Downloaded 97 times









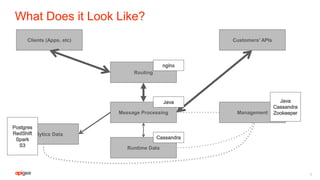

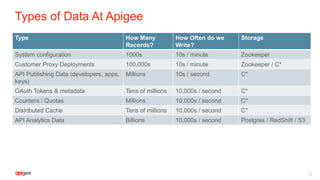
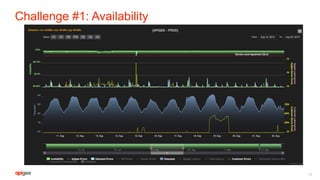








This document discusses the technical challenges of building and maintaining APIs at a global scale. It notes that APIs must be highly available, globally distributed with no downtime, rigorously monitored, and secure from attacks. It outlines Apigee's approach of using services like Zookeeper, Cassandra, and analytics platforms to distribute data and configurations globally, implement features like quotas and abuse detection, and manage high volumes of data and traffic with five-nines availability. The document also stresses the importance of managing the API platform itself with the same availability and reliability standards as the APIs.






























































































