Download to read offline

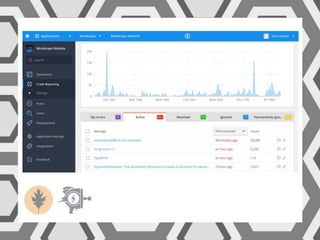
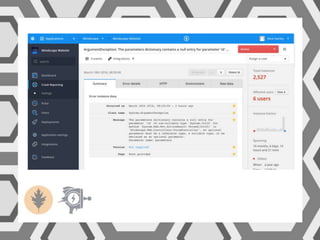
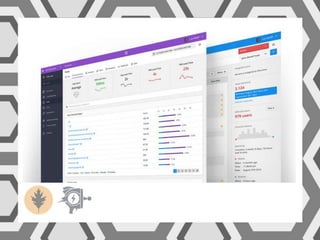
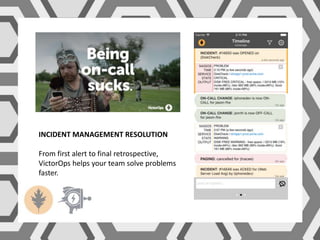
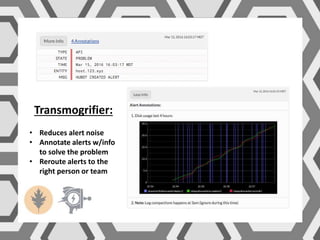

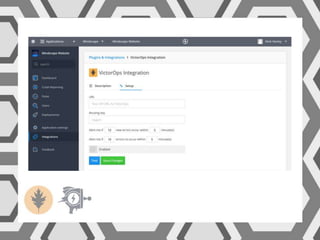
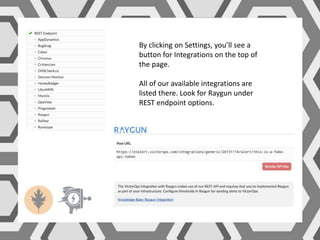
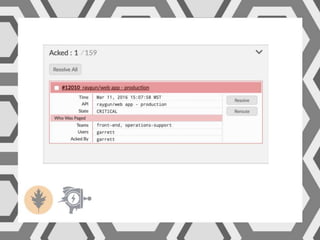
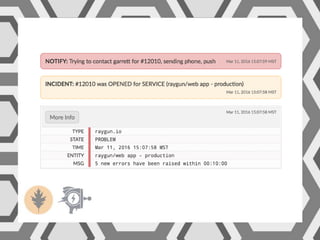
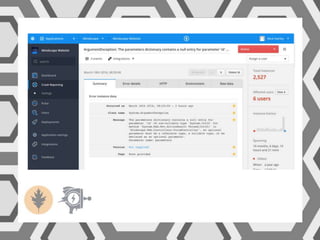


VictorOps assists teams in incident management by streamlining the resolution process from initial alert to final review, helping to resolve issues more quickly. Key features include reducing alert noise, annotating alerts with pertinent information, and routing alerts to appropriate personnel or teams. Users can access integrations such as Raygun through the settings menu on the platform.
































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)













