Download to read offline











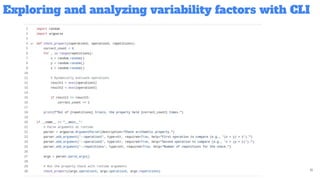







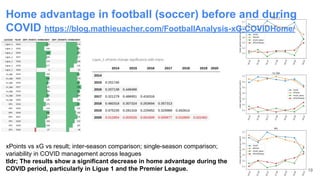










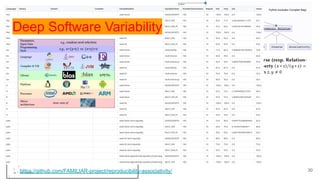



Reproducibility is often discussed but rarely practiced in undergraduate computer science education. In this paper, we present the design, implementation, and evaluation of a 24-hour hands-on course entirely dedicated to reproducibility and variability in computational experiments. Taught to fourth-and fifth-year students at INSA Rennes in Fall 2024, the course combines scientific thinking, software engineering practices, and variability analysis. Students first explored the non-associativity of floating-point arithmetic as a reproducibility "Hello World" using Docker, GitHub Actions, and templated experimentation to analyze sources of variability across programming languages, compiler flags, and numerical precision. The second half of the course focused on reproducing and replicating actual research papers, including studies on large language models playing chess, home advantage in football during COVID-19, and energy efficiency across programming languages. Students successfully reproduced key results, identified subtle reproducibility issues such as changes in library defaults, and designed replications that extended or challenged original findings. We describe the course structure, pedagogical strategies, and lessons learned, including when students found reproducibility flaws in the instructor's own prior work. Our experience suggests that reproducibility and variability deserve a central place in computer science education and can be taught in a way that is both technically rigorous and scientifically engaging.