Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Satoshi Noda
PDF, PPTX
4,265 views
TensorFlowを触ってみたよ!
2015/12/26 GDG神戸 TensorFlow勉強会 LT
Technology
◦
Read more
4
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 40
2
/ 40
3
/ 40
4
/ 40
5
/ 40
6
/ 40
7
/ 40
8
/ 40
9
/ 40
10
/ 40
11
/ 40
12
/ 40
13
/ 40
14
/ 40
15
/ 40
16
/ 40
17
/ 40
18
/ 40
19
/ 40
20
/ 40
21
/ 40
22
/ 40
23
/ 40
24
/ 40
25
/ 40
26
/ 40
27
/ 40
28
/ 40
29
/ 40
30
/ 40
31
/ 40
32
/ 40
33
/ 40
34
/ 40
35
/ 40
36
/ 40
37
/ 40
38
/ 40
39
/ 40
40
/ 40
More Related Content
PDF
Unity入門勉強会(PG向け)
by
Satoshi Noda
PDF
Cardboard勉強会
by
Satoshi Noda
PDF
ちょっとだけさわってみる Go言語
by
Satoshi Noda
PDF
Google VRと開発ノウハウ
by
Satoshi Noda
PDF
DaydreamではじめるVR
by
Satoshi Noda
PDF
Android6.0の機能まとめ 実機でサンプルを動かしてみた
by
Satoshi Noda
PDF
モバイルVR「Daydream」でVRの世界にふれてみる
by
Satoshi Noda
PDF
Google VR - Google I/O Extended 報告会 2016 in 関西 -
by
Satoshi Noda
Unity入門勉強会(PG向け)
by
Satoshi Noda
Cardboard勉強会
by
Satoshi Noda
ちょっとだけさわってみる Go言語
by
Satoshi Noda
Google VRと開発ノウハウ
by
Satoshi Noda
DaydreamではじめるVR
by
Satoshi Noda
Android6.0の機能まとめ 実機でサンプルを動かしてみた
by
Satoshi Noda
モバイルVR「Daydream」でVRの世界にふれてみる
by
Satoshi Noda
Google VR - Google I/O Extended 報告会 2016 in 関西 -
by
Satoshi Noda
What's hot
PDF
モバイルVR「Daydream」について
by
Satoshi Noda
PDF
ちょっとさわってみるGo言語ハンズオン
by
Satoshi Noda
PDF
Namespace API を用いたマルチテナント型 Web アプリの実践
by
Takuya Ueda
PDF
NGK2018B マルチプラットフォームQtと日本Qtユーザー会の紹介
by
Kazuo Asano (@kazuo_asa)
PDF
Golangによるubicの試作
by
kn1kn1
PDF
粗探しをしてGoのコントリビューターになる方法
by
Takuya Ueda
PDF
Androidアプリ開発で活躍必至!? ビルドツールGradle
by
amayaw9
PDF
Androidnight contribute droidkaigi
by
Shinjiro Watanabe
PDF
静的解析とUIの自動生成を駆使してモバイルアプリの運用コストを大幅に下げた話
by
Takuya Ueda
PDF
Gradle task with kotlin
by
史也 久米
PDF
Cloud functionsの紹介
by
Takuya Ueda
PDF
Visual studio2013からGithubへPushする方法
by
Takuya Kawabe
PDF
Cloud Functionsの紹介
by
Takuya Ueda
PDF
Go Friday 傑作選
by
Takuya Ueda
PDF
kosenconf をきっかけに新しい縁を
by
shiget84
PDF
GoによるiOSアプリの開発
by
Takuya Ueda
PDF
Maker Faire Bay Areaに行きたかったのでGoogle I/Oに行ってきた
by
Takao Sumitomo
PDF
Google IO 2012 つまみ食い(1) ADT r20 の新機能
by
Takuya Fujimura
PDF
goパッケージで型情報を用いたソースコード検索を実現する
by
Takuya Ueda
PPTX
1月からAndroidアプリ開発をやってみての近況
by
takathemax
モバイルVR「Daydream」について
by
Satoshi Noda
ちょっとさわってみるGo言語ハンズオン
by
Satoshi Noda
Namespace API を用いたマルチテナント型 Web アプリの実践
by
Takuya Ueda
NGK2018B マルチプラットフォームQtと日本Qtユーザー会の紹介
by
Kazuo Asano (@kazuo_asa)
Golangによるubicの試作
by
kn1kn1
粗探しをしてGoのコントリビューターになる方法
by
Takuya Ueda
Androidアプリ開発で活躍必至!? ビルドツールGradle
by
amayaw9
Androidnight contribute droidkaigi
by
Shinjiro Watanabe
静的解析とUIの自動生成を駆使してモバイルアプリの運用コストを大幅に下げた話
by
Takuya Ueda
Gradle task with kotlin
by
史也 久米
Cloud functionsの紹介
by
Takuya Ueda
Visual studio2013からGithubへPushする方法
by
Takuya Kawabe
Cloud Functionsの紹介
by
Takuya Ueda
Go Friday 傑作選
by
Takuya Ueda
kosenconf をきっかけに新しい縁を
by
shiget84
GoによるiOSアプリの開発
by
Takuya Ueda
Maker Faire Bay Areaに行きたかったのでGoogle I/Oに行ってきた
by
Takao Sumitomo
Google IO 2012 つまみ食い(1) ADT r20 の新機能
by
Takuya Fujimura
goパッケージで型情報を用いたソースコード検索を実現する
by
Takuya Ueda
1月からAndroidアプリ開発をやってみての近況
by
takathemax
Viewers also liked
PDF
TensorFlow を使った 機械学習ことはじめ (GDG京都 機械学習勉強会)
by
徹 上野山
PPTX
Tensorflowのチュートリアルで理解するdeep learningはじめてハンズオン
by
健一 茂木
PPTX
Tensor flow勉強会3
by
tak9029
PDF
Tensor flow勉強会 (ayashiminagaranotensorflow)
by
tak9029
PPTX
MIRU2014 tutorial deeplearning
by
Takayoshi Yamashita
PDF
Google TensorFlow Tutorial
by
台灣資料科學年會
PDF
scikit-learnを用いた機械学習チュートリアル
by
敦志 金谷
PDF
Chainerチュートリアル -v1.5向け- ViEW2015
by
Ryosuke Okuta
PDF
機械学習概論 講義テキスト
by
Etsuji Nakai
PPTX
深層学習とTensorFlow入門
by
tak9029
PDF
Deep Learningと画像認識 ~歴史・理論・実践~
by
nlab_utokyo
PDF
Tokyo.R 41 サポートベクターマシンで眼鏡っ娘分類システム構築
by
Tatsuya Tojima
PPTX
Pythonとdeep learningで手書き文字認識
by
Ken Morishita
PDF
機械学習によるデータ分析まわりのお話
by
Ryota Kamoshida
PDF
機械学習チュートリアル@Jubatus Casual Talks
by
Yuya Unno
TensorFlow を使った 機械学習ことはじめ (GDG京都 機械学習勉強会)
by
徹 上野山
Tensorflowのチュートリアルで理解するdeep learningはじめてハンズオン
by
健一 茂木
Tensor flow勉強会3
by
tak9029
Tensor flow勉強会 (ayashiminagaranotensorflow)
by
tak9029
MIRU2014 tutorial deeplearning
by
Takayoshi Yamashita
Google TensorFlow Tutorial
by
台灣資料科學年會
scikit-learnを用いた機械学習チュートリアル
by
敦志 金谷
Chainerチュートリアル -v1.5向け- ViEW2015
by
Ryosuke Okuta
機械学習概論 講義テキスト
by
Etsuji Nakai
深層学習とTensorFlow入門
by
tak9029
Deep Learningと画像認識 ~歴史・理論・実践~
by
nlab_utokyo
Tokyo.R 41 サポートベクターマシンで眼鏡っ娘分類システム構築
by
Tatsuya Tojima
Pythonとdeep learningで手書き文字認識
by
Ken Morishita
機械学習によるデータ分析まわりのお話
by
Ryota Kamoshida
機械学習チュートリアル@Jubatus Casual Talks
by
Yuya Unno
Similar to TensorFlowを触ってみたよ!
PPTX
TensorFlowの導入
by
yuf yufkky
PPTX
TensorFlowの導入
by
yuf yufkky
PDF
TensorFlowで遊んでみよう!
by
Kei Hirata
PPTX
Webエンジニアが初めて機械学習に触れてみた話
by
Shohei Tai
PDF
TensorFlow計算グラフ最適化処理
by
Atsushi Nukariya
PPTX
Google TensorFlowで遊んでみた①
by
Tetsuya Hasegawa
PDF
Tensorflow
by
Hakky St
PDF
TFUG_yuma_matsuoka__distributed_GPU
by
YumaMatsuoka
PDF
機械学習ライブラリ : TensorFlow
by
エンジニア勉強会 エスキュービズム
PPTX
Androidで動かすはじめてのDeepLearning
by
Miyoshi Kosuke
PPTX
HTML5 Conference LT TensorFlow
by
isaac-otao
PPTX
Tensor コアを使った PyTorch の高速化
by
Yusuke Fujimoto
PDF
TensorFlow 3分紹介 with 速攻 windows 環境構築
by
Michiko Arai
PDF
TensorFlowの使い方(in Japanese)
by
Toshihiko Yamakami
PDF
TensorFlow White Paperを読む
by
Yuta Kashino
PPTX
TensorFlowをもう少し詳しく入門
by
tak9029
PDF
Playgroundでディープラーニングを勉強しよう
by
Hiroyuki Yoshida
PDF
LIFULL HOME'S「かざして検索」リリースの裏側
by
Takuro Hanawa
PDF
20170421 tensor flowusergroup
by
ManaMurakami1
PDF
第3回機械学習勉強会「色々なNNフレームワークを動かしてみよう」-Keras編-
by
Yasuyuki Sugai
TensorFlowの導入
by
yuf yufkky
TensorFlowの導入
by
yuf yufkky
TensorFlowで遊んでみよう!
by
Kei Hirata
Webエンジニアが初めて機械学習に触れてみた話
by
Shohei Tai
TensorFlow計算グラフ最適化処理
by
Atsushi Nukariya
Google TensorFlowで遊んでみた①
by
Tetsuya Hasegawa
Tensorflow
by
Hakky St
TFUG_yuma_matsuoka__distributed_GPU
by
YumaMatsuoka
機械学習ライブラリ : TensorFlow
by
エンジニア勉強会 エスキュービズム
Androidで動かすはじめてのDeepLearning
by
Miyoshi Kosuke
HTML5 Conference LT TensorFlow
by
isaac-otao
Tensor コアを使った PyTorch の高速化
by
Yusuke Fujimoto
TensorFlow 3分紹介 with 速攻 windows 環境構築
by
Michiko Arai
TensorFlowの使い方(in Japanese)
by
Toshihiko Yamakami
TensorFlow White Paperを読む
by
Yuta Kashino
TensorFlowをもう少し詳しく入門
by
tak9029
Playgroundでディープラーニングを勉強しよう
by
Hiroyuki Yoshida
LIFULL HOME'S「かざして検索」リリースの裏側
by
Takuro Hanawa
20170421 tensor flowusergroup
by
ManaMurakami1
第3回機械学習勉強会「色々なNNフレームワークを動かしてみよう」-Keras編-
by
Yasuyuki Sugai
More from Satoshi Noda
PDF
Flutterとプラットフォーム依存の処理の対応について
by
Satoshi Noda
PDF
VRをはじめよう!
by
Satoshi Noda
PDF
Google I/O Extended 報告会 2016 in 関西 LT
by
Satoshi Noda
PDF
Oculus Game Jam 2015 presentation
by
Satoshi Noda
PDF
ぶっちゃけ Android wear ってどうよ?
by
Satoshi Noda
PDF
2015/02/21 GDG神戸 Go on Android ハンズオン&もくもく会
by
Satoshi Noda
PDF
dockerはじめました。 GDG京都 2014年忘れ勉強会 LT
by
Satoshi Noda
PDF
GDG DevFest Kyoto 2014 これからのGoの話をしよう
by
Satoshi Noda
PDF
2014/09/13 Android Wear Hackahon
by
Satoshi Noda
PDF
Android Wear のムダ知識
by
Satoshi Noda
PDF
2013/03/09 VisualStudio勉強会 LT 「統合開発環境の支援ツール」
by
Satoshi Noda
Flutterとプラットフォーム依存の処理の対応について
by
Satoshi Noda
VRをはじめよう!
by
Satoshi Noda
Google I/O Extended 報告会 2016 in 関西 LT
by
Satoshi Noda
Oculus Game Jam 2015 presentation
by
Satoshi Noda
ぶっちゃけ Android wear ってどうよ?
by
Satoshi Noda
2015/02/21 GDG神戸 Go on Android ハンズオン&もくもく会
by
Satoshi Noda
dockerはじめました。 GDG京都 2014年忘れ勉強会 LT
by
Satoshi Noda
GDG DevFest Kyoto 2014 これからのGoの話をしよう
by
Satoshi Noda
2014/09/13 Android Wear Hackahon
by
Satoshi Noda
Android Wear のムダ知識
by
Satoshi Noda
2013/03/09 VisualStudio勉強会 LT 「統合開発環境の支援ツール」
by
Satoshi Noda
TensorFlowを触ってみたよ!
1.
TensorFlowを 触ってみたよ! 2015/12/26 TensorFlow勉強会LT GDG神戸 野田悟志
2.
GDG神戸 2015年開催イベント 2015/2/21 Go
on Android ハンズオン&もくもく会 2015/4/29 Angular勉強会#3 2015/5/23 GDG神戸 初級〜中級者向け Android勉強会 2015/5/28 I/O Extended 2015 Kobe 2015/6/20 GDG DevFest Japan Summer 2015 in Kyoto(共催) 2015/7/18 AndroidWearハッカソン 2015/7/25 WebMusicハッカソン(共催) 2015/8/22 AndroidTVハンズオン勉強会 2015/9/19 Cardboardハンズオン勉強会(共催) 2015/9/20 Polymerコードラボ 2015/10/11 GDG DevFest Kobe Firebaseハンズオン勉強会 2015/11/7 ちょっとさわってみる Go言語ハンズオン 2015/11/14 Android6.0 Marshmallow勉強会 2015/12/26 TensorFlow勉強会 2015/12/28 GDG神戸 2015年忘年会
3.
環境 ● OS ○ Windows10
64bit ● CPU ○ Core i7-3770 4-Core 3.4GHz (Turbo 3.9GHz, HT 8Thread) ● GPU ○ なし ● Memory ○ 32GB ● HDD
4.
環境 Windows(※)なので、Dockerを使用 DockerVM(VirtualBox) ● CPU ○ 4コア(4Thread) ●
Memory ○ 16GB ※BazelがWindowsをサポートしていないため。Bazelは2016/02頃にサポート予定
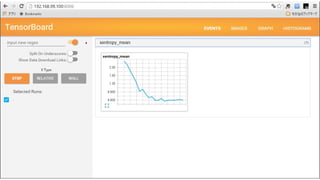
5.
TensorBoard TensorBoardでグラフとかを見れるようにしておきたい グラフを作成するにはSummaryWriterでログを出力している必要がある tutorialsの手書き数字認識でfully_connected_feed.pyではログを出力して いたので、とりあえずこれで確認してみる(TensorFlow Mechanics 101)
6.
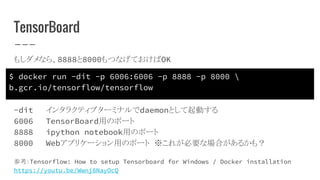
TensorBoard Dockerを使用しているので、コンテナ作成時に、TensorBoardが使用している6006を ホストマシンにつないでおく必要がある $ docker run
-dit -p 6006:6006 b.gcr.io/tensorflow/tensorflow PORT 0.0.0.0:6006->6006/tcp, 8888/tcp docker psで下のような感じで6006と8888が出てればOK
7.
TensorBoard $ docker run
-dit -p 6006:6006 -p 8888 -p 8000 b.gcr.io/tensorflow/tensorflow もしダメなら、8888と8000もつなげておけばOK -dit インタラクティブターミナルでdaemonとして起動する 6006 TensorBoard用のポート 8888 ipython notebook用のポート 8000 Webアプリケーション用のポート ※これが必要な場合があるかも? 参考:Tensorflow: How to setup Tensorboard for Windows / Docker installation https://youtu.be/Wwnj8NayOcQ
8.
TensorBoard docker psでコンテナIDを確認して、attachする $ docker
ps $ docker attach [container id] $ apt-get update $ apt-get install git $ apt-get install vim とりあえずgitが必要 好きなテキストエディタも入れとけば楽
9.
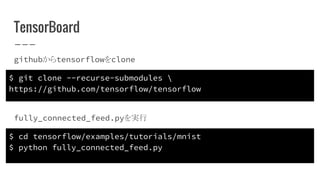
TensorBoard githubからtensorflowをclone $ git clone
--recurse-submodules https://github.com/tensorflow/tensorflow $ cd tensorflow/examples/tutorials/mnist $ python fully_connected_feed.py fully_connected_feed.pyを実行
10.
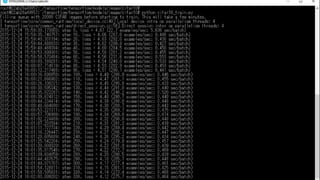
TensorBoard ちなみに4コア(4Thread)割り当ててるので、以下の文言が出てくる Local device intra
op parallelism threads: 4 Direct session inter op parallelism threads: 4 summaryで出力したログのディレクトリ(data)を指定する(絶対パスの方が良いみた い.ここではrootのtensorflow以下にクローンしたので、こんなパス) $ tensorboard --logdir=/root/tensorflow/ tensorflow/examples/tutorials/mnist/data http://192.168.99.100:6006 にアクセスする(IPはVBoxのデフォルト値)
11.
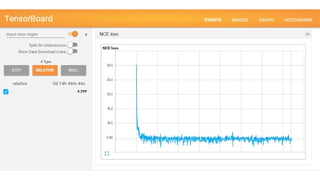
TensorBoard
12.
TensorBoard TensorBoardはCtrl+Cで止まる dockerからはCtrl+P+Qで抜ける(detach)
13.
Convolutional Neural Networks CIFAR-10とは、一般物体認識のベンチマークとしてよく使われている画像データセット 約8000万枚の画像がある「80
Million Tiny Images」からサブセットとして約6万 枚の画像を抽出してラベル付けしたデータセット
14.
Convolutional Neural Networks とりあえず何も考えずに実行してみる $
cd tensorflow/models/image/cifar10 $ python cifar10_train.py
16.
Convolutional Neural Networks 6時間経過
19.
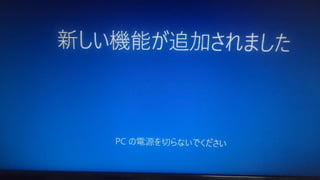
Convolutional Neural Networks PCの電源を切らないでください!
20.
Convolutional Neural Networks Windows10
TH2で、コルタナさんが無事我が家にやってきました とりあえずcheck pointは作成しているし、ログは出力されていたけど、もう一度やり直 した
21.
Convolutional Neural Networks 1日(24時間)経過
23.
Convolutional Neural Networks 1日で18万Stepくらい ソースをちゃんと見てみると、100万Stepある この調子だと、終わるまで大体6日(144時間)はかかる 今年中には終わりそう…(現在進行中)
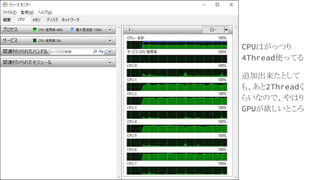
24.
CPUはがっつり 4Thread使ってる 追加出来たとして も、あと2Threadく らいなので、やはり GPUが欲しいところ
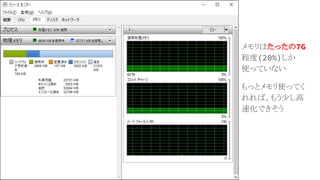
25.
メモリはたったの7G 程度(20%)しか 使っていない もっとメモリ使ってく れれば、もう少し高 速化できそう
26.
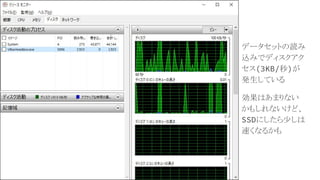
データセットの読み 込みでディスクアク セス(3KB/秒)が 発生している 効果はあまりない かもしれないけど、 SSDにしたら少しは 速くなるかも
27.
Vector Representations of
Words 自然言語処理 人が日常的に使っている言葉をコンピュータに処理させるもの Word2Vec 単語をベクトル化して表現するする定量化手法 「同じ文脈の中にある単語はお互いに近い意味を持っている」というシンプルな考え方 論文:「Efficient Estimation of Word Representations in Vector Space」 http://arxiv.org/pdf/1301.3781v3.pdf
28.
Vector Representations of
Words
29.
Vector Representations of
Words 今回は先にどれくらいかかりそうかソースを見てみると、15Epochで終わるみたい とりあえず実行してみる まずは訓練データセット(text8.zip)と評価データ(questions-words.txt)を取 得し、訓練データセットはzipファイルなので解凍する $ apt-get install wget $ apt-get install unzip $ cd tensorflow/models/embedding $ wget http://mattmahoney.net/dc/text8.zip -O text8.zip $ unzip text8.zip $ wget https://word2vec.googlecode.com/svn/trunk/questions-words.txt
30.
Vector Representations of
Words check pointとログファイルの出力先を作成しておく word2vec.py実行時に、train_dataに訓練データセット、eval_dataに評価デー タ、save_pathにcheck pointとログファイルの出力先を指定する $ mkdir /tmp/word2vec $ python word2vec.py --train_data=text8 --eval_data=questions-words.txt --save_path=/tmp/word2vec
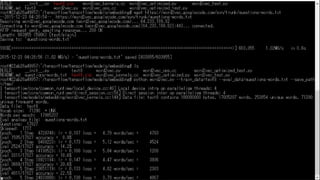
31.
Vector Representations of
Words 開始時にword2vec_kernels.ccが訓練データセットの中身をチェックしているみた い。1700万単語存在している様子 Data file: text8 contains 100000000 bytes, 17005207 words, 253854 unique words, 71290 unique frequent words.
33.
Vector Representations of
Words 6時間経過
34.
Vector Representations of
Words 突然PCがフリーズ
35.
Vector Representations of
Words 数時間放置してたら 復旧した!
38.
Vector Representations of
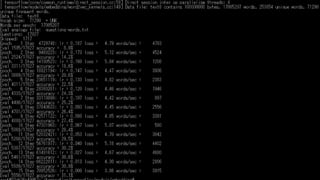
Words 精度は3割くらい 時間は14時間くらいかかってた(word2vec_optimized.pyの方だとそれよりも早 いっぽい。未確認) 論文のAbstractでは「16億単語から高品質な単語ベクトルを学習するのに1日かから ない」とあるので、それくらいの単語数はいるのかも?
39.
TensorFlowを触ってみたまとめ ● メモリはそんなに使わない ● GPUは欲しい ●
Bazelはよ ※Windows対応 ● ソース読め ● 6時間後に何か起こる
40.
TensorFlowを触ってみたよ! ご清聴ありがとうございました!
Download








![TensorBoard
docker psでコンテナIDを確認して、attachする
$ docker ps
$ docker attach [container id]
$ apt-get update
$ apt-get install git
$ apt-get install vim
とりあえずgitが必要
好きなテキストエディタも入れとけば楽](https://image.slidesharecdn.com/tensorflow-151226145957/85/TensorFlow-8-320.jpg)