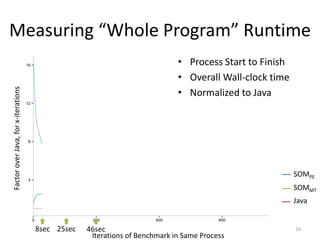
The document compares tracing and partial evaluation as meta-compilation approaches for self-optimizing interpreters, analyzing the performance of systems like Truffle+Graal and RPython+Meta-Tracing. It concludes that while peak performance seems similar for both approaches, tracing is generally faster and requires less optimization, offering better prototype performance. The measurement of startup performance indicates complexities, suggesting an unclear advantage between the two methods.



![Compare Concrete Systems
Truffle + Graal
with Partial Evaluation
RPython
with Meta-Tracing
[3] Würthinger et al., One VM to Rule Them All, Onward!
2013, ACM, pp. 187-204.
[2] Bolz et al., Tracing the Meta-level: PyPy's Tracing JIT
Compiler, ICOOOLPS Workshop 2009, ACM, pp. 18-25.
Oracle Labs](https://image.slidesharecdn.com/mt-vs-pe-151101181528-lva1-app6892/85/Tracing-versus-Partial-Evaluation-Which-Meta-Compilation-Approach-is-Better-for-Self-Optimizing-Interpreters-4-320.jpg)


![SOMMT versus SOMPE
Meta-Tracing Partial Evaluation
7
cnt
1
+
cnt:
=
if
cnt:
=
0
cnt
1
+
cnt:
=if cnt:
=
0
[3] Würthinger et al., One VM to Rule Them
All, Onward! 2013, ACM, pp. 187-204.
[2] Bolz et al., Tracing the Meta-level: PyPy's
Tracing JIT Compiler, ICOOOLPS Workshop
2009, ACM, pp. 18-25.](https://image.slidesharecdn.com/mt-vs-pe-151101181528-lva1-app6892/85/Tracing-versus-Partial-Evaluation-Which-Meta-Compilation-Approach-is-Better-for-Self-Optimizing-Interpreters-7-320.jpg)

![Peak Performance of Basic Interpreters
Runtime
Normalized
to Java 8
(lower is
better)
Compiled
SOM[MT]
Compiled
SOM[PE]
10
100
Bounce
BubbleSort
DeltaBlue
Fannkuch
GraphSearch
Json
Mandelbrot
NBody
PageRank
Permute
Queens
QuickSort
Richards
Sieve
Storage
Towers
Bounce
BubbleSort
DeltaBlue
Fannkuch
GraphSearch
Json
Mandelbrot
NBody
PageRank
Permute
Queens
QuickSort
Richards
Sieve
Storage
Towers
Runtimenormalizedto
Java(compiledorinterpreted)
SOMMT on RPython SOMPE on Truffle
Minimal SOMMT
5.5x slower
min. 1.6x
max. 14x
Minimal SOMPE
170x slower
min. 60x
max. 600x](https://image.slidesharecdn.com/mt-vs-pe-151101181528-lva1-app6892/85/Tracing-versus-Partial-Evaluation-Which-Meta-Compilation-Approach-is-Better-for-Self-Optimizing-Interpreters-9-320.jpg)


![Peak Performance of Optimized Interpreter
Compiled
SOM[MT]
Compiled
SOM[PE]
1
4
8
12
Bounce
BubbleSort
DeltaBlue
Fannkuch
GraphSearch
Json
Mandelbrot
NBody
PageRank
Permute
Queens
QuickSort
Richards
Sieve
Storage
Towers
Bounce
BubbleSort
DeltaBlue
Fannkuch
GraphSearch
Json
Mandelbrot
NBody
PageRank
Permute
Queens
QuickSort
Richards
Sieve
Storage
Towers
Runtimenormalizedto
Java(compiledorinterpreted)
SOMMT on RPython SOMPE on Truffle
Runtime
Normalized
to Java 8
(lower is
better)
Optimized SOMMT
3x slower
min. 1.5x
max. 11x
OptimizedSOMPE
2.3x slower
min. 4%
max. 4.9x
2.4x
speedup
80x
speedup](https://image.slidesharecdn.com/mt-vs-pe-151101181528-lva1-app6892/85/Tracing-versus-Partial-Evaluation-Which-Meta-Compilation-Approach-is-Better-for-Self-Optimizing-Interpreters-12-320.jpg)
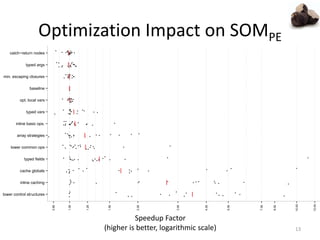




![Peak Performance of Optimized Interpreter
Compiled
SOM[MT]
Compiled
SOM[PE]
1
4
8
12
Bounce
BubbleSort
DeltaBlue
Fannkuch
GraphSearch
Json
Mandelbrot
NBody
PageRank
Permute
Queens
QuickSort
Richards
Sieve
Storage
Towers
Bounce
BubbleSort
DeltaBlue
Fannkuch
GraphSearch
Json
Mandelbrot
NBody
PageRank
Permute
Queens
QuickSort
Richards
Sieve
Storage
Towers
Runtimenormalizedto
Java(compiledorinterpreted)
SOMMT on RPython SOMPE on Truffle
Runtime
Normalized
to Java 8
(lower is
better)
Optimized SOMMT
3x slower
min. 1.5x
max. 11x
OptimizedSOMPE
2.3x slower
min. 4%
max. 4.9x](https://image.slidesharecdn.com/mt-vs-pe-151101181528-lva1-app6892/85/Tracing-versus-Partial-Evaluation-Which-Meta-Compilation-Approach-is-Better-for-Self-Optimizing-Interpreters-19-320.jpg)






















































































