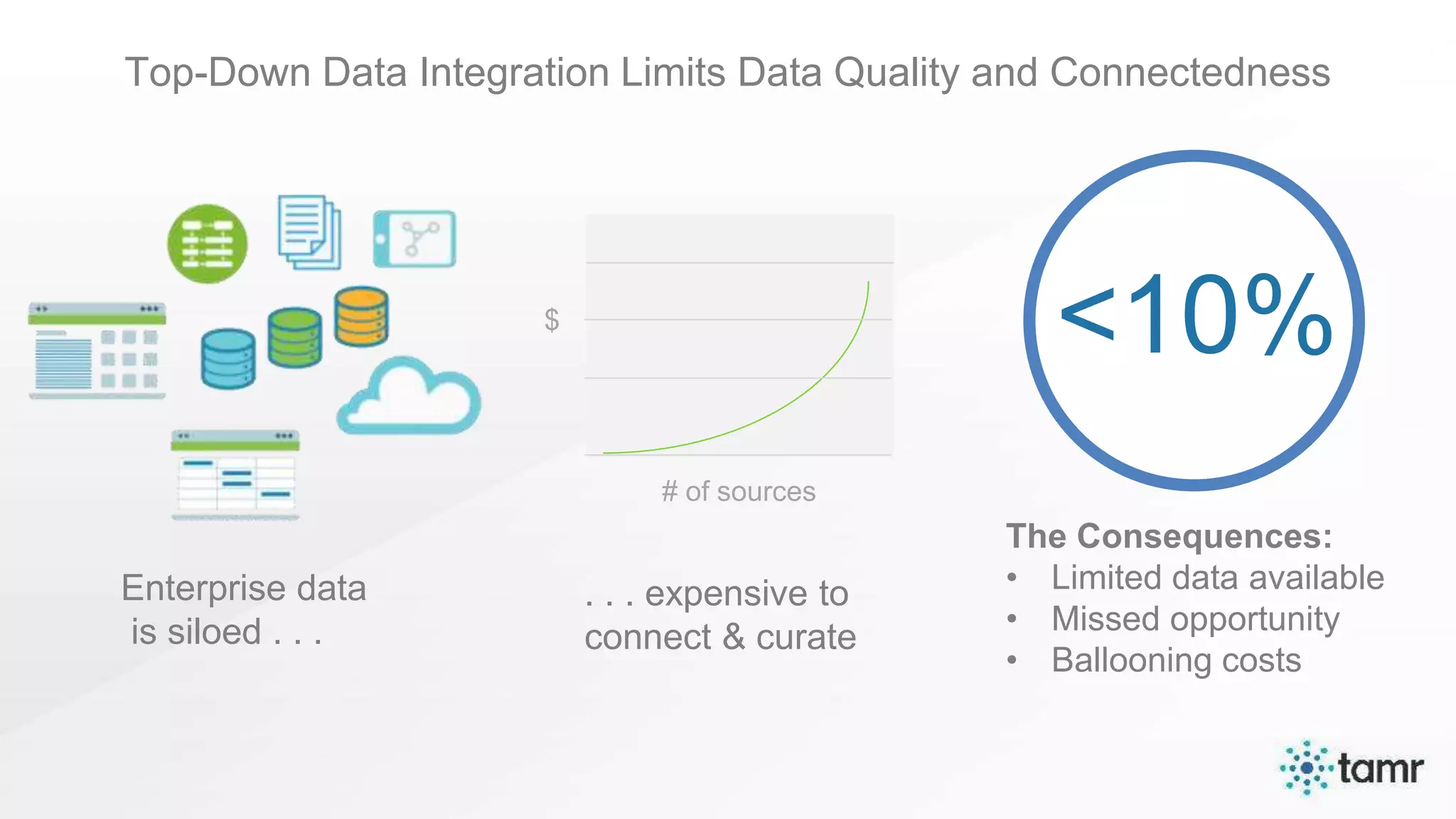
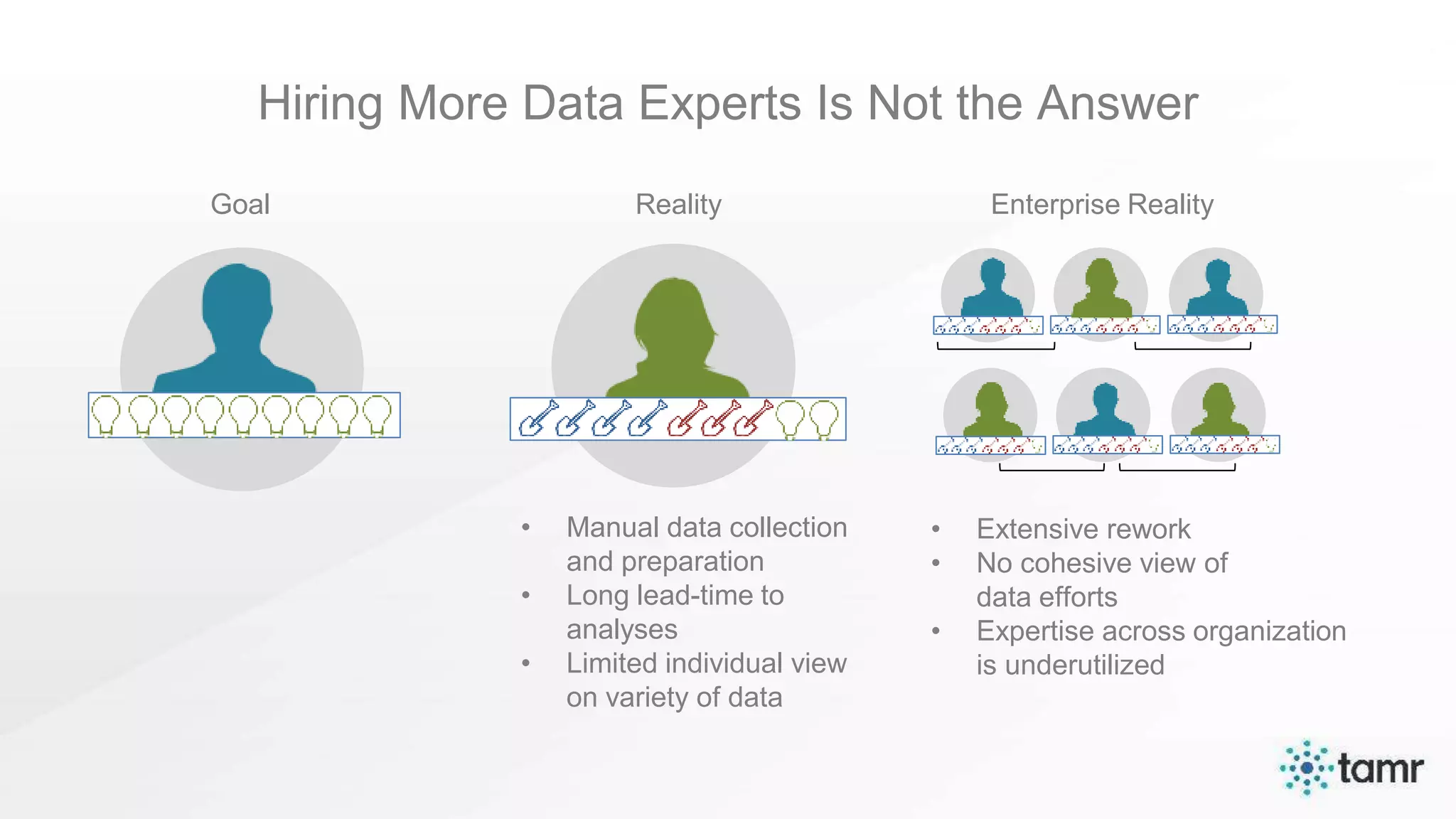
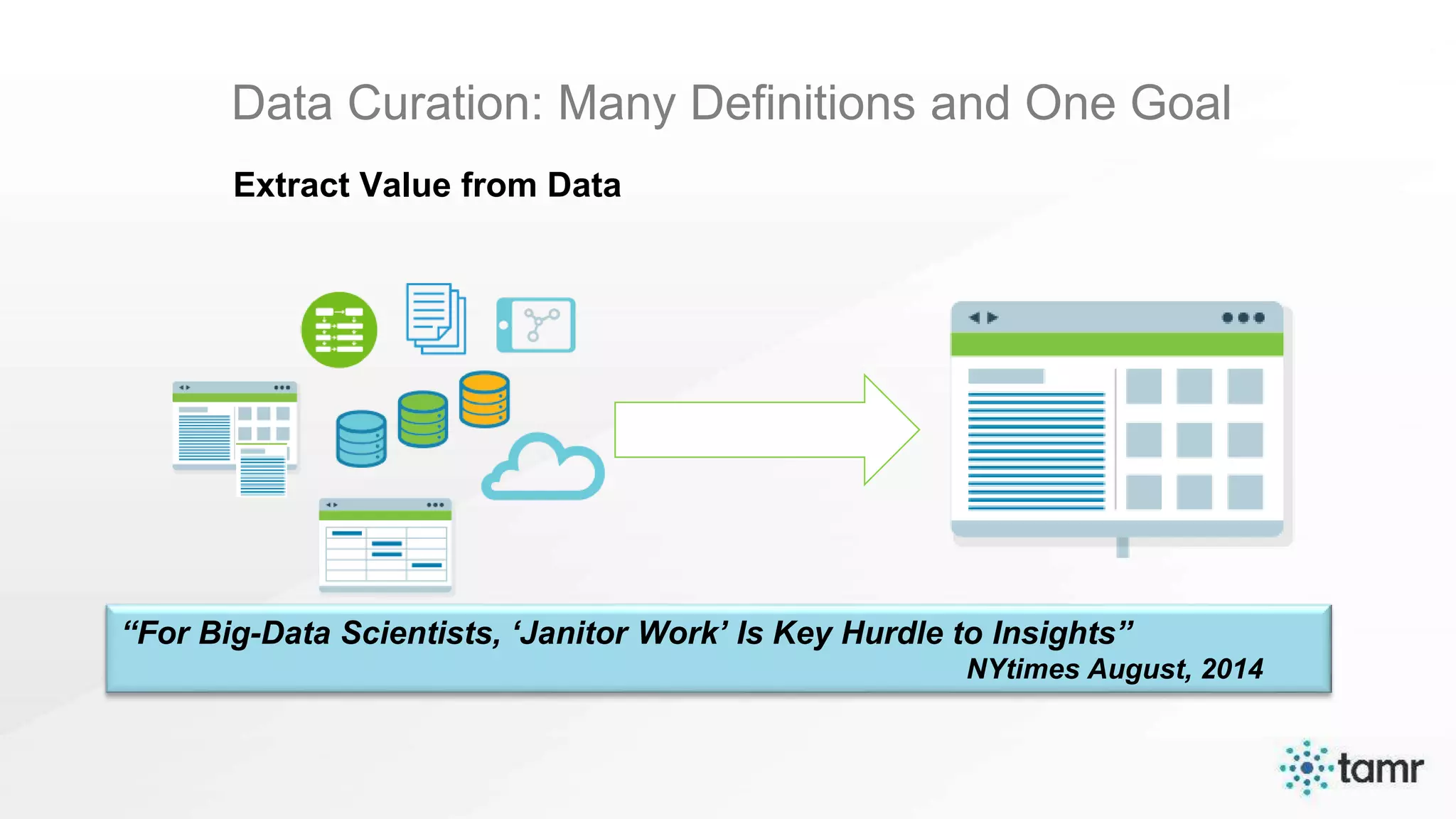
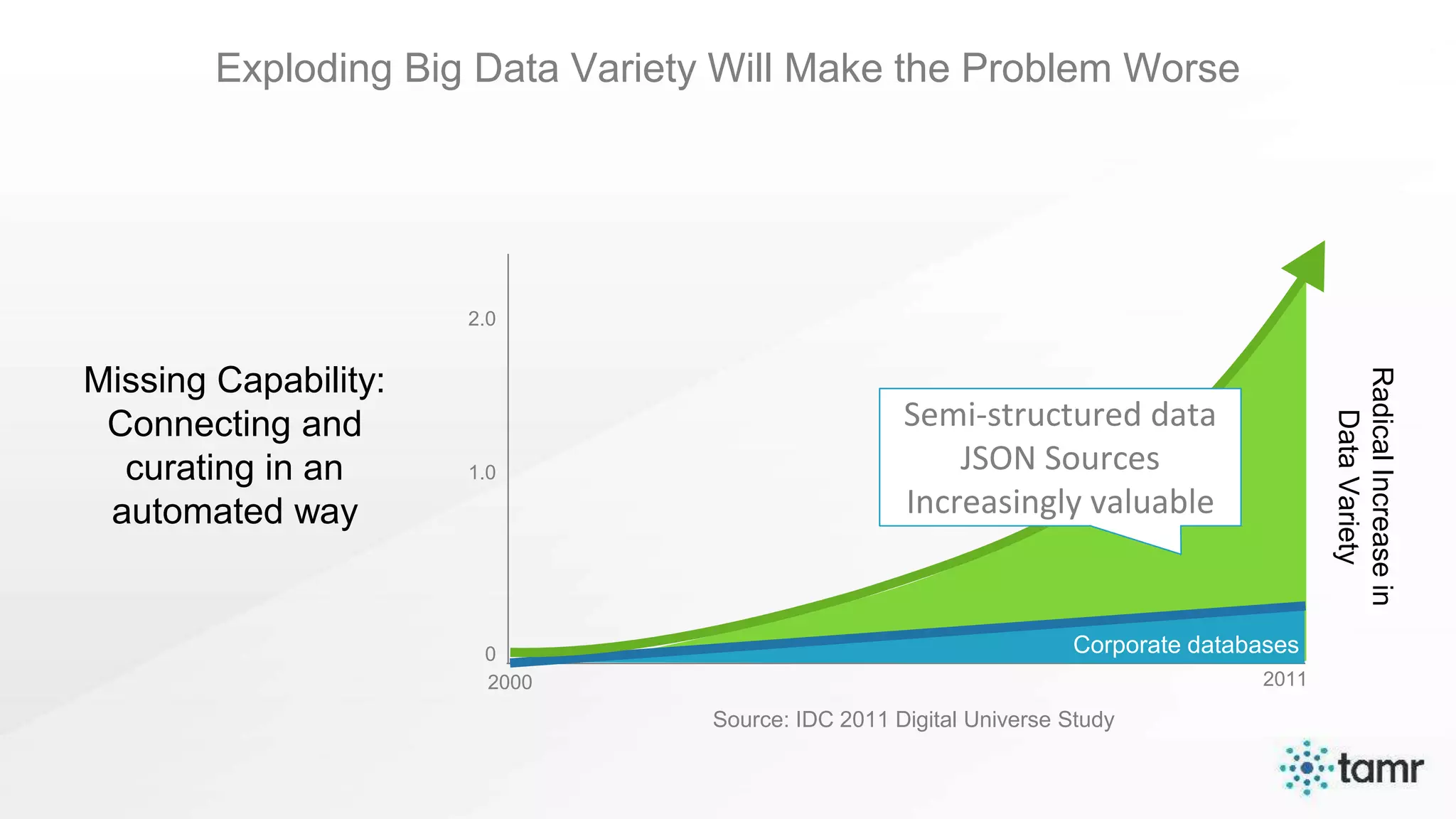
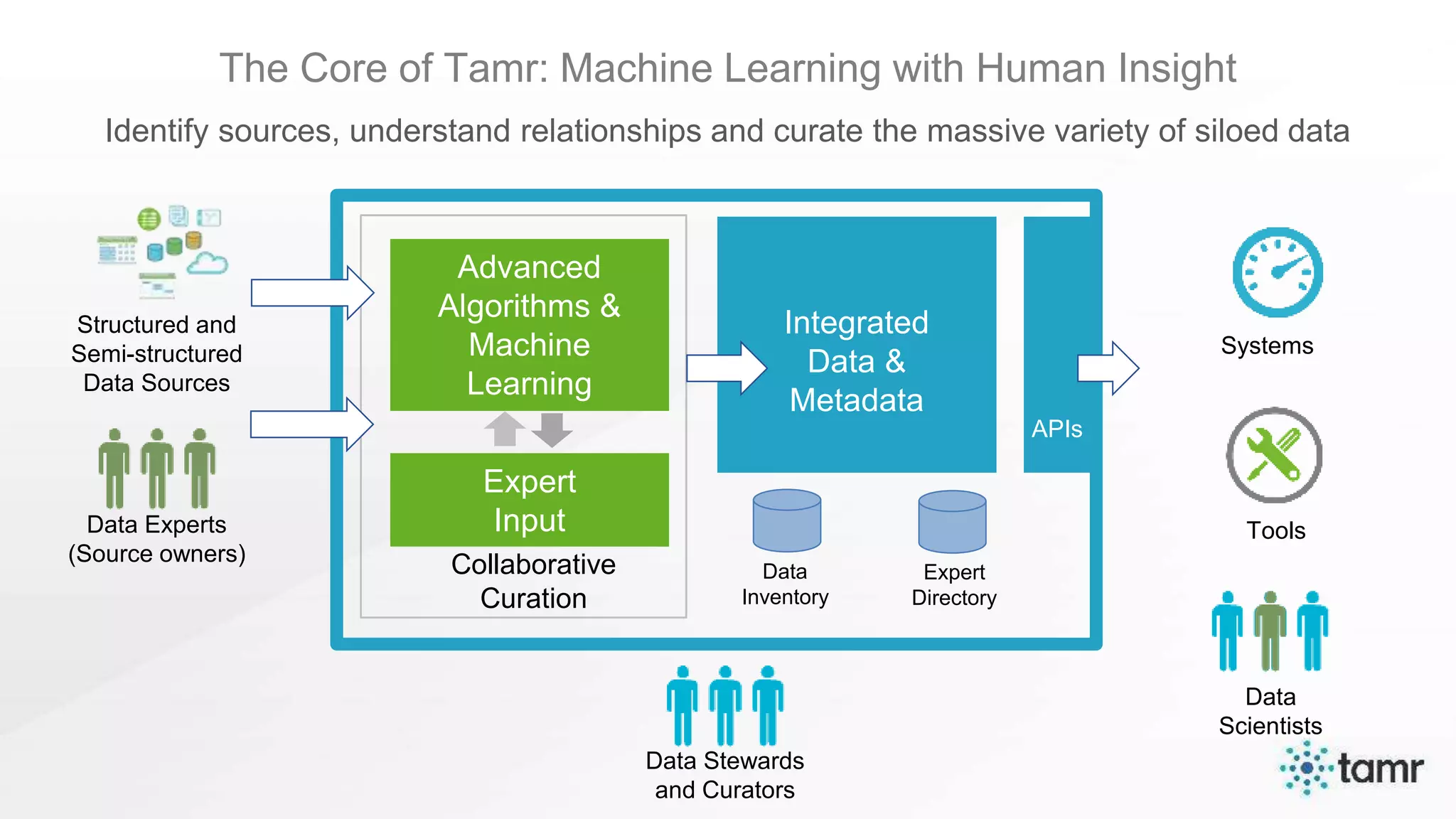
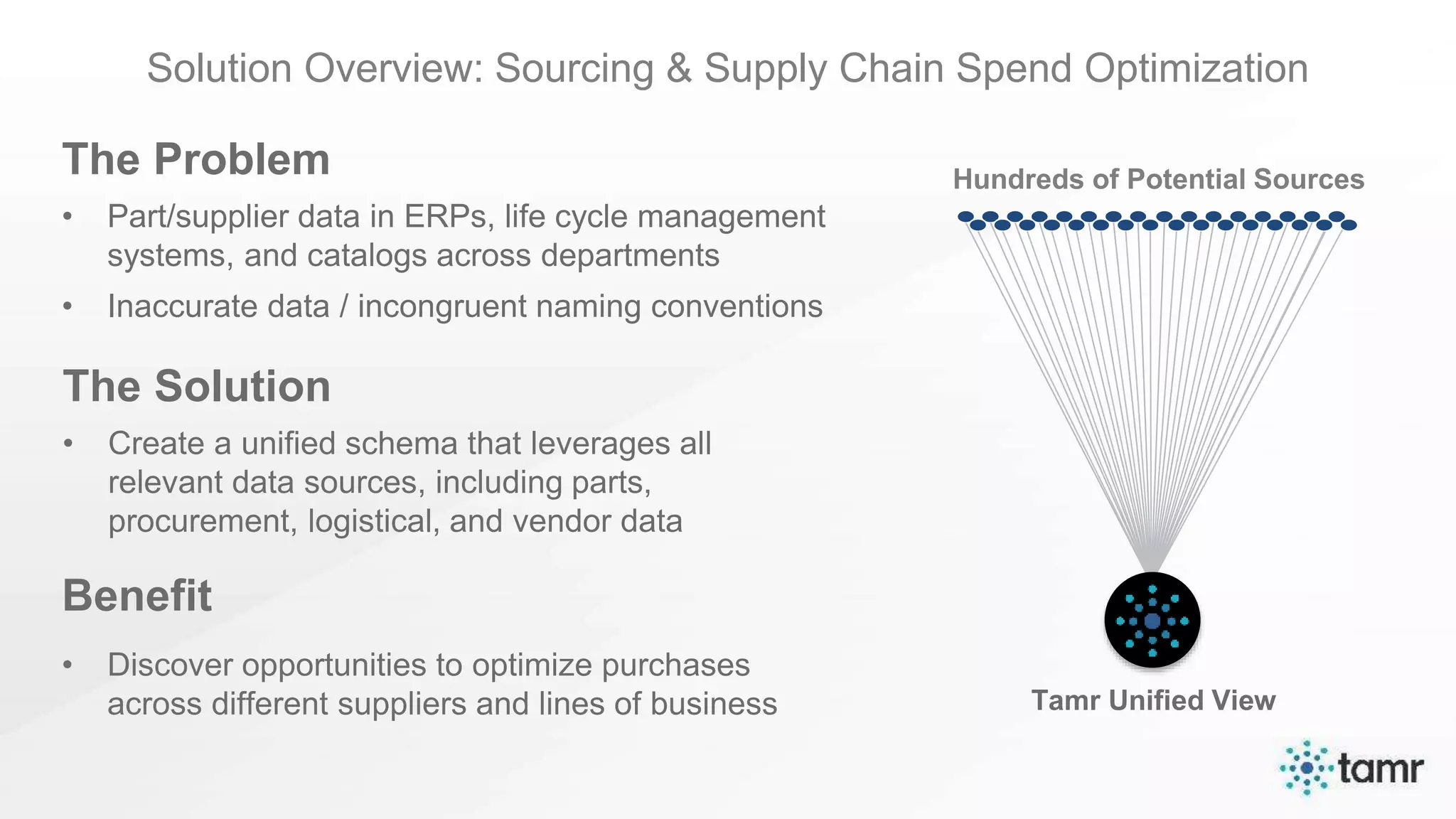
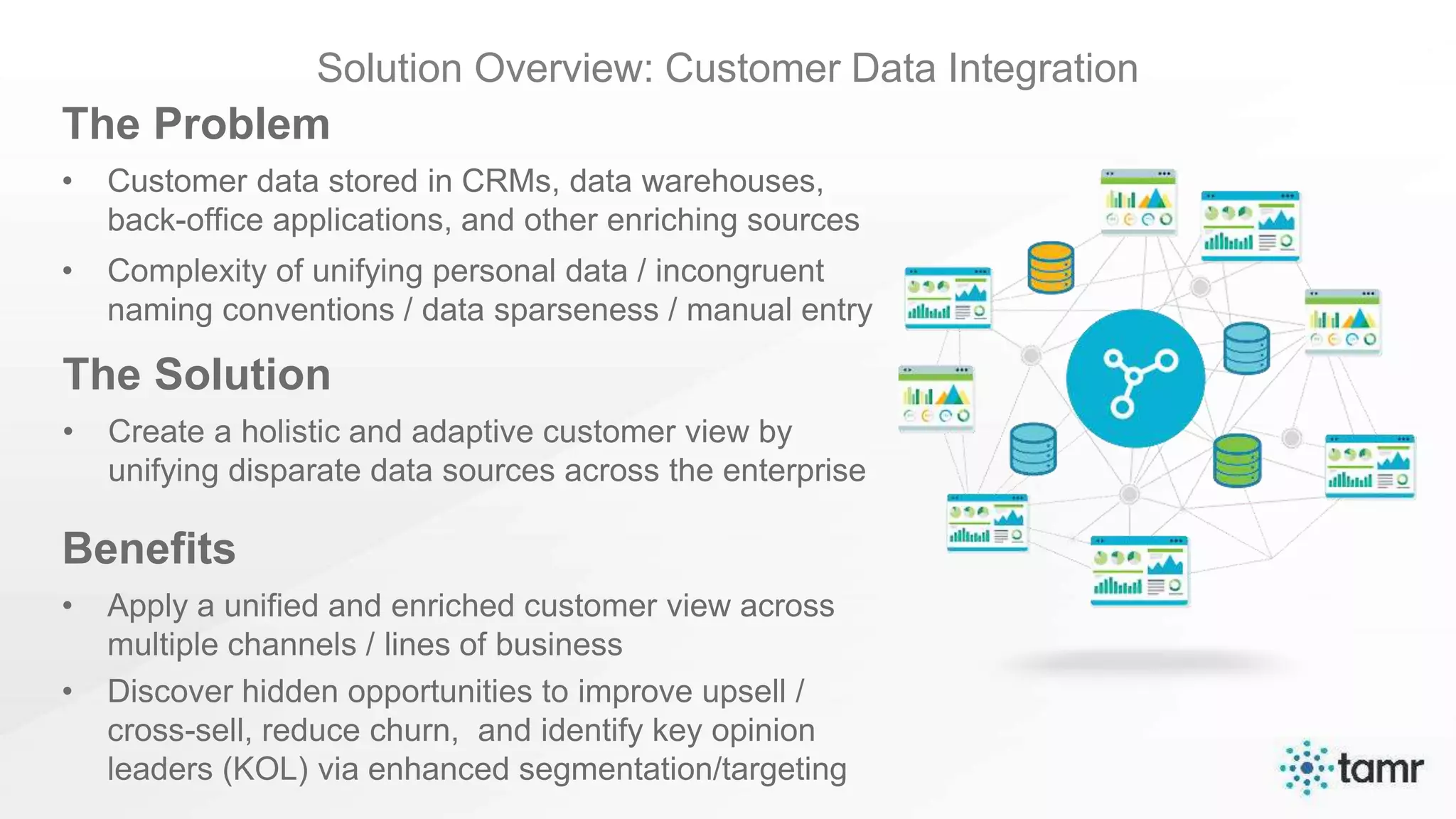
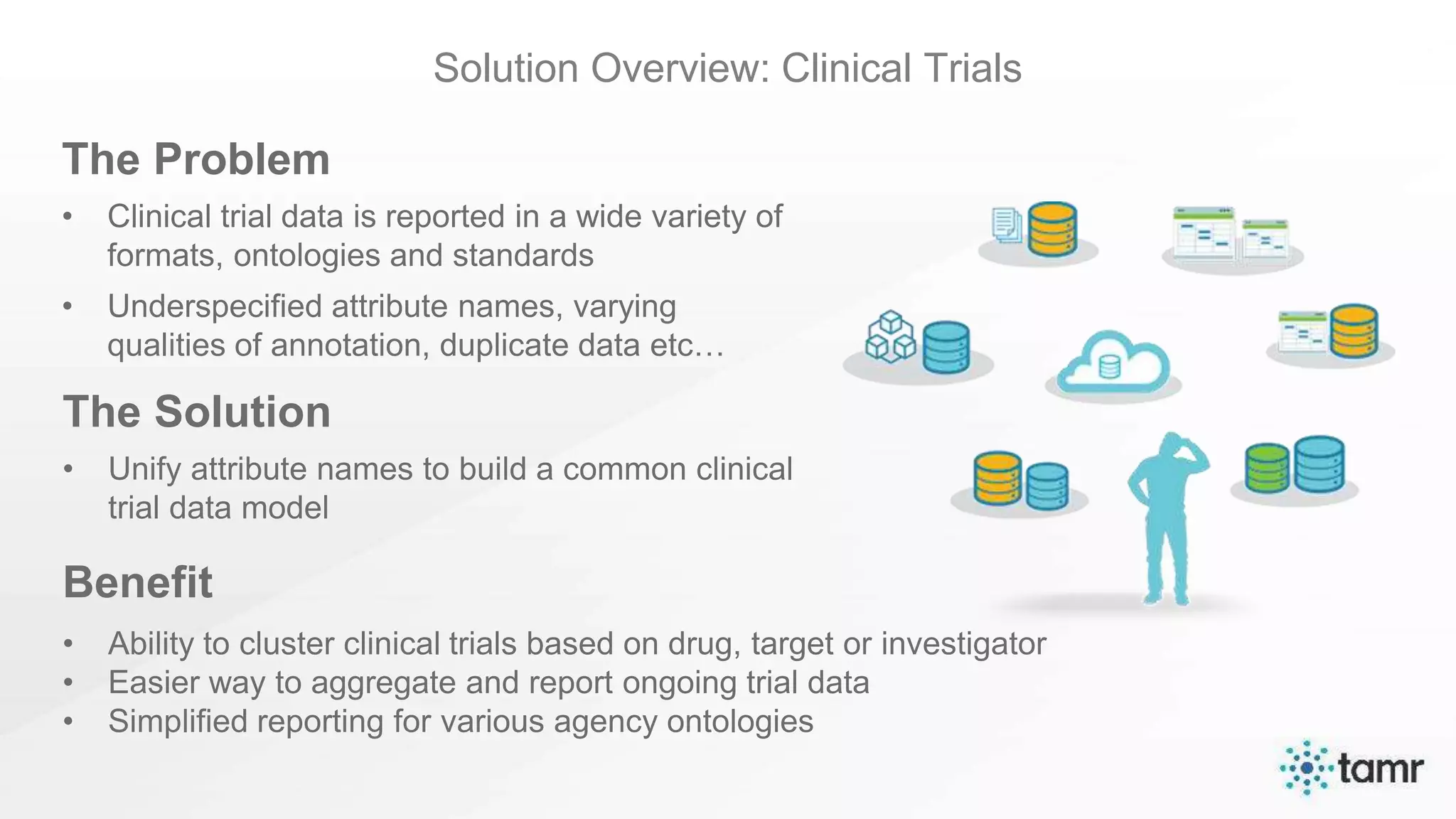
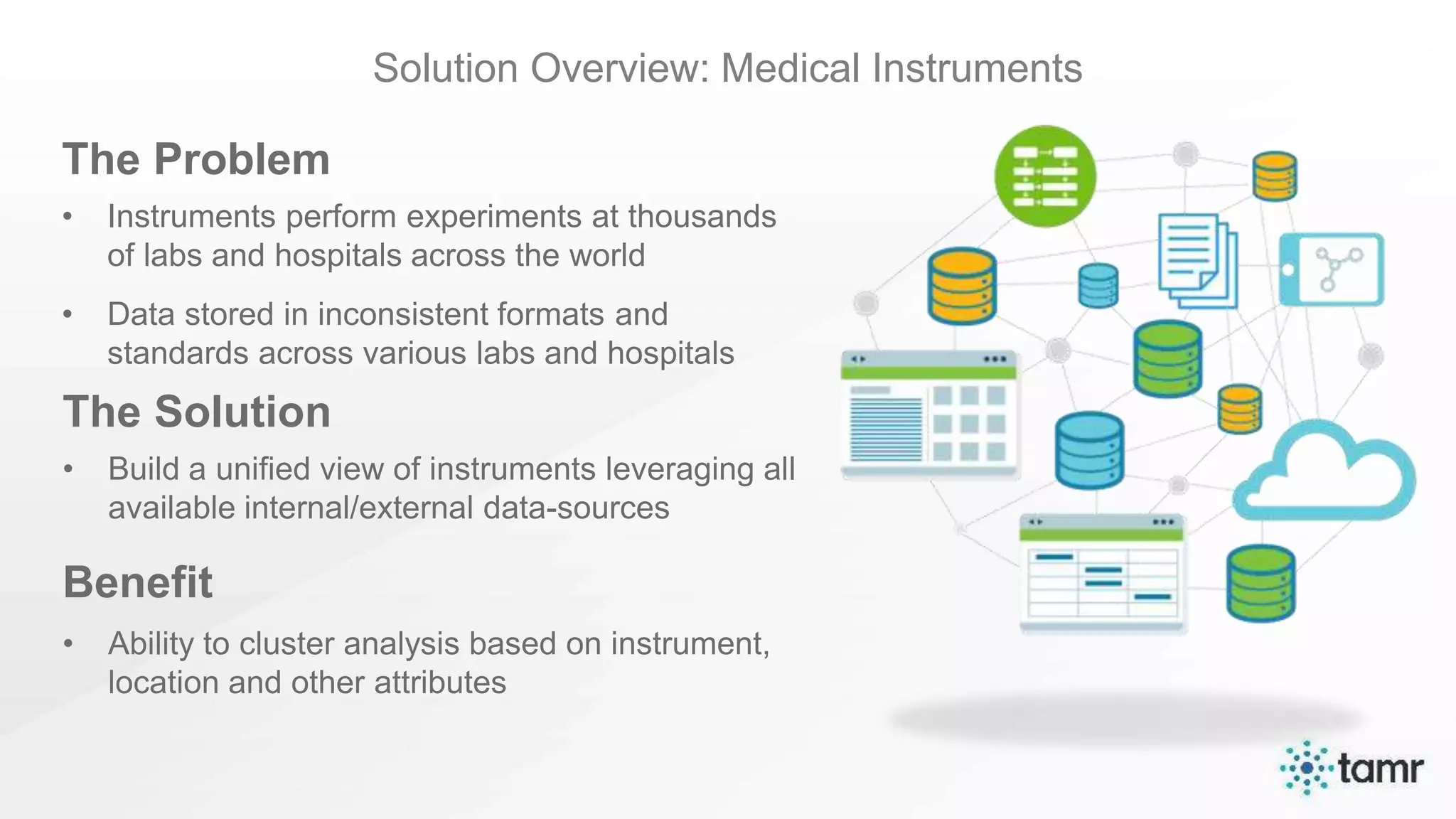
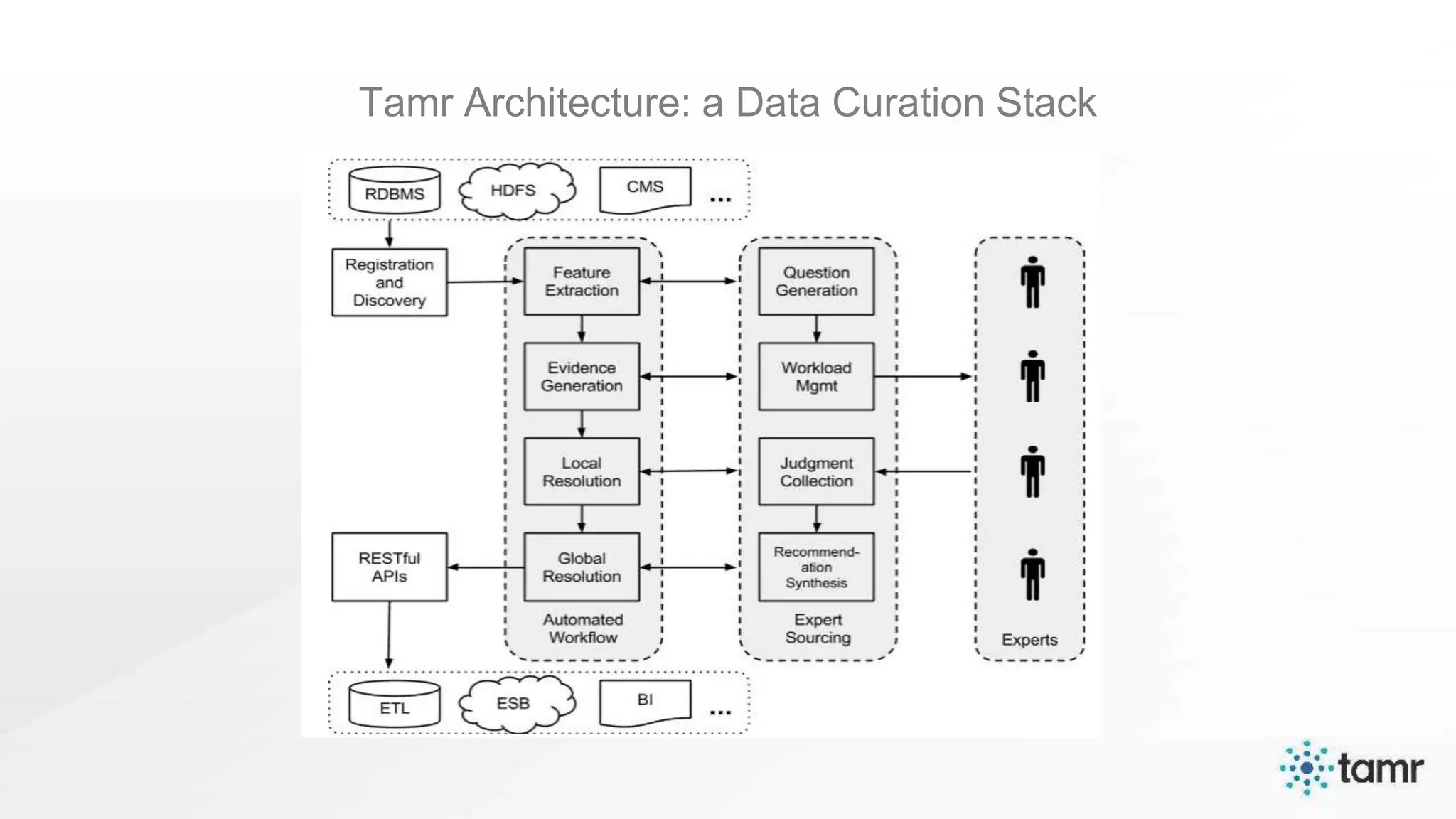
The document discusses the challenges of enterprise data integration, highlighting that over 90% of data is siloed, leading to limited data availability and increased costs. It presents Tamr's approach to data curation through the use of machine learning and human insight to connect and automate the curation of structured and semi-structured data. Various use cases, including sourcing, customer data integration, clinical trials, and medical instruments are provided, illustrating the benefits of achieving a unified data view.


















































![[DSC Europe 22] The Making of a Data Organization - Denys Holovatyi](https://cdn.slidesharecdn.com/ss_thumbnails/holovatyi-themakingofadataorganization-221130084917-bd5db899-thumbnail.jpg?width=640&height=640&fit=bounds)




















![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)






