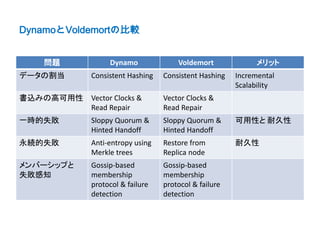
Index
• Voldemortの紹介
• Voldemortの実現技術
– Consistent Hashing and Replication
– Vector Clocking and Read Repair
– Sloppy Quorum and Hinted Handoff
– Gossip Protocol and Failure Detection
Anti-entropy using Merkletrees on Dynamo: Merkle Tree
a type of data
structure that contains
a tree of summary
information about a larger
piece of data
http://en.wikipedia.org/wiki/Hash_tree
25.
Anti-entropy using Merkletrees on Dynamo: Merkle Tree
より大きなデータ(例えば
ファイル)の要約結果を
格納する木構造の一種
http://ja.wikipedia.org/wiki/%E3%83%8F%E3%83%83%E3%82%B7%E3%83%A5%E6%9C%A8
26.
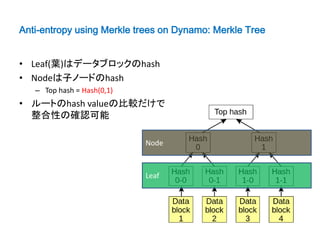
Anti-entropy using Merkletrees on Dynamo: Merkle Tree
• Leaf(葉)はデータブロックのhash
• Nodeは子ノードのhash
– Top hash = Hash(0,1)
• ルートのhash valueの比較だけで
整合性の確認可能
Node
Leaf
27.
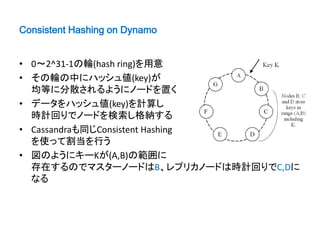
Anti-entropy using Merkletrees on Dynamo
• 各ノードはKey rangeのデータをMerkle Treeで管理
• 定期的に同じKey rangeのMerkle Treeを複数ノードが比較
• 異なる場合、最新のデータへ更新
• ノードの追加等で多くのKey rangeが変更される場合、
Merkle Tree再計算で負荷が高くなる可能性がある










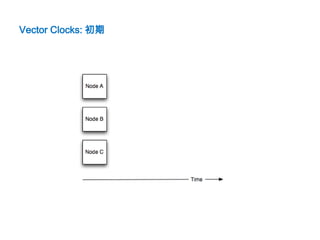
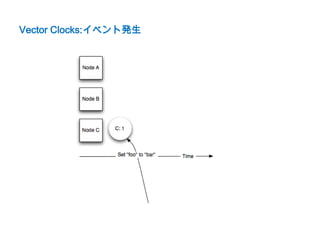
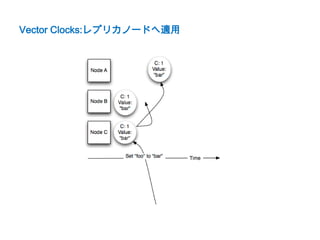
![Vector Clocks
• 書き込んだ順序を持つ
• 書込/更新時バージョンを上げる
[$nodeId, $version]
例)[C:1] -> [C:2]
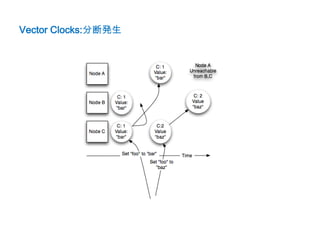
• 分断が発生すると異なるバージョンが複数ノードに存在する
例) [C:45,B:1], [C:45,A:1]
• その場合バージョンで因果関係を決められる
• 整合性は読込時解決する
– Read Repair
– アプリケーション実装](https://image.slidesharecdn.com/dynamovoldemort-121221031521-phpapp02/85/voldemort-Dynamo-12-320.jpg)
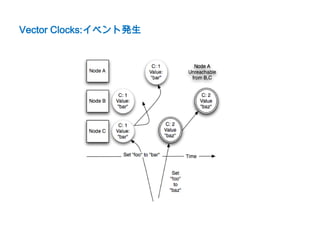
![Read Repair on Voldemort
• 読込時ノードに存在しないデータ又は
古いバージョンのデータを最新のデータに更新する
• stores.xmlのreplication-factorとpreferred-readsが2以上
に設定することで有効になる
• replication-factor = 3
preferred-reads = 2
データは1ノードのみ存在する場合、
Read Repairで2ノードにデータが存在するようになる
• データのバージョンが比較が出来ない場合
バージョンをすべてクライアントに返す
この場合アプリケーションでハンドルする必要がある
例) [A:10, B:1][A:10, C:1]](https://image.slidesharecdn.com/dynamovoldemort-121221031521-phpapp02/85/voldemort-Dynamo-18-320.jpg)

![Sloppy Quorum
• Quorumとは?
– 議決に必要な定足数
– W + R > N, W > N/2の場合、複製(レプリカ)の整合性が保証できる
• W : ノードへ書き込む数、R:ノードから読み出す数、N:レプリカの数
– Strict Quorum
– サーバ障害又はネットワーク障害で可用性が落ちる
• Sloppy Quorumとは?
– N=3, W=2, R=2
– C, Dノードが障害
– 生存しているノードからreference listを作成
[B,E,F]
– Strict Quorumでは失敗になるが
Key KはB, E, Fへ格納されて書き込みは成功
高可用性保証](https://image.slidesharecdn.com/dynamovoldemort-121221031521-phpapp02/85/voldemort-Dynamo-20-320.jpg)
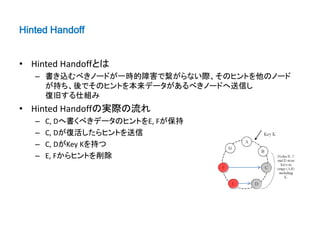
![Sloppy Quorum and Hinted Handoff on Voldemort
• Sloppy Quorumはない
– C, Dへ繋がらなくても本来書き込むノードでreference listを生成
[B, C, D]
– 書込みはB, C, Dノードに対して行う
– 書込み失敗のエラーを返す
• Hinted Handoff
– 書込み失敗時も実行される
– ノードへ書込みが失敗したらreference list以外の
ノードからランダムでヒントを送るノードを選ぶ
– 5分間隔で1回復旧を行う](https://image.slidesharecdn.com/dynamovoldemort-121221031521-phpapp02/85/voldemort-Dynamo-22-320.jpg)



























































![[LT] Continuous Delivery](https://cdn.slidesharecdn.com/ss_thumbnails/ltcontinuousdelivery-141103111558-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)






