Downloaded 37 times


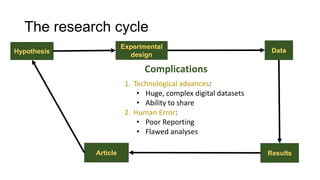
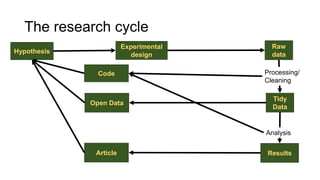



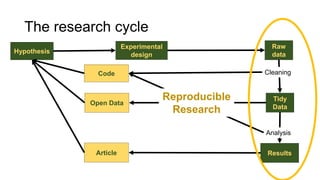




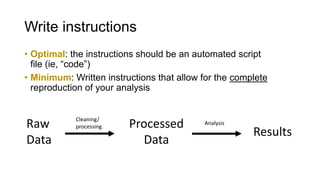









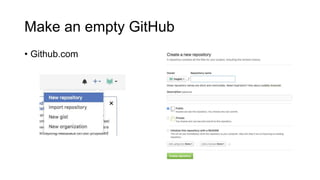


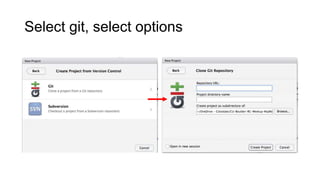
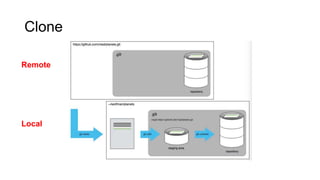
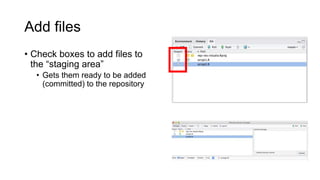
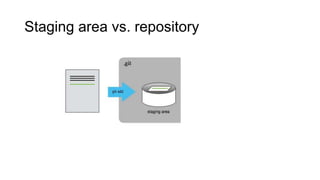
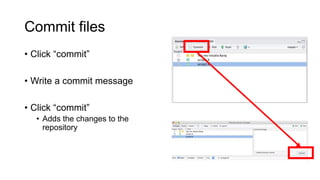
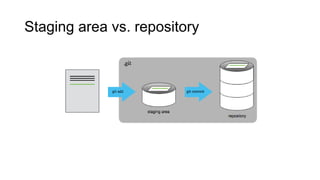
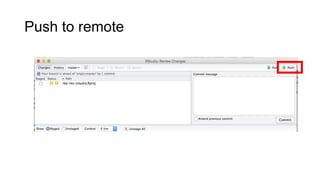
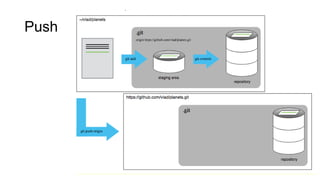





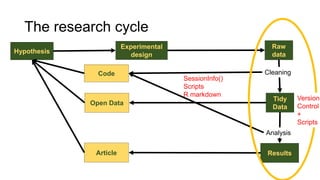


This document discusses reproducible research and provides guidance on how to conduct analysis in a reproducible manner. Reproducible research means distributing all data, code, and tools required to reproduce published results. Key aspects include automating analysis, using version control like Git, and producing human and machine readable reports in R Markdown. The presenter provides examples of documenting analysis in R and using R Markdown documents. Researchers are encouraged to think about reproducibility in their entire workflow and use checklists to ensure all elements like data, code, software details are preserved.















































































![[DSC Europe 25] Raul Cruz Bonilla - Harnessing GEN AI in Fashion, Luxury and ...](https://cdn.slidesharecdn.com/ss_thumbnails/me7nvup5thwqzwzblbvw-raul-cruz-harnessing-ai-en-luxury-260123083019-32ac5a43-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Ekaterina Bubenko - Behind the Curtain: How Data Roles Collab...](https://cdn.slidesharecdn.com/ss_thumbnails/anmv6x8dstqbbzchoklr-ekaterina-bubenko-behind-the-curtain-how-data-roles-collaborate-in-the-ai-era-a-260123083019-4b252ec7-thumbnail.jpg?width=640&height=640&fit=bounds)
