Download to read offline






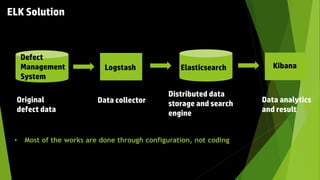

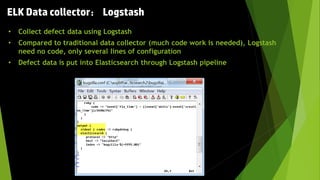

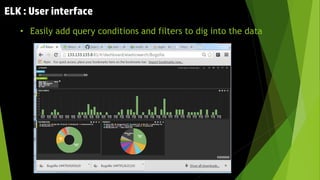
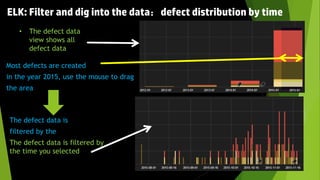
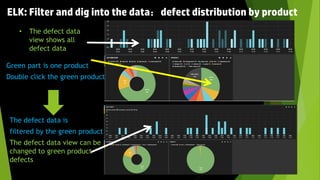
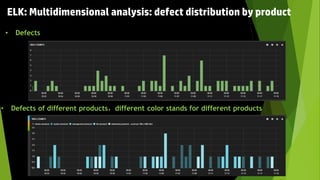




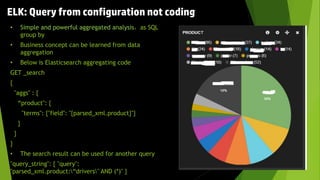





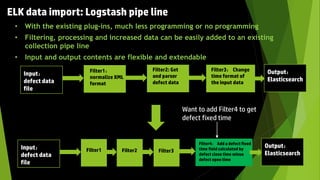

This document discusses using the ELK stack (Elasticsearch, Logstash, Kibana) to analyze defect data from a customer's defect management system. It defines key performance indicators (KPIs) for defects and describes how ELK provides an easy way to import defect data, calculate KPIs, and explore the data without coding. ELK allows analyzing large amounts of defect data through distributed storage and aggregation capabilities. It provides advantages over traditional analytics methods by enabling configuration-based data collection, querying, and visualization.