on the Google Assistant intelligence) to maintain
context from one step to another (the maximum number of context it can carry is 5).
While this mechanism could appear among sentences belonging to the same conversa-
tion, it is not true among different conversations, what we noticed is that each conversa-
tion is for sure independent from the previous ones. Hence, the agent does not own a
story of the entire dialog. Additionally, the assistant does not seem to be conscious
about the actual status of the conversation; this marks the impossibility for it to be
an effective tool to achieve a complex goal (differently from single interactions like
“turning on the light”).
This situation strongly limits the capability of these systems of being employed into more
complex scenarios where it is necessary to address the following challenges: (1) to manage
long conversations possibly having a high number of interactions, (2) to keep track of users’
status in order to send proper requests or feedback based on the whole context, (3) to exploit
background knowledge in order to have at any time all information about the domain in
which the conversational agent has been deployed, and (4) to plan dialogs able to dynami-
cally evolve based on the information that have been already acquired and on the long-term
goals associated with users. To address these challenges it is necessary to sustain NLU strat-
egies with knowledge-based solutions able to reason over the information provided by users
in order to understand her status at any time and to interact with her properly.
Conversational agents integrating this knowledge-based paradigm go one step beyond
state-of-the-art systems that limit their interactions with users to a single-turn mode.
In this chapter, we present Convology (CONVersational ontOLOGY), a top-level
ontology aiming to model the conversation scenario for supporting the development of
conversational knowledge-based systems. Convology defines concepts enabling the
description of dialog flows, users’ information, dialogs and users events, and the real-time
statuses of both dialogs and users. Hence, systems integrating Convology are able to man-
age multiturn conversations. We present the TBox, and we show how it can be instantiated
into a real-world scenario.
The chapter is structured as follows. In Section 2.2, we discuss the main types of
conversation tools by highlighting how none of them is equipped with facilities for man-
aging multiturn conversations. Then, in Sections 2.3 and 2.4, we present the methodology
used for creating Convology and we explain the meaning of the concepts defined.
Section 2.5 shows how to get and to reuse the ontology, whereas Section 2.6 presents an
application integrating Convology together with examples of future projects that will inte-
grate it. Section 2.7 discusses the sustainability and maintenance aspects, and, finally,
Section 2.8 concludes the chapter.
8 2. Convology: an ontology for conversational agents in digital health
I. Representation
23.
2.2 Background
Conversational agents,in their larger definition, are software agents with which it is
possible to carry a conversation. Researchers discussed largely on structuring the terminol-
ogy around conversational agents. In this chapter, we decide to adhere to Franklin and
Graesser (1997) that segments conversational agents according to both learned and
indexed content and approaches for understanding and establishing a dialog. The evolu-
tion of conversational agents proposed three different software types: generic chit-chat
(i.e., tools for maintaining a general conversation with the user), goal-oriented tools that
usually rely on a large amount of prebuilt answers (i.e., tools that provide language inter-
faces for digging into a specific domain), and the recently investigated knowledge-based
agents that aim to reason over a semantic representation of a dataset to extend the intent
classification capabilities of goal-oriented agents.
The first chit-chat tool, named ELIZA (Weizenbaum, 1966), was built in 1966. It was cre-
ated mainly to demonstrate the superficiality of communications and the illusion to be
understood by a system that is simply applying a set of pattern-matching rules and a substi-
tution methodology. ELIZA simulates a psychotherapist and, thanks to the trick of present-
ing again to the interlocutor some contents that have been previously mentioned, it keeps
the conversation without having an understanding of what really is said. At the time when
ELIZA came out, some people even attributed human-like feelings to the agent. A lot of
other computer programs have been inspired by ELIZA and AIML—markup language for
artificial intelligence—has been created to express the rules that drive the conversation. So
far, this was an attempt to encode knowledge for handling a full conversation in a set of
predefined linguistic rules.
Domain-specific tools were designed to allow an individual to search conversationally
into a restricted domain, for instance simulating the interaction with a customer service of
a given company. A further generalization of this typology was introduced by knowledge-
based tools able to index a generic (wider) knowledge base and provides answers pertain-
ing a given topic. These two are the largest utilized types of conversational agents
(Ramesh et al., 2017). The understanding of the interactions is usually performed using
machine learning, in fact recent approaches have abandoned handcrafted rules utilized in
ELIZA toward an automatic learning from a dialog corpus. In other words, the under-
standing task is related to turning natural language sentences into something that can be
understood by a machine: its output is translated into an intent and a set of entities. The
response generation can be fully governed by handcrafted rules (e.g., if a set of conditions
apply, say that) or decide the template response from a finite set using statistical
approaches [using some distance measures like TF-IDF, Word2Vec, Skip-Thoughts (Kiros
et al., 2015)]. In this chapter, we focus on the understanding part of the conversation.
While machine learning offers statistical support to infer the relationship between sen-
tences and classes, one pillar of these approaches is the knowledge about the classes of
these requests. In fact, popular devices such as Amazon Echo and Google Home require,
whether configured, to list the intents of the discussion. However, those devices hardly
cope with a full dialog, multiturn, as the intents are either considered in isolation or con-
textualized within strict boundaries. Previous research attempts investigated the
I. Representation
9
2.2 Background
24.
multiturn aspect withneural networks (Mensio et al., 2018). The conversation was fully
understood statistically, that is, through statistical inference of intents sequentially, with-
out a proper reasoning about the topics and actors of the conversation. Other research
attempts exploited the concept of ontology for modeling a dialog stating that a semantic
ontology for dialog needs to provide the following: first, a theory of events/situations;
second, a theory of abstract entities, including an explication of what propositions and
questions are; and third, an account of Grounding/Clarification (Ginzburg, 2012). An
ontology is thus utilized to also order questions maximizing coherence (Milward, 2004).
Despite the research findings on this theme and the trajectory that shows a neat interac-
tion between statistical inference approaches and ontologies for modeling the entire dia-
log (Flycht-Eriksson and Jönsson, 2003), there is a lack of a shared ontology. In this
chapter, we aim to fill this gap by presenting Convology.
2.3 The construction of convology
The development of Convology followed the need of providing a metamodel able
not only to provide a representation of the conversational domain but also to support
the development of smart applications enabling the access to knowledge bases
through a conversational paradigm. Such applications aim to reduce users’ effort
in obtaining required information. For this reason, the proposed ontology has
been modeled by taking into account how it can be extended for being integrated into
real-world applications.
The process for building Convology followed the METHONTOLOGY (Fernández-
López et al., 1997) methodology. This approach is composed by seven stages:
Specification, Knowledge Acquisition, Conceptualization, Integration, Implementation,
Evaluation, and Documentation. For brevity, we report only the first five steps since
they are the most relevant ones concerning the design and development of the ontol-
ogy. The overall process involved four knowledge engineers and two domain experts
from the Trentino Healthcare Department. More precisely, three knowledge engineers
and one domain experts participated to the ontology modeling stages (hereafter, the
modeling team). While, the remaining knowledge engineer and domain expert were in
charge of evaluating the ontology (hereafter, the evaluators). The role of the domain
experts was to supervise the psychological perspective of the ontology concerning the
definition of proper concepts and relationships supporting the definition of empathetic
dialogs.
The choice of METHONTOLOGY was driven by the necessity of adopting a life-cycle
split in well-defined steps. The development of Convology requires the involvement of
the experts in situ. Thus the adoption of a methodology having a clear definition of the
tasks to perform was preferred. Other methodologies, like DILIGENT (Pinto et al., 2004)
and NeOn (Suárez-Figueroa, 2012), were considered before starting the construction of
the Convology ontology. However, the characteristics of such methodologies, like the
emphasis on the decentralized engineering, did not fit our scenario well.
10 2. Convology: an ontology for conversational agents in digital health
I. Representation
25.
2.3.1 Specification
The purposeof Convology is twofold. On the one hand, we want to provide a metamo-
del fully describing the conversation domain from the conversational agent perspective.
On the other hand, we want to support the development of smart applications for support-
ing users in accessing content of knowledge bases by means of a conversational paradigm.
As mentioned in Section 2.1, Convology supports the modeling of a full dialog between
users and systems.
From the granularity perspective, Convology is modeled with a low granularity level.
As we discuss in Section 2.4, Convology contains only top-level concepts representing the
main entities involved in describing a conversation and that can be used for storing infor-
mation about user-based events that can be exploited for reasoning purposes. The ratio-
nale behind this choice is to avoid changes in the TBox when Convology is instantiated
into a new domain. Thus, when a new application is developed, the experts in charge of
defining all entities involved in the conversation supported by the application will work
only on the ABox.
2.3.2 Knowledge acquisition
The acquisition of the knowledge necessary for building Convology was split in two
phases: (1) the definition of the TBox and (2) the definition of the ABox. The TBox has
been modeled by the modeling team having also competences in NLU. The modeling
activity started by analyzing the requirements for realizing a classic (i.e., single-turn) con-
versational agents and by defining which kind of information are necessary for supporting
the multiturn paradigm.
At this point, the modeling team defined the set of entities playing an important role
during the reasoning process. In particular, three concepts have been defined: UserEvent,
UserStatus, and DialogStatus. The first one defines events of interest associated with users.
Such events are the basic information used at reasoning time. The second one allows to
model the status of interest in which a User can be and it can be activated at reasoning
time in case a specific set of UserEvent is verified. Finally, the third one represents a snap-
shot of a conversation between a User and a Agent and works as trigger for the system to
perform specific actions. In Section 2.4, we will explain each concept and the interactions
among them in more detail.
Differently, knowledge defined within the ABox is acquired through the collaborative
work with domain experts. Indeed, when Convology is instantiated into a new applica-
tion, it is necessary to define which are the relevant information (i.e., questions, answers,
intents, etc.) used by the conversational agent for managing dialogs. Such information
can be provided only by domain experts. Let us consider the sample scenario we
reported in Section 2.6 about the asthma domain. There, pulmonologists have been
involved for providing all the knowledge necessary for managing a conversation with
users in order to collect information needed for supporting a real-time reasoning of their
healthy status.
11
2.3 The construction of convology
I. Representation
26.
2.3.3 Conceptualization
The conceptualizationof Convology was split into two steps. The first one was covered
by the knowledge acquisition stage, where most of the terminology is collected and
directly modeled into the ontology. While the second step consisted in deciding how to
represent, as classes or as individuals, the information we collected from unstructured
resources. Then, we modeled the properties used for supporting all the requirements.
During this stage, we relied on several ontology design patterns (Hitzler et al., 2016).
However, in some cases, we renamed some properties upon the request of domain
experts. In particular, we exploit the logical patterns Tree and N-Ary Relation, the align-
ment pattern Class Equivalence, and the content patterns Parameter, Time Interval, Action,
and Classification.
2.3.4 Integration
The integration of Convology has two objectives: (1) to align it with a foundational
ontology and (2) to link it with the Linked Open Data (LOD) cloud. The first objective was
satisfied by aligning the main concepts of Convology with ones defined within the
DOLCE (Gangemi et al., 2002) top-level ontology. Concerning the second objective,
although it is not addressed by the TBox of Convology, it can be satisfied when
Convology is integrated into specific application and some of the intents can be aligned
with concepts defined in other ontologies. As example, if Convology is integrated into a
chat-bot supporting people about diet and physical activity, instances of the Intent concept
can be aligned with concepts defined within the AGROVOC1
vocabulary. Similarly, the
integration of Convology, proposed in Section 2.6, into a conversational agent supporting
people affected by asthma opens the possibility of aligning instances of the Intent concept
with concepts defined into an external medical knowledge base like UMLS2
.
This way, individuals defined within the ABox of Convology may work as a bridge
between Convology and the LOD cloud.
2.4 Inside convology
The ontology contains five top-level concepts: Actor, ConversationItem, Dialog, Event, and
Status. Among these, the Dialog concepts does not subsume any other concept. However,
it works as collector of other concepts for representing a whole dialog instance. Fig. 2.1
shows a general overview of the ontology with the hierarchical organization of the
concepts.
Below, by starting from each top-level concept, we detail each branch of Convology by
providing the semantic meaning of the most important entities.
1
http://aims.fao.org/vest-registry/vocabularies/agrovoc.
2
https://www.nlm.nih.gov/research/umls/.
12 2. Convology: an ontology for conversational agents in digital health
I. Representation
27.
2.4.1 Dialog
The Dialogconcept represents a multiturn interaction between a User and one or more
Agent. A new instance of the Dialog concept is created when a user starts a conversation
with one of the agents available within a specific application. The hasId datatype property
associated with the Dialog instance works as tracker for all the interactions made during a
single conversation between a User and the involved Agent. Furthermore, the value of this
property is used at reasoning time for extracting from the knowledge repository only the
data related to a single conversation in order to maintain the efficiency of the reasoner
suitable for a real-time environment.
2.4.2 Actor
The Actor concept defines the different roles that can take part into a conversation.
Within Convology, we foresee two main roles represented by the concepts Agent and User.
Instances of the Agent concept are conversational agents that interact with users. When
Convology is deployed into an application, instances of Agent concept represents the dif-
ferent agents involved into the conversations with the users adopting the application.
Within the same application (e.g., the conversational agent implemented for the asthma
scenario described in Section 2.6), Convology will have a different instance of the Agent
concept for each User even if the application is the same. The rationale behind is that dif-
ferent active conversations may be in different statuses. Hence, for favoring the efficiency
of reasoning activity, different instances are created into the ontology. Finally, different
instances of the Agent concept are associated with different instances of the Dialog concept.
The second concept defined in this branch is User. Instances of the User concept repre-
sents the actual users that are dialoguing with the conversational agent. A new instance of
the User concept is created when a new user starts a conversation within a specific applica-
tion (e.g., a new user installs the application for monitoring her asthma conditions). An
instance of the User concept can be associated with different instances of the Dialog and
FIGURE 2.1 Overview of Convology.
13
2.4 Inside convology
I. Representation
28.
Agent concepts. Thereasons for which this does not happen for the Agent concept (i.e., an
Agent instance can be associated with one and only one instance of User) is because the
focus of Convology is to track and support the conversations from the user perspective.
Thus the ontology maintains a single instance of User for each deployment of Convology
due to the necessity of tracing the whole history of users.
For debug purposes (e.g., to analyze the behavior of the conversational agents for evalu-
ating its effectiveness), it is anyway possible to collect all instances of the Agent concept.
2.4.3 ConversationItem
A ConversationItem is an entity taking part into a conversation and that allows to repre-
sent relevant knowledge for supporting each interaction. Within Convology, we defined
four subclasses of the ConversationItem concept: Question, Intent, Feedback, and DialogAction.
An individual of type Question represents a possible question that an instance of type
Agent can send to a User. Instances of Question are defined by domain experts together
with all the Intent individuals that are associated with each Question through the
hasRelevantIntent object property. A Question can be associated with also a specific
UserEvent through the hasTriggerQuestion object property.
An Intent represents a relevant information, detected within a natural language answer
provided by a User, that the NLU module is able to recognize and that the reasoner is able
to process. Concerning the mention to the NLU module, it is important to clarify that the
detection of an Intent within a user’s answer requires the integration of a NLU module
able to classify the content of users’ answers with respect to each Intent associated with
the Question sent to a User. Hence, one of the prerequisites for deploying Convology into a
real-world system is the availability of a module that maps the content of users’ answers
with the instances of the Intent concept defined into the ontology. The possible strategies
that can be implemented for supporting such a mapping operation are out of scope of this
chapter. An Intent is then associated with a StatusItem through the activated object prop-
erty: once a specific Intent is recognized, a StatusItem instance is created into the knowl-
edge repository for supporting the inference of the user’s status.
Differently from a Question where it is expected that a User performs a new interaction
and a set of relevant Intent are associated with them, a Feedback represents a simple sen-
tence that an Agent can send to users and for which it does not expect any reply. Feedback
are used for closing a conversation as result of the reasoning process or simply for sending
single messages to users without requiring any further interaction.
Instances of the DialogAction concept describes the next action that an Agent individual
has to perform. DialogAction individuals can be defined by domain experts as conse-
quences of the detection of specific intents or can be generated as result of reasoning activ-
ities and associated with a DialogStatus instance. Individuals of type DialogAction are
associated with a Question or a Feedback individual representing the next message sent to a
User. Moreover, a DialogAction might have the datatype property waitTime set, that is, the
amount of seconds that the system must wait before sending the Question or the Feedback
to the User.
14 2. Convology: an ontology for conversational agents in digital health
I. Representation
29.
2.4.4 Event
The Eventconcept describes a single event that can occur during a conversation. Within
Convology, we identified three kinds of events: EventQuestion, EventAnswer, and
UserEvent. Instances of these concepts enable the storage of information within the knowl-
edge repository, trigger the execution of the reasoning process, and allow the retrieval of
information for both analysis and debugging purposes.
An EventQuestion represents the fact that a Question has been submitted to an Actor. Here,
we do not make distinctions between the actors because, from a general perspective, the
model supports scenarios where questions are sent from a User to an Agent. Instances of this
concept are associated with knowledge allowing to identify the timing (hasTimestamp datatype
property), the Actor instance that sent the question (sentQuestion object property), and the
Actor instance that received the question (receivedQuestion object property).
On the contrary, the EventAnswer concept represents an Answer provided by an Actor.
The timing information associated with individuals of this concept is defined through the
hasTimestamp datatype property, whereas the sender and the receiver are defined by the
sentAnswer and receivedAnswer object properties.
The last concept of this branch is the UserEvent one. A UserEvent represents an Event
associated with a specific user. The purpose of having a specific UserEvent concept instead
of inferring UserEvent objects from the EventQuestion and EventAnswer individuals is that a
UserEvent does not refer only to questions and answers but also to other events that can
occur. Examples are the presence of one or more Intent within users’ answer (this kind of
knowledge cannot be associated with EventAnswer individuals because Agent instances do
not provide Intent within an answer) or information about users’ action that are not
directly connected with the conversation (the storage of these information is important in
case of it is of interest to analyze users’ behaviors). The relationship between a UserEvent
and an Intent is instantiated through the hasRecognizedIntent object property. Finally,
instances of UserEvent can trigger the activation of a specific UserStatus (explained below)
as result of the reasoning process. Triggering events are instantiated through the
hasTriggerQuestion and triggers object properties. The former allows to put in relationship a
UserEvent with a Question. The latter associates a UserEvent with a specific UserStatus. Both
relationships are defined as result of the reasoning process.
2.4.5 Status
The last branch of Convology has the Status concept as top-level entity. This branch
contains concepts describing the possible statuses of users, through the UserStatus and
StatusItem concepts, or of dialogs, through the DialogStatus concept.
Instances of the UserStatus concept are defined by the domain experts, and they repre-
sent which are the relevant statuses of a User that the conversational agent should discover
during the execution of a Dialog. Let us consider the asthma scenario described in
Section 2.6, the aim of the conversational agent is to understand which is the health status
of the user. Within this application, the domain experts defined four UserStatus based on
the gravity of the symptoms that are recognized during the conversation. A UserStatus
is associated with a set of UserEvent that, in turn, are associated with Intent individuals.
15
2.4 Inside convology
I. Representation
30.
This path describeswhich is the list of Intent enabling the classification of a User with
respect to a specific UserStatus. This operation is performed by a SPARQL-based reasoner.
A UserStatus individual is associated with a set of StatusItem individuals representing
atomic conditions under which a UserStatus can be activated. Generally, not all StatusItem
has to be activated for inferring, in turn, a UserStatus. Different strategies can be applied at
reasoning time, but they are out of scope of this chapter.
The third subsumed concept is the DialogStatus one. A DialogStatus individual provides
a snapshot of a specific Dialog at a certain time. Entities associated with a DialogStatus indi-
vidual are the Dialog which the status refers to, the identifiers of the User and of the one or
more Agent involved into the conversation, and the DialogAction that has to be performed
as next step. Individuals of type DialogStatus are created at reasoning time after the proces-
sing of the Intent recognized by the system.
2.5 Availability and reusability
Convology is licensed under the Creative Commons Attribution-NonCommercial-
ShareAlike 4.03
, and it can be downloaded from the Convology website4
. The rational
behind the CC BY-NC-SA 4.0 is that the Trentino Healthcare Department, that funds the
project in which Convology has been developed, was not in favor of releasing this
ontology for business purposes. Hence, they force the adoption of this type of license
for releasing the ontology. Convology can be downloaded in two different modalities:
(1) the conceptual model only, where the user can download a light version of the ontol-
ogy that does not contain any individual, or (2) the full package, where the ontology is
populated with all the individuals we have already modeled for the asthma domain.
Convology is constantly updated due to the project activities using the ontology as core
component.
The ontology is available also as web service. Detailed instructions are provided on the
ontology website. Briefly, the service exposes a set of informative methods enabling the
access to a JSON representation of the individuals included into the ontology.
The reusability aspect of Convology can be seen from two main perspectives. First,
Convology describes a metamodel that can be instantiated from conversational agents
into different domains. This opens the possibility of building an ecosystem of knowledge
resources describing conversational interactions within many scenarios. Second,
Convology enables the construction of innovative smart applications combining both
natural language processing and knowledge management capabilities as presented in
Section 2.6. Such applications represent innovative solutions within the conversational
agents field.
3
https://creativecommons.org/licenses/by-nc-sa/4.0/.
4
http://w3id.org/convology.
16 2. Convology: an ontology for conversational agents in digital health
I. Representation
31.
2.6 Convology inaction
As introduced, a real practical scenario based on Convology was the development of
PuffBot, a multiturn goal-oriented conversational agent supporting patients affected by
asthma. The current version of PuffBot supports interactions in Italian, but we are in the pro-
cess of extending it to both English and Chinese languages. In Fig. 2.2, we provide a sample
conversation in Italian between PuffBot and a user. PuffBot is equipped with a NLU module
able to classify intents contained within natural language text provided by users. The cur-
rent list of intents available in PuffBot is relatively short (almost 40) and were defined with
the collaboration of the domain experts of the Trentino Healthcare Department. Within this
list, there are also defined 12 intents referring to the OnBoarding part consisting in a set of
Question submitted for building a preliminary of the user profile (e.g., the name, the city
where she lives, sports practiced, etc.) that is stored into the knowledge repository and used
as contextual information at reasoning time. The main aim of PuffBot is to perform a real-
time inference of UserStatus in order to monitor users’ health conditions and to suggest the
most effective action to take for solving undesired situations.
During the design phase, we decided to create a hierarchy of intents, each single intent
belongs to a set of related intents. For instance, we have defined different types of intents
related to the cough (e.g., cough frequency, last episode) and other intents related to the
recently medical examinations done or breath situation. To handle different steps of
FIGURE 2.2 This figure illustrates an example of an entire conversation with PuffBot. The two screenshots on
left show the OnBoarding phase where we delineate the user profile. The third one instead is the real conversa-
tion scenario where we want to infer the UserStatus through a series of questions. The last message contains the
overall resume with the advice made by the reasoner.
17
2.6 Convology in action
I. Representation
32.
conversations, all togetherwe have exploited the possibility of creating several instances of
Dialog, each one with its own DialogStatus identified by Convology with a unique identifier.
The conversation can be triggered both by the user and the agent. When the agent
receives a trigger from the outside (e.g., a humidity changing in the air was detected), it
can ask specific questions to the user in order to monitor his status. Anyway the user can
start the conversation by saying something and so by triggering an UserEvent that has to
be related to one of the defined intents.
Each time PuffBot recognizes a relevant intent (i.e., an intent modeled within the knowledge
base), and it triggers the reasoner that is in charge of inferring the current user’s status and to
generate the next DialogAction to take. For instance, a possible DialogAction can be a further
question needed for understanding the UserStatus with higher accuracy. Once the application
classifies the UserStatus with a certain accuracy5
, the reasoner triggers the dispatch of an advice
to the user containing a summary of the information that has been acquired and inferred
through the use of Convology. Generally, this advice is an instance of the Feedback concept.
Fig. 2.3 presents an exemplification about how the reasoning process works. On the top-
left part of the picture, we report a piece of the conversation between the user and PuffBot.
Red circles highlight relevant messages provided by users that are transformed into
UserEvent individuals (i.e., the blue blocks in Fig. 2.3). At this point the NLU module is
invoked for analyzing the natural language text provided by the user and it returns the set of
detected Intent. For each Intent, the hasRelevantIntent object property is instantiated (i.e., the
green arrows in Fig. 2.3) in order to associate each UserEvent individual with the related
Intent (i.e., the white block in Fig. 2.3). The right part of Fig. 2.3 shows three instances of the
UserStatus concepts, namely LowRisk, MediumRisk, and HighRisk. These individuals are
defined by domain experts and they represent the risk level of a User of having a strong
asthma event in the short period. Each status is associated with several symptoms that are
instances of the StatusItem concept. Within the knowledge base, the relationships between an
Intent and a StatusItem are defined through the activates object property (i.e., the red arrows).
Hence, the detection of specific Intent triggers the activation of specific StatusItem individuals.
At this point, the SPARQL-based reasoner starts and try to infer which is the most probable
status in which the user is and, in case of an undecided classification, it generated the proper
individuals for triggering the continuation of the conversation (i.e., DialogAction individuals).
2.6.1 Other scenarios
Besides the description of the PuffBot application, Convology is going to be deployed in
more complex scenarios. Below, we mention two of them always related to the healthcare
domain, indeed, as explained in Section 2.7, currently, the sustainability of Convology is
strictly connected with activities jointly done with the Trentino Healthcare Department.
The first one concerns the promotion of adopting healthy lifestyle. Here, a conversational
agent is used for acquiring information about consumed food and performed physical
activities by means of natural language chats with users. With respect to the PuffBot appli-
cation, the number of possible Intent and UserStatus dramatically increases due to the high
number of relevant entity that the system has to recognize (i.e., one Intent for each recipe
5
The strategies implemented for classifying users within different statuses are out of scope of this chapter.
18 2. Convology: an ontology for conversational agents in digital health
I. Representation
33.
and physical activity).The second scenario relates to support users affected by diabetes
concerning its self-management of the disease. One of the most common issue in self-
managing chronic disease is given by psychological barriers avoiding users in performing
self-monitoring actions (e.g., measuring glycemia value). Convology will be deployed into
an application used for knowing which are the barriers affecting each user. With respect
to the first scenario and to the PuffBot application, the main challenge that will be
addressed by the domain experts is the definition of all relevant Intent associated with
each barrier that has to be detected. This modeling task will require a strong interaction
between psychologists and linguistics in order to identify all natural language expressions
that can be linked with each barrier.
2.7 Resource sustainability and maintenance
As mentioned in the previous section, the presented ontology is the result of a collabo-
rative work between several experts. While, on the one hand, this collaboration led to the
FIGURE 2.3 Exemplification of the reasoning process.
19
2.7 Resource sustainability and maintenance
I. Representation
34.
development of aneffective and useful ontology; on the other hand, the sustainability and
the maintenance of the produced artifact represent a criticality.
Concerning the sustainability, this ontology has been developed in the context of the
PuffBot project. The goal of this research project is to provide the first prototype of conversa-
tional agent relying on the use of a knowledge base in order to support a multistep interac-
tion with users. This project, recently started within FBK, is part of the “Trentino Salute 4.0”
framework promoted by the Trentino’s local government with the aim of providing smart
applications (e.g., intelligent chat-bots) to citizens for supporting them under different per-
spectives (e.g., monitoring of chronic diseases, promoting healthy lifestyles, etc.). One of the
goals of this framework is to promote the integration of artificial intelligence solutions into
digital health platforms with the long-term goal of improving the life quality of citizens. The
presented ontology is part of the core technologies used in this framework. The overall sus-
tainability plan for the continuous update and expansion of the Convology ontology is
granted by this framework and by the projects mentioned in Section 2.6.
The maintenance aspect is managed by the infrastructure available within FBK from
both the hardware and software perspectives. In particular, we enable the remote collabo-
ration between experts thanks to the use of the MoKi (Dragoni et al., 2014) tool (details
about the tool are out of the scope of this chapter). Here, it is important only to remark
that this tool implements the support for the collaborative editing of ontologies by provid-
ing different views based on the kind of experts (domain expert, language expert, ontology
engineer, etc.) that has to carry out changes to the ontology.
The canonical citation for Convology is “Dragoni M., Rizzo G., Senese M.A.,
Convology: an Ontology For Conversational Agents (2019). http://w3id.org/convology”.6
2.8 Conclusions and future work
In this chapter, we presented Convology: a top-level ontology for representing conver-
sational scenarios with the aim of supporting the building of conversational agents able to
provide effective interactions with users. The knowledge modeled within Convology
derives from the analysis of knowledge engineers with competences in NLU, and it has
been thought for providing a metamodel able to ease the development of smart applica-
tions. We described the process we followed to build the ontology and which information
we included. Then, we presented how the ontology can be utilized and we introduced the
projects and use cases that currently integrate and use Convology.
Future research activities will focus on the integration of our model within the projects
we mentioned in Section 2.7 with the aim of verifying the correctness and completeness of
Convology and to further improve the model. Furthermore, our intent is to analyze if also
the Convology TBox can be opened to domain experts in order to provide a more flexible
tool for describing specific domains. Finally, we aim to integrate Convology within mind-
fulness applications that, from the conversational perspective, are very complex to manage
and it would be a stressful test-bed for the proposed model.
6
DOI of the ontology file will be provided in case of acceptance in order to include possible refinements
suggested by Reviewers.
20 2. Convology: an ontology for conversational agents in digital health
I. Representation
35.
References
Dragoni, M., Bosca,A., Casu, M., Rexha, A., 2014. Modeling, managing, exposing, and linking ontologies with a
wiki-based tool. In: LREC, pp. 1668 1675.
Fernández-López, M., Gómez-Pórez, A., Juristo, N., 1997. Methontology: from ontological art towards ontological
engineering. In: Proc. Symposium on Ontological Engineering of AAAI.
Flycht-Eriksson, A., Jönsson, A., 2003. Some empirical findings on dialogue management and domain ontolo-
gies in dialogue systems—implications from an evaluation of birdquest. In: Proceedings of the Fourth
SIGdial Workshop on Discourse and Dialogue, 2003, pp. 158 167. , https://www.aclweb.org/anthol-
ogy/W03-2113 . .
Franklin, S., Graesser, A., 1997. Is it an agent, or just a program?: a taxonomy for autonomous agents. In: Müller,
J.P., Wooldridge, M.J., Jennings, N.R. (Eds.), Intelligent Agents III Agent Theories, Architectures, and
Languages. Springer Berlin Heidelberg, Berlin, Heidelberg, pp. 21 35.
Gangemi, A., Guarino, N., Masolo, C., Oltramari, A., Schneider, L., 2002. Sweetening ontologies with dolce. In:
Proceedings of the 13th International Conference on Knowledge Engineering and Knowledge Management.
Ontologies and the Semantic Web, Springer-Verlag, 2002, pp. 166 181. , http://dl.acm.org/citation.cfm?
id5645362.650863 . .
Ginzburg, J., 2012. A semantic ontology for dialogue. The Interactive Stance. Oxford University Press, Oxford.
Hitzler, P., Gangemi, A., Janowicz, K., Krisnadhi, A., Presutti, V. (Eds.), 2016. Ontology engineering with ontology
design patterns—foundations and applications. Studies on the Semantic Web, IOS Press, Vol. 35.
Kiros, R., Zhu, Y., Salakhutdinov, R., Zemel, R.S., Torralba, A., Urtasun, R., et al., 2015. Skip-thought vectors,
CoRR abs/1506.06726. , http://arxiv.org/abs/1506.06726 . . arXiv:1506.06726.
Mensio M., Rizzo, G., Morisio, M., (2018) Multi-turn qa: a rnn contextual approach to intent classification for goal-
oriented systems. In: Companion Proceedings of the The Web Conference 2018, WWW ’18, International
World Wide Web Conferences Steering Committee, Republic and Canton of Geneva, Switzerland,
pp. 1075 1080. Available from: https://doi.org/10.1145/3184558.3191539.
Milward, D., 2004. Ontologies and the structure of dialogue. In: Proceedings of the 8th Workshop on the
Semantics and Pragmatics of Dialogue (Catalog), 2004, 69 77.
Pinto H.S., Staab, S., Tempich, C., 2004. DILIGENT: towards a fine-grained methodology for distributed, loosely-
controlled and evolving engineering of ontologies. In: de Mántaras, R.L., Saitta, L. (Eds.), Proceedings of the
16th Eureopean Conference on Artificial Intelligence, ECAI’2004, including Prestigious Applicants of
Intelligent Systems, PAIS 2004, Valencia, Spain, August 22 27, 2004, IOS Press, pp. 393 397.
Ramesh, K., Ravishankaran, S., Joshi, A., Chandrasekaran, K., 2017. A survey of design techniques for conversa-
tional agents. In: Kaushik, S., Gupta, D., Kharb, L., Chahal, D. (Eds.), Information, Communication and
Computing Technology, Springer Singapore, Singapore, pp. 336 350.
Suárez-Figueroa, M.C., 2012. NeOn Methodology for Building Ontology Networks: Specification, Scheduling and
Reuse (PhD thesis), Technical University of Madrid, 2012. , http://d-nb.info/1029370028 . .
Weizenbaum, J., 1966. Eliza—a computer program for the study of natural language communication between
man and machine. Commun. ACM 9, 36 45. Available from: https://doi.org/10.1145/365153.365168.
21
References
I. Representation
would make theweb machine understandable compared to machine readable. By
describing the metadata more precisely, we can enhance the learning capabilities of
machines, resulting in knowledgeable machines.
Use of XML (extensible mark-up language) is highly popular when it comes to defining
metadata and sharing of web content. However, XML and RDF (Resource Description
Framework) both address the problem of heterogeneity, but XML is primarily a serializa-
tion format compared to RDF that is considered as a data model. XML does not provide a
universally global unique identifier, that is, the identifiers added to an XML document are
unique for that document and not globally. Here comes RDF which uses an ontology as a
schema, and it has a unique Universal Resource Identifier (URI) globally. Also, RDF is
more flexible than XML. This makes the interoperability among ontologies (which are
knowledge representation of concepts within a domain through the relationships between
them) (Patel and Jain, 2020; Lassila), and hence the web much more enhanced. Data in
RDF is structured in the form of triplets as opposed to XML which stores data in a tree for-
mat, thus data organization is also a lot better for data, which is present in an enormous
amount on the web. There are a lot more advantages of using RDF for the modeling of
data and thus conversion of XML data into RDF format is gaining popularity. A number
of approaches have been introduced for transforming the XML data into RDF. This work
shows a study of various approaches presented so far by the learned authors and develo-
pers. Section 3.2 describes the importance of RDF for Linked Data and Semantic
Computing and why is it necessary in the first place. Section 3.3 shows the related work
through a literature review done on the journal articles and approaches of the converter.
Section 3.4 goes on to present the conceptual evaluation of converter. It comprises compar-
ison table of the converter based on the various parameters and general architecture which
is followed in the converter workflow. Section 3.5 discusses the findings deduced from the
rigorous study of these approaches. Certain questions raised while reading this literature
have also been discussed. Finally, Section 3.6 concludes the study.
3.2 Resource Description Framework as a semantic data model
Why use RDF when XML is doing a fine job? To start with, XML is a mark-up language
that defines particular standards for annotating the data which is to be carried and making
it human as well as machine understandable, whereas RDF is a framework which pro-
vides a data model for the data which organizes and annotates the data elements and pro-
vides a standard for their relationship with each other and similar real-world entities. So,
XML is useful when users want to query the document itself, whereas RDF is useful when
data is to be queried while considering its meaning. Hence RDF makes the interpretation
of the data much better, facilitating machine understandability. The fact that RDF species
a global unique identifier for its data elements facilitates interoperability among data pres-
ent in the web worldwide. When using XML as the underlying technology, metadata is
formatted in an XML schema which consists of specific tags to annotate the data along
with plain text which semantically describes the tags in the schema and grammatical
meaning of the document. However, this does not facilitate to make the data understand-
able and interoperability suffers as each XML schema may have different set of rules for
24 3. Conversion between semantic data models: the story so far, and the road ahead
I. Representation
38.
its metadata, eachset of documents may have similar tags with different meanings in their
respective XML schema. When using RDF, an RDF schema such as Ontology Web Language
(OWL) ontology is made for modeling the data which represents not only the data but also
the relationships among those data. As XML is used to format the metadata in most of the
web documents, creation of ontologies has to be done on the basis of present set of rules for
existing metadata. To make ontologies from an XML schema, a key component is that the
data present in XML must have related domain knowledge with it which is what ontologies
work upon to link the World Wide Web. Thus it is recommended to transform XML docu-
ments into RDF instances to establish OWL ontologies from them. In this chapter, various
approaches put forward for this transformation have been discussed.
3.3 Related work
As RDF is in the format of triples, it describes relationships between entities as well as
their meaning in the form of statements consisting of a subject, a predicate, and an object,
that is, resource, a property, and property value (Hardesty, 2016). There have been many
approaches given by learned authors for converting an XML metadata into RDF metadata.
One of the earliest known converters for RDF format in the Semantic Web is Triple
(Manola and Miller, 2004). It was announced in 2007. Among various RDF syntax libraries
is Raptor, a part of the Redland librdf package which was written in C, Triplr is based on
Raptor. Guessing the format of the supplied input data was its key feature at the time it
was designed. This key feature proves very useful as a functionality of online converters.
The Triplr service is based on the REST API and is served as a raw REST service. It does
not, however, take HTML-based input which might help the users while composing REST
URIs. Battle (2006) devised this conversion by making use of OWL ontology. The XML is
first represented in an OWL ontology and the result to be obtained are the RDF instances
of this OWL ontology. Thus they specify a mapper document which is nothing but a map-
ping link between the XML document and the ontology. This linking document is an XML
document. Their approach was exemplified by applying it on DIG35 metadata specification,
which describes metadata about digital images. They state that XML metadata focuses on the
structure of the document rather than its semantics. So, what better tool than a semantic web
technology like an ontology to focus on the semantics. For this, XML has to be converted into
RDF instances.
Hardesty (2016) described that transitioning from XML to RDF is the consideration for
stepping toward linked data and semantic web. As stated in RDF Primer 1.0 “RDF directly
represents only binary relationships” (Stolz et al., 2013). The metadata in XML is described
by encoding values in their respective elements and attributes. On the contrary, RDF forms
statements for a value, which comprises direct references to that value. The references are
to the thing or value that is being described, the reference to the descriptor that describes
it, and a reference to the value at that descriptor’s reference. Bischof et al. (2012) presented
an approach to transform XML to RDF and back again. He called the resultant tool Gloze;
it works under the Jena framework. In the Gloze approach, the modeling of XML content
into RDF is shown by mapping the XML elements and attributes into RDF. This approach
he says is nonlossy, that is, RDF can be mapped back to XML. He called it the Gloze
25
3.3 Related work
I. Representation
39.
approach which mapsXML into RDF by showing that XML can be modeled into RDF. It
maps XML into RDF in such a way that RDF can be again mapped backed to XML which
makes it a nonlossy approach. However, in this process, the sequencing given implicitly in
the tree structure of XML might be lost. To describe the manner in which XML is mapped
into RDF and back into XML, the Gloze approach makes XML schema the basis. Unlike
other procedural approaches like XSLT, Gloze approach gives the benefit that the XML
schema which is used as basis is neutral when it comes to the direction in which mapping
has to be done. Beckett and Broekstra, 2013 presented RDF translator which makes the
conversion between multiple data formats possible like RDF/XML, RDFa, Microdata,
N-Triples, RDF/JSON, etc. In their proposal, the focus is on the technical facet of assisting
the burgeoning of Semantic Web applications with the capability of syntax transformation,
as well as collaborative aspects of the process of development. The days when Semantic
Web had only started blossoming, the prime language for the RDF structure of standard
serialization was XML, (as picturized in the Semantic Web stack1
), the eminence which
RDF syntaxes used to have has now changed and they are being replaces by syntaxes like
RDF/XML, N-Triples, Notation 3 (N3) that embraces Turtle and N-Triples, RDF in attri-
butes (RDFa), and JSON.
RDFa has come out to be most popular when some semantic content has to be pub-
lished on a web page (Stolz et al., 2013). The fact that there are a lot of options of these
syntaxes makes it burdensome for the developers of Semantic Web as they now have to
pay attention on various variants of these different syntaxes. It also makes the interopera-
bility of the semantic web tools vulnerable and limited. If a Semantic Web developer, say,
is not well acknowledged with RDFa, then they would not want to spend their time and
resources on getting familiarized with RDF embedded in HTML using RDFa, rather they
would prefer to use the syntax they are well aquatinted with. For example, it is not easy to
support parsing of RDFa belonging to the other pages if web pages of a web site reply on
the library of JavaScript. The need of a comprehensive online converter thus arises. What
makes the solution effective and multipurpose is an amalgamation of features which work
together to provide the bidirectional conversion of various RDF data formats, to have
made possible that syntax can be highlighted for corresponding supported serialization
formats, the fact that in order to make the collaboration better, sharing functionality can be
linked, a Web Interface which provides user with clean and straightforward design to
operate with and be acquainted and complied with latest Web technologies. Stefan Bischof
et al. (Bischof, 2007) presented a new language called XSPARQL which is a combination of
XQuery and SPARQL. Although XQuery and SPARQL languages were designed for two
different data models (Van Deursen et al., 2008), the authors show that by merging
XQuery and SPARQL together such as in XSPARQL the purpose of bringing XML and
RDF closer can be accomplished. Mapping in either direction (i.e., XML to RDF and vice
versa) can be helped by the precise and concise intuitive solutions provided by XSPARQL.
The fact that SPARQL does not handle XML data says that transformations of such kinds
cannot be accomplished by SPARQL alone. Serializing RDF graphs using RDF/XML
seems the only way by which RDF data can be queried using XQuery.
1
http://www.w3.org/2000/Talks/1206-xml2k-tbl/slide10-0.html
26 3. Conversion between semantic data models: the story so far, and the road ahead
I. Representation
40.
3.4 Conceptual evaluation
Thissection shows the comparative analysis between different converters based on
different parameters like input/output format, programming language, last released date,
and so on. Here we also draw a generalized architecture of the converter.
3.4.1 Comparison study
Table 3.1 shows a comparison study of various converter tools presented so far, whether
available online or not. The year shows in which they were proposed, whether through an
article, journal, or final programmatical product made online. It is to be noted that as the years
progressed, the functionality of conversion between multiformat input/output has been
added into a converter making it a more effective tool for semantic web. Thus after a year or
two, the converter tool kept making progress, as far as data format was concerned.
3.4.2 Generalized architecture
The diagram shown in Fig. 3.1 represents the generalized architectural flow of a con-
verter. The converter tool takes as input, the XML document, the mapping document,
and OWL ontology (acting as vocabulary for making the ontology corresponding to this
XML). It is shown that the data is extracted from this XML schema in form of instances.
TABLE 3.1 Comparison between converters and their significant publishing year.
Available
converter Input format Output format Year
Programming
language
Last
release
date
Online
availability
Battle (2006) XML/RDF RDF/XML 2014 None No
Stolz et al. (2013) XML/RDF-JSON/N-
Triples/Microdata
XML/RDF-JSON/
N-Triples/
Microdata
2013 Python 2013 Yes
Bischof et al.
(2012)
XML RDF 2012 XSPARQL 2012 Yes
Van Deursen et
al. (2008)
XML schema RDF instances 2008 None 2008 No
Catasta et al.
(2019)
RDF/XML, Turtle,
Notation3, RDFa,
Microformats, HTML5,
JSON-LD, CSV
RDF Java 2019 Yes
Kellogg (2011) RDFa, JSONLD,
RDFXML, n3, microdata,
tabular, trix, turtle,
normalise, rj, trig,
normalise, nquads
RDFa, JSONLD, n3,
tabular, trix, turtle,
RDFXML,
normalise, rj, trig,
normalise, nquads,
ntriples, vocabulary
Ruby Yes
Garcı́a et al. RDF/XML, Turtle/N3 RDFa Not given Yes
27
3.4 Conceptual evaluation
I. Representation
41.
The metadata extractedfrom XML schema is used to make its ontology, that is, an ontol-
ogy is developed according to the given XML schema and data inside it. To make this
ontology, a mapping document is used as input. A mapping document is in the XML for-
mat and it provides a link between the XML and OWL ontology, thus the entities in the XML
can be mapped in the OWL ontology, by figuring out which category does it fall in. The XML
schema can map to more than one ontology to figure out the entities and their categories. To
do this, a set of rules has to be followed which is provided in the mapping document. A map-
ping document is in the XML format and it consists of elements such as import statements,
vocabularies, and identifiers. This document says all the rules of mapping between the XML
and the ontology. The OWL ontology which is to be imported in the resulting RDF instances
is specified by import element, by constructs such as, owl: import. The RDF instances are then
extracted from the ontology thus formed, from the imported OWL ontology and XML
schema, and hence a corresponding RDF file is made. The process of translating XML to RDF
is also called lifting, the reason being, the data in RDF is abstracted on a higher level than
in XML where data is semi-structured, thus the opposite conversion is called lowering
(Bischof, 2007).
3.5 Findings
Various approaches have been put forward by learned authors. Some of them are
discussed in Section 3.2. Various intriguing questions are raised from the literature studies
Mapping OWL
ontology to
XML data
Mapping
document
OWL ontology(s)
which work as
vocabularies for
forming the ontology
corresponding to the
current XML data
Ontology
corresponding
to the input
XML
RDF file
Extract RDF
instances
from
ontology
Output RDF
document
Refer to rules and principles in the mapping
document for mapping XML to ontology
XML data
(instances
from the
metadata)
Input
document
Extract metadata
(XML schema) of
the input
document
Input vocabulary
FIGURE 3.1 Generalized architectural flow of the converter. RDF, Resource Description Framework; OWL,
Ontology Web Language.
28 3. Conversion between semantic data models: the story so far, and the road ahead
I. Representation
42.
of converter. Suchas what led to such amount of different approaches on converting the
data formats. This chapter discusses the following questions which could be thought about
while trying to understand converters:
Why available converters are not suitable and why there has been a rise in the need of new
converters? It can be observed that as the number of users of internet rise, the variety of
users also rises, and thus there is a variety in the problems and use cases of internet users.
Different types of users from a software employee, a schoolteacher to a defense personnel
use the internet for their own use. Thus as the variety of users increases, it becomes neces-
sary to change the features of a converter. Such as RDF Translator described in (Beckett
and Broekstra, 2013), bidirectional conversion between data formats, syntax highlighting,
link sharing, interactive web user interface, and compliance with latest web technologies
are some of the features which they have described in their paper, which makes their
product stand out.
What all functionalities must/could be supported by a converter tool? It is the basic functionality
of a converter to transform data format into the one which is more machine understandable.
After going through and studying various approaches, it has been contemplated that a con-
verter can perform much more than this basic function. It can provide as a functionality, the
testing and checking of the annotations which may be encoded in lesser convenient or hard
to parse formats such as RDFa in HTML translated to N3. The developers may provide a
human friendlier format at first, after it has been modeled it can be converted into the target
format, for example, taking N3 as the modeling structure and then publishing in RDF/XML
so that it is easier for the applications to interoperate with each other. There are few popular
data formats (structured), hence the converter can be comprised conversions among these
structured data formats including Microdata. Microdata is most popular these days and is
being used by search engines such as Google, Microsoft, Yandex, and Yahoo!, as it consists
of a syntax which is alternative for embedding structured data in HTML. A converter com-
prising these formats should be able to meet with most of the needs of the developer. The
service should be user-friendly by being available online for free, this provides more accessi-
bility to the user. The user interface service can also include the functionality of keyboard
shortcuts, copying and pasting hassle-free, etc. Applying REST API to the web service makes
it easier for different data formats from heterogeneous sources to be integrated effortlessly.
3.6 Concluding remarks
The structural logic for structured data is provided by XML in its hierarchical definition
of data comprised by elements and attributes. On the other hand, RDF’s main focus is to
derive data logic which aims to declare data resources, these resources are related to each
other using properties. All of these properties are given a unique key, that is, Uniform
Resource identifier, meaning as clear by the term, they are uniquely identified by single
reference points, unlike in the case of XML where each property is provided with its
description encased and encoded. The fact that RDF has an XML language has given birth
to an honest confusion that RDF itself is XML or can be expressed as XML. As clearly read
in Lassila’s work (Patel et al., 2018), regarding the specification of RDF from the World
Wide Web Consortium (W3C), “RDF encourages the view of ‘metadata being data’ by
29
3.6 Concluding remarks
I. Representation
43.
using XML (eXtensibleMarkup Language) as its encoding syntax.” Hence, it is clear that
even though RDF has a way of expressing its resources, which are related to each other by
properties, using XML, RDF cannot be called as an XML schema itself. RDF uses an XML
language, which also sometimes, confusingly called RDF, and thus RDF/XML. The litera-
ture has provided approaches and tools for the conversion of heterogeneous data formats
into RDF, which helps move semantic web in the direction of being interoperable and
being able to not just read but also understand the data. Since many techniques and
approaches have been proposed, a converter must do more than the basic functionality of
converting into RDF. By providing a mixture of features like bidirectional conversions, a
converter can be made to really appeal to the user. As such tools are provided online, the
libraries which they are dependent upon must be updated regularly to keep matching
with the current updated standards. Providing error feedbacks and status information
may prove to be a helpful feature and the upcoming approaches could try to inculcate it.
References
Battle, S., 2006. Gloze: XML to RDF and back again. In: Jena User Conference. , http://jena.hpl.hp.com/juc2006/
proceedings.html. (Cit. on p.) . .
Beckett, D., Broekstra, J., 2013. , https://www.w3.org/TR/rdf-sparql-XMLres/ . .
Bischof, S., et al., 2007. Triplr. , http://triplr.org/ . .
Bischof, S., Decker, S., Krennwallner, T., Lopes, N., Polleres, A., 2012. Mapping between RDF and XML with
XSPARQL. J. Data Semant. 1 (3), 147 185.
Catasta, M., et al., 2019. Introduction to Apache Any23. , http://any23.apache.org/ . .
Garcı́a, R., Hepp, M., Radinger, A. RDF2RDFa converter. , http://www.ebusiness-unibw.org/tools/rdf2rdfa/ . .
Hardesty, J.L., 2016. Transitioning from XML to RDF: considerations for an effective move towards Linked Data
and the Semantic Web. Inf. Technol. Librar. 35 (1), 51 64.
Jain, S., Patel, A., 2020. Situation-aware decision-support during man-made emergencies. In: Proc. of ICETIT 2019.
Springer, Cham, pp. 532 542.
Kellogg, G., 2011. RDF.rb. , http://rdf.greggkellogg.net/distiller?command 5 serialize . .
Lassila, O. Introduction to RDF Metadata. , https://www.w3.org/TR/NOTE-rdf-simple-intro-971113.html . .
Manola, F., Miller, E., 2004. RDF Primer. , https://www.w3.org/TR/rdf-primer/#structuredproperties . .
Patel, A., Jain, S., 2020. A novel approach to discover ontology alignment. Recent Adv. Comput. Sci. Commun. 13 (1).
Patel, A., Jain, S., Shandilya, S.K., 2018. Data of SemanticWeb as unit of knowledge. J. Web Eng. 17 (8), 647 674.
Stolz, A., Rodriguez-Castro, B., Hepp, M., 2013. RDF translator: a restful multi-format data converter for the
semantic web. arXiv preprint arXiv:1312.4704.
Van Deursen, D., Poppe, C., Martens, G., Mannens, E., Van de Walle, R., 2008. XML to RDF conversion: a generic
approach. In: Proc. 2008 International conference on automated solutions for cross media content and multi-
channel distribution, pp. 138 144. IEEE.
30 3. Conversion between semantic data models: the story so far, and the road ahead
I. Representation
systems and clinicalterminology systems. Section 4.4 also discusses several clinical terminol-
ogy systems available in the market and introduces Systematized NOmenclature of
MEDicine-Clinical Terms (SNOMED-CT), the world’s most comprehensive clinical terminol-
ogy system. The section also explains the features of semantic web technology that can be lev-
eraged to improve semantic interoperability. Section 4.5 reviews the literature to gage the
current contribution of semantic web technologies in the improvement of healthcare interoper-
ability at both syntactic and semantic levels. Based on this analysis and review, Section 4.6
describes some innovative future directions to enhance healthcare interoperability using
semantic web technologies and finally, Section 4.7 concludes the chapter.
4.1.1 Healthcare interoperability: a brief overview
Healthcare interoperability is the capability of health information systems to expose,
make accessible, and seamlessly communicate information locked in heterogeneous sys-
tems. Better interoperability between systems can facilitate well-informed decisions and
improve the delivery of healthcare services (HIMSS, 2019). Interoperability is complex
and, to ensure effective communication, it needs to be maintained at several levels:
• Physical interoperability: deals with the physical connections required for transmission of
data from one point (source of information) to another (receiver of information). Since
the advent of the Internet and effortless connection of hundreds of computer systems,
the challenge of physical interoperability is considerably reduced. Therefore this
chapter focuses on the interoperability problem at syntactic and semantic levels.
• Syntactic interoperability: deals with the structure, syntax, and packaging of healthcare data.
Various healthcare standards have emerged in the past few decades that define fixed
message structures, data types, and formats to ensure uniformity in storage and retrieval of
healthcare data. Health level 7 (HL7) is a leading not-for-profit organization involved in the
development of the most widely used healthcare standards to facilitate smooth exchange of
electronic healthcare information between heterogeneous and distributed systems.
Section 4.3 of this chapter discusses syntactic interoperability, various HL7 standards, and
the advantages of applying semantic web technology in this area.
• Semantic interoperability: deals with the semantics, that is, meaning of clinical terms used
by healthcare professionals. After the aforementioned levels have accomplished the
transfer of data from point A (sender) to point B (receiver), semantic interoperability
ensures that the receiver correctly interprets and understands what the sender wants to
convey. This is achieved by adopting various clinical terminology systems that provide
standard codes to replace heterogeneous synonymous clinical terms for symptoms,
diagnoses, and procedures. Section 4.4 discusses the challenges to providing robust
semantic interoperability and the contribution of semantic web technology in this area.
4.2 Semantic web technologies
This section gives an introduction to semantic web technologies including SPARQL,
RDF, RDF graphs, and vocabularies like OWL and RDFS. The section also reviews a wide
range of domains that have leveraged semantic web technologies.
32 4. Semantic interoperability: the future of healthcare
I. Representation
46.
4.2.1 Resource dataframework
The original web of documents was extended to build the semantic web. The primary
goal of this augmentation was to link web content in a machine comprehensible format.
The elementary unit of the semantic web is RDF (RDF, 2014). RDF is a data model, which
was developed as an alternative to the relational model to store and retrieve dynamic web
resources effectively (Ducharme, 2013). While the basic unit of a relational database man-
agement system (RDBMS) model is a tuple, the basic unit of RDF data model is a triple.
A subject, an object, and a predicate together constitute a triple. A record identifier in an
RDBMS model transforms into a subject in RDF, a column in RDBMS converts to a predi-
cate in RDF, and the value in an RDBMS cell transforms to an object in RDF. A universal
resource identifier (URI) is used to locate web resources and RDF links such web resources
to each other using triples. The value of a subject and predicate of an RDF triple must be a
web resource represented using a URI, whereas an object can be a web resource repre-
sented using a literal or a URI. Fig. 4.1 illustrates the conversion of a column (attribute) of
an RDBMS tuple to an RDF triple.
A major advantage of RDF over the traditional RDBMS data model is that it facilitates
exposure, integration, merging, and sharing of structured or semistructured data across
multiple applications even if the underlying schemas differ (RDF, 2014). For example,
while it is a tedious task to merge information stored in tables with different schemas of
different sizes say (m 3 n) and (p 3 q), when these tables are converted into sets of triples,
the complexity of merging this information is reduced as the structure of the storage build-
ing blocks (the triples—subject, object, and predicate) is independent of the amount of
information stored, thus making the data merging process smooth and efficient.
4.2.2 RDF graphs
RDF graphs are formed when information represented by multiple triples is grouped
together. Fig. 4.2 illustrates an elementary example of an RDF graph built by grouping
and linking data from other triples to the triple illustrated in Fig. 4.1. Blank nodes are
used in RDF graphs to improve the organization of data. A blank node does not have any
identity on its own and its only purpose is to group meaningful data together. For exam-
ple, Jack’s address information like street, postal code, and city could have been scattered
among his other details like name, contact information, and profession, but a better way to
FIGURE 4.1 Conversion of an attribute from RDBMS tuple to RDF triple format. RDBMS, Relational database
management system; RDF, resource description framework.
33
4.2 Semantic web technologies
I. Representation
47.
represent this informationwould be to group the nodes as they collectively represent his
complete address. This organization is achieved by introducing a blank node.
4.2.3 Vocabularies, RDFS and OWL
RDF represents relationships among resources in the form of triples. However, linking
resources using the triple format does not add semantics to the data. In order for a
machine to correctly interpret any information, semantics have to be added to this raw
RDF triple data. Semantics are added by representing subjects, objects, and predicates as
instances of well-defined structures, called classes, and guidelines on how these classes
can be linked with each other. For example, consider the triple from Fig. 4.1 where Alex is
diagnosed with otitis media. In order for a machine to interpret the meaning of this triple,
classes Patient, Disorder, and Diagnosis have to be defined. Using these semantics the
machine can then interpret that “Alex” is a patient (an instance of the class patient) and
“otitis media” is a disorder (an instance of the class disorder) and Diagnosis represents the
fact that the patient has a particular disorder. Vocabularies are created to add semantics to
the otherwise raw data represented by RDF. The addition of semantics with the help of
vocabularies is what makes the web meaningful. Vocabularies define classes on the basis
of common properties and provide rules to relate these classes to each other. The RDFS
supplies a set of standard vocabularies that can be reused. Additionally, RDFS allows the
creation of new customized vocabularies that can be integrated with the existing standard
vocabularies to better represent the semantics of individual data. Some standard vocabu-
laries that specialize in particular areas are listed below:
FIGURE 4.2 An example of RDF graph. RDF, resource description framework.
34 4. Semantic interoperability: the future of healthcare
I. Representation
48.
• Friend ofa friend (FOAF) (FOAF, 2014) specializes in representing personal
relationships. It is useful in social network and social media analysis;
• Dublin Core (DCMI, 2019) is a bibliographic vocabulary that represents relationships
like author/creator or title of a book;
• Geonames (GeoNames, 2006) specializes in adding semantics to geospatial data;
• The data cube vocabulary (W3C, 2009) provides a way to meaningfully link statistical,
multidimensional data.
• Simple Knowledge Organization System (W3C, 2009) represents concept hierarchies
and mappings.
• RDFS (W3C, 2009) supports the creation of classes for the RDF resources and
relationships among these classes.
Among the above-mentioned examples, RDFS is the most popular vocabulary. The fol-
lowing paragraphs discuss RDFS in further detail. In particular, RDFS (W3C, 2009) sup-
ports the creation of classes for the RDF resources and relationships among these classes.
For example, you can define a class “Person” by using rdfs:Class and then define a class
of “Patient” by using rdfs:subClassOf, which introduces an inheritance (parent child)
property among the classes, and the machine can then infer that all patients are persons.
Relationships among the classes are defined using properties in RDFS. To define an rdf:
property, two important elements have to be specified, its range (rdfs:range) and domain
(rdfs:domain), which are nothing but constraints to validate the values of its object and
subject, respectively. For example, an rdf:property “Diagnose” should have an rdfs:domain
of class “Doctor” and rdfs:range of class “Disorder,” by which a machine understands that
an instance of class “Doctor” can “Diagnose” an instance of class “Disorder.” Defining
such classes and relationships provides meaning to the data.
However, the expressive power of RDFS is limited. So, OWL (W3C, 2009) was created
to define more complex structures. RDFS is often used in conjunction with ontologies like
OWL that build on top of it to define more complex structures that cannot be expressed
using RDFS alone. Using OWL you can infer additional information and deduce relation-
ships that are not explicitly defined. For example, if there is a relationship that states:
1. John is Maria’s spouse, using owl:SymmetricProperty on the property “spouse,” you
can automatically infer that Maria is John’s spouse too, even if that relationship is not
explicitly defined.
2. Alex is Jack’s patient, using owl:inverseOf on the properties “patient” and “doctor,”
you can deduce that Jack is Alex’s doctor, even when the relationship is not explicitly
defined.
Apart from this, OWL also allows you to describe data in terms of set operations on
already existing classes. Consider the following examples:
1. The class “Father” can be deduced from owl:unionOf classes “Parent” and “Male.”
2. “Patients with diabetes and blood pressure” can be defined as an intersection of classes
“patients with diabetes” and “patients with blood pressure.”
The ability of OWL to describe complex classes and intelligently infer relationships can
be used in a variety of fields where complex interrelated data need to be analyzed.
35
4.2 Semantic web technologies
I. Representation
49.
4.2.4 SPARQL
The SPARQLProtocol and RDF Query Language (pronounced as sparkle) (W3C, 2009)
is world wide web consortium’s (W3C) standard query language to construct, modify, and
retrieve data stored in RDF format, that is, RDF triples or RDF graphs. SPARQL is mostly
used to query data stored in RDF format and the “Protocol” part in SPARQL is only
employed when writing queries that need to be passed back and forth between different
machines. SPARQL queries work by mining the RDF triples for properties mentioned in
the query. Fig. 4.3 presents a basic SPARQL query to find all patients diagnosed with
“otitis media” and its corresponding structured query language (SQL) query. SQL (pro-
nounced as sequel) is a query language used to manage data stored in a relational data-
base system.
SPARQL allows the usage of prefixes to make the queries more readable. Prefix vcard is
used to replace the URI “,http://www.w3.org/2006/vcard/ns#..” Both SQL and SPARQL
queries perform functions like retrieving, modifying, ordering, aggregating, grouping, and
joining data. In spite of these commonalities, a major difference is that SPARQL queries are
executed on RDF triples while SQL queries operate on data stored in tables.
4.2.5 Applications of semantic web technology
The underlying principle of semantic web technology to consolidate data from heteroge-
neous sources and meaningfully link it together can be generalized and applied in a variety of
fields. For example, Dadkhah et al. (2020) explored the potential of semantic web technology
in software testing. Lampropoulos et al. (2020) proposed a method to improve augmented
reality by leveraging knowledge graphs and semantic web technology. Viktorović et al. (2019)
proposed a method to improve automated vehicular navigation with the assistance of seman-
tic web technology. Louge et al. (2019) discussed the applications and suitability of semantic
web technology in the domain of astrophysics. Moussallem et al. (2018) explained the poten-
tial of semantic web technology to overcome the obstacle of syntactic and lexical ambiguity in
machine translation. Drury et al. (2019) examined the potential of semantic web technology to
make unstructured agricultural data more meaningful and motivate further research in this
domain. The W3C has published a list of 13 semantic web use cases that also includes 35 case
studies (Case Studies, 2005).
While this section has presented several domains that find semantic web technologies
advantageous, the chapter mainly examines applications of semantic web technology in
the health informatics domain. The next section assesses the contribution of semantic web
FIGURE 4.3 An example of
SPARQL query and its corresponding
SQL query. SPARQL, Protocol and RDF
query language.
36 4. Semantic interoperability: the future of healthcare
I. Representation
The consequence ofher success will be the re-establishment of
commerce upon its ancient, free and general footing; all nations are
interested in this success, but none so much as the Dutch. From
them, therefore, America in a most special manner looks for support.
Resentment of an ancient injury, the policy of their ancestors, their
present interest, unite in calling upon them for a spirited avowal and
support of the independence of America. They will not forget the
blood, that was spilt in endeavoring to vindicate their right when it
was first invaded. They will not forget the insolence and injustice
with which Great Britain harassed their trade during the late war, by
means of that very naval strength which she derived from her
usurped monopoly. They cannot but feel at this moment the insult
and indignity from the British Court, in presuming to forbid them
that free participation of commerce which America offers.
The extraordinary remittances, which the people of America have
made to the merchants of Great Britain, since the commencement of
this dispute, is a proof of their honor and good faith; so much more
safe and advantageous is it to trust money with a young,
industrious, thriving people, than with an old nation overwhelmed
with debt, abandoned to extravagance and immersed in luxury. By
maintaining the independence of America, a new avenue will be
opened for the employment of money where landed property, as yet
untouched by mortgage or other incumbrances, will answer for the
principal, and the industry of a young and uninvolved people would
insure the regular payment of interest. The money holder would in
that case be relieved from the continual fears and apprehensions,
which every agitation of the English stocks perpetually excites. He
might count his profits without anxiety, and plan his monied
transactions with certainty.
These are the substantial objects of advantage, which America
holds up to the people of Holland; and this the moment of
embracing them.
TO COUNT DE VERGENNES.
52.
Chaillot, April 24th,1778.
Sir,
Since I had the honor of seeing your Excellency, I have learnt
that Mr Hartley in conversing with French people, whose opinions he
thinks may have weight, insinuates to them, that engaging in a war
in our favor is very impolitic, since you can expect nothing from us
but ingratitude and ill faith, with which we have repaid Great Britain.
To us he says, the French have done nothing for you, they can never
be trusted, no cordial connexion can be formed with them, therefore
you had better return back to your former connexions, which may be
upon your own terms if you will renounce France. This gentleman
and the wise men who sent him, have so high an opinion of our
understandings, that they flatter themselves these insinuations will
succeed.
I have also been informed, that besides their commissioners, the
ministry have despatched two persons to America to work privately
as Mr Hartley is doing. One of them is an American. I know them,
and both the size of their understandings and the degree of their
influence. There is nothing to apprehend from either. These are the
little projects of little spirits, and will be attended with proportional
success. They show the imbecility and distress of our enemies, and
will only change the detestation of America into utter contempt.
I have the honor to be, &c.
ARTHUR LEE.
COUNT DE VERGENNES TO ARTHUR LEE.
Translation.
Versailles, April 24th, 1778.
Sir,
I am obliged to you for your attention in communicating Mr
Hartley’s insinuations, as well to yourself as to such other persons as
53.
he may supposehe can influence in this country. I doubt that he
finds easier access to you, than he will surely find with us; and I can
assure you, that he will not find us accessible to the prejudices he
may wish to inspire us with.
I conclude, being obliged to attend the Council, requesting you to
accept of the assurances of the perfect respect, with which I have
the honor, &c.
DE VERGENNES.
TO THE COMMITTEE OF FOREIGN AFFAIRS.
Paris, May 9th, 1778.
Gentlemen,
No declaration of war in Germany or England. All things are
preparing for it. Count d’Estaing had not passed Gibraltar the 27th of
last month, contrary winds having prevented his passing the Straits.
About thirty sail of the line are assembled at Spithead, under Admiral
Keppel, but are not yet in a state for action. They are arraying their
militia, and the chief object of their attention now seems to be their
own defence. As far as I can judge, the King and his Ministers are
not now sincere in their propositions, even such as they are, of
peace and accommodation.
I have not yet obtained any light on Folger’s affairs. The enclosed
copy of a letter from Count de Vergennes will show you the train in
which I have put the inquiry. But I have reason to apprehend, that
persons are concerned, who will have address enough to frustrate it.
The blank paper substituted for the letters taken should be
preserved, and compared with the paper of all the letters received
by the same vessel. Some discovery may be pointed out by that. Mr
Deane and Mr Carmichael should be examined, and their accounts
transmitted here to be compared with those of others.
Spain and the German powers are yet undecided with regard to
us. I do not think our enemies will succeed with Holland. We shall
54.
endeavor to establisha fund for the purposes you desire.
I have the honor to be, &c.
ARTHUR LEE.
P. S. By the banker’s accounts it appears, that
the following sums were paid from December,
1776, to March, 1778, to the private disposition of
the Commissioners.
Livres.
To Dr Franklin, 65,956 3 13
To Silas Deane, 113,004 12 13
To Arthur Lee, 68,846 2 16
In my sum is included the additional expense of
my journies to Spain and Germany.
COMMITTEE OF FOREIGN AFFAIRS TO ARTHUR LEE.
York, May 14th, 1778.
Sir,
Your several favors of October 6th, November 27th, and
December 8th, were delivered to us on the 2d instant, the
despatches by Mr Deane and those by Captain Young arriving on the
same day. We had before received your short letter of the 1st of
June, but are yet without that of the 29th of July, in which you had
informed us “at large of your proceedings in Prussia.” Its contents
would have proved highly agreeable to us in these months, when we
were quite uninformed of the proceedings and prospects of your
colleagues at Paris. Impressed with the sense of the value of the
King of Prussia’s “warmest wishes for our success,” we give
assurances of equal wishes in Congress for that monarch’s
prosperity. We have little doubt of open testimonies of his Majesty’s
friendship in consequence of the late decision of the king of France.
55.
Your information inregard to our connexion with the fictitious
house of Roderique Hortalez & Co. is more explicit, than any we had
before received, but we further expect that all mystery should be
removed. Surely there cannot now be occasion for any, if there ever
was for half of the past. Our commercial transactions will very
speedily be put under the direction of a Board consisting of persons
not members of Congress, it being impracticable for the same men
to conduct the deliberative and executive business of the Continent
now in its great increase. It has been next to impossible to make
remittances for many months from the staple Colonies, their coasts
having been constantly infested by numerous and strong cruisers of
the enemy. We hope the alliance of maritime powers with us will
remove our embarrassments, and give us opportunity to carry into
effect our hearty wishes to maintain the fairest commercial
reputation.
There will be great impropriety in our making a different
settlement for the supplies received from Spain, from that which we
make in regard to those received from France. We are greatly
obliged to the friends, who have exerted themselves for our relief,
and we wish you to signify our gratitude upon every proper
opportunity. But having promised to make remittances to the house
of Hortalez & Co. for the prime cost, charges, interest and usual
mercantile commission upon whatever is justly due to that house,
we must keep the same line with Messrs Gardoqui. On the one
hand, we would not willingly give disgust by slighting princely
generosity, nor on the other submit to unnecessary obligations.
The unanimity with which Congress has ratified the treaties with
France, and the general glad acceptance of the alliance by the
people of these States, must shock Great Britain, who seems to have
thought no cruelty from her would destroy our former great partiality
in her favor. What plan she will adopt in consequence of her
disappointment, time only can discover. But we shall aim to be in a
posture, either to negotiate honorable peace, or continue this just
war.
56.
We stand inneed of the advice and assistance of all our friends
in the matter of finance, as the quantity of our paper currency
necessarily emitted has produced a depreciation, which will be
ruinous if not speedily checked. We have encouraging accounts of
the temper of the Hollanders of late, and expect that we may find
relief from that quarter among others.
A few weeks, if not a few days, must produce fruitful subject for
another letter, when we shall, in our line of duty, renew our
assurances of being, with great regard,
Sir, your affectionate humble servants,
RICHARD H. LEE,
JAMES LOVELL,
ROBERT MORRIS.
TO THE COMMITTEE OF FOREIGN AFFAIRS.
Paris, May 23d, 1778.
Gentlemen,
In consequence of your despatches by my colleague, Mr Adams,
I lost no moment to press the renewal of the order for the supplying
you with such stores as you want, and as that country affords, from
the Court of Spain. I have the satisfaction to inform you that such
orders are given, and I am assured will be carried into execution as
speedily as possible.
We mean to apply for the loan desired to the monied men of
Holland, and in my particular department, I shall endeavor to take
the favorable opportunity of the arrival of the flotilla to urge the
same in Spain.
War is not begun in Germany or Great Britain; but it seems to be
inevitable.
I have sent orders to all the ports in France and Spain to
communicate the account of the sailing of a fleet of thirteen ships
57.
from England againstAmerica, to all the captains who sail for the
United States or the French islands. This I conceived would be the
most certain means of communicating the alarm, and preventing
surprise.
The ministry here are also to convey a letter from us, by every
opportunity, to the same purpose.
I have the honor to be, &c.
ARTHUR LEE.
TO THE COMMITTEE OF FOREIGN AFFAIRS.
Paris, June 1st, 1778.
Gentlemen,
The hurry in which the last despatches went away, prevented me
from being so particular about them as I wished. Nos. 7, 8 and 9
were omitted, being newspapers, and too voluminous for the
conveyance. M. Monthieu’s papers were sent to show you the
demands that are made upon us, and the grounds of them. You will
see that they are accounts, which Mr Deane ought to have settled. It
is this sort of neglect, and a studied confusion, that have prevented
Mr Adams and myself, after a tedious examination of the papers left
with Dr Franklin, from getting any satisfaction as to the expenditure
of the public money. All that we can find is, that millions have been
expended, and almost everything remains to be paid for. Bargains
have been made of the most extravagant kind with this Mr Monthieu
and others. For example, the uniforms that are agreed for at
thirtyseven livres might have been had here for thirtytwo livres each,
and equally good, which, being five livres in every suit too much,
comes to a large sum upon thousands.
Of the 100,000 livres advanced to Mr Hodge, there appears no
account. I have been told that Cunningham’s vessel cost but three
thousand pounds sterling; for what purpose the overplus was given
to Mr Hodge, how the public came to pay for her refitting, and at
58.
length the vesseland her prize money made over to Mr Ross and Mr
Hodge, without a farthing being brought to public account, it rests
with Mr Deane or Mr Hodge to explain. I have enclosed you all the
receipts found among those papers, the sending of which has been
neglected. Of the triplicates and duplicates an original is sent, and
copies of those that are single. You will see that my name is not to
the contracts. In fact they were concealed from me with the utmost
care, as was every other means of my knowing how these affairs
were conducted; and as both my colleagues concurred in this
concealment, and in refusing my repeated requests to make up
accounts and transmit them to Congress, it was not in my power to
know with accuracy, much less to prevent, this system of profusion.
I was told that Mr Williams, to whom I knew the public money was
largely intrusted, was to furnish his accounts monthly, but they were
never shown me, and it now appears, that for the expenditure of a
million of livres he has given no account as yet, nor can we learn
how far what he has shipped is on the public, how far on private
account. We are in the same situation with regard to Mr Ross. This
indulgence to Mr Williams,[34] and favoring M. Chaumont, a
particular friend of Dr Franklin, is the only reason I can conceive for
the latter having countenanced and concurred in all this system. You
will see a specimen of the manner of it in the enclosed copy of a
letter from Dr Franklin to his nephew, which the latter sent me as an
authority for his doing what the commercial agent conceived to be
encroaching on his province. I have done my utmost to discharge
my duty to the public, in preventing the progress of this disorder and
dissipation in the conduct of its affairs. If it should be found that my
colleagues have done the same, I shall most cordially forgive them
the offence and injury so repeatedly offered me in the manner of it.
I do not wish to accuse them, but excuse myself; and I should have
felt as much happiness in preventing, as I have regret in
complaining of this abuse.[35]
The appearance of things between this country and Great Britain,
and the Emperor and the King of Prussia, has been so long hostile,
without an open rupture, that it is not easy to say when either war
59.
will begin. TheKing of Prussia has found it so necessary to cultivate
the aid of Hanover, Hesse, Brunswick, &c. that he has declined
receiving your deputy, or following the example of France as he
promised. It remains therefore to try the Empress, who, independent
of the present crisis, was much less inclined to our cause. It seems
to be the settled system of northern politics, that if a war should
happen, the Empress of Russia will assist the King of Prussia, as far
as the Porte will permit her.
In this country, the appointment of Marechal de Broglio
commander of the army on the sea coast, and the Duc de Chartres,
son to the Duc d’Orleans and Prince of the blood, going on board the
fleet at Brest, announce designs of some dignity and magnitude.
I am of opinion, with our colleague Mr Adams, that it would be
better for the public, that the appointment of your public ministers
were fixed, instead of being left at large, and their expenses
indefinite. From experience I find the expense of living in that
character cannot well be less than three thousand pounds sterling a
year, which I believe too is as little as is allowed to any public
minister above the rank of a consul. If left at liberty, I conceive that
most persons will exceed this sum. Neither do I perceive any
adequate advantage to be expected from having more than one
person at each Court. When things take a more settled form, there
will be little need of that check, which is the chief utility of it at
present.
The mixing powers too, and vesting them in several persons at
the same time, give ground for disputes, which are disgraceful as
well as detrimental to the public. This has been much experienced in
the case of the commercial agents, and the agent of the
Commissioners, who have been clashing and contesting till the
public business was almost entirely at a stand. For the present,
however, we have settled this matter, by directing all commercial
business to be put into the hands of those appointed by the
commercial agent, till the pleasure of Congress is known.
60.
Two more shipshave been lately sent to Newfoundland, and two
to the Mediterranean, which, with thirteen detached under Admiral
Byron to reinforce Lord Howe, leave seventeen of the line and eight
frigates for Admiral Keppel, and these very ill manned. I have
exceeding good information, that their plan of operations for
America is as follows.
General Howe is to evacuate Philadelphia, sending five thousand
of his troops and two ships of war to Quebec; the rest of the troops
with the fleet are to return to Halifax, where the latter being joined
by Admiral Byron will, it is presumed, maintain a superiority in those
seas over the allied fleet.
I wrote you before, that the lowest estimate given to the English
Ministry for the defence of Canada was eight thousand men, and
that their actual force there was about four thousand; the five
thousand added will, in their opinion, be sufficient, with their
superiority at sea, for its protection. I cannot learn that any but
some German recruits are to be sent out this year, and from the
situation of things they are more likely to recall a great part of their
troops, than to reinforce them.
Our friends in Spain have promised to remit me 150,000 livres
more, which I shall continue to vest in supplies that may be useful to
you.
I hope, in consequence of what I formerly wrote, to have the
express order of Congress relative to the line they would choose to
fix between the territories of the United States, and those of the
crown of Spain. The privileges to be enjoyed by the subjects of the
United States, settling for the purposes of commerce, and the
regulation of port duties, remain yet to be settled in both nations.
But I foresee that if they are left unregulated, they will be the source
of complaints and disagreements.
The flotilla is not yet in port, which retards the operations in
Europe. I could have wished that the great object of having a
superior naval force in America, had not been left to the uncertain
61.
issue on whichit was placed by other advice than mine. Had the
Brest and Toulon fleets, which were equally ready, been ordered to
sail at the same time, that which met immediately with favorable
winds to go on, and the other to return, one of them would probably
have been upon your coast before this time, that is, before the
English fleet could possibly have sailed to reinforce and save Lord
Howe; and as having a superior force in America was the great
object, together with that of taking the Howes by surprise, they
should have made as sure of this aim as possible. And indeed, had it
been executed with address, the war would have been ended.
M. Penet has proposed to me the collecting and carrying over a
number of workmen to establish a foundery of cannon, and a
manufactory of small arms. It is to be at his expense, under the
protection of Congress. As this seems to me much more likely to
answer your purposes than our sending them, I have ventured to
give him my opinion, that it will be acceptable to Congress. We have
found such a universal disposition here to deceive us in their
recommendations, that it is ten to one, if workmen chosen by us in
such a circumstance were skilful.
The disposition in Holland seems to be favorable to us, but I
apprehend it is not warm enough to produce any decided proof of it,
till they see Great Britain more enfeebled. M. Dumas has published a
Memoir I sent him on the subject, which he thinks will have some
effect.
With my humble duty to Congress, I have the honor to be, &c.
ARTHUR LEE.
62.
TO M. DUMAS.
Chaillot,June 4th, 1778.
Dear Sir,
It gave me great pleasure to receive the key to the treasure you
sent us before in Dutch, my unacquaintance with which having
prevented me from knowing how much I was obliged to you, for the
improvement made in the little essay I had the honor of sending to
you. Felix faustumque sit. May it open the eyes of your people to
their own interests, before a universal bankruptcy in England, and a
compelled frugality in America, have deprived them of the golden
opportunity of extricating themselves from bad debtors, and
connecting themselves with good ones.
So fair an opportunity of sharing in the most valuable commerce
on the globe, will never again present itself; and, indeed, they are
greatly obliged to the noble and disinterested principles of the Court
of France, which prevented this country from attempting to possess
itself of the monopoly, which Great Britain had forfeited. In truth,
they were great and wise principles, and the connexion formed upon
them will be durable. France, and the rest of Europe, can never pay
too large a tribute of praise to the wisdom of The Most Christian
King, and his Ministers, in this transaction.
You are happy in having the esteem and counsel of the Grand
Facteur, who seems to have equal good sense and good intentions.
Our enemies seem embarrassed in their operations. As far as we can
learn, their fleet has not yet sailed for America to save the Howes
from the fate that hangs over them. We have no intelligence on
which we can rely.
I have the honor to be, &c.
ARTHUR LEE.
63.
TO THE COMMITTEEOF FOREIGN AFFAIRS.
Paris, June 9th, 1778.
Gentlemen,
My last of the 1st, informed you of Admiral Byron, with thirteen
sail, being ordered against you, of which we sent notice by every
way most likely to warn the States of their danger.
We have now certain advice, that this fleet having put into
Plymouth is there stopped, their remaining fleet being found too
weak to protect them at home. I enclose you a late account of their
force and the disposal of it; and nothing seems more certain, than
that the naval and land force now employed against you will be
diminished, not augmented. However, I have now settled such
means of intelligence, that you will be apprized if any alteration
should happen.
All our intelligence announces the utmost confusion in Great
Britain and Ireland; such as will infallibly find them employment at
home, independent of France and Spain. Their councils are so
fluctuating in consequence of the variety of their distress, that
advices of them cannot be given with certainty; that is, without
being frequently subject to appear premature.
The British Ministry have agreed to an exchange of prisoners with
us, by which we shall immediately release upwards of 200.
War is not commenced in Germany, but is talked of as inevitable.
The deputy of Congress for Vienna is at his destination to feel the
disposition of that Court. But I understand, that their attention is so
engaged with the approaching war, that other propositions proceed
slowly. As the King of Prussia contends against the Empress and the
House of Austria, in maintenance of the treaty of Westphalia, which
is the great bulwark of German rights, it is therefore necessary, that
he should league himself with the German Princes, among whom the
King of Great Britain, as elector of Hanover, bears so much sway,
that he could not hazard the turning his influence against him by
entering into an alliance with us. To cultivate and encourage the
64.
favorable disposition towardsus in Holland, we have sent them the
treaty concluded here, and we shall follow it by proposals for a loan,
as soon as Dr Franklin (to whom the digesting of the plan, and
having the proposed bills printed, is left) has prepared the business
for execution.
Mr Williams has at length given in his accounts, from which it
appears, that upwards of forty thousand suits of the soldiers’ clothes
ordered, and twenty thousand fusils, have been sent from Nantes
and Bordeaux; and the present exhausted state of our finances will
not permit us to fulfil them further. The ships of war sent hither are
an enormous expense to us; hardly any of them less than 100,000
livres, and things have been hitherto so managed, that their prizes
produce us little or nothing. This seems to have arisen from the
variety of agents employed, the confusion of their provinces, and the
loose manner in which the public accounts have been kept. To
remedy this, we have to simplify the business of expenditure, by
directing the whole to be discharged by the two deputy commercial
agents appointed by my brother, in the interval of his negotiation in
Germany. By this we expect to avoid the infinite impositions arising
from a connexion with a multiplicity of merchants, many of whom,
supposing us to know no better, will endeavor to deceive us. They,
as merchants, know how to check the others, and are themselves
ultimately responsible to us.
I have the honor to be, &c.
ARTHUR LEE.
TO COUNT DE VERGENNES.
Chaillot, June 14th, 1778.
Sir,
It was with great pleasure I heard the explanation, which your
Excellency did me the honor to give me yesterday relative to the
12th article of the Commercial Treaty; that it was meant to
65.
comprehend only provisions,and not the whole of our exports to his
Majesty’s Islands, and that denrées, the word employed, signifies
eatables, not merchandise. It relieved the apprehensions I had
entertained, that the having set in that article the whole of our
produce against one of your productions would seem unequal, would
therefore give uneasiness in Congress, and prevent that unanimity in
their approbation of the treaty, which the wise and liberal principles
on which it is planned deserve; and which I most sincerely wished it
might receive.
Upon referring, however, to the words of the treaty, I find they
are denrées et marchandise, so that the words appear, by I know
not what accident, to have been different from, and to mean more
than you intended. I lament extremely that nothing of this
explanation passed in our conference and correspondence with M.
Gerard on this and the preceding article. Yet I am not without hope,
that Congress will rather trust to the equity of your Court for
reducing the article to its intended equality, than gratify our enemies
by an appearance of dissension in ratifying the treaties.
Reciprocity and equality being the principles of the treaties, and
duration the object, your Excellency will, in my judgment, have an
opportunity of strengthening the confidence and ties between us, by
offering to remove words of a latitude not intended, and of an
inequality, which must be seen and create dissatisfaction.
I have the honor to be, &c.
ARTHUR LEE.
COUNT DE VERGENNES TO ARTHUR LEE.
Translation.
Versailles, June 15th, 1778.
Sir,
66.
I received withpleasure the letter you did me the honor of
writing to me yesterday. We shall not be long probably before we
receive news from your constituents, and their judgment of the act
which you signed here in conjunction with your colleagues. Should
they demand any eclaircissements, we shall not refuse to make
them. You know our principles, and I think we have given proofs of
our disinterestedness.
I see with pleasure, Sir, that you are satisfied with the proofs of
the Prince de Montbaray’s zeal in procuring you the articles you
requested from him.[36] You will always find us disposed to do
everything, that may concern the welfare of the United States of
America.
I have the honor to be, &c.
DE VERGENNES.
TO THE COMMITTEE OF FOREIGN AFFAIRS.
Paris, June 15th, 1778.
Gentlemen,
I find I was mistaken in saying in my last, of the 9th, that twenty
thousand fusils had been shipped from Nantes and Bordeaux;
upwards of ten thousand remain unshipped, at Nantes. Upon the
strength of the promised remittance from our friends in Spain, and
near one hundred thousand remaining in my hands, I have desired
the Gardoquis to continue shipping blankets and strong shoes from
Bilboa; twenty thousand livres worth of drugs, and salt to be shipped
by Mr Cathatan of Marseilles; a thousand suits of soldiers’ clothes
from Bordeaux, by Mr Bonfield; and six hundred fusils, of the
Prussian make, from Berlin, that you may judge on arming a corps
with them whether they are preferable to others.
My brother writes me from Vienna in a late letter, that Colonel
Faucit is using the utmost endeavors to raise German recruits; but
from the present state of things, I do not imagine he can succeed;
67.
and the North,that is Russia and Denmark, are not likely to give our
enemies any assistance. As far as I can judge, their efforts against
us, except a sort of piratical war, are exhausted. The same ministry
continues. The House of Bourbon is certainly united against them.
They have the same imbecility of council. Their enemies increase in
proportion to the diminution of their means. The decay of their
commerce, the distress of their people, the rapacity of their public
officers, and the load of their debt and taxes, promise soon to bring
upon them the most deplorable distress, and prevent them from
being any longer a formidable enemy.
The flotilla is not yet arrived. The enclosed copies of Captain
Jones’ letters, and one[37] from the majority of his crew, make me
apprehend, that the Ranger will share the fate of the Revenge. We
have done all in our power to bring him and his officers into order,
but hitherto in vain.
I have the honor to be, &c.
ARTHUR LEE.
TO THE COMMITTEE OF FOREIGN AFFAIRS.
Paris, July 1st, 1778.
Gentlemen,
I enclose you some extracts, by which you will see, that war is
not yet declared, though on all hands it appears to be fast
approaching.
The Spanish flotilla is not yet arrived, nor their fleet from South
America. Since my last, a French frigate of twentysix guns was
attacked by an English frigate of twentyeight, off Brest, and after an
obstinate engagement the latter made off, and soon after sunk! This
has given great spirits to the French marine and nation, and is more
especially fortunate, as the English were the aggressors. Admiral
Keppel is before Brest, with twentythree sail of the line, where I
believe he will not remain long unattacked. Permission is given to
68.
French subjects tofit out privateers; and orders are sent to all the
ports to prepare our prizes to be sold. From London, the Ministry
have offered us an exchange of prisoners, which we are taking the
necessary measures to embrace.
By some unaccountable neglect the person, to whom Dr Franklin
committed the printing of the bills resolved on for the loan, has not
furnished them, so that nothing further is yet done in that business.
But I hope you will soon have news of its further progress, and that
some event will happen to furnish us with a very favorable moment
for its execution.
I have the honor to be, &c.
ARTHUR LEE.
Mr Lee presents his respects to his Excellency Count
d’Aranda, and begs he will have the goodness to forward
the packet, addressed to Count de Florida Blanca, which
he has the honor of enclosing him, and which is on
business of the last importance, by the first opportunity to
his Court.
TO COUNT DE FLORIDA BLANCA.
Paris, July 18th, 1778.
Sir,
I have the honor of transmitting to your Excellency the enclosed
resolutions of Congress,[38] with my most earnest prayer, that they
may be laid immediately before the King. Nothing but the
uncommon exigency of the present war, attended with such peculiar
circumstances with regard to the United States, would prevail upon
them to press so much upon his Majesty’s goodness. That necessity
must also plead my pardon for entreating your Excellency to let me
have as early an answer as possible. As the United States have the
highest confidence in the friendship of the King, they promise
themselves that his goodness will afford this loan as a relief to their
69.
most urgent distresses.With regard to the interest for the quantum
of that, they refer themselves to his Majesty’s justice. Five per cent
is the legal interest with them, but I am authorised to give six, if his
Majesty should desire it.
This interest will be most punctually paid; and they will neglect
no means of liquidating the principle, if desired, sooner than the
stipulated time, which will be easily accomplished, when peace or
some other employment of the enemy’s navy than that of preying
upon their trade will permit the export of their produce to European
markets.
Your Excellency will perceive, that this loan is appropriated to
sinking the paper money, which necessity obliged Congress to issue.
An infant and unprepared people, compelled to defend themselves
against an old, opulent, powerful, and well appointed nation, were
driven to this resource of issuing paper. They were to create armies
and navies, to fortify towns, erect forts, defend rivers, and establish
governments, besides the immense expense of maintaining a war,
that pressed them powerfully on all sides. For these purposes they
had neither funds established, taxes imposed, specie in their
country, nor commerce to introduce it. In this exigency paper money
was their only resource, and not having been able hitherto for the
same reasons to redeem it, the depreciation, which necessarily
followed, threatens the total destruction of their credit, and
consequently their only means of maintaining their independence.
In this distress their hope is fixed upon his Majesty, and I most
earnestly beseech your Excellency so to represent our situation to
the King, as may move his royal benevolence to furnish the relief,
which will raise an everlasting tribute of gratitude in the minds of the
people of the United States.
I have the honor to be, with the greatest respect, your
Excellency’s most obedient, &c.
ARTHUR LEE.
70.
TO THE COMMITTEEOF FOREIGN AFFAIRS.
Paris, July 29th, 1778.
Gentlemen,
I enclose you a duplicate of the news of an engagement between
the fleets of France and England. The particulars received since
make the loss on board the French fleet very inconsiderable, and
paint the behavior of the English to have been inexpert and
dastardly. The repulsing them in the first engagement will probably
lead to the defeating them in the next, for which purpose the fleet of
our allies will go out in a few days.
The Empress and Emperor seem at length sensible of the
impropriety of their conduct, and in consequence a truce for six
weeks is agreed on, to give time for negotiation to prevent the
effusion of blood.
The quadruplicate of the ratification reached us on the 3d in
safety, as all the rest have done. The answer of Congress to the
Commissioners was immediately sent to the ministers, and will, I am
persuaded, give great satisfaction.
It has been forgotten, I believe, to mention both in our joint and
particular letters, that we have attended to the plan proposed by the
Committee of sending the frigates to cruise in the East Indies, and
upon considering all things it seemed to us impracticable at present.
Better order must be established in our marine, and the ships’
companies better sorted, before it will be safe to attempt enterprises
at such a distance, and which require a certain extent of ideas in the
Captain, and entire obedience in the crew.
The authority of Congress for omitting the 11th and 12th articles
of the Commercial Treaty, which was omitted in the other
despatches, came safe in the last, and will be presented immediately
to the minister, who has already agreed to have them expunged.
I enclose you our letter, and Mr Hodge’s answer, concerning the
money expended at Dunkirk, together with a particular account of
71.
what he hasreceived from the public banker.
I have the honor to be, &c.
ARTHUR LEE.
JAMES GARDOQUI TO ARTHUR LEE.
Madrid, August 13th, 1778.
Dear Sir,
My last respects went to you under the 23d ult. and referring you
to my sequels with regard to your desires of me in money matters, I
must beg leave to inform you, that the proposal you have made for
borrowing money through the hands of a nobleman at your place is
received, and that your being served therewith would give your
friends on this side a real pleasure, but I am sorry to tell you, that it
is impossible for the present. You will please to observe and consider
upon the immense charges occasioned within these two or three
years, and that all is done merely on account of your present
quarrel, as likewise that such formidable preparations have been and
will still be of infinite service to the Americans; besides which, it is
well known to yourself, and more so to your worthy constituents,
that great succors have been sent forthwith through various
channels, and that the same is continued to this day, and will be so
in future as much as possible.
In short, it is not doubted but you will represent the whole to
your constituents, looking upon all in its true light, and observing
that if affairs should be accommodated to their satisfaction and that
of this side, the means of succoring you would be facilitated.
I am, Sir, your most obedient humble servant.
JAMES GARDOQUI.
JAMES GARDOQUI TO ARTHUR LEE.
72.
Madrid, August 20th,1778.
Dear Sir,
I confirm my last compliments to you under the 13th inst,
wherein I observed how difficult it would be to borrow the two
millions sterling here, under the present circumstances, more
especially while the enormous charges and fitting out of vessels are
carried on merely to protect your colonies, which are besides
assisted with effective succors, and will be so in future as much as
possible. Since my letter, I have maturely considered upon the
matter, and it has occurred to me, that if your government means by
it to take up all the paper that has been laid out, perhaps the
cession of Florida to Spain, (in case you could reduce it,) might at
the conclusion of peace produce, if not the whole, at least a great
part of the funds required.
You will no doubt consider, that I cannot penetrate the way of
thinking of our Court in this and other entangled matters, but
judging like a merchant, I think a negotiation of this kind might well
take place, for I imagine it would be proper for both, that the
frontier in question should not remain in future in the hands of
enemies or suspicious powers. There is, besides, a further
negotiation which might be added to the great benefit of your States
and this Court, and that is, your providing this kingdom with good
timber for the Spanish navy at commodious prices.
I hope, Sir, you will excuse my liberty in pointing out these hints,
to which I am led by the honest principle of friendship, and by the
wished for view that the interest of both countries may be united
upon a sincere and lasting footing; therefore I hope you will weigh
the same as you may think more convenient, observing that I
suppose you will not propose it to our Court, before you know how
the honorable Congress thinks upon both objects.
I am with unfeigned esteem, &c.
JAMES GARDOQUI.
73.
TO THE COMMITTEEOF FOREIGN AFFAIRS.
Paris, August 21st, 1778.
Gentlemen,
I wrote you on the 28th ult. of my having pressed for the loan
directed by Congress. I have received an assurance through the
Ambassador, that an answer will be given to my memorial as soon as
possible.
I enclose you a memorial for the consideration of Congress, as
we do not think ourselves authorised to act upon it without express
orders. Could one be sure, that justice would be done to the public,
it might be of advantage to adopt this scheme, for Congress must
not trust to the success of a loan, which, for the following reasons, I
apprehend will be found impracticable.
The war in Germany supervening on that between us and Great
Britain, and the preparations for it by France and Spain, have raised
and multiplied the demand for money, so as to give the holders of it
their choice and their price. The Empress Queen has engrossed
every shilling in the Netherlands. England has drawn large sums
from the Hollanders, who cannot easily quit their former market.
France is negotiating a loan of one hundred million livres, which will
exhaust Geneva and Switzerland. The money holders regard the
lending their money at such a distance, as Jacob did the sending
Benjamin into Egypt, and it is time only will make them endure the
thought of such a separation.
These are the difficulties which the circumstances of things
oppose to our scheme of a loan, and render the aid of some other
operation necessary for sinking the superabundant paper.
The Minister’s answer relative to M. Holker was, that he had no
authority from this Court, but on this our joint letter I expect will be
more full. I have determined to write to you once a month or
oftener, as opportunity offers, and as we do not write so frequently,
74.
I am temptedto mention things which should properly come from all
the Commissioners, as they relate to the joint commission.
From the necessity of the case we have ventured to administer
the oath of allegiance to those who desire passports of us, but I
hope Congress will authorise their Commissioners to do so where it
is necessary.
I have the honor to be, &c.
ARTHUR LEE.
TO JAMES GARDOQUI.
Paris, August 27th, 1778.
Dear Sir,
I received yesterday your favor of the 13th. If I remember rightly
what made me delay writing to you relative to the bills was my
desire of informing you, at the same time, of their being accepted;
and it was long before I could learn that myself, from the manner in
which they were drawn. I am very sorry it did you any disservice.
I am neither unmindful of, nor ungrateful for, the support we
have received from your quarter. The inevitable necessity, which
compelled an application for more, gave me great uneasiness. I was
sensible the sum desired was very considerable. But so are our
wants. It is our misfortune, not our fault, that we are obliged thus to
trouble and distress our friends. I trust they will consider it in that
light. There is nothing more precarious and immeasureable than
what influences public credit. The sum sought would have enabled
Congress to call in such a quantity of the paper emitted, as must
establish the credit and value of the rest in defiance of all the efforts
of our enemies. And I think that if our friends could lend us even as
much as would constitute a fund here, on which Congress might
draw, so as to call in at once one or two million dollars, it would
greatly raise the value of the rest. This would require about eight or
ten million livres. When it is seen that the redemption is begun,
75.
Welcome to ourwebsite – the perfect destination for book lovers and
knowledge seekers. We believe that every book holds a new world,
offering opportunities for learning, discovery, and personal growth.
That’s why we are dedicated to bringing you a diverse collection of
books, ranging from classic literature and specialized publications to
self-development guides and children's books.
More than just a book-buying platform, we strive to be a bridge
connecting you with timeless cultural and intellectual values. With an
elegant, user-friendly interface and a smart search system, you can
quickly find the books that best suit your interests. Additionally,
our special promotions and home delivery services help you save time
and fully enjoy the joy of reading.
Join us on a journey of knowledge exploration, passion nurturing, and
personal growth every day!
ebookmasss.com





















![2.2 Background
Conversational agents, in their larger definition, are software agents with which it is
possible to carry a conversation. Researchers discussed largely on structuring the terminol-
ogy around conversational agents. In this chapter, we decide to adhere to Franklin and
Graesser (1997) that segments conversational agents according to both learned and
indexed content and approaches for understanding and establishing a dialog. The evolu-
tion of conversational agents proposed three different software types: generic chit-chat
(i.e., tools for maintaining a general conversation with the user), goal-oriented tools that
usually rely on a large amount of prebuilt answers (i.e., tools that provide language inter-
faces for digging into a specific domain), and the recently investigated knowledge-based
agents that aim to reason over a semantic representation of a dataset to extend the intent
classification capabilities of goal-oriented agents.
The first chit-chat tool, named ELIZA (Weizenbaum, 1966), was built in 1966. It was cre-
ated mainly to demonstrate the superficiality of communications and the illusion to be
understood by a system that is simply applying a set of pattern-matching rules and a substi-
tution methodology. ELIZA simulates a psychotherapist and, thanks to the trick of present-
ing again to the interlocutor some contents that have been previously mentioned, it keeps
the conversation without having an understanding of what really is said. At the time when
ELIZA came out, some people even attributed human-like feelings to the agent. A lot of
other computer programs have been inspired by ELIZA and AIML—markup language for
artificial intelligence—has been created to express the rules that drive the conversation. So
far, this was an attempt to encode knowledge for handling a full conversation in a set of
predefined linguistic rules.
Domain-specific tools were designed to allow an individual to search conversationally
into a restricted domain, for instance simulating the interaction with a customer service of
a given company. A further generalization of this typology was introduced by knowledge-
based tools able to index a generic (wider) knowledge base and provides answers pertain-
ing a given topic. These two are the largest utilized types of conversational agents
(Ramesh et al., 2017). The understanding of the interactions is usually performed using
machine learning, in fact recent approaches have abandoned handcrafted rules utilized in
ELIZA toward an automatic learning from a dialog corpus. In other words, the under-
standing task is related to turning natural language sentences into something that can be
understood by a machine: its output is translated into an intent and a set of entities. The
response generation can be fully governed by handcrafted rules (e.g., if a set of conditions
apply, say that) or decide the template response from a finite set using statistical
approaches [using some distance measures like TF-IDF, Word2Vec, Skip-Thoughts (Kiros
et al., 2015)]. In this chapter, we focus on the understanding part of the conversation.
While machine learning offers statistical support to infer the relationship between sen-
tences and classes, one pillar of these approaches is the knowledge about the classes of
these requests. In fact, popular devices such as Amazon Echo and Google Home require,
whether configured, to list the intents of the discussion. However, those devices hardly
cope with a full dialog, multiturn, as the intents are either considered in isolation or con-
textualized within strict boundaries. Previous research attempts investigated the
I. Representation
9
2.2 Background](https://image.slidesharecdn.com/32049-250402052604-1c8fe6bc/75/Web-Semantics-Cutting-Edge-and-Future-Directions-in-Healthcare-Sarika-Jain-23-2048.jpg)









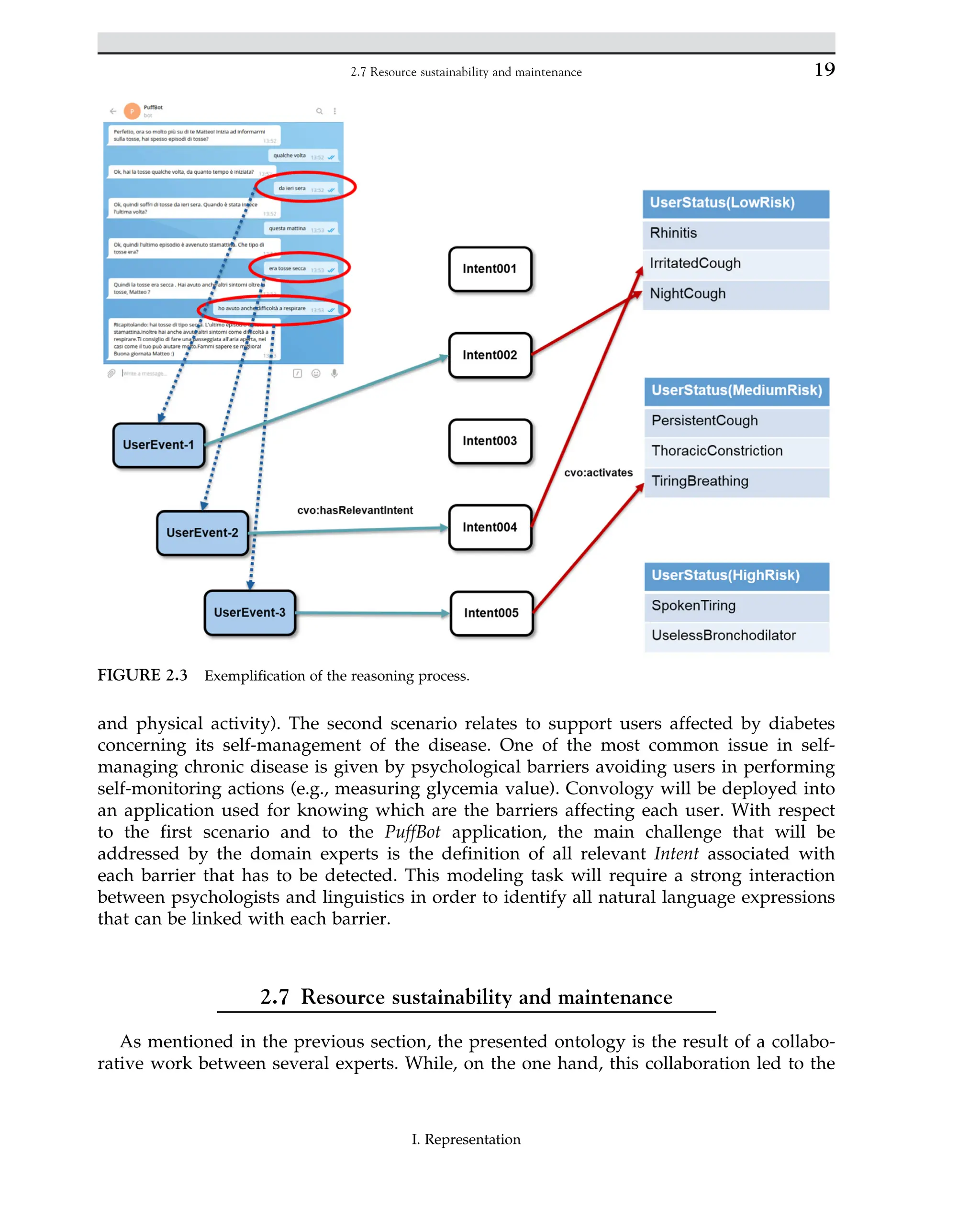






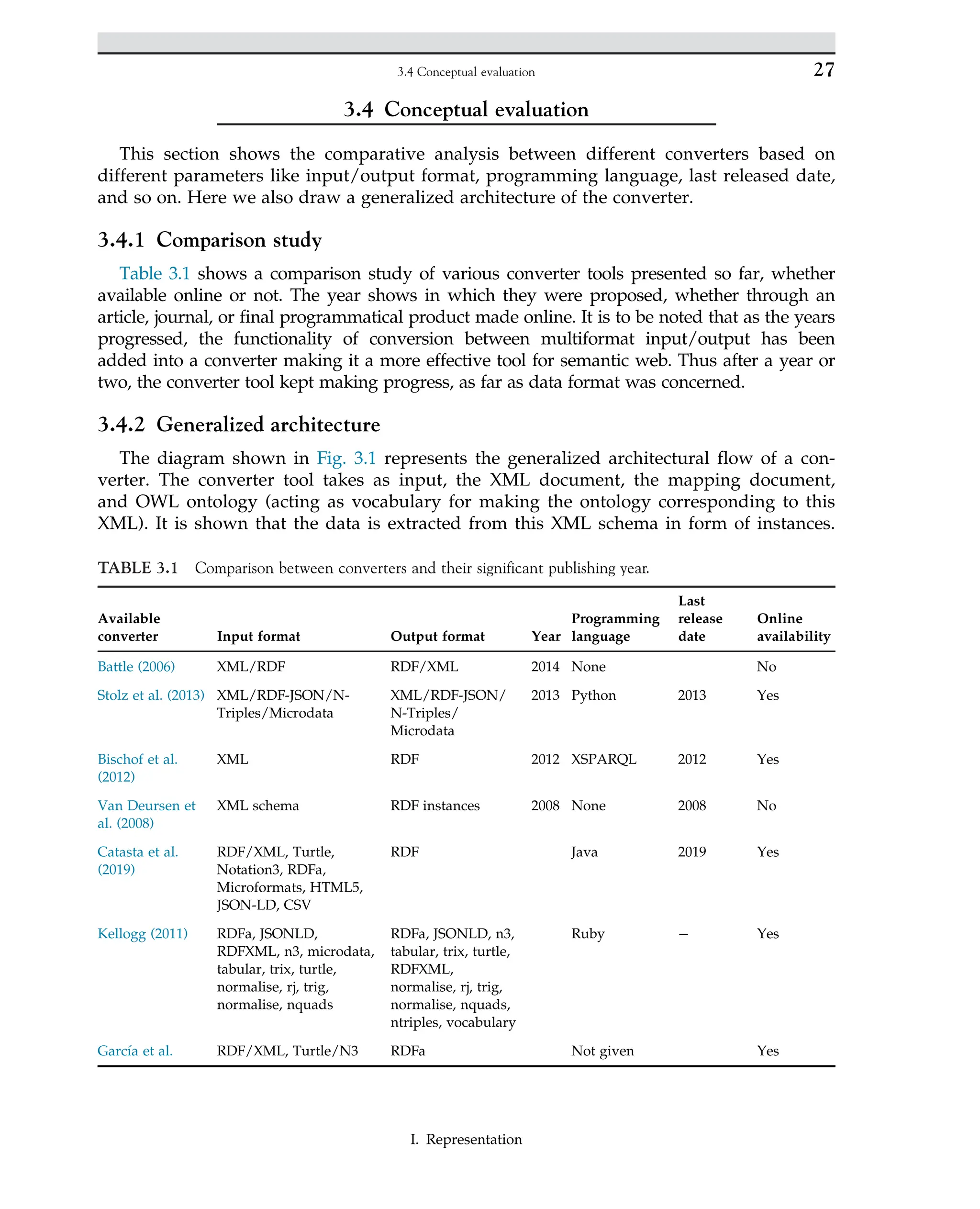






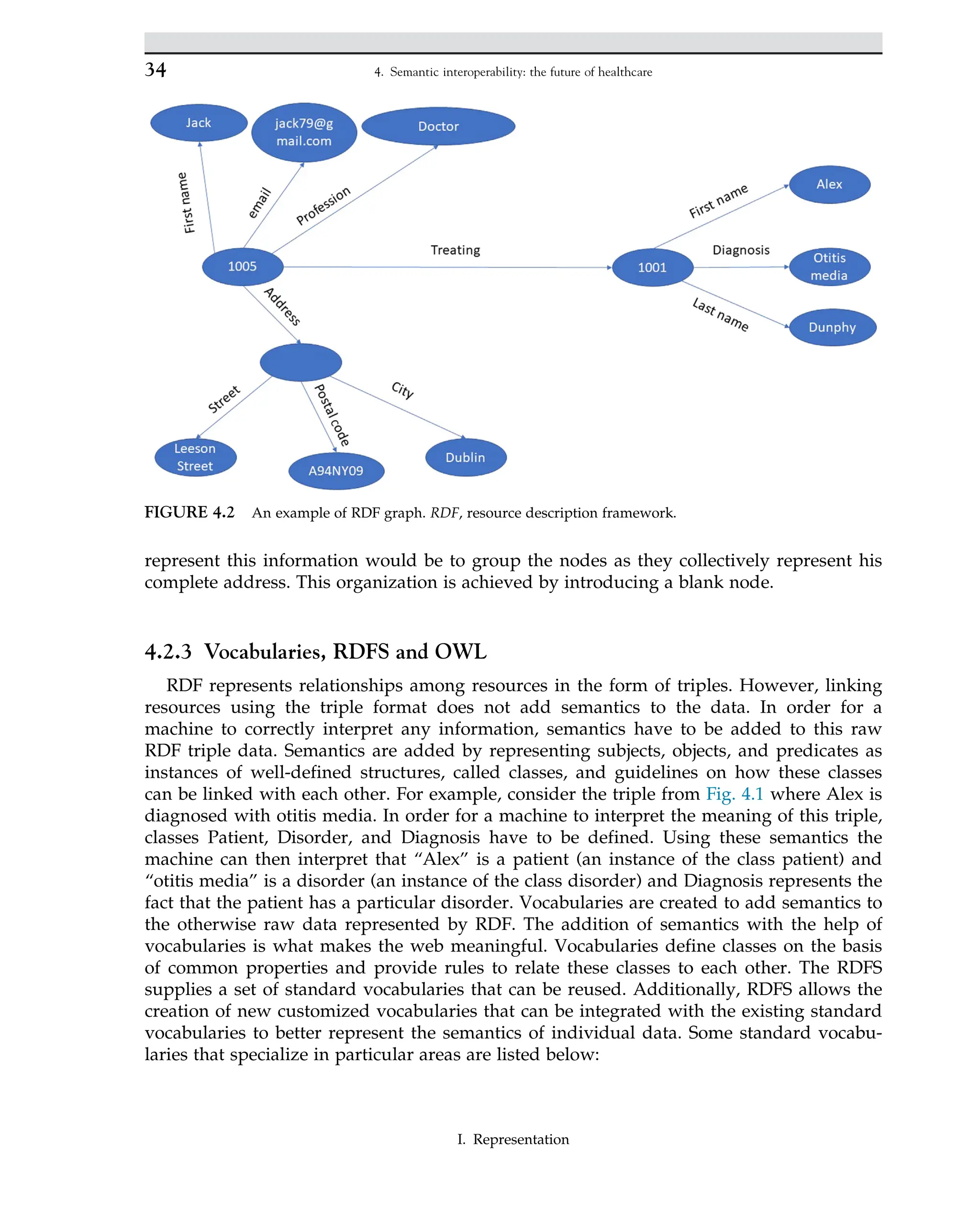










![length the vessel and her prize money made over to Mr Ross and Mr
Hodge, without a farthing being brought to public account, it rests
with Mr Deane or Mr Hodge to explain. I have enclosed you all the
receipts found among those papers, the sending of which has been
neglected. Of the triplicates and duplicates an original is sent, and
copies of those that are single. You will see that my name is not to
the contracts. In fact they were concealed from me with the utmost
care, as was every other means of my knowing how these affairs
were conducted; and as both my colleagues concurred in this
concealment, and in refusing my repeated requests to make up
accounts and transmit them to Congress, it was not in my power to
know with accuracy, much less to prevent, this system of profusion.
I was told that Mr Williams, to whom I knew the public money was
largely intrusted, was to furnish his accounts monthly, but they were
never shown me, and it now appears, that for the expenditure of a
million of livres he has given no account as yet, nor can we learn
how far what he has shipped is on the public, how far on private
account. We are in the same situation with regard to Mr Ross. This
indulgence to Mr Williams,[34] and favoring M. Chaumont, a
particular friend of Dr Franklin, is the only reason I can conceive for
the latter having countenanced and concurred in all this system. You
will see a specimen of the manner of it in the enclosed copy of a
letter from Dr Franklin to his nephew, which the latter sent me as an
authority for his doing what the commercial agent conceived to be
encroaching on his province. I have done my utmost to discharge
my duty to the public, in preventing the progress of this disorder and
dissipation in the conduct of its affairs. If it should be found that my
colleagues have done the same, I shall most cordially forgive them
the offence and injury so repeatedly offered me in the manner of it.
I do not wish to accuse them, but excuse myself; and I should have
felt as much happiness in preventing, as I have regret in
complaining of this abuse.[35]
The appearance of things between this country and Great Britain,
and the Emperor and the King of Prussia, has been so long hostile,
without an open rupture, that it is not easy to say when either war](https://image.slidesharecdn.com/32049-250402052604-1c8fe6bc/75/Web-Semantics-Cutting-Edge-and-Future-Directions-in-Healthcare-Sarika-Jain-58-2048.jpg)







![I received with pleasure the letter you did me the honor of
writing to me yesterday. We shall not be long probably before we
receive news from your constituents, and their judgment of the act
which you signed here in conjunction with your colleagues. Should
they demand any eclaircissements, we shall not refuse to make
them. You know our principles, and I think we have given proofs of
our disinterestedness.
I see with pleasure, Sir, that you are satisfied with the proofs of
the Prince de Montbaray’s zeal in procuring you the articles you
requested from him.[36] You will always find us disposed to do
everything, that may concern the welfare of the United States of
America.
I have the honor to be, &c.
DE VERGENNES.
TO THE COMMITTEE OF FOREIGN AFFAIRS.
Paris, June 15th, 1778.
Gentlemen,
I find I was mistaken in saying in my last, of the 9th, that twenty
thousand fusils had been shipped from Nantes and Bordeaux;
upwards of ten thousand remain unshipped, at Nantes. Upon the
strength of the promised remittance from our friends in Spain, and
near one hundred thousand remaining in my hands, I have desired
the Gardoquis to continue shipping blankets and strong shoes from
Bilboa; twenty thousand livres worth of drugs, and salt to be shipped
by Mr Cathatan of Marseilles; a thousand suits of soldiers’ clothes
from Bordeaux, by Mr Bonfield; and six hundred fusils, of the
Prussian make, from Berlin, that you may judge on arming a corps
with them whether they are preferable to others.
My brother writes me from Vienna in a late letter, that Colonel
Faucit is using the utmost endeavors to raise German recruits; but
from the present state of things, I do not imagine he can succeed;](https://image.slidesharecdn.com/32049-250402052604-1c8fe6bc/75/Web-Semantics-Cutting-Edge-and-Future-Directions-in-Healthcare-Sarika-Jain-66-2048.jpg)
![and the North, that is Russia and Denmark, are not likely to give our
enemies any assistance. As far as I can judge, their efforts against
us, except a sort of piratical war, are exhausted. The same ministry
continues. The House of Bourbon is certainly united against them.
They have the same imbecility of council. Their enemies increase in
proportion to the diminution of their means. The decay of their
commerce, the distress of their people, the rapacity of their public
officers, and the load of their debt and taxes, promise soon to bring
upon them the most deplorable distress, and prevent them from
being any longer a formidable enemy.
The flotilla is not yet arrived. The enclosed copies of Captain
Jones’ letters, and one[37] from the majority of his crew, make me
apprehend, that the Ranger will share the fate of the Revenge. We
have done all in our power to bring him and his officers into order,
but hitherto in vain.
I have the honor to be, &c.
ARTHUR LEE.
TO THE COMMITTEE OF FOREIGN AFFAIRS.
Paris, July 1st, 1778.
Gentlemen,
I enclose you some extracts, by which you will see, that war is
not yet declared, though on all hands it appears to be fast
approaching.
The Spanish flotilla is not yet arrived, nor their fleet from South
America. Since my last, a French frigate of twentysix guns was
attacked by an English frigate of twentyeight, off Brest, and after an
obstinate engagement the latter made off, and soon after sunk! This
has given great spirits to the French marine and nation, and is more
especially fortunate, as the English were the aggressors. Admiral
Keppel is before Brest, with twentythree sail of the line, where I
believe he will not remain long unattacked. Permission is given to](https://image.slidesharecdn.com/32049-250402052604-1c8fe6bc/75/Web-Semantics-Cutting-Edge-and-Future-Directions-in-Healthcare-Sarika-Jain-67-2048.jpg)
![French subjects to fit out privateers; and orders are sent to all the
ports to prepare our prizes to be sold. From London, the Ministry
have offered us an exchange of prisoners, which we are taking the
necessary measures to embrace.
By some unaccountable neglect the person, to whom Dr Franklin
committed the printing of the bills resolved on for the loan, has not
furnished them, so that nothing further is yet done in that business.
But I hope you will soon have news of its further progress, and that
some event will happen to furnish us with a very favorable moment
for its execution.
I have the honor to be, &c.
ARTHUR LEE.
Mr Lee presents his respects to his Excellency Count
d’Aranda, and begs he will have the goodness to forward
the packet, addressed to Count de Florida Blanca, which
he has the honor of enclosing him, and which is on
business of the last importance, by the first opportunity to
his Court.
TO COUNT DE FLORIDA BLANCA.
Paris, July 18th, 1778.
Sir,
I have the honor of transmitting to your Excellency the enclosed
resolutions of Congress,[38] with my most earnest prayer, that they
may be laid immediately before the King. Nothing but the
uncommon exigency of the present war, attended with such peculiar
circumstances with regard to the United States, would prevail upon
them to press so much upon his Majesty’s goodness. That necessity
must also plead my pardon for entreating your Excellency to let me
have as early an answer as possible. As the United States have the
highest confidence in the friendship of the King, they promise
themselves that his goodness will afford this loan as a relief to their](https://image.slidesharecdn.com/32049-250402052604-1c8fe6bc/75/Web-Semantics-Cutting-Edge-and-Future-Directions-in-Healthcare-Sarika-Jain-68-2048.jpg)









![[PDF Download] Web Semantics: Cutting Edge and Future Directions in Healthcar...](https://cdn.slidesharecdn.com/ss_thumbnails/107043-240805203721-c4d1d052-thumbnail.jpg?width=640&height=640&fit=bounds)










































