Download to read offline







![8
A data warehouse is a subject-oriented, integrated,
nonvolatile, time-variant collection of data in support of
management's decisions. [WH Inmon]
Subject Oriented
Data warehouses are designed to help to analyze the data.
Integrated
The data in the data warehouse is loaded from different
sources that store the data in different formats and focus on
different aspects of the subject.
IFETCE/CSE/III YEAR/VI SEM/IT6702/DWDM/PPT/UNIT-1/ VER 1.2](https://image.slidesharecdn.com/unit1dwdm-230728033548-c452f8d1/85/UNIT-1-DWDM-pdf-8-320.jpg)


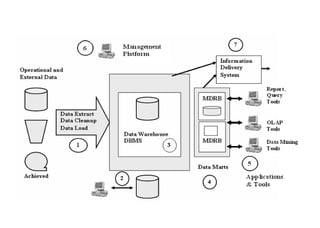


































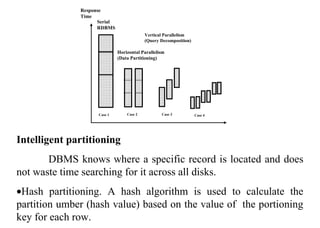



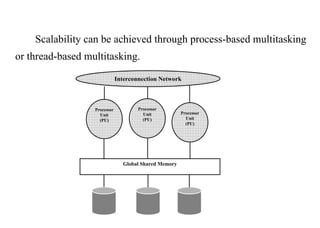


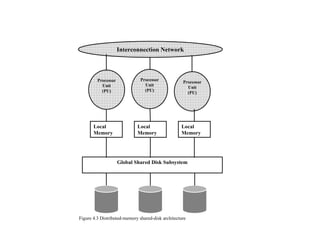
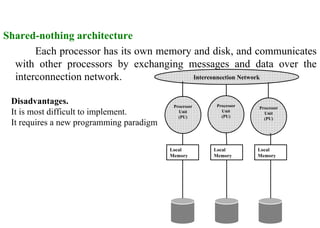



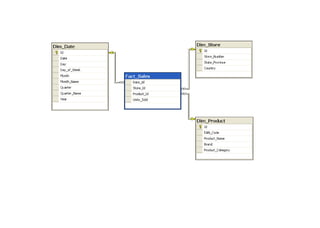











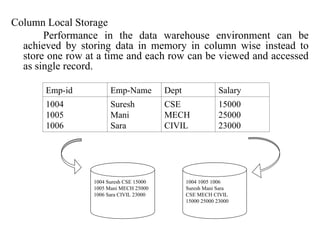
















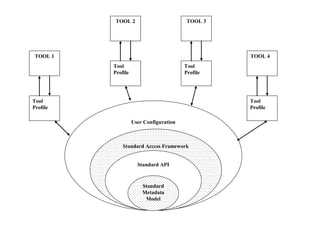




The document discusses components of data warehousing including data extraction, transformation, metadata, data warehouse databases, access tools, data marts, and administration. It describes building a data warehouse by considering business needs, organizational issues, and approaches like top-down or bottom-up. Key components are sourcing data from operational systems, cleaning and transforming it, loading it into a data warehouse database, and providing access tools for analysis and reporting. Metadata is also an important part of the data warehousing system.




















































































