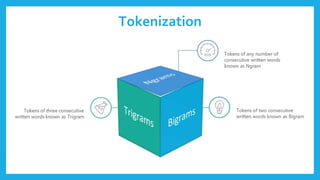
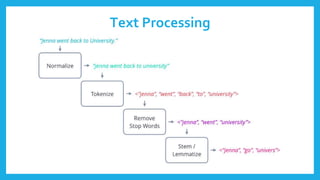
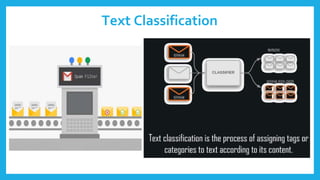
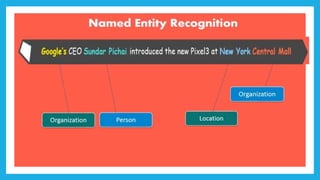
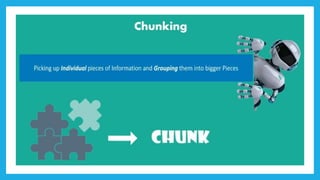
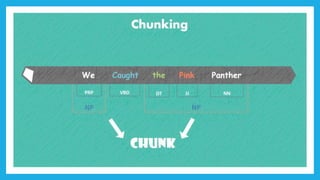
The document discusses natural language processing (NLP) and its applications in text analytics, highlighting the importance of processing human languages through methods like tokenization, stopword removal, stemming, and lemmatization. It introduces the Natural Language Toolkit (NLTK) as a tool for performing these tasks and explains key processes such as data cleaning, text classification, and named entity recognition. Overall, it emphasizes the significance of extracting meaningful information from text data.