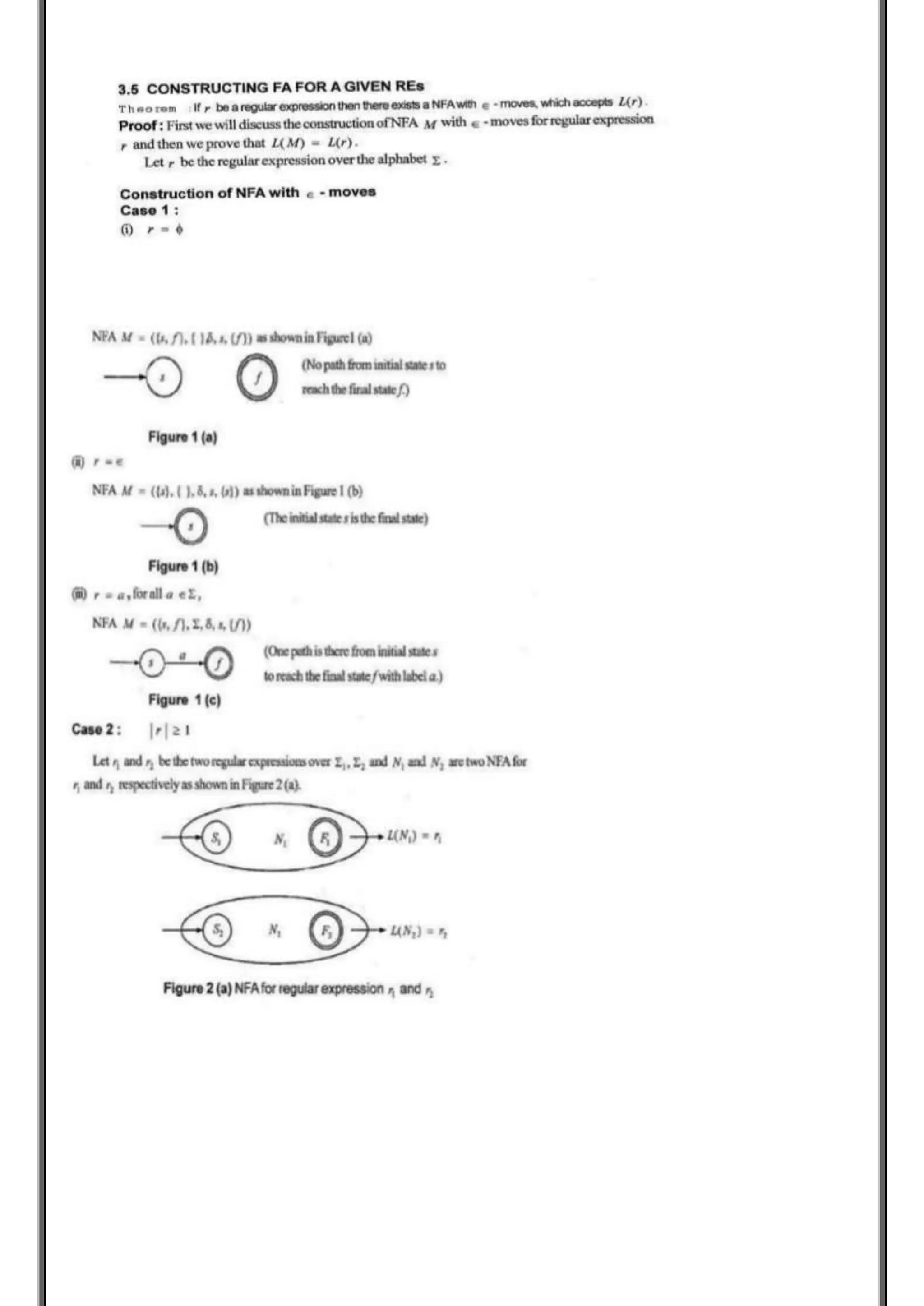
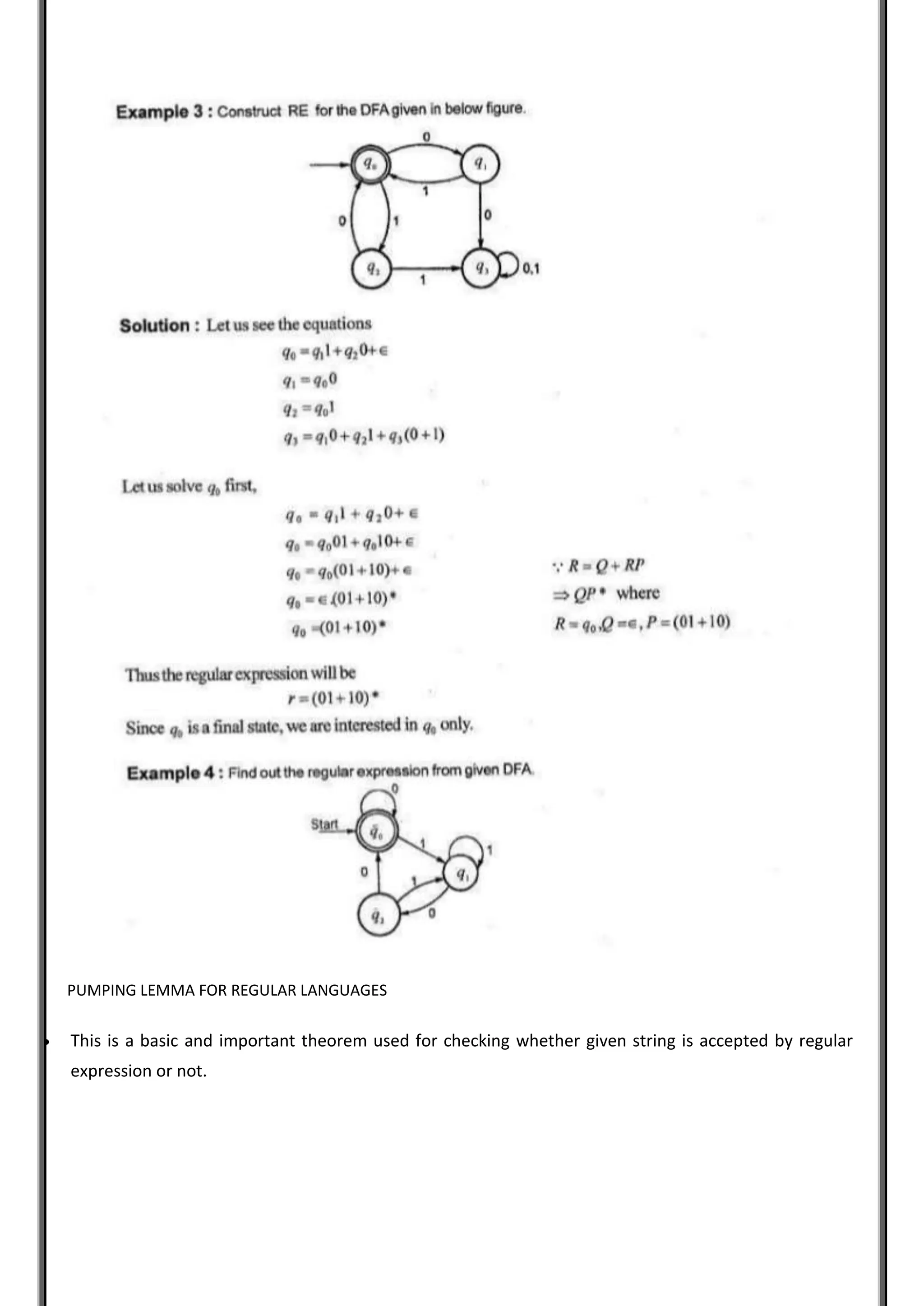
The document covers the Theory of Computation, focusing on regular expressions (RE), their operators, and properties of regular languages. It explains the construction of RE from primitive constituents, the language associated with them, and the precedence rules for operators. Additionally, it discusses the application of RE in text search and manipulation, highlighting the importance of the pumping lemma for assessing language acceptance.