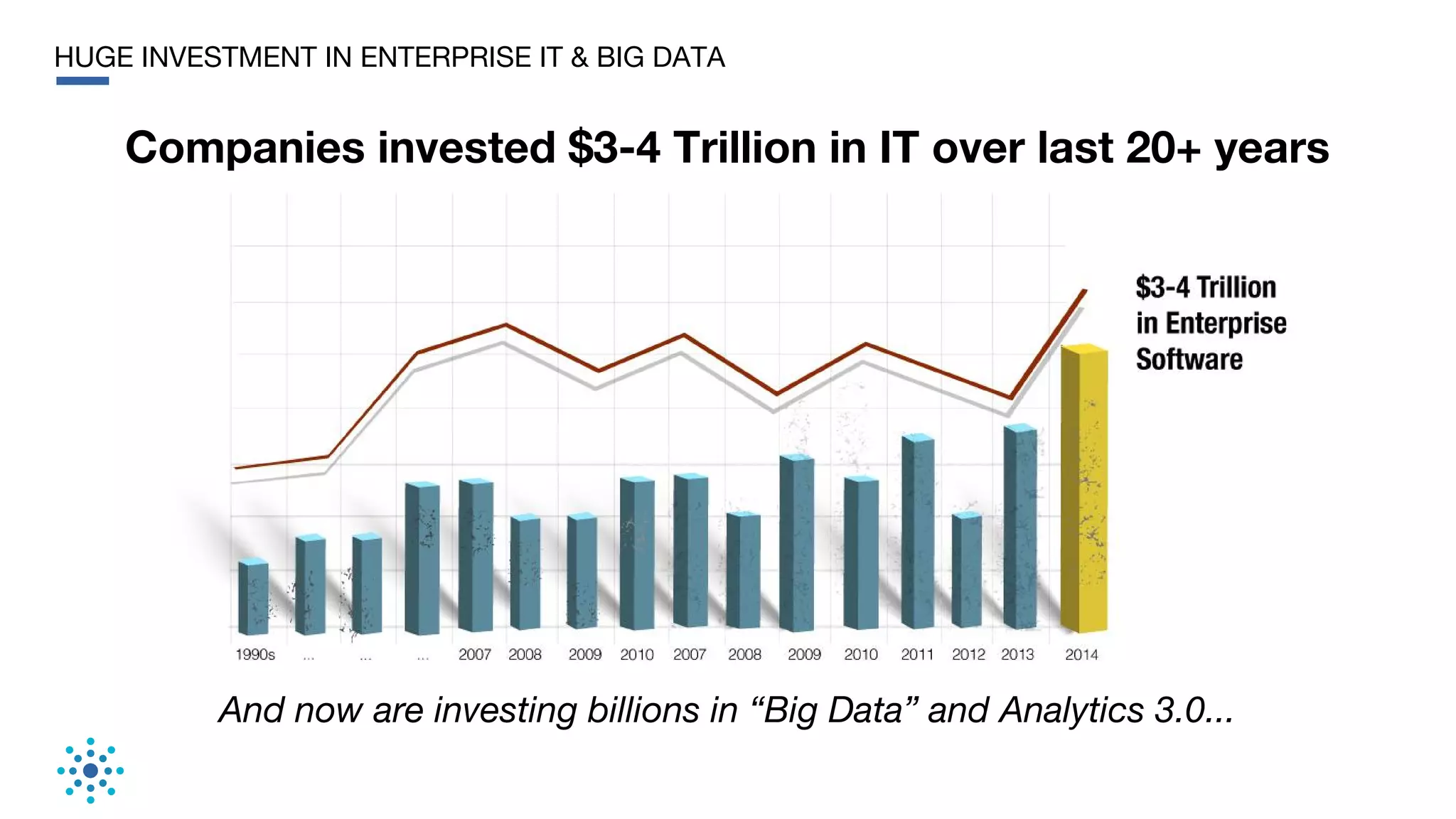
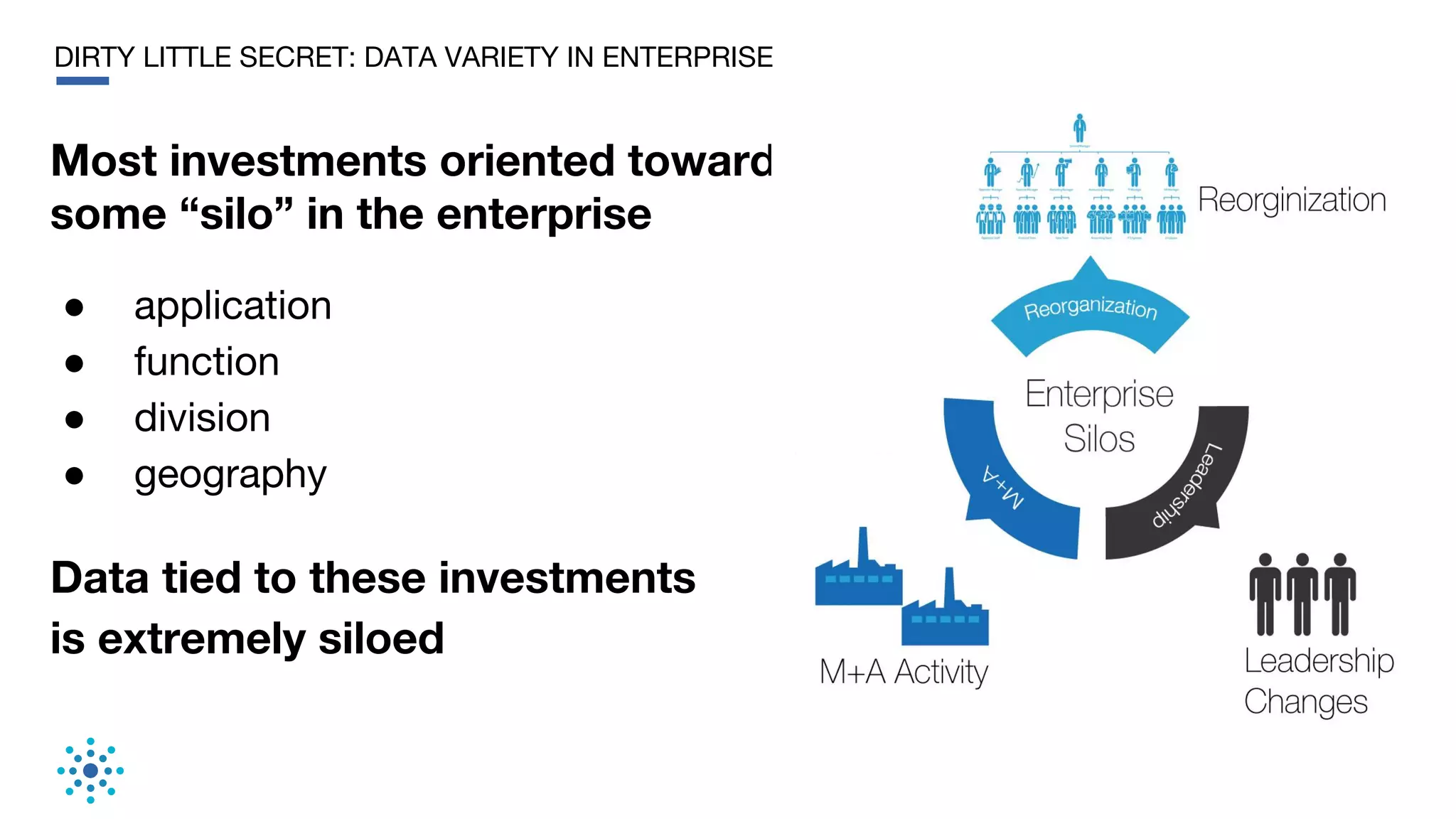
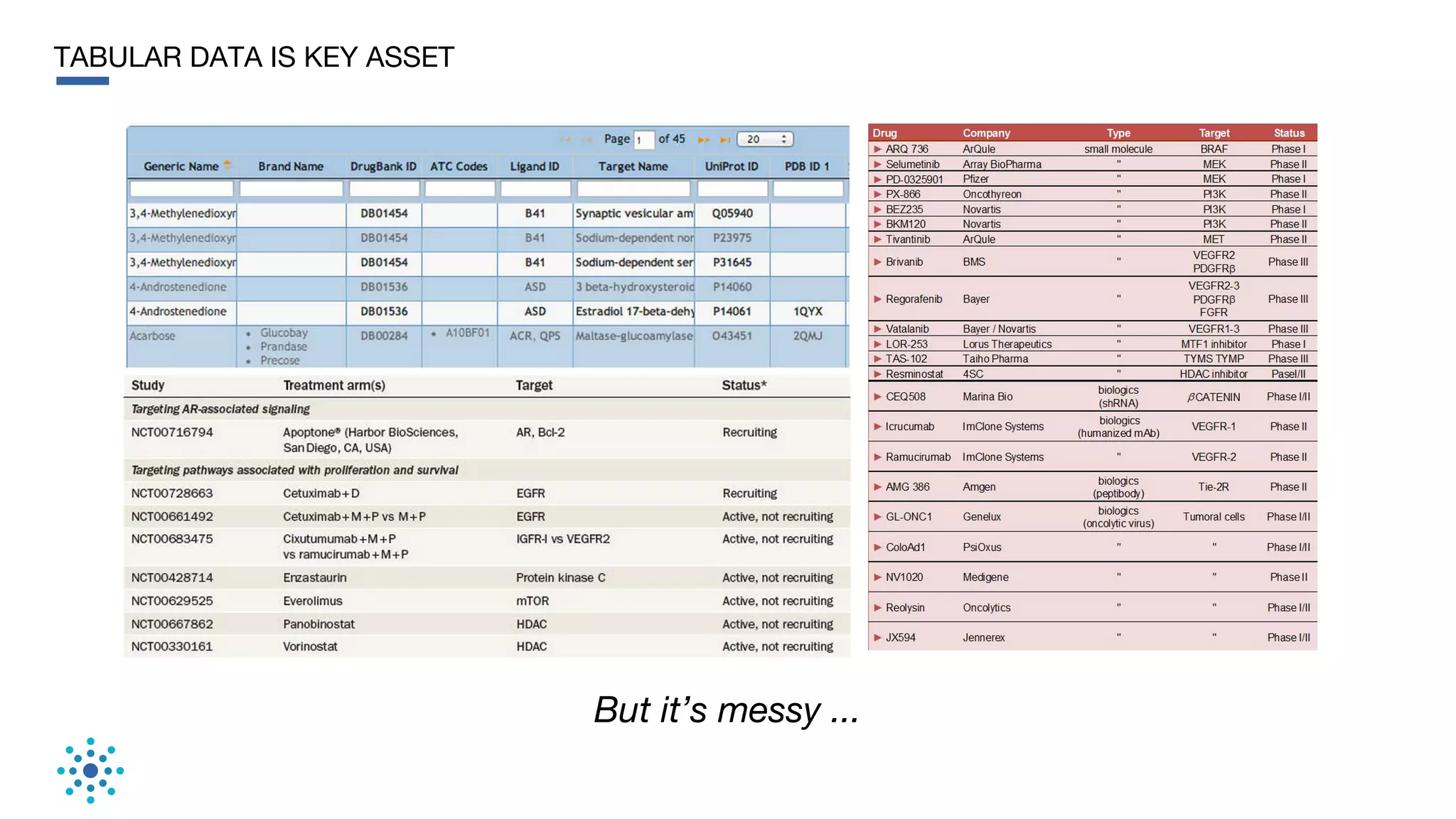
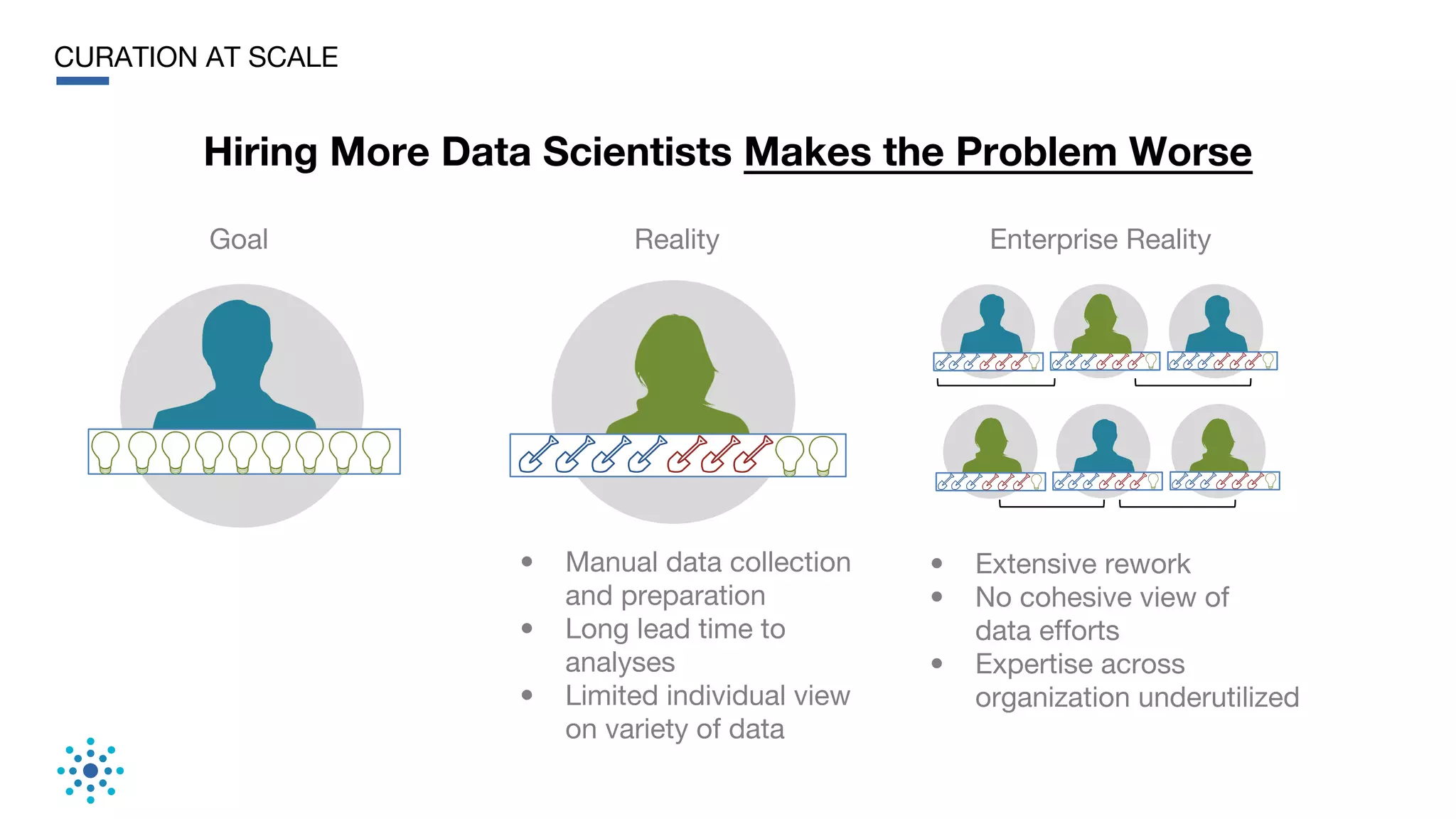
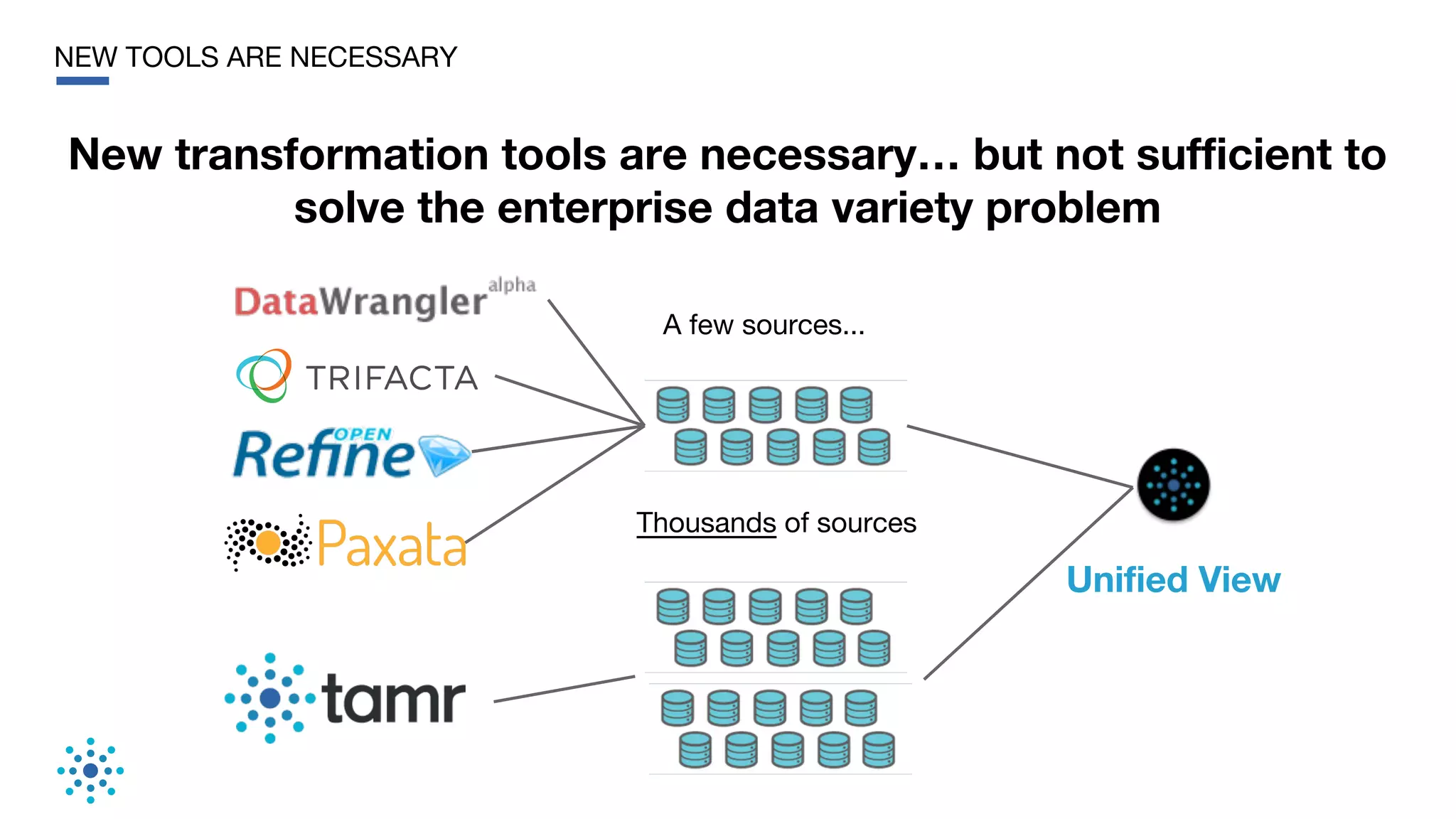
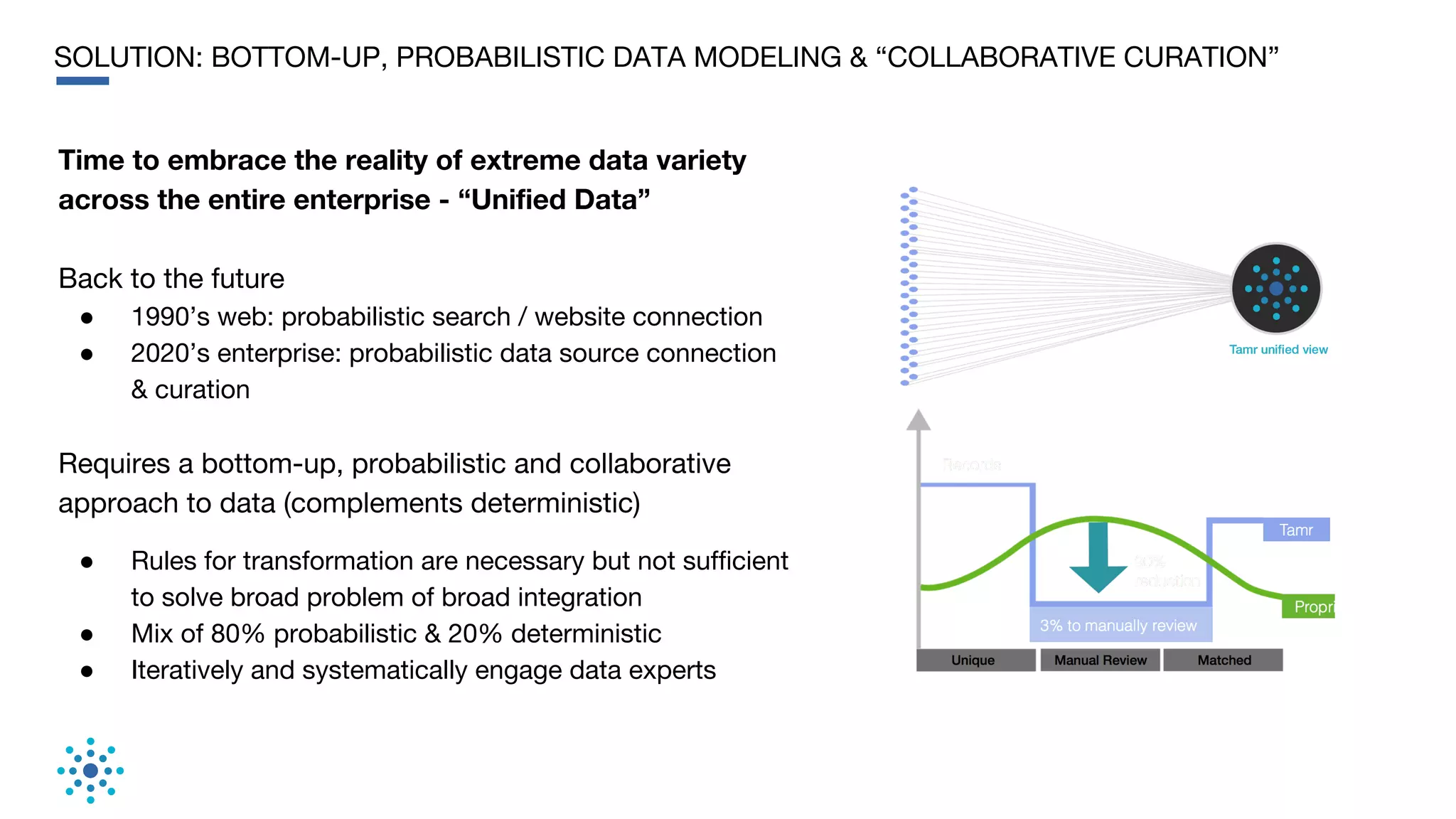
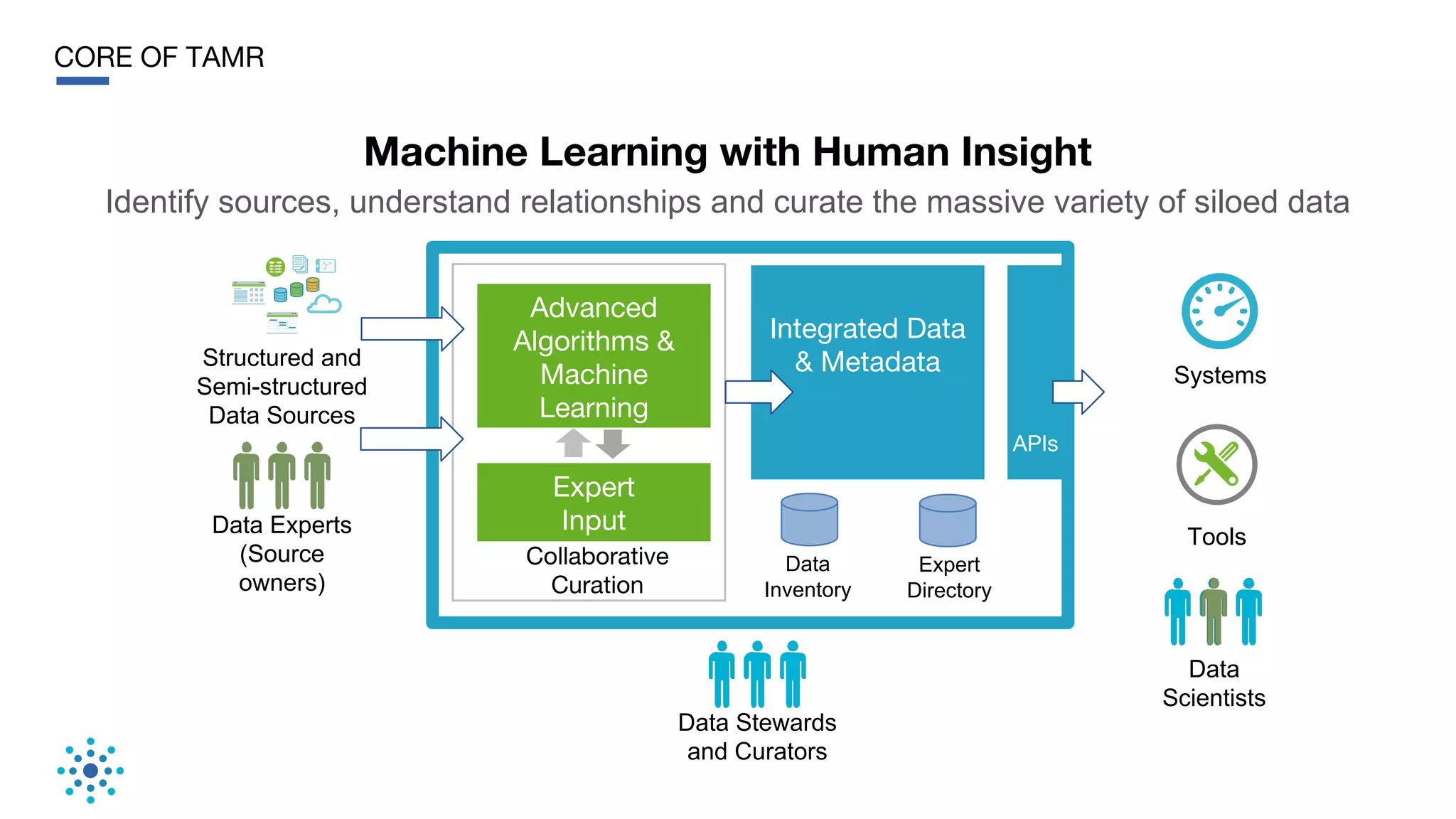
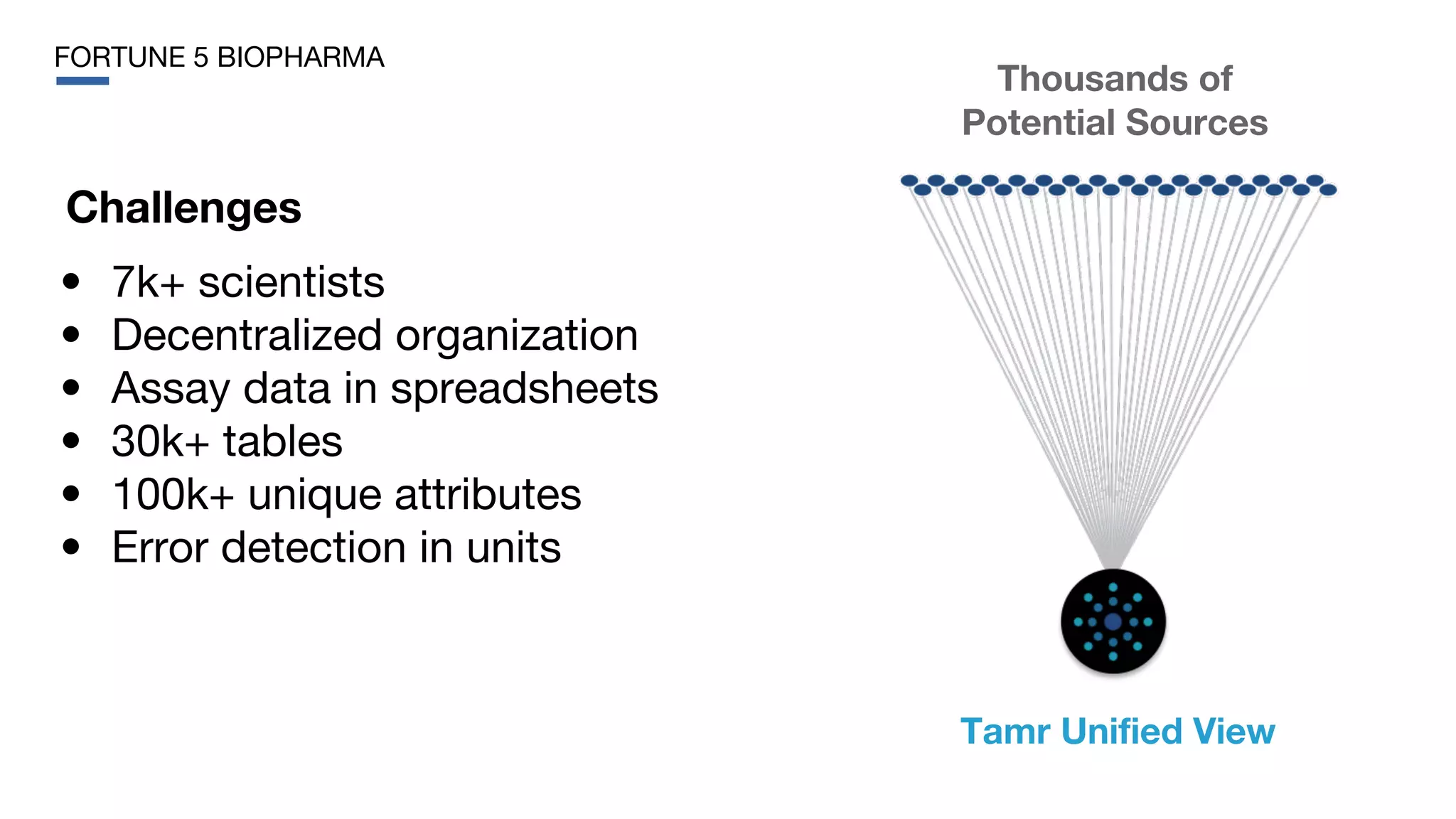
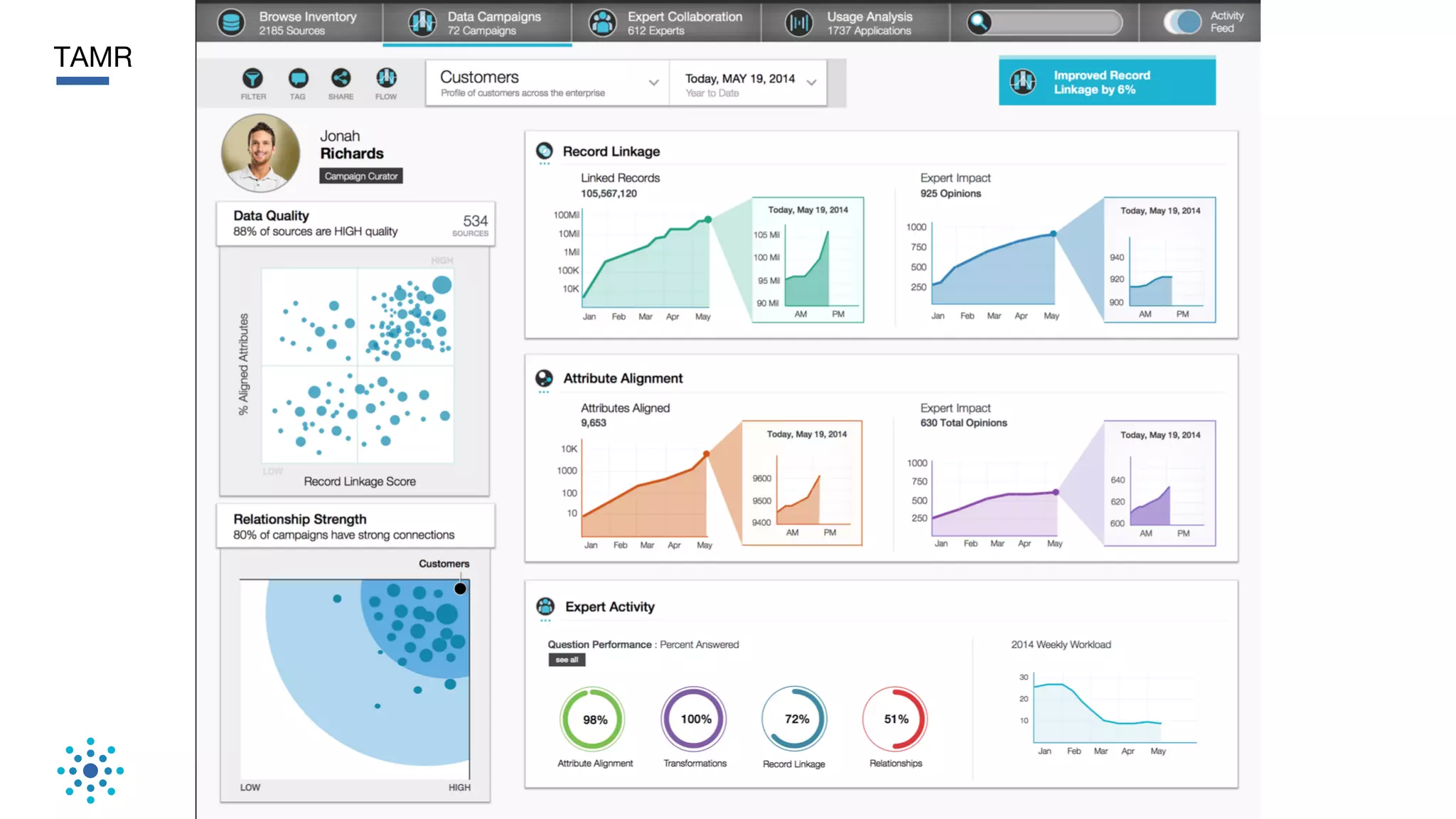
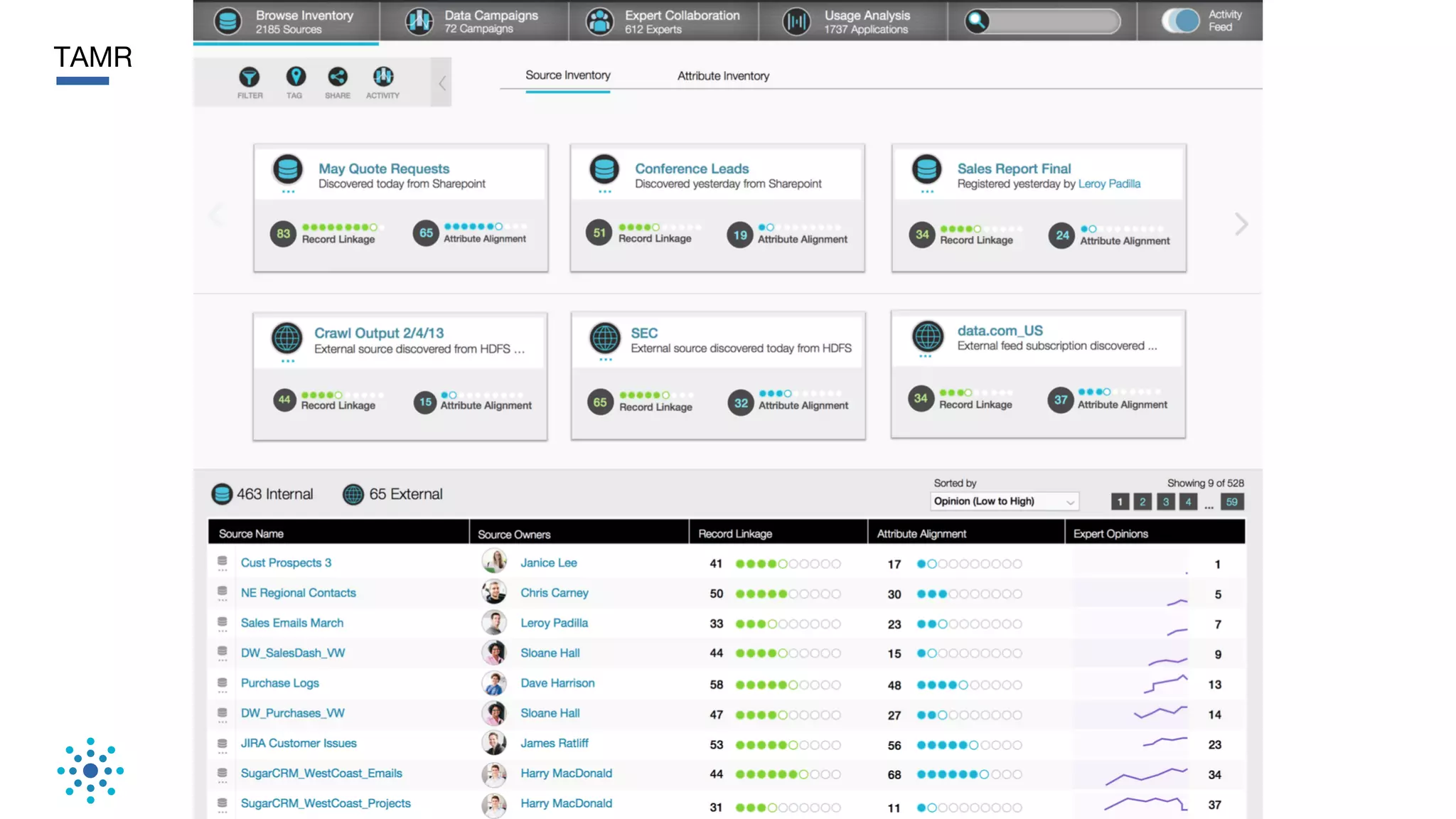
This document discusses the need for data unification across enterprises. It notes that while companies have invested trillions in IT and billions in big data and analytics, data remains extremely siloed within organizations. True big data and analytics require clean and unified data sources. The document advocates for a bottom-up, probabilistic and collaborative approach to data unification using machine learning combined with human insight and curation. This approach is needed to tackle the huge challenge of integrating and making sense of the massive variety of siloed data sources within large organizations. The document provides examples of how Tamr's data unification platform has helped large healthcare and biopharma companies achieve a unified view of their extremely diverse and decentralized data.
















































![[DSC Europe 22] The Making of a Data Organization - Denys Holovatyi](https://cdn.slidesharecdn.com/ss_thumbnails/holovatyi-themakingofadataorganization-221130084917-bd5db899-thumbnail.jpg?width=640&height=640&fit=bounds)






























