Download as PDF, PPTX







![Test Set
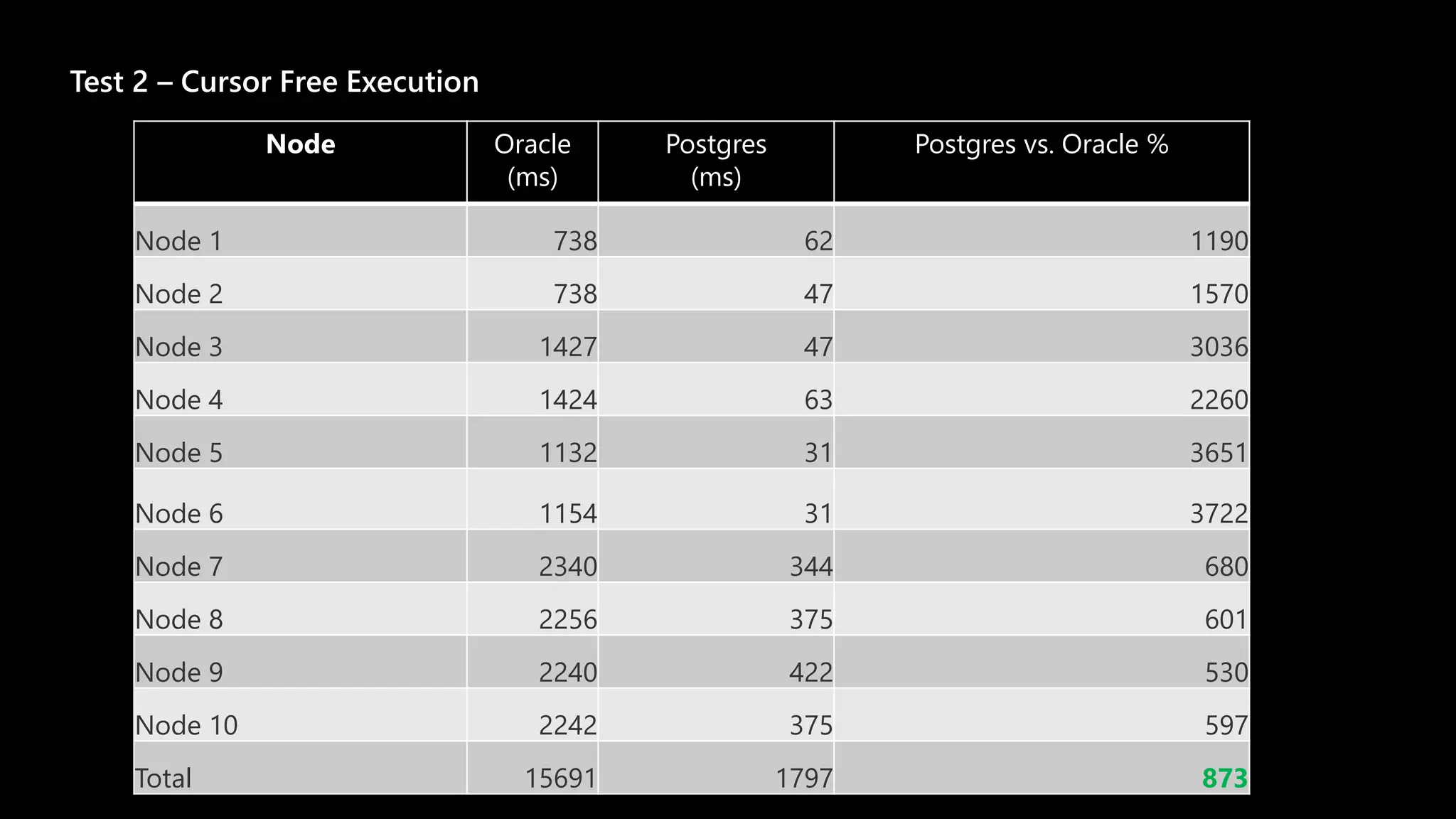
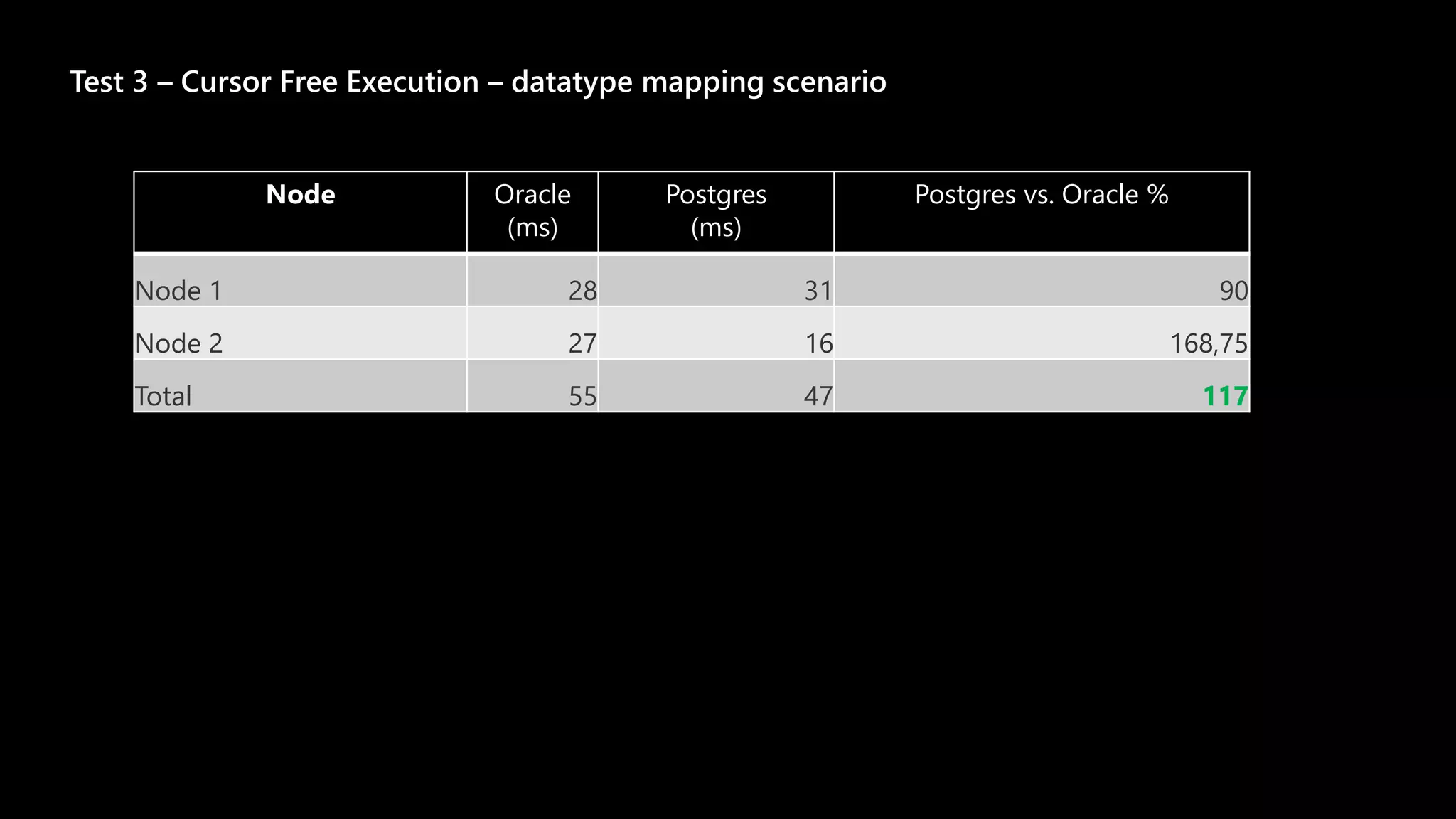
Test 1
Node 1
duration
Node 2
duration
[...]](https://image.slidesharecdn.com/zymjakxts264t3jmp3bo-signature-2300fb2c70f088a43140bf83c71ebf5e5ede6c1c1df4e82b0275bf08937e751e-poli-201222093552/75/The-Story-About-The-Migration-8-2048.jpg)




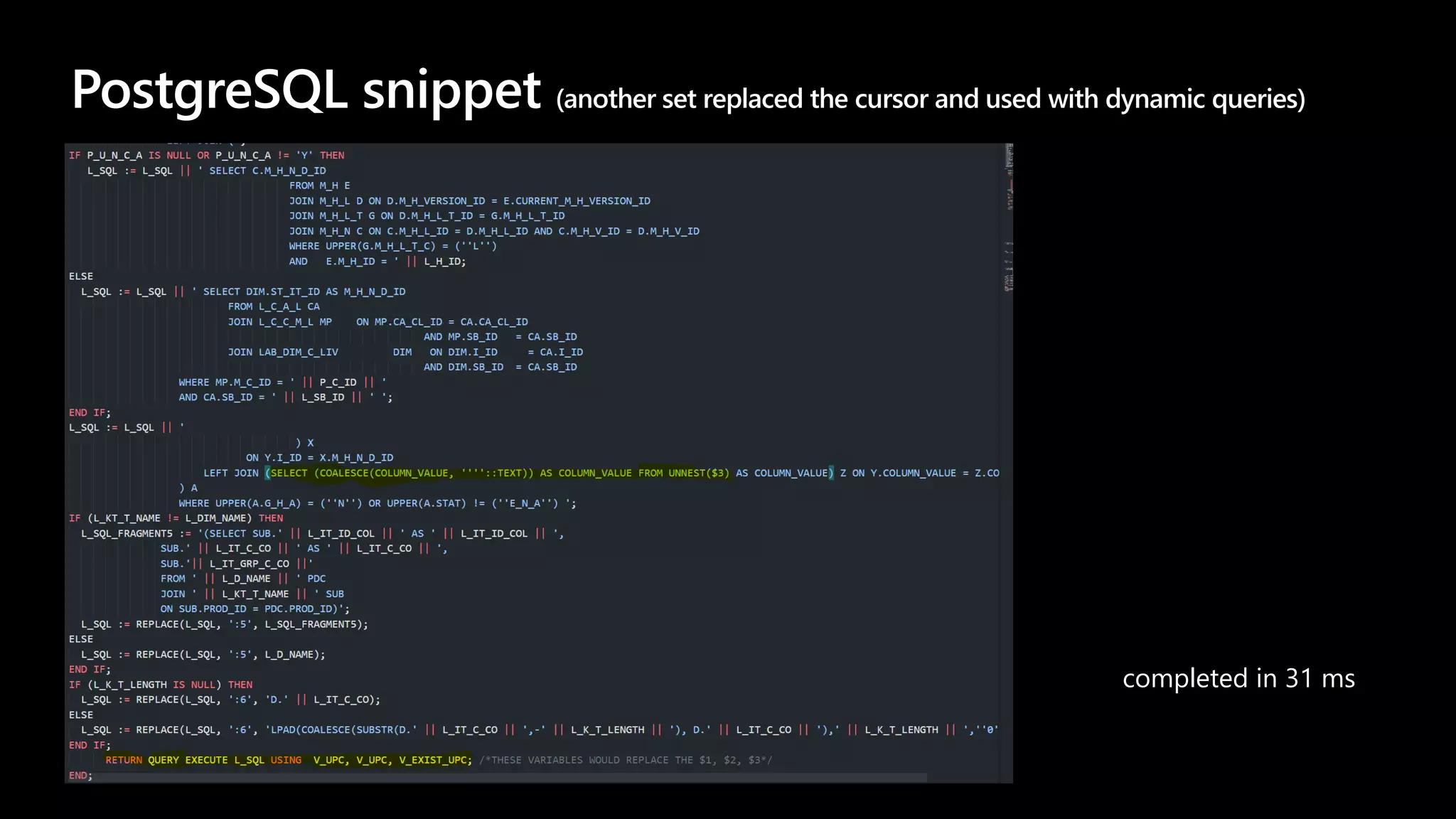
![Let’s get rid of WITH RECURSIVE
DO
$$
DECLARE
bar_ids_tab NUMERIC[];
bar_ids_string TEXT;
BEGIN
bar_ids_tab := '{111, 20, 3, 4, 5}';
SELECT string_agg(x::TEXT, ',')
INTO bar_ids_string
FROM (
SELECT unnest(bar_ids_tab) AS x
ORDER BY x) a;
RAISE NOTICE '%', bar_ids_string;
END;
$$
[00000] 3,4,5,20,111
completed in 3 ms](https://image.slidesharecdn.com/zymjakxts264t3jmp3bo-signature-2300fb2c70f088a43140bf83c71ebf5e5ede6c1c1df4e82b0275bf08937e751e-poli-201222093552/75/The-Story-About-The-Migration-17-2048.jpg)
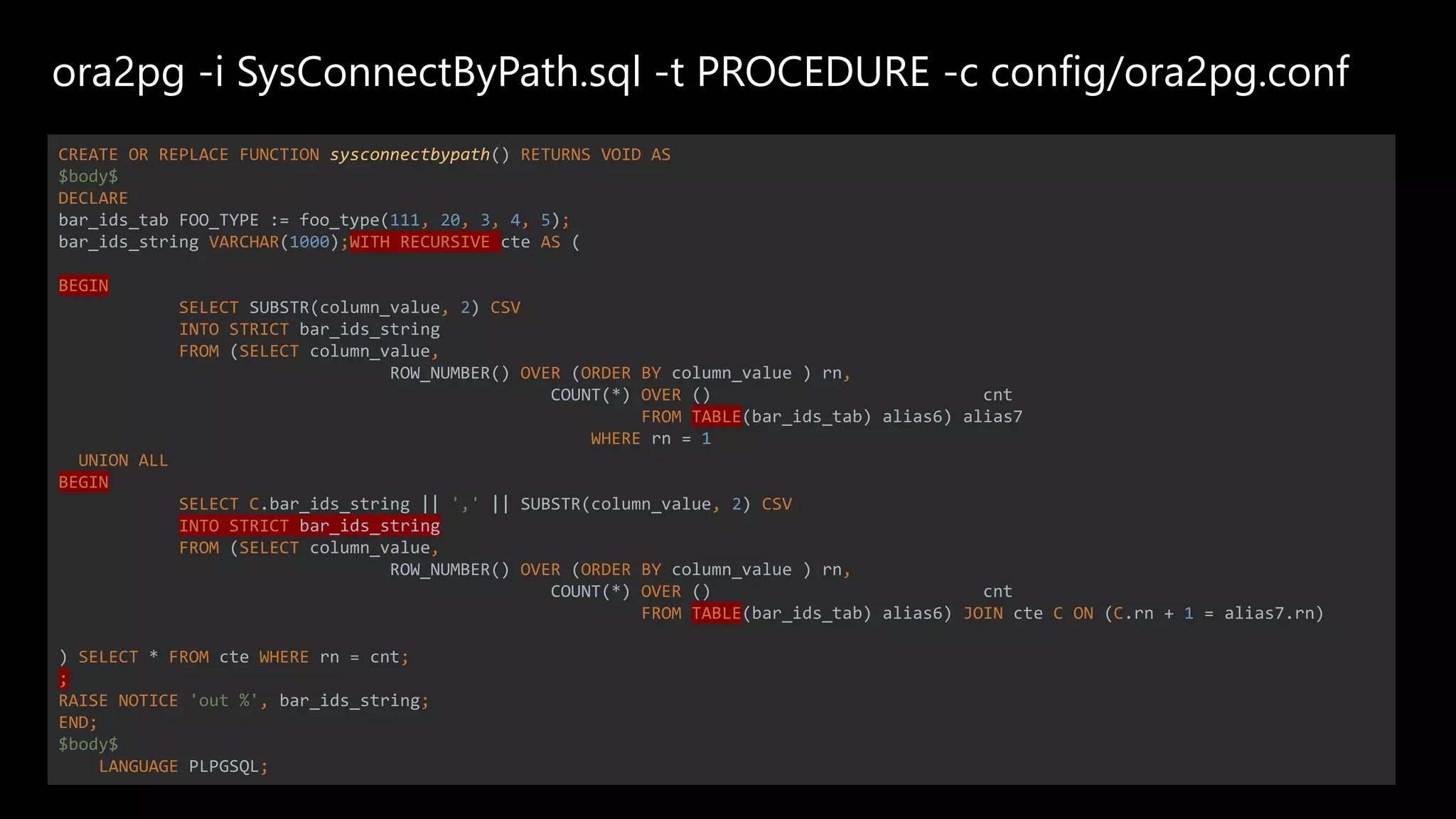
![Postgres WINS!
DO
$$
DECLARE
bar_ids_tab NUMERIC[];
bar_ids_string TEXT;
BEGIN
bar_ids_tab := '{111, 20, 3, 4, 5}';
SELECT string_agg(x::TEXT, ',')
INTO bar_ids_string
FROM (
SELECT unnest(bar_ids_tab) AS x
ORDER BY x) a;
RAISE NOTICE '%', bar_ids_string;
END;
$$
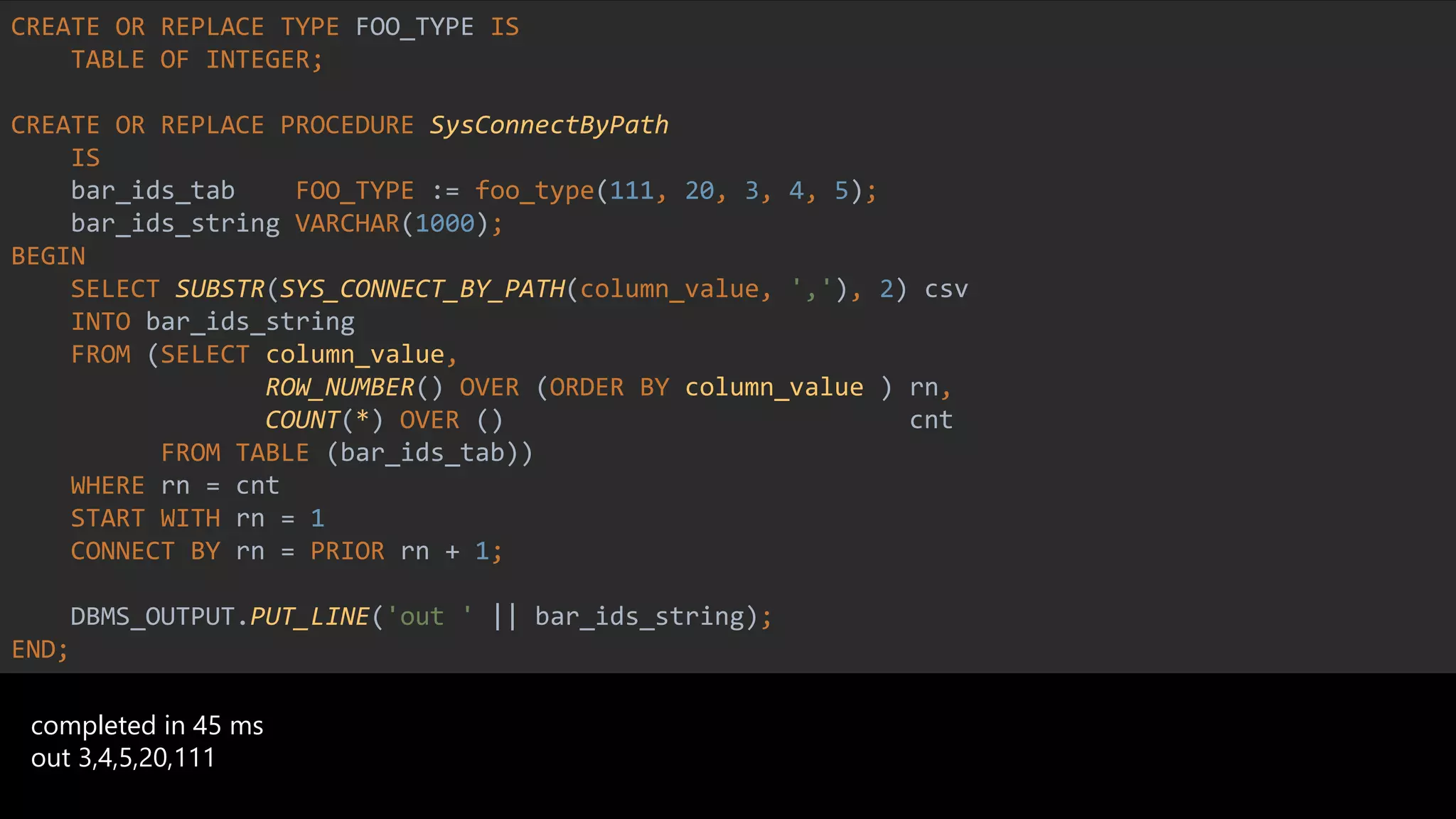
CREATE OR REPLACE TYPE FOO_TYPE IS
TABLE OF INTEGER;
CREATE OR REPLACE PROCEDURE SysConnectByPath
IS
bar_ids_tab FOO_TYPE := foo_type(111, 20, 3, 4, 5);
bar_ids_string VARCHAR(1000);
BEGIN
SELECT SUBSTR(SYS_CONNECT_BY_PATH(column_value, ','), 2) csv
INTO bar_ids_string
FROM (SELECT column_value,
ROW_NUMBER() OVER (ORDER BY column_value ) rn,
COUNT(*) OVER () cnt
FROM TABLE (bar_ids_tab))
WHERE rn = cnt
START WITH rn = 1
CONNECT BY rn = PRIOR rn + 1;
DBMS_OUTPUT.PUT_LINE('out ' || bar_ids_string);
END;
[00000] 3,4,5,20,111
completed in 3 ms
out 3,4,5,20,111
completed in 45 ms](https://image.slidesharecdn.com/zymjakxts264t3jmp3bo-signature-2300fb2c70f088a43140bf83c71ebf5e5ede6c1c1df4e82b0275bf08937e751e-poli-201222093552/75/The-Story-About-The-Migration-18-2048.jpg)


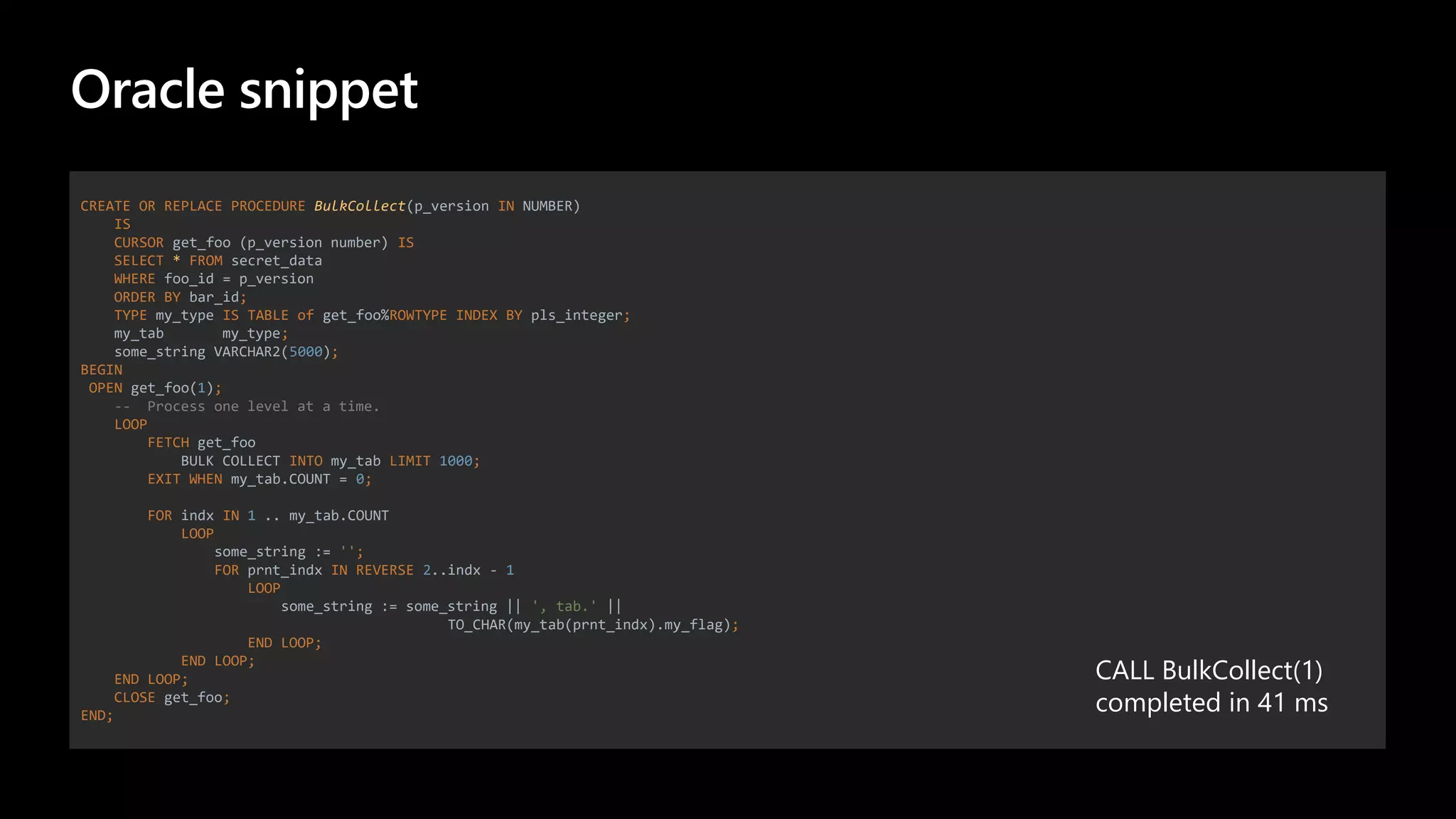
![ora2pg -i BulkCollect.sql -t PROCEDURE –c config/ora2pg.conf
CREATE OR REPLACE FUNCTION bulkcollect(p_version BIGINT) RETURNS VOID AS
$body$
DECLARE
get_foo CURSOR (p_version BIGINT) FOR
SELECT *
FROM secret_data
WHERE foo_id = p_version
ORDER BY bar_id;
TYPE MY_TYPE IS TABLE OF RECORD INDEX BY INTEGER;
my_tab MY_TYPE;
some_string VARCHAR(5000);
BEGIN
OPEN get_foo(1);
-- Process one level at a time.
LOOP
FETCH get_foo BULK COLLECT INTO my_tab LIMIT 1000;
EXIT WHEN my_tab.COUNT = 0;
FOR indx IN 1 .. my_tab.COUNT
LOOP
some_string := '';
FOR prnt_indx IN REVERSE indx..2 - 1
LOOP
some_string := some_string || ', tab.' ||
my_tab[prnt_indx].my_flag::VARCHAR;
END LOOP;
END LOOP;
END LOOP;
CLOSE get_foo;
END;
$body$
LANGUAGE PLPGSQL
;](https://image.slidesharecdn.com/zymjakxts264t3jmp3bo-signature-2300fb2c70f088a43140bf83c71ebf5e5ede6c1c1df4e82b0275bf08937e751e-poli-201222093552/75/The-Story-About-The-Migration-22-2048.jpg)
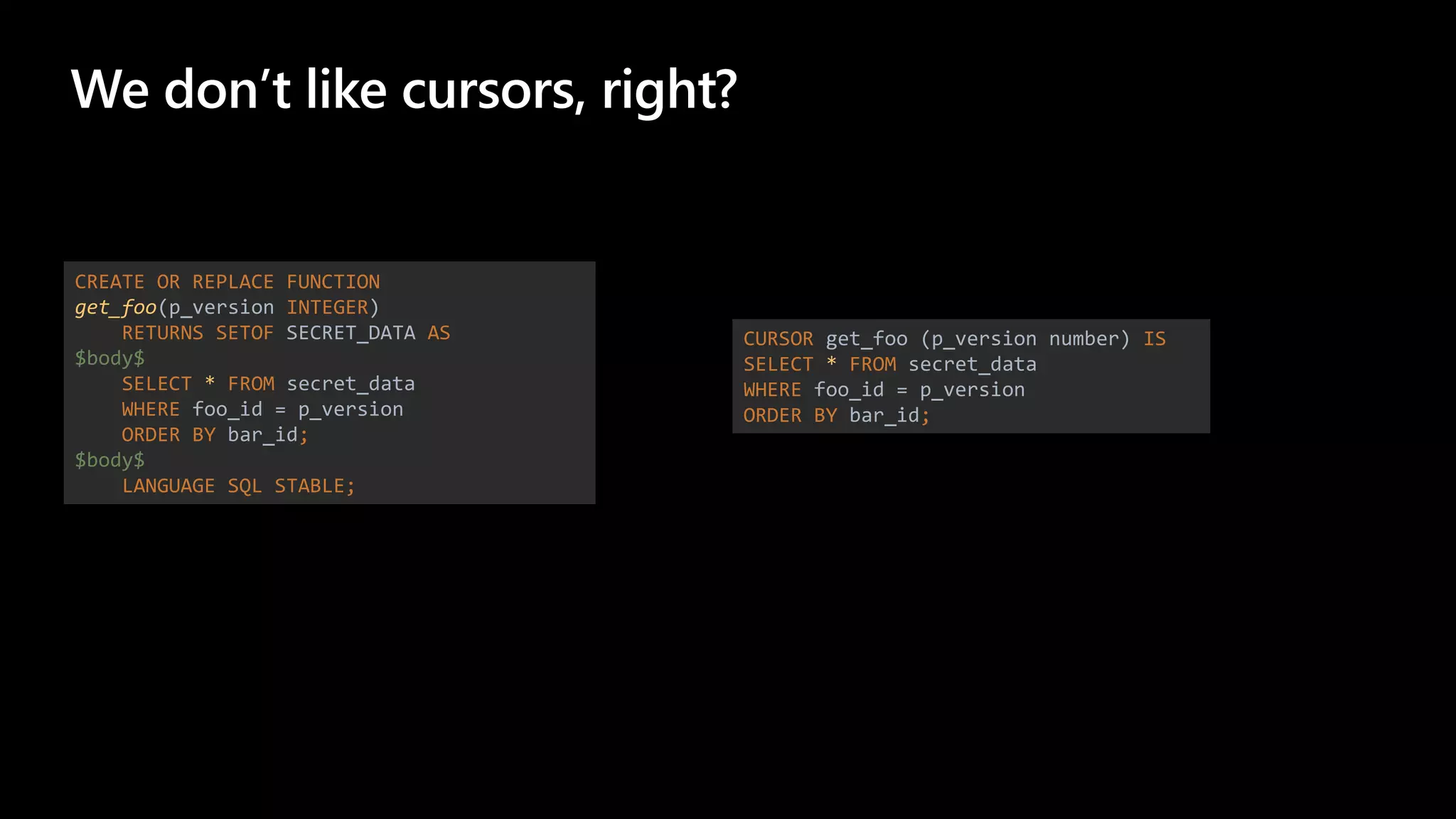
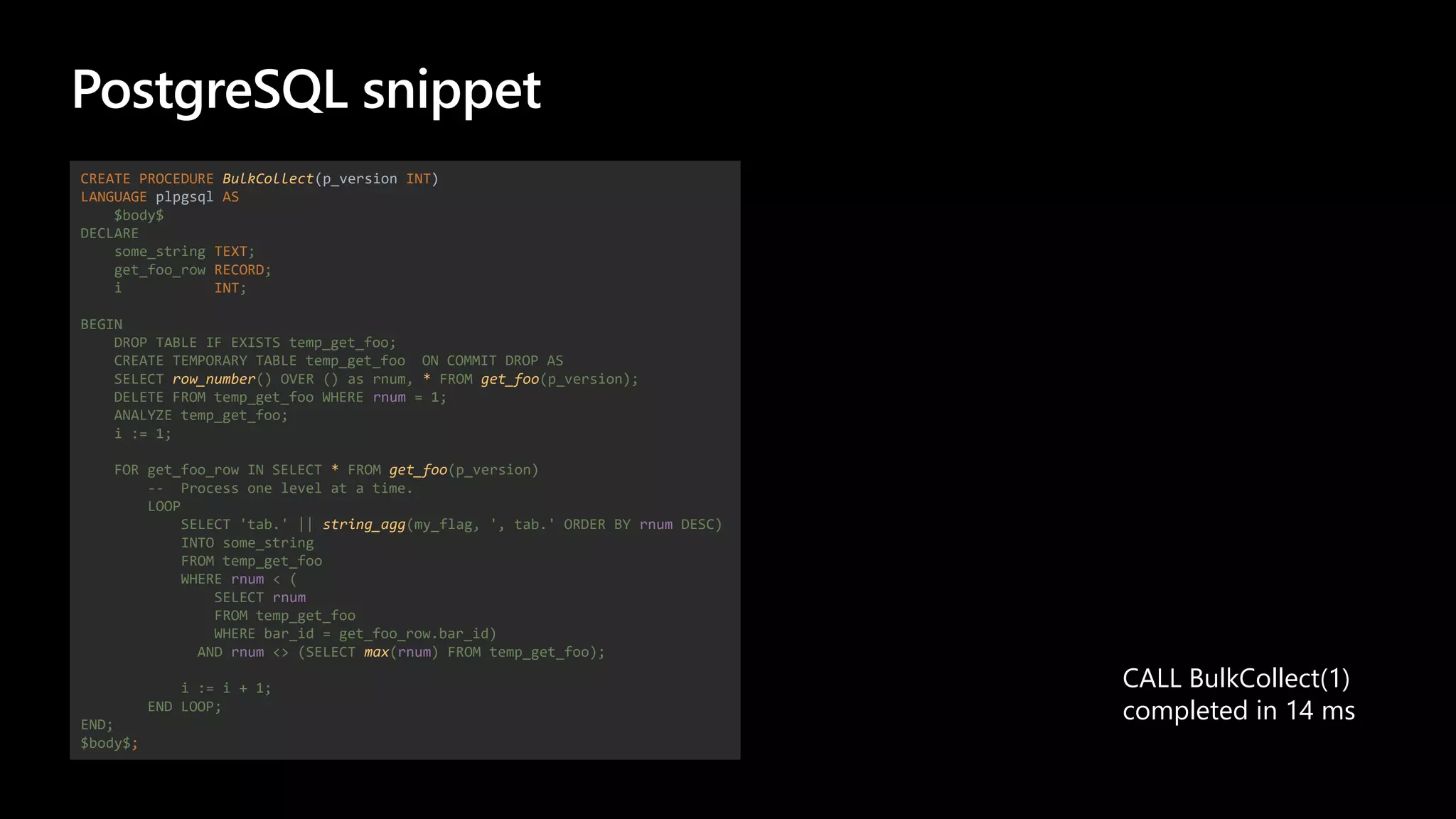
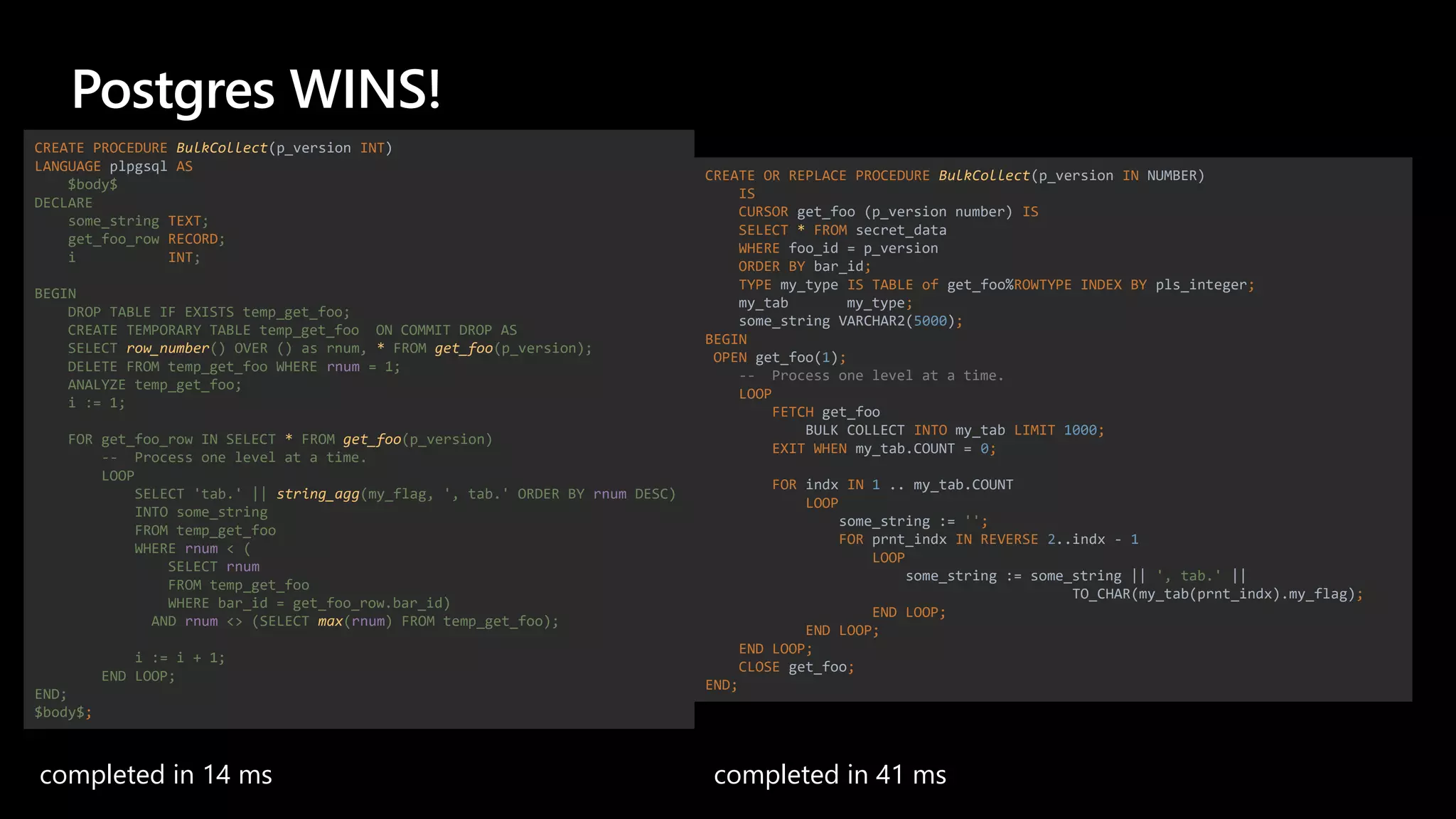
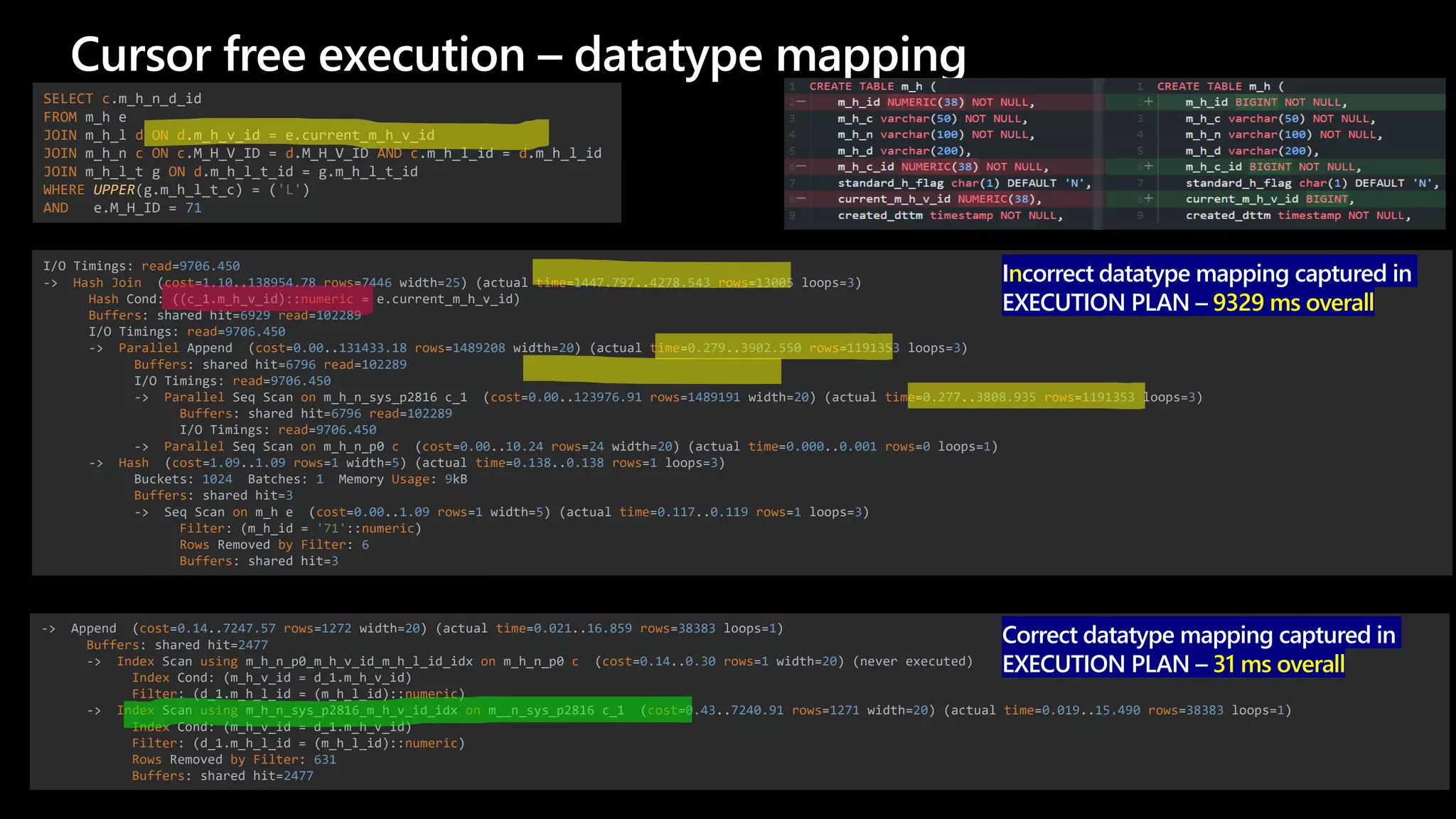







The document details a migration project involving Oracle Exadata to Azure Database for PostgreSQL, focusing on performance comparisons between the two databases during schema and data migrations. It includes implementation insights, code migration strategies, and performance evaluation through various tests, showcasing PostgreSQL's efficiency in different scenarios. Additionally, it offers references to Azure Postgres resources and migration guides, emphasizing performance optimization techniques.



































































![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)


![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)




![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)








![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)

