Downloaded 23 times









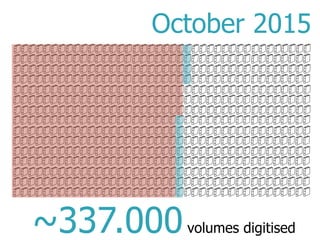







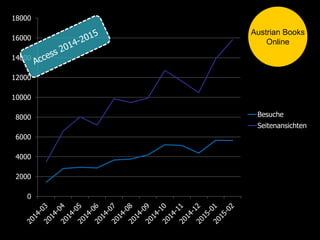


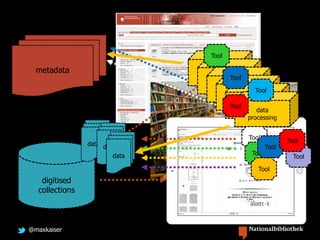
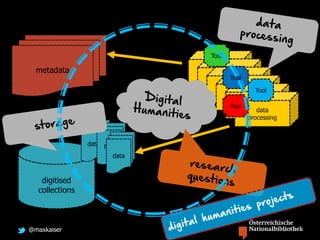
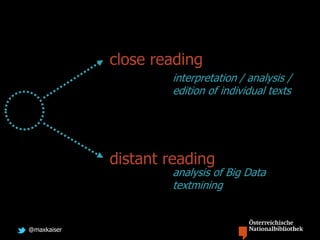





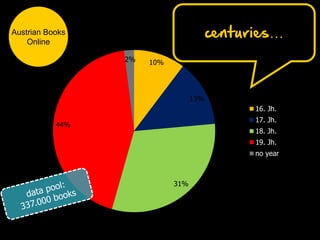
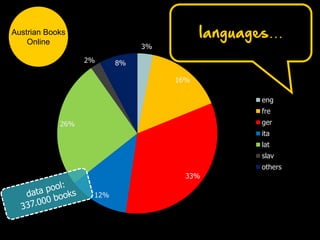
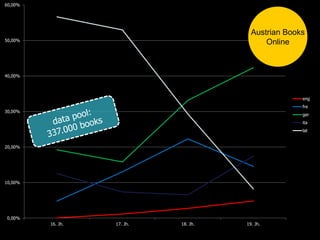




























Max Kaiser discusses the challenges and advancements in text and data mining within cultural heritage contexts, specifically at the Austrian National Library. The document outlines the extensive digitization efforts, including the collaboration with Google, and the potential of OCR and text mining technologies to enhance accessibility to historical texts. It highlights the complexities involved in integrating these technologies into existing library systems and the need for further research and development to effectively utilize text mining in production environments.














































































