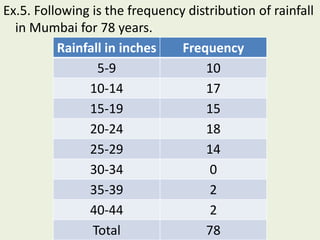
This document provides an introduction to statistics, including its definition, history, and scope. It discusses how statistics originated as a way to collect administrative data for governments and has evolved into a discipline. Key figures who contributed to the development of modern statistics and probability theory are mentioned. The document also defines key statistical concepts like population, sample, and different sampling methods. It outlines how statistics is applied in economics, management, and quality control in industry.