목차
◦ 컴퓨터 시스템12장 : 동시성 프로그래밍 + OS 프로세스, 쓰레드, Deadlock, 스케줄링
◦ 동시성 프로그래밍
◦ 프로세스
◦ 개념
◦ 프로세스를 이용한 동시성 프로그래밍
◦ 프로세스간 공유, 제어
◦ 쓰레드
◦ 개념
◦ 쓰레드를 이용한 동시성 프로그래밍
◦ 공유변수와 공유변수 제어
◦ 관련된 주요 주제들
◦ Dead Lock
◦ 스케줄링
◦ 개념
◦ 스케줄링의 종류
◦ 과제
◦ 생산자-소비자 문제 프로그래밍
◦ 부록
◦ 참고 사이트
3.
동시성 프로그래밍?
◦ 현대컴퓨터는 동시에 여러 프로그램을 실행한다.
◦ CPU가 단 하나 뿐이더라도 여러 프로그램을 실행할 수 있다.
◦ 프로그램을 실행하기 위해서는 명령어를 CPU에서 처리해 주어야 하는데 EIP, ESP, EBP, EAX… 등 레지스터는 하나의 CPU에
각각 하나뿐이다.
◦ 그런데 어떻게 동시에 프로그램을 실행할 수 있을까?
◦ 실제로 CPU는 한 순간에 하나의 프로그램을 실행한다.
◦ 하나의 프로그램을 진행하다가 실행할 프로그램을 바꾸어 다른 프로그램을 진행한다.
◦ CPU의 처리 속도가 아주 빨라서 그 시간이 아주 짧다. 그래서 사람이 느끼기에는 동시에 처리하는 것처럼 보인다.
◦ 프로그램을 실행하기 위한 레지스터 등은 백업 해 둔다. 다시 실행할 때 복원하고 이어서 실행한다.
4.
동시성 프로그래밍?
◦ 하드웨어와OS가 협업하여 동시에 프로그램을 실행할 수 있는 환경을 조성해 준다.
◦ 그 중 다음을 공부해 보려 한다.
◦ 프로세스를 이용한 방법
◦ 쓰레드를 이용한 방법
◦ 각각의 방법의 원리와 사용법에 대해서 알아보자.
◦ 코드 실습 환경
◦ Linux(Ubuntu)
프로세스
• 운영체제가 제공하는추상화 - 프로세스
• 프로그래밍을 할 때, 분명 동시에 많은 프로그램들이 돌고 있지만 각자 자신이 사용하던 레지스터 값이나 변수 값이 다른 프로그램에 의해 변할 거
라는 가정을 하지 않았다.
• 레지스터는 CPU에 붙어있는 저장 장소이고, 그 수가 분명 제한되어 있다. 그런데 어떻게 동시에 많은 프로그램이 돌아갈 수 있을까?
• 메인 메모리는 분명 크기가 제한되어 있다. 그런데 어떻게 여러 프로그램들이 각자의 메모리를 침범하지 않을까?
• ->각각의 프로그램이 프로세스라는 형태로 관리되기 때문이다.
7.
프로세스
◦ 실행중인 프로그램을추상화한 것
◦ 레지스터 set + 메모리 구조 + 프로세스 별 독립적인 대상들
◦ 그 프로그램이 사용하던 CPU의 상태
◦ 레지스터에 있던 값
◦ 다음에 실행할 코드 위치(EIP)
◦ 스택 프레임 정보(ESP, EBP)
◦ 기타 들고있던 숫자들(EAX, EBX, …)
◦ 그 프로그램이 사용하던 메모리의 상태
◦ 가상 메모리를 물리 메모리 어디에 올려 두었는지 매핑(mapping)한 테이블
◦ 메모리 구역마다 정해 둔 권한(읽기/쓰기/실행 권한)
◦ 그 프로그램이 사용하던 파일 목록
◦ 열었던 파일들에 대한 정보
◦ 파일의 위치, 어디까지 읽었는지 등
◦ 파일은 I/O device의 추상화이므로, 사용하던 I/O device에 대한 정보라 할 수 있음
◦ +그 프로그램을 정상적으로 실행하기 위해 필요한 정보들
◦ 이 모든 정보를 담은 것을 프로세스라 한다.
CPU Main Memory I/O devices
Virtual Memory
File
Processes
8.
프로세스
◦ 프로세스를 이용한동시 처리
◦ 하나의 CPU는 일정 시간동안 하나의 프로세스를 처리한다.
◦ 일정 시간이 지나면 진행하던 프로세스 정보를 백업해둔 뒤 다른 프로세스를 진행한다.
◦ 여기서 중요한 점은, 각각의 프로세스가 끝나지 않았음에도(프로그램을 완료하지 않았음에도) 불구하고 다른 프로세스로
바뀐다는 점이다.
◦ 프로세스에 대한 정보를 백업하고 진행할 다른 프로세스의 정보를 복원하는 일을 context switching이라 한다.
9.
프로세스
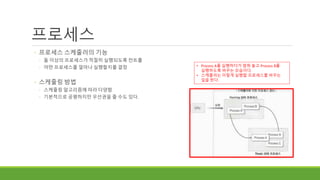
◦ 프로세스 스케줄러의기능
◦ 둘 이상의 프로세스가 적절히 실행되도록 컨트롤
◦ 어떤 프로세스를 얼마나 실행할지를 결정
◦ 스케줄링 방법
◦ 스케줄링 알고리즘에 따라 다양함
◦ 기본적으로 공평하지만 우선권을 줄 수도 있다.
• Process A를 실행하다가 멈춰 놓고 Process B를
실행하도록 바꾸는 모습이다.
• 스케줄러는 이렇게 실행할 프로세스를 바꾸는
일을 한다.
10.
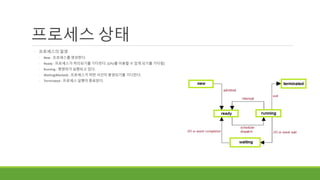
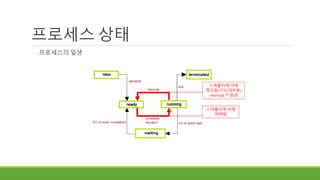
프로세스 상태
◦ 프로세스의일생
◦ New : 프로세스를 생성한다.
◦ Ready : 프로세스가 처리되기를 기다린다. (CPU를 이용할 수 있게 되기를 기다림)
◦ Running : 명령어가 실행되고 있다.
◦ Waiting(Blocked) : 프로세스가 어떤 사건이 발생되기를 기다린다.
◦ Terminated : 프로세스 실행이 종료된다.
11.
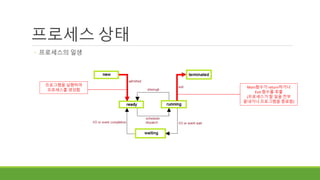
프로세스 상태
◦ 프로세스의일생
프로그램을 실행하여
프로세스를 생성함
Main함수가 return하거나
Exit 함수를 호출
(프로세스가 할 일을 전부
끝내거나 프로그램을 종료함)
12.
프로세스 상태
◦ 프로세스의일생
스케줄러에 의해
채택됨
스케줄러에 의해
중단됨(거의 대부분)
Interrupt 가 발생
13.
프로세스 상태
◦ 프로세스의일생
오래 걸리는 일(I/O 등)을 마치기를 기다림
이벤트가 발생하기를 기다림
오래 걸리는 일이 끝남
기다리던 이벤트가 발생 함
14.
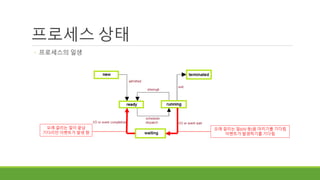
프로세스 상태
◦ 일반적인프로세스 관리 모습
◦ 시나리오 1
◦ 진행하고 있던 프로세스에게 할당된 시간이 다 되면 알람이 울린다.
◦ 알람을 받으면 진행하던 프로세스를 ready queue의 맨 끝에 넣는다.
◦ Ready queue의 맨 앞에 있는 프로세스의 데이터를 복원하고 실행한다.
15.
프로세스 상태
◦ 일반적인프로세스 관리 모습
◦ 시나리오 2
◦ 진행하고 있던 프로세스가 I/O 작업을 요청한다.
◦ I/O작업이 완료된 후 완료되었다는 메시지를 보낼 때까지 waiting(block)한다.
◦ Block 상태 : 아무것도 하지 않고 멈춰 있음
◦ Ex) scanf시 아무것도 입력하지 않으면 입력 값과 엔터가 들어올 때까지 기다리는 것이 블록 상태에 들어간 것임.
◦ Ready queue의 맨 앞에 있는 프로세스의 데이터를 복원하고 실행한다.
16.
프로세스 상태
◦ 일반적인프로세스 관리 모습
◦ 시나리오 3
◦ I/O를 요청해서 block 상태에 들어간 어떤 프로세스가 I/O가 완료되었다는 메시지를 받았다.
◦ Block상태를 빠져나와 ready queue의 맨 끝에 들어간다.
17.
Context Switching
◦ Contextswitching
◦ 실행중인 process에 대한 정보를 백업, 다른 process를 복원하는 것
◦ A 프로세스가 ready상태로 바뀔 때 메모리에 A의 데이터를 저장한다.
◦ B 프로세스가 running 상태로 바뀔 때, B가 백업해 둔 데이터를 복원한다.
◦ 레지스터에 한정된 것은 아님
◦ Context switching은 비싸다. (오래 걸림)
◦ 메모리 ~ 레지스터 사이의 데이터 이동도 I/O이다. I/O는 비싸다.
◦ 최소한으로 하고싶음
◦ 하지만 동시에 다수의 프로세스를 실행하고 싶다면 골고루 실행해야 한다
◦ ->최소 비용으로 적당한 기회를 나눠 가질 수 있도록 하는 것이 스케줄링의 issue
18.
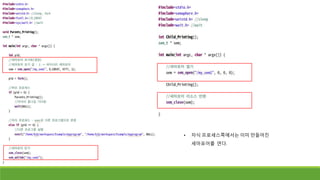
프로세스를 이용한 동시성프로그래밍 – UNIX
◦ fork와 exec 계열 함수를 이용한다.
◦ fork 함수
◦ Unix에서 새로운 프로세스를 생성하는 유일한 함수
◦ fork함수를 호출한 프로세스의 복제본을 생성한다
◦ 호출한 프로세스와 똑같은 프로세스를 생성한다.
◦ fork 함수를 호출하여 프로세스를 만들어준 쪽을 부모 프로세스, 만들어진 프로세스를 자식 프로세스라 한다.
◦ 함수 반환 값은 PID이다.
◦ PID란 프로세스 id로, 각 프로세스마다 부여되는 고유 번호이다. (겹치지 않음)
◦ exec계열 함수
◦ 프로세스의 정보를 다른 프로그램 것으로 바꾼다.
◦ fork함수로 만들어진 프로세스의 메모리 이미지를 변경
◦ 실제로 unix에서 프로그램을 실행할 때는 fork로 복제한 뒤 exec계열 함수로 실행할 프로그램의 데이터
로 바꾼다.
19.
프로세스를 이용한 동시성프로그래밍 – UNIX
◦ fork 함수
◦ 함수 원형 : pid_t fork(void);
◦ pid_t는 signed int형을 typedef로 정의한 것
◦ 큰 프로젝트에서는 typedef를 이용하여 자료형 이름을 재정의한다. (익숙해 져야 함)
◦ 호출한 부모 프로세스와 똑같은 프로세스를 복사하는 함수
◦ 반환 값
◦ 부모 프로세스와 자식 프로세스에서의 반환 값이 다름->이걸로 부모와 자식을 구별
◦ 부모 프로세스는 이 함수의 return value로 자식 프로세스의 pid를 얻는다.
◦ 자식 프로세스는 이 함수의 return value로 0을 얻는다.
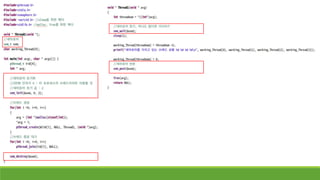
프로세스를 이용한 동시성프로그래밍 – UNIX
Fork함수를 호출하면 똑같은
데이터와 코드를 가진
프로세스가 복사된다.
자식 프로세스는 fork함수의
return value를 얻는 코드부터
시작한다.
<부모 프로세스> <자식 프로세스>
22.
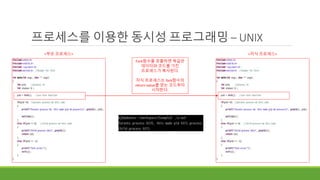
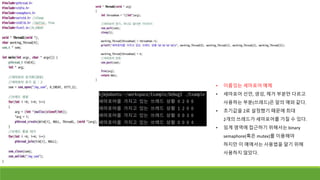
프로세스를 이용한 동시성프로그래밍 – UNIX
<부모 프로세스> <자식 프로세스>
부모 프로세스와 자식 프로세스에서의 fork
함수 반환 값이 다르다.
반환 값을 이용하여 부모와 자식이 다른
메시지를 프린트하도록 만들었다.
부모 부모
자식
fork
23.
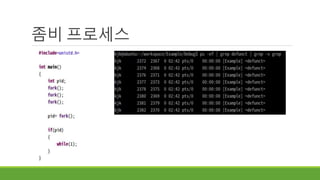
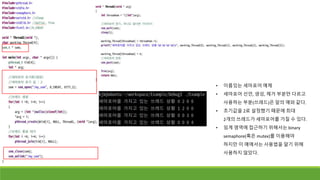
프로세스를 이용한 동시성프로그래밍 – UNIX
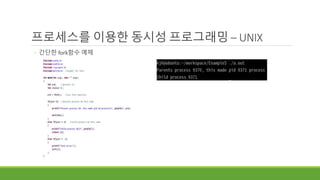
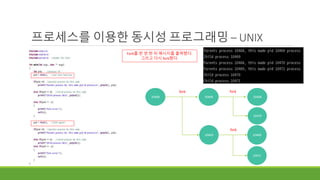
10468
10469
fork
Fork를 한 번 한 뒤 메시지를 출력했다.
그리고 다시 fork했다.
10470
10468 10468
10469
10471
fork
fork
24.
프로세스를 이용한 동시성프로그래밍 – UNIX
◦ exec 계열 함수
◦ 프로세스의 정보를 다른 프로그램 것으로 바꾸는 함수
◦ 주로 fork함수 다음에 이용 – fork함수로 만든 새 프로세스의 메모리 이미지를 다른 프로그램을 위한 것으로 변경한다.
◦ 프로세스를 다른 프로그램을 위한 프로세스로 바꿔 치기 한다 생각하면 됨
25.
프로세스를 이용한 동시성프로그래밍 – UNIX
◦ exec 계열 함수
◦ 종류
◦ 어떤 방식으로 실행할 프로그램을 찾는가에 따라
◦ main함수에 인자를 어떻게 넣는가에 따라
◦ 환경 변수를 어떻게 넘기는가에 따라
◦ l, v : argv인자를 넘겨줄 때 사용
◦ main함수 인자를 l일 경우는 char *로 하나씩
◦ v일 경우는 char *[]로 배열로
◦ e : 환경변수를 넘겨줄 때 사용
◦ 환경 변수를 char * []로 배열로 넘겨 줌
◦ p : 환경변수 path를 참조하기 때문에 절대 경로를 입력하지 않아도 됨
26.
프로세스를 이용한 동시성프로그래밍 – UNIX
◦ 간단한 execl함수 예제
◦ 현재 프로그램을 ls 프로그램으로 변경한다. (리눅스 명령어 ls도 ls 기능을 하는 프로그램을 실행하는 것임)
27.
프로세스를 이용한 동시성프로그래밍 – UNIX
◦ 간단한 execl함수 예제
◦ 내가 만든 다른 프로그램을 자식 프로세스가 실행하게 만드는 프로그램
◦ 실제로 프로그램을 실행할 때 이런 방식으로 실행함
실행
28.
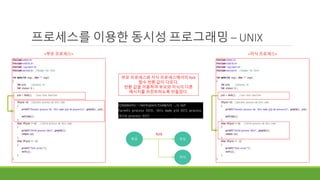
프로세스를 이용한 동시성프로그래밍 – UNIX
Fork해서 복사한 프로세스를 다른
프로그램의 프로세스로 변경했다.
부모 프로세스는 그대로 fork 아래
코드를 실행하여 메시지를 출력한다.
29.
좀비 프로세스
◦ 좀비프로세스
◦ 실행이 종료되었지만 아직 완전히 삭제되지 않은 프로세스
◦ Exit status(main함수에서 return한 값 혹은 exit 함수에 인자로 준 값)와 PID는 커널에 유지된다.
◦ 그래서 부모 프로세스가 자식 프로세스의 종료 상태 등을 알아낼 수 있다.
◦ 좀비 프로세스는 부모 프로세스의 실행이 끝나야 없어진다.
◦ 잠깐 쓰는 프로그램은 괜찮지만, 서버처럼 계속 실행해야 하는 프로그램에서는 문제가 된다.
◦ Wait 함수를 호출하면 찌꺼기 데이터들(좀비 프로세스)을 없앨 수 있다.
◦ 좀비 프로세스를 만들지 않기 위해 Wait 함수를 꼭 호출해 주자.
프로세스의 구현
◦ 프로세스를구현하기 위해서 운영체제는 프로세스 제어 블록(Process Control Block, PCB)이라는 테
이블을 각 프로세스마다 하나씩 가지도록 한다.
◦ OS가 프로세스를 위해서 관리하는 자료구조이다.
◦ 프로세스가 쫓겨날 때, 후에 이어서 실행할 수 있도록 하기 위해 필요한 정보들이 있다.
◦ 오른쪽은 일반적인 PCB의 구조이다.
◦ 레지스터에 있던 값들, 연 파일 등..
◦ PCB는 운영체제가 관리한다.
32.
프로세스의 구현
◦ 멀티프로세스를 관리하는 모습이다.
◦ PCB 를 모아두는 테이블이 있고, 그 테이블에는 해당 PCB의 주소가 저장되어 있다.
◦ 테이블에서 해당 프로세스의 PCB를 찾아 접근한다.
◦ 옆의 그림처럼 PID를 인덱스삼아 찾을 수도 있다.
◦ 프로세스를 구현하는 방식은 OS에 따라 다름
◦ 하지만 그 일반적인 개념(PCB를 만들고, process table로 관리하는 등)은 같다.
33.
프로세스 계층 구조
◦계층 구조
◦ UNIX는 부모와 자식 프로세스가 계층 구조를 이룬다.
◦ 컴퓨터를 부팅했을 시 init이라 불리는 특별한 프로세스가 실행된다. UNIX에서 실행되는 모든 프로그램은 이 프로세스의
자식이다.
◦ 부모와 그 후손들은 모두 프로세스 그룹을 형성한다.
◦ 시그널(ctrl + C등을 입력하면 프로그램이 종료하는 것도 시그널의 일종임. 예외처리에서 다룰 것)은 대상이 된 프로세
스와 그 프로세스가 속한 프로세스 그룹에 전부 전달된다.
◦ Windows는 UNIX와 다르게 계층 구조가 두드러지지 않는다.
◦ 부모 자식이 있긴 하지만, UNIX만큼 두드러지지는 않는다.
◦ 부모 자식 관계에 주어지는 특권은 다른 프로세스 와도 가질 수 있다.
34.
프로세스간 공유, 제어
◦데이터를 공유하거나 다른 프로세스를 제어하고 싶다.
◦ 각 프로세스는 고유의 가상 메모리를 이용한다.
◦ 이 가상 메모리가 같은 물리 메모리를 가리키게 한다면 쉽게 공유할 수 있겠지만, 대부분의 상황에서 이를 허용하지 않는다.
◦ 쉽게 공유할 수 없게 해야 프로그램의 안정성을 보장할 수 있다.
◦ 따라서 프로세스간 공유나 제어를 하기 위한 매커니즘을 만들었다.
◦ 프로세스 간 통신(Inter-Process Communication, IPC)이라고 한다.
35.
프로세스간 공유, 제어- 파일
◦ 일반 파일을 이용한 공유
◦ 매우 단순하고 직관적인 공유이다.
◦ 특정 프로세스가 어떤 파일에 데이터를 쓰면, 다른
프로세스가 그 데이터를 이용할 수 있다.
◦ IPC의 많은 것들이 파일을 이용한 공유와 유사하다.
◦ 특수한 파일을 만들고 공유한다고 생각하면 이해가 쉽다.
36.
프로세스간 공유, 제어– 신호(signal)
◦ 어떤 이벤트가 발생하면 해당 이벤트의 주인이 되
는 프로그램에게 신호를 보낸다.
◦ 각종 예외적인 상황을 처리하기 위해, 또는 프로세
스끼리 신호를 보내기 위해 있다.
◦ 구체적인 이용 방법은 예외처리에서 할 것임
◦ Ex) Ctrl + C를 누르면 해당 프로세스에게 시그널이 전달된다. 시
그널은 고유 번호가 있는데, Ctrl + C에 해당되는 번호를 받는다
면 default로 프로그램을 종료한다.
◦ 프로그램에서 설정을 하면 Ctrl + C 를 눌렀을 때 다른 일을 할
수도 있다.
◦ UNIX에서 많이 쓰인다. Windows는 상대적으로 덜
사용한다.
프로세스간 공유, 제어– 소켓
◦ 보통 외부 컴퓨터의 프로세스와 통신할 때 이용
◦ 네트워크
◦ 내부 프로세스간 통신에도 이용 가능하다.
39.
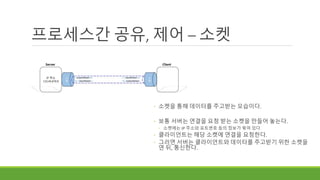
프로세스간 공유, 제어– 소켓
◦ 소켓을 통해 데이터를 주고받는 모습이다.
◦ 보통 서버는 연결을 요청 받는 소켓을 만들어 놓는다.
◦ 소켓에는 IP 주소와 포트번호 등의 정보가 묶여 있다
◦ 클라이언트는 해당 소켓에 연결을 요청한다.
◦ 그러면 서버는 클라이언트와 데이터를 주고받기 위한 소켓을
연 뒤, 통신한다.
40.
프로세스간 공유, 제어– 메시지 큐
◦ 각 프로세스 혹은 쓰레드가 자신에게 온 메시지를
큐에 넣어두고, 읽어올 수 있는 매커니즘
◦ 윈도우는 모든 쓰레드에 메시지 큐가 존재한다.
41.
프로세스간 공유, 제어– 메시지 큐
◦ 옆은 윈도우 메시지 구조 그림이다.
◦ 이벤트 뿐만 아니라 IPC로도 이용된다.
◦ 프로세스간 메시지를 주고받는다.
42.
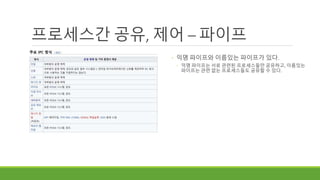
프로세스간 공유, 제어– 파이프
◦ 익명 파이프와 이름있는 파이프가 있다.
◦ 익명 파이프는 서로 관련된 프로세스들만 공유하고, 이름있는
파이프는 관련 없는 프로세스들도 공유할 수 있다.
43.
프로세스간 공유, 제어– 파이프
◦ 수도 파이프와 비슷하다.
◦ 입구와 출구가 있어서 한 프로세스는 쓰기만 하고, 한 프로세스
는 읽기만 한다.
◦ 이러한 특징을 Half-duplex 통신(반이중 통신)이라고 한다.
◦ 이런 특징때문에 두 프로세스가 주고받기 위해서는 두 개의 파
이프가 필요하다.
44.
프로세스간 공유, 제어– 공유 메모리
◦ 보통 프로세스에서 사용되는 메모리 영역은 해당
프로세스만이 사용할 수 있다.
◦ 하지만 특별히 공유 메모리를 생성하여 공유할 수 있다.
◦ IPC 중 가장 빠른 수행 속도를 보인다.
◦ 단순히 메모리에 쓰기만 하면 되니까
◦ 하나의 프로세스가 접근 중일 때, 또 다른 프로세스
가 접근하면 데이터가 훼손될 수 있다.
◦ 한 번에 하나의 프로세스가 메모리에 접근하도록 해야 한다.
◦ Semaphore 등 공유 자원 제어 도구를 이용해야 한다.
45.
프로세스간 공유, 제어– 공유 메모리
◦ 각자의 가상 메모리가 같은 물리 메모리를 가리키
도록 매핑한다.
◦ 공유 메모리를 생성하기 위해서는 API를 이용하여
커널에게 요청해야 한다.
46.
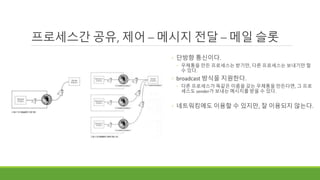
프로세스간 공유, 제어– 메시지 전달 – 메일 슬롯
◦ 윈도우에서 두드러지는 IPC이다.
◦ 쉽게 말해, 우체통을 만든다.
◦ 다른 프로세스는 해당 우체통에 메일을 보낼 수 있다.
◦ 우체통을 만든 프로세스는 메일을 꺼내서 볼 수 있다.
47.
프로세스간 공유, 제어– 메시지 전달 – 메일 슬롯
◦ 단방향 통신이다.
◦ 우체통을 만든 프로세스는 받기만, 다른 프로세스는 보내기만 할
수 있다.
◦ broadcast 방식을 지원한다.
◦ 다른 프로세스가 똑같은 이름을 갖는 우체통을 만든다면, 그 프로
세스도 sender가 보내는 메시지를 받을 수 있다.
◦ 네트워킹에도 이용할 수 있지만, 잘 이용되지 않는다.
48.
프로세스간 공유, 제어
◦신호(signal) -> 예외처리에서 다루겠음
◦ 메시지 큐, 파이프, 공유 메모리 등 -> 네트워크 프로그래밍에서 다루겠음
◦ 네트워크 프로그래밍은 통신 뿐만 아니라 여러 동시성 이슈를 처리하는 일도 중요하게 다룬다.
◦ 여러 클라이언트에게 동시에 서비스를 제공해야 하기 때문
◦ OS/시스템에서는 동시성 이슈 위주로 보고, 네트워크 이론을 공부한 뒤 TCP/IP에 대해 자세히 다루겠음
쓰레드
◦ 한 프로그램내에서도 여러 흐름이 있을 수 있다.
◦ 예) 게임은 HP, MP, 경험치를 관리해야 한다. 또한 캐릭터가 움직이게 해야 한다. 몹도 움직이고 공격해야 한다. 버튼을 누르면 메뉴를 띄워야 한다.
◦ 이것을 여러 자식 프로세스를 생성하여 해결하면 어떨까?
◦ 컨텍스트 스위칭이 너무 비싸다
◦ 성능 저하의 원인이 된다
◦ ->어떻게 해결할 수 있을까? : 저장하고 복원하는 컨텍스트 정보의 개수를 줄여주면 된다.
◦ 공유가 어렵다
◦ 관련된 프로세스끼리 많은 정보를 공유할 필요가 있다. IPC를 이용하기엔 부담스럽다.
◦ ->어떻게 해결할 수 있을까? : 특별한 통신 없이도 공유 할 수 있게 해주면 된다.
◦ 한 프로그램 내에서의 흐름을 만들기 위해 프로세스를 이용하는 것은 부담스럽다.
◦ 프로세스 A와 프로세스 B가 완전히 별개가 아닌 50% 정도만 별개이고, 나머지 50%는 공유하는 구조라면, 컨텍스트 스위칭 시 저장하고 복원하는 정보도
반으로 줄지 않을까?
◦ ->이러한 생각을 기반으로 쓰레드가 생겼다.
51.
쓰레드
◦ 쓰레드란?
◦ 프로세스의컨텍스트 내에서 돌아가는 논리 흐름
◦ 하나의 프로그램 내에서 둘 이상의 프로그램 흐름을 만들어 내기 위해 디자인 된 것
◦ 프로세스와의 비교
◦ 쓰레드는 하나의 프로그램 내에서 여러 개의 실행 흐름을 두기 위한 모델이다.
◦ 쓰레드는 프로세스처럼 완벽히 독립적인 구조가 아니다.
◦ 쓰레드들 사이에는 공유하는 요소들이 있다.
◦ 공유하는 요소가 있기 때문에 컨텍스트 스위칭에 걸리는 시간이 프로세스보다 짧다.
52.
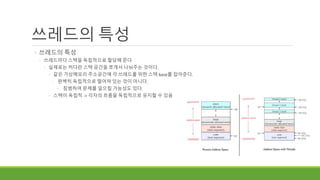
쓰레드의 특성
◦ 쓰레드의특성
◦ 쓰레드마다 스택을 독립적으로 할당해 준다
◦ 실제로는 커다란 스택 공간을 쪼개서 나눠주는 것이다.
◦ 같은 가상메모리 주소공간에 각 쓰레드를 위한 스택 base를 잡아준다.
◦ 완벽히 독립적으로 떨어져 있는 것이 아니다.
◦ 침범하여 문제를 일으킬 가능성도 있다.
◦ 스택이 독립적 -> 각자의 흐름을 독립적으로 유지할 수 있음
53.
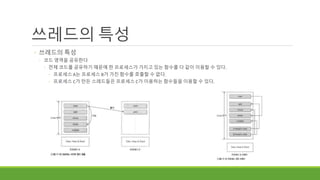
쓰레드의 특성
◦ 쓰레드의특성
◦ 코드 영역을 공유한다
◦ 전체 코드를 공유하기 때문에 한 프로세스가 가지고 있는 함수를 다 같이 이용할 수 있다.
◦ 프로세스 A는 프로세스 B가 가진 함수를 호출할 수 없다.
◦ 프로세스 C가 만든 스레드들은 프로세스 C가 이용하는 함수들을 이용할 수 있다.
54.
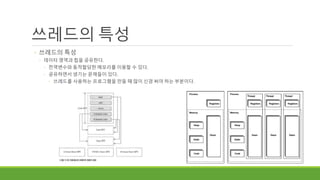
쓰레드의 특성
◦ 쓰레드의특성
◦ 데이터 영역과 힙을 공유한다.
◦ 전역변수와 동적할당한 메모리를 이용할 수 있다.
◦ 공유하면서 생기는 문제들이 있다.
◦ 쓰레드를 사용하는 프로그램을 만들 때 많이 신경 써야 하는 부분이다.
55.
커널 레벨 쓰레드와유저 레벨 쓰레드
◦ 쓰레드를 누가 관리해 주는가에 따라 분류할 수 있다
◦ 커널 레벨 쓰레드
◦ OS가 직접 쓰레드를 관리해 준다.
◦ OS가 쓰레드를 지원하는 경우에만 이용 가능하다.
◦ 쓰레드 생성, 삭제해 주고, 스케줄링 해 준다.
◦ 쓰레드 생성을 위해 시스템 함수를 호출해야 한다.
◦ 유저 레벨 쓰레드
◦ OS가 쓰레드를 지원하지 않을 경우에 이용 가능하다.
◦ 그렇다고 지원하지 않을 때만 이용하는 것은 아니다. 유저 레벨 쓰레드만의 장점이 있다.
◦ 커널에 의존적이지 않은 형태로 쓰레드의 기능을 제공하는 라이브러리를 이용한다.
56.
커널 레벨 쓰레드와유저 레벨 쓰레드
◦ 커널 레벨 쓰레드
◦ 커널 영역에 쓰레드의 정보가 있다.
◦ OS가 직접 쓰레드를 스케줄링 해 준다.
◦ 장점
◦ 커널이 직접 관리해 주기 때문에 안전성이 있고, 다양한 기능이 제공된다.
◦ 단점
◦ 커널에서 제공해주는 기능이기 때문에 유저 모드와 커널 모드의 전환이 빈번히 일어난다.
◦ 성능이 저하된다.
◦ 유저 레벨 쓰레드
◦ 유저 영역에 쓰레드의 정보가 있다.
◦ 커널은 프로세스만 스케줄링 해 준다.
◦ 프로세스가 직접 쓰레드를 관리한다.
◦ 장점
◦ 쓰레드 스케줄링을 위해 유저 모드에서 커널 모드로 전환할 필요가 없다.
◦ 성능이 좋다
◦ 단점
◦ 한 쓰레드가 블록 상태에 들어가야 한다면 OS에서는 그 쓰레드가 포함된 프로세스 A 전체가 블록 된다
◦ 커널 레벨 쓰레드는 프로세스 A의 한 쓰레드가 블록 됐을때, 프로세스 A의 다른 쓰레드를 실행할 수 있다. (프로세스 A의 한 스레드만 블록되지 전체가 블록 되지는 않는다)
◦ 커널 레벨 쓰레드에 비해 프로그래밍, 관리가 어렵다.
57.
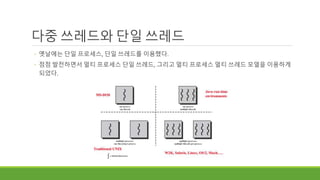
다중 쓰레드와 단일쓰레드
◦ 옛날에는 단일 프로세스, 단일 쓰레드를 이용했다.
◦ 점점 발전하면서 멀티 프로세스 단일 쓰레드, 그리고 멀티 프로세스 멀티 쓰레드 모델을 이용하게
되었다.
58.
쓰레드를 이용한 동시성프로그래밍 - UNIX
◦ pthread 함수 이용
◦ Pthread 함수란 POSIX에 속하는 스레드 함수이다.
◦ POSIX란?
◦ 서로 다른 UNIX OS의 공통 API를 정리하여 이식성이 높은 UNIX
응용 프로그램을 개발하기 위한 목적으로 IEEE가 책정한 규격
◦ 함수 이름과 역할, 인자와 return value 등을 정의해 놓았다.
◦ 각 OS는 이 정의에 맞도록 라이브러리 함수를 만들어야 한다.
◦ 이렇게 함으로써 각 OS의 세부 사항이 다르더라도 하나의
C 코드로 같은 일을 시킬 수 있다.
◦ 호환성 있는 프로그램을 개발하기 위해 만든 규격들이다.
cond
59.
cond
쓰레드를 이용한 동시성프로그래밍 - UNIX
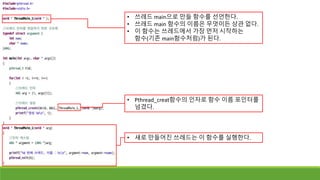
◦ 쓰레드 만들기
◦ pthread_create 함수
◦ 인자 설명
◦ tid : 생성한 쓰레드 ID를 저장할 버퍼 주소
◦ attr : 생성한 쓰레드에게 전달할 입력 인자
◦ start_routine : 쓰레드로 시작할 함수
◦ 함수 포인터
◦ arg : 함수에 넘길 인자
◦ Void 포인터로 받음.
◦ 많은 인자를 주고 싶다면 struct에 넣어 주어야 함
60.
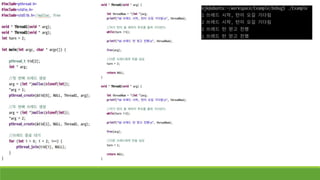
• 간단한 쓰레드생성 예제이다.
• 이 예제가 원하는 일은 생성한 쓰레드가 몇 번째인지 출력하고,
생성된 쓰레드는 자신이 몇 번째 쓰레드인지 출력하고, 인자로
받은 이름을 출력하는 것이다.
• 이 예제는 위와 같이 실행된다고 보장할 수 없다.
61.
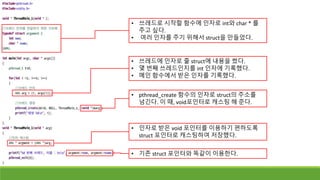
• 쓰레드 main으로만들 함수를 선언한다.
• 쓰레드 main 함수의 이름은 무엇이든 상관 없다.
• 이 함수는 쓰레드에서 가장 먼저 시작하는
함수(기존 main함수처럼)가 된다.
• Pthread_creat함수의 인자로 함수 이름 포인터를
넘겼다.
• 새로 만들어진 쓰레드는 이 함수를 실행한다.
62.
• 쓰레드로 시작할함수에 인자로 int와 char * 를
주고 싶다.
• 여러 인자를 주기 위해서 struct을 만들었다.
• pthread_create 함수의 인자로 struct의 주소를
넘긴다. 이 때, void포인터로 캐스팅 해 준다.
• 쓰레드에 인자로 줄 struct에 내용을 썼다.
• 몇 번째 쓰레드인지를 int 인자에 기록했다.
• 메인 함수에서 받은 인자를 기록했다.
• 인자로 받은 void 포인터를 이용하기 편하도록
struct 포인터로 캐스팅하여 저장했다.
• 기존 struct 포인터와 똑같이 이용한다.
63.
쓰레드를 이용한 동시성프로그래밍 - UNIX
원하는 작업 ?????
• 실행해 보면 어떤 때는 원하는 대로 되고, 어떤 때는 원하는 대로 되지 않는다.
• 대체 왜 이러는 걸까?
• ->쓰레드 실행 순서가 보장되지 않기 때문이다.
64.
쓰레드를 이용한 동시성프로그래밍 - UNIX
• pthread_self 함수는 자신의 쓰레드 id를
반환하는 함수이다.
• 쓰레드를 실행하는 순서가 뒤죽박죽이다.
• 심지어 아래 있는 것은 뒤에 만들어진
쓰레드가 먼저 실행되었다.
• ->이렇게 아무 조치를 취하지 않은
쓰레드는 실행 순서를 보장할 수 없다.
65.
cond
쓰레드를 이용한 동시성프로그래밍 - UNIX
◦ 쓰레드 기다리기
◦ pthread_join 함수
◦ 한 쓰레드가 끝나기를 기다린다.
◦ 프로세스에서 wait함수와 같은 역할이다.
◦ 인자 설명
◦ tid : 기다릴 쓰레드 id
◦ thread_return : 쓰레드가 끝나면서 반환한 값을 저장할 버퍼 주소
◦ 쓰레드 종료하기
◦ 쓰레드는 자신의 최상위 쓰레드 루틴이 리턴할 때 묵시적으로 종료한다.
◦ 혹은 명시적으로 pthread_exit함수를 호출하여 종료한다.
◦ pthread_exit 함수
◦ 쓰레드를 종료 한다.
◦ 이 함수 대신 return을 이용해도 된다.
◦ 주의
◦ exit()함수는 프로세스를 종료하는 함수이다. 쓰레드를 종료하겠다고 이
함수를 호출하면 프로세스가 종료된다. 실수하지 않게 주의하자.
◦ 인자 설명
◦ retval : return 할 값
66.
• 생성한 쓰레드하나가 종료되어야 다음 쓰레드를 생성한다.
• 이제 순서가 맞춰진다.
• 쓰레드 반환 값을 이용하는 방법도 알 수 있다.
67.
쓰레드를 이용한 동시성프로그래밍 - UNIX
◦ 쓰레드 분리하기
◦ 쓰레드는 연결 가능(joinable)하거나 분리되어(detached) 있다.
◦ Joinable
◦ 다른 쓰레드에 의해 청소되고 종료될 수 있다.
◦ 자신의 메모리 자원들은 다른 쓰레드에 의해 청소될 때까지는 반환되지 않는다.
◦ 청소해 주지 않으면 메모리 누수가 생길 수 있다.
◦ 명시적으로 소거해 주거나, 분리해야 한다.
◦ Default로 joinable 쓰레드가 생성된다.
◦ Detached
◦ 다른 쓰레드에 의해서 청소되거나 종료될 수 없다.
◦ 자신의 메모리 자원들은 해당 쓰레드가 끝나면 자동으로 반환된다.
◦ Return value를 얻어오는 등의 일은 할 수 없다.
68.
• 쓰레드를 detach하여join할 수 없다.
• Join 함수가 에러에 해당하는 숫자를 return한다.
• Join을 시도한 쓰레드가 detach되어 있을 시 에러
EINVAL을 반환한다.
• EINVAL은 errno.h에 22로 define되어 있다.
69.
쓰레드 프로그램에서 공유변수
◦ 쓰레드는 전역 변수와 힙(동적 할당)을 공유한다.
◦ 이런 공유는 편하지만, 때로는 심각한 문제를 초래한다.
◦ 어떤 문제가 있는지 예제로 살펴보고, 어떻게 해결하는 지 살펴보자.
70.
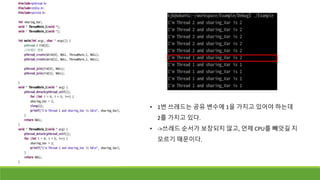
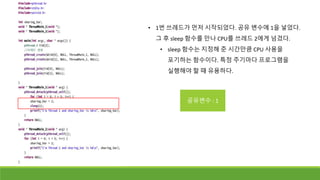
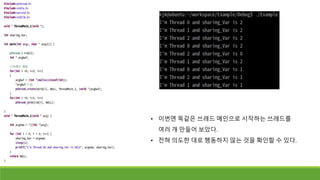
• 1번 쓰레드는공유 변수에 1을 가지고 있어야 하는데
2를 가지고 있다.
• ->쓰레드 순서가 보장되지 않고, 언제 CPU를 빼앗길 지
모르기 때문이다.
71.
• 1번 쓰레드가먼저 시작되었다. 공유 변수에 1을 넣었다.
그 후 sleep 함수를 만나 CPU를 쓰레드 2에게 넘겼다.
• sleep 함수는 지정해 준 시간만큼 CPU 사용을
포기하는 함수이다. 특정 주기마다 프로그램을
실행해야 할 때 유용하다.
공유변수 : 1
72.
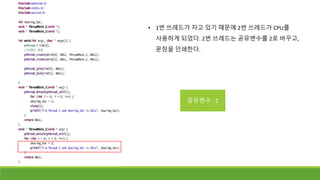
• 1번 쓰레드가자고 있기 때문에 2번 쓰레드가 CPU를
사용하게 되었다. 2번 쓰레드는 공유변수를 2로 바꾸고,
문장을 인쇄한다.
공유변수 : 2
73.
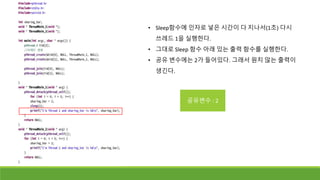
• Sleep함수에 인자로넣은 시간이 다 지나서(1초) 다시
쓰레드 1을 실행한다.
• 그대로 Sleep 함수 아래 있는 출력 함수를 실행한다.
• 공유 변수에는 2가 들어있다. 그래서 원치 않는 출력이
생긴다.
공유변수 : 2
74.
쓰레드 프로그램에서 공유변수
◦ 이 예에서는 일부러 sleep함수를 호출해 상황을 만들었지만, 실제로도 충분히 가능한 상황이다.
◦ 쓰레드에게 할당된 CPU 시간만큼 돌아가면서 쓰는데, 어느 코드에서 시간을 다 쓰고 멈출지 모르기 때문이다.
◦ 문제를 일으킬 가능성이 있는 코드 영역을 크리티컬 섹션, 크리티컬 리전(region)이라고 한다.
◦ 임계구역, 치명적 영역
◦ 위 예에서는 공유변수에 값을 넣는 코드와 printf하는 코드가 크리티컬 섹션이다.
◦ (MS에서 이용하는 동기화 기법도 크리티컬 섹션이라고 부른다. 헷갈림 주의.)
◦ 두 개 이상의 작업이 경쟁하여 사용하는 자원을 경쟁 자원이라 한다.
◦ 위 예에서 sharing_Var에 해당한다.
◦ 두 개 이상의 작업이 경쟁 자원을 사용하려는 상태를 경쟁 상태(Race Condition)이라 한다.
◦ 동기화 오류는 쓰레드 프로그래밍의 중요한 이슈이다.
◦ 이러한 동기화 오류를 막기 위한 여러가지 방법이 있다.
◦ 스핀 락(Spin lock)
◦ 세마포어(Semaphore)
◦ 뮤텍스(Mutex)
◦ 모니터(Monitor)
75.
쓰레드 프로그램에서 공유변수 - 스핀락
◦ 가장 직관적이고 기본적인 제어
◦ 사용 자격을 얻을 때까지 루프를 돌며 기다린다.
◦ 락을 획득할 때까지 해당 쓰레드가 빙빙 돌고있다(spinning)라는 의미에서 스핀락이라는 이름이 붙었다.
◦ 이렇게 CPU를 소모하며 기다리는 것을 busy wating이라고 한다.
◦ 운영체제의 지원을 받지 않고 코드에서 해결할 수 있다.
◦ 문맥 교환(Context switching)이 일어나지 않아 오버헤드가 적다.
◦ 일반적으로 짧은 시간 내에 임계영역에 진입할 수 있는 곳에 이용한다.
◦ 조금만 기다리면 바로 쓸 수 있는데 굳이 컨텍스트 스위칭으로 부하를 줄 필요가 있나? 라는 컨셉
◦ CPU를 소모하며 기다리는 것이므로, 오래 기다려야 하는 경우 비효율적이다.
◦ CPU가 하나뿐일 때는 유용하지 않다.
◦ 이 경우 어차피 컨텍스트 스위칭 해야 하므로
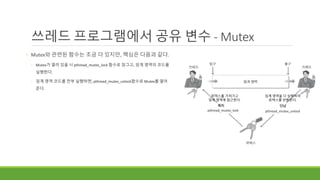
쓰레드 프로그램에서 공유변수 - Mutex
◦ Mutex 이용하기
◦ Mutually Exclusive(상호 배타적)의 약자
◦ 세마포어에 속하는데, 특별히 카운트가 1인 락이다.
◦ 하나의 쓰레드만 임계 영역에 접근할 수 있도록 해준다
◦ Ex)
◦ 열쇠가 하나뿐이다. 열쇠를 얻은 쓰레드는 임계 영역의 코드를 실행할 수 있다.
◦ 열쇠를 누군가가 가지고 있으면 다른 쓰레드들은 임계 영역에 접근할 수 없다.
◦ 열쇠를 가져간 쓰레드가 열쇠를 반환할 때까지 기다려야 한다.
◦ 열쇠를 기다리는 쓰레드들은 block 상태에 들어간다. (자고 있다)
◦ 열쇠를 반환하고, 자고있는 쓰레드 중 하나를 깨운다.
◦ 깬 쓰레드는 다시 열쇠가 있는지 체크한 뒤, 열쇠가 있다면 임계 영역에 들어가
일을 수행한다.
79.
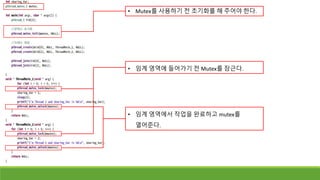
쓰레드 프로그램에서 공유변수 - Mutex
pthread_mutex_unlockpthread_mutex_lock
◦ Mutex와 관련된 함수는 조금 더 있지만, 핵심은 다음과 같다.
◦ Mutex가 열려 있을 시 pthread_mutex_lock 함수로 잠그고, 임계 영역의 코드를
실행한다.
◦ 임계 영역 코드를 전부 실행하면, pthread_mutex_unlock함수로 Mutex를 열어
준다.
임계 영역을 다 실행하여
뮤텍스를 반환한다.
뮤텍스를 가져가고
임계 영역에 접근한다.
80.
cond
쓰레드 프로그램에서 공유변수 - Mutex
◦ pthread_mutex_init
◦ Mutex객체를 초기화한다.
◦ 인자 설명
◦ mutex : 초기화 할 mutex변수
◦ mattr : mutex의 특징을 정의한다. NULL을 넣으면 defaul로 설정됨.
◦ Pthread_mutex_destroy
◦ Mutex를 위해 사용하던 리소스를 해제한다.
◦ Mutex가 더 이상 필요 없을 때는 호출해서 삭제해 주어야 한다.
◦ 리눅스에서는 쓰레드가 종료되어도 mutex객체는 여전히 남아 있으
므로 메모리 누수의 원인이 될 수 있다.
◦ Pthread_mutex_lock
◦ Mutex를 잠그고 임계 영역에 들어간다.
◦ 다른 쓰레드가 뮤텍스 잠금을 얻은 상태라면 잠금을 얻을 수 있을 때까
지 기다리게 된다.
◦ pthread_mutex_unlock
◦ Mutex를 열어서 다른 쓰레드가 임계 영역에 들어갈 수 있게 해준다.
81.
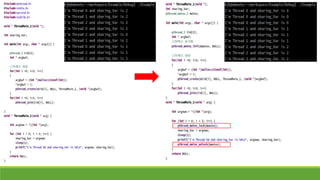
• 두 쓰레드가동시에 같은 공유 변수를 이용하려 했기
때문에 문제가 생겼다.
• 이제 공유 변수에 원하지 않는 값이 들어가는 경우가
없어졌다.
82.
• Mutex를 사용하기전 초기화를 해 주어야 한다.
• 임계 영역에 들어가기 전 Mutex를 잠근다.
• 임계 영역에서 작업을 완료하고 mutex를
열어준다.
83.
• 이번엔 똑같은쓰레드 메인으로 시작하는 쓰레드를
여러 개 만들어 보았다.
• 전혀 의도한 대로 행동하지 않는 것을 확인할 수 있다.
85.
• Mutex때문에 한번에한 쓰레드만 임계 영역에 접근한다.
• 원하는 대로 출력되는 것을 확인할 수 있다.
86.
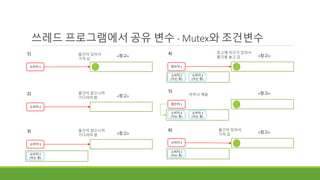
쓰레드 프로그램에서 공유변수 - Mutex와 조건변수
◦ Mutex의 접근제어만으로는 뭔가 부족하다..
◦ 쓰레드는 복잡하게 상호작용이 일어난다.
◦ 어떤 조건이 맞아야 일을 할 수 있는 상황이 생긴다.
◦ Ex)생산자-소비자 문제
◦ 생산자가 물건을 만들어야 소비자가 물건을 가져갈 수 있다. 물건이 없다면 소비자는 기다려야 한다.
◦ 생산자의 창고가 꽉 차면 더 이상 물건을 만들 수 없다. 소비자가 물건을 사서 창고에 공간이 생겨야 새로운 물건을 만들 수 있다.
◦ 조건이 충족될 때까지 기다리고 싶다. 조건이 충족되면 알림을 받고 싶다.
◦ Mutex로 lock을 걸면 한 번에 한 쓰레드만 임계 영역에 접근할 수 있다.
◦ 같은 Mutex를 이용한다는 것은 같은 공유변수를 이용한다는 의미이다. (그렇게 프로그래밍 해야 겠다.)
◦ 위의 예에서, 소비자 쓰레드가 물건을 소비하러 왔다면, 물건이라는 공유 변수에 접근할 것이고, 그러기 위해서 mutex를 닫았을 것이다.
◦ 생산자 쓰레드가 공유 변수에 접근하여 물건을 생산해야 소비자가 일을 끝내고 임계 영역을 나올 수 있는데, mutex가 닫혀 있어 생산자 쓰레드가 접근
할 수 없는 경우가 생길 수 있다.
◦ 이런 상황을 피하기 위해 조건 변수라는 기능을 Mutex와 묶어서 이용할 수 있도록 POSIX 함수가 정의되었다.
87.
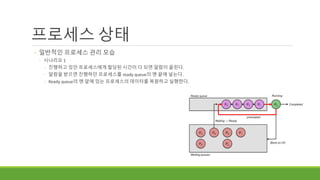
쓰레드 프로그램에서 공유변수 - Mutex와 조건변수
◦ 조건 변수
◦ 공유 데이터에 대한 특정 조건에 따라 쓰레드의 실행을 중지하거나 다시 실행시키는 역할을 하는 동기화 장치
◦ Wait함수와 Signal함수(Linux의 IPC 시그널과는 다르다)를 이용하여 제어한다.
◦ Wait 함수
◦ Wait함수를 실행하면 mutex 잠금을 풀어준다. 그리고 그 쓰레드는 block된다(잠 잔다)
◦ 내부적으로 pthread_mutex_unlock을 호출한다.
◦ 시그널을 받아서 쓰레드가 깨어나면 자동적으로 mutex 잠금을 얻는다.
◦ 내부적으로 pthread_mutex_lock을 호출한다.
◦ 주의!
◦ 자동으로 block 상태가 풀리는 경우가 있으므로 별도의 조건 체크와 루프문을 이용해 주어야 한다.
◦ Signal 함수
◦ Block된 쓰레드를 깨운다.
88.
쓰레드 프로그램에서 공유변수 - Mutex와 조건변수
<창고>
소비자 1
1)
<창고>
소비자 2
2) 물건이 없으니까
기다려야 함
물건이 있어서
가져 감
<창고>
소비자 3
3) 물건이 없으니까
기다려야 함
소비자 2
(자는 중)
<창고>
생산자 1
4) 창고에 자리가 있어서
물건을 놓고 감
소비자 2
(자는 중)
소비자 3
(자는 중)
<창고>
생산자 1
5)
아무나 깨움
소비자 2
(자는 중)
소비자 3
(자는 중)
<창고>
6) 물건이 있어서
가져 감
소비자 2
(자는 중)
소비자 3
89.
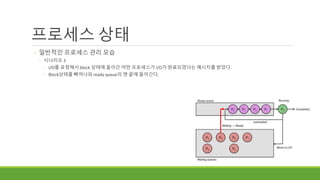
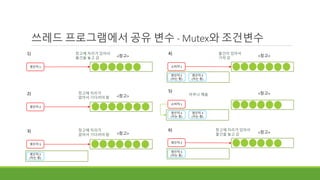
쓰레드 프로그램에서 공유변수 - Mutex와 조건변수
<창고>
생산자 1
1)
<창고>
생산자 2
2) 창고에 자리가
없어서 기다려야 함
<창고>
생산자 3
3)
생산자 2
(자는 중)
<창고>
소비자 1
4) 물건이 있어서
가져 감
생산자 2
(자는 중)
생산자 3
(자는 중)
<창고>
소비자 1
5)
아무나 깨움
생산자 2
(자는 중)
생산자 3
(자는 중)
<창고>
6) 창고에 자리가 있어서
물건을 놓고 감
생산자 3
(자는 중)
생산자 2
창고에 자리가 있어서
물건을 놓고 감
창고에 자리가
없어서 기다려야 함
90.
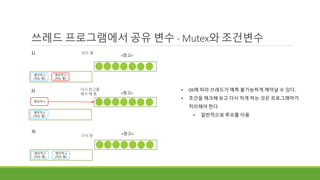
쓰레드 프로그램에서 공유변수 - Mutex와 조건변수
<창고>
1) 자다 깸
생산자 2
(자는 중)
생산자 3
(자는 중)
<창고>
2) 다시 창고를
체크 해 봄
생산자 2
(자는 중)
생산자 3
<창고>
3)
다시 잠
생산자 2
(자는 중)
생산자 3
(자는 중)
• OS에 따라 쓰레드가 예측 불가능하게 깨어날 수 있다.
• 조건을 체크해 보고 다시 자게 하는 것은 프로그래머가
처리해야 한다.
• 일반적으로 루프를 이용
91.
cond
쓰레드 프로그램에서 공유변수 - Mutex와 조건변수
◦ pthread_cond_init
◦ 조건 변수를 초기화한다.
◦ 인자 설명
◦ cond : 조건 변수
◦ cattr : 조건 변수의 특징을 정의한다. NULL을 넣으면 default로 설정됨
◦ pthread_cond_destroy
◦ 조건변수에 할당된 리소스를 해제한다.
◦ pthread_cond_wait
◦ 시그널이 전달되기를 기다린다.
◦ 인자 설명
◦ Cond : 조건 변수
◦ Mutex : mutex
◦ pthread_cond_signal
◦ Cond 인자를 가지고 Wait중인 쓰레드 중 하나를 깨운다.
◦ Pthread_cond_broadcast
◦ cond 인자를 가지고 Wait 중인 모든 쓰레드를 깨운다.
◦ 쓰레드가 다수일 경우 mutex를 먼저 잡은 thread가 먼저 동작되며 나머지는 다
시 잔다.
92.
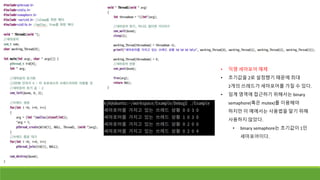
• 일단 쓰레드를생성한다. 생성한 쓰레드는 wait에
걸려서 자고 있다.
• ThreadMain_2를 이용하는 쓰레드가 while문에서
체크하는 조건을 변경하고, 시그널을 보내면 그
때부터 쓰레드가 wait을 빠져나와 일 한다.
93.
• Mutex를 풀지않고 시그널을 보내면 제대로
동작하지 않는 경우가 있다. 주의해야 한다.
• Ex) B 쓰레드가 시그널로 A 쓰레드를 깨웠다.
Unlock하기 전에 A쓰레드를 실행하게 되었다.
그러다 다시 B 쓰레드를 실행하여 Unlock했다.
그래서 C 쓰레드가 실행되었다.
94.
쓰레드 프로그램에서 공유변수 - Semaphore
◦ Semaphore 이용하기
◦ 세마포어란?
◦ 한정된 수의 열쇠가 있다. 열쇠가 있는 쓰레드만이 임계 영역에 접근 가능하다.
◦ 열쇠를 얻지 못 한 쓰레드는 누군가 열쇠를 반환할 때까지 기다린다.
◦ 리소스의 개수가 한 개 이상인 경우에 이용하면 좋다.
◦ 사용하는 방법
◦ 1. 임계 영역을 설정한다.
◦ 2. 임계 영역에 진입하기전에 세마포어 값을 확인한다.
◦ 3. 세마포어 값이 0보다 크면 세마포어를 가져온다. 세마포어를 가져왔으니 세마포어가 1감소 한다.
◦ 세마포어를 가져온 쓰레드는 임계 영역의 코드를 실행할 수 있다.
◦ 4. 세마포어 값이 0이면 값이 0보다 커질 때까지 block 되며, 0보다 커지게 되면 2번 부터 시작하게 된다.
◦ 깨어나면 다시 세마포어 값을 확인하고, 가져올 수 있으면 가져온다.
sem_wait
임계 영역을 다 실행하여
세마포어를 반환한다.
세마포어를 가져가고
임계 영역에 접근한다.
sem_post
95.
쓰레드 프로그램에서 공유변수 - Semaphore
◦ 세마포어 함수는 크게 POSIX 세마포어와 System V 세마포어가 있다.
◦ 몇가지 차이점이 있지만 용도는 같다.
◦ POSIX 세마포어를 사용해 볼 것임
◦ POSIX 세마포어에는 두 종류가 있다.
◦ Named 세마포어와 unnamed 세마포어
◦ Named 세마포어 (이름있는 세마포어)
◦ 이름을 가지고 있어 찾을 수 있다.
◦ 부모자식 관계가 아닌 프로세스 사이에서도 이용할 수 있다.
◦ Unnamed 세마포어 (익명 세마포어)
◦ 한 프로세스 내의 쓰레드끼리 사용하거나, 부모자식 관계의 프로세스끼리 사용한다.
96.
쓰레드 프로그램에서 공유변수 - Semaphore
◦ 관련 헤더 : semaphore.h 관련 라이브러리 : pthread
◦ int sem_init(sem_t *sem, int pshared, unsigned int value)
◦ 익명 세마포어를 만드는 함수
◦ 인자 설명
◦ sem : 초기화 할 세마포어 객체
◦ pshared : 0이면 프로세스 내부에서만 사용한다. 0이 아니면 프로세스들 간에도 공유한다. (자식과의 공유)
◦ value : 세마포어의 초기 값
◦ int sem_destroy(sem_t * sem)
◦ 익명 세마포어를 삭제한다.
◦ 호출하지 않아도, 생성한 프로세스가 종료하면 파괴된다.
97.
쓰레드 프로그램에서 공유변수 - Semaphore
◦ int sem_post(sem_t *sem)
◦ 세마포어를 되돌려 준다.
◦ 세마포어 값이 하나 증가한다.
◦ sem_wait(sem_t *sem)
◦ 세마포어를 얻는다.
◦ 세마포어 값이 0보다 클 때는 세마포어를 얻은 후 세마포어 수를 감소한 뒤 즉시 반환한다.
◦ 세마포어 값이 0이라면 세마포어가 0보다 커지거나 시그널이 발생할 때까지 대기한다.
◦ int sem_getvalue(sem_t *sem, int *sval)
◦ 현재 세마포어의 값을 알아낸다.
◦ 인자 설명
◦ sval : 이 변수에 현재 세마포어의 값이 저장된다.
98.
• 익명 세마포어예제
• 초기값을 2로 설정했기 때문에 최대
2개의 쓰레드가 세마포어를 가질 수 있다.
• 임계 영역에 접근하기 위해서는 binary
semaphore(혹은 mutex)를 이용해야
하지만 이 예에서는 사용법을 알기 위해
사용하지 않았다.
• binary semaphore는 초기값이 1인
세마포어이다.
100.
쓰레드 프로그램에서 공유변수 - Semaphore
◦ sem_t* sem_open(const char* name, int oflag, mode_t mode, unsigned int value)
◦ 이름 있는 세마포어를 만들거나 만들어진 세마포어를 이용하는 함수
◦ 이름 있는 세마포어는 파일로 만들어지기 때문에, 파일 이름과 권한 설정이 필요하다.
◦ 인자 설명
◦ name : 세마포어 이름
◦ oflag : 세마포어를 열 때, 어떤 방식으로 여는가
◦ O_CREAT는 세마포어를 생성할 때, 0을 넣으면 있는 것을 연다.
◦ mode : 접근 권한
◦ oflag에 O_CREATE를 설정했을 때만 의미가 있다.
◦ 파일 접근 권한과 같음
◦ value : 세마포어 초기화
◦ oflag에 O_CREATE를 설정했을 때만 의미가 있다.
◦ int sem_close(sem_t *sem)
◦ 이름있는 세마포어의 할당된 메모리 제거
◦ 단순히 지정된 세마포어와의 연결을 끊음
◦ int sem_unlink(const char *name)
◦ 이름있는 세마포어 자체를 삭제한다.
◦ 해당 세마포어를 다루고 있는 다른 다른 프로세스가 있다면 그 프로세스는 에러가 나게 됨
101.
• 이름있는 세마포어예제
• 세마포어 선언, 생성, 제거 부분만 다르고
사용하는 부분(쓰레드)은 앞의 예와 같다.
• 초기값을 2로 설정했기 때문에 최대
2개의 쓰레드가 세마포어를 가질 수 있다.
• 임계 영역에 접근하기 위해서는 binary
semaphore(혹은 mutex)를 이용해야
하지만 이 예에서는 사용법을 알기 위해
사용하지 않았다.
102.
• 이름있는 세마포어예제
• 세마포어 선언, 생성, 제거 부분만 다르고
사용하는 부분(쓰레드)은 앞의 예와 같다.
• 초기값을 2로 설정했기 때문에 최대
2개의 쓰레드가 세마포어를 가질 수 있다.
• 임계 영역에 접근하기 위해서는 binary
semaphore(혹은 mutex)를 이용해야
하지만 이 예에서는 사용법을 알기 위해
사용하지 않았다.
103.
Semaphore를 이용한 프로세스사이의 제어
◦ 세마포어를 이용하면 다른 프로세스(조금 더 정확하게는 다른 프로세스의 쓰레드)와도 동기화 할
수 있다.
◦ 익명 세마포어는 부모 자식관계의 프로세스에서만 이용 가능하다.
◦ 이름있는 세마포어는 아예 관련이 없는 프로세스 사이에서도 이용 가능하다.
• 파란색은 먼저실행할 프로그램,
빨간 색은 뒤에 실행할 프로그램
• 이번에는 자식 프로세스를 만들지
않고 따로 실행할 것이다.
108.
• putty를 두개 띄우고 각 프로그램을 실행해 보자.
• 혹은 ./Program1 & 로, &를 뒤에 입력하자
• 백그라운드에서 실행한다는 의미로, 실행시킨 뒤
같은 터미널에서 다른 일을 할 수 있다. 같은
터미널에서 ./Program2 할 수 있다.
109.
쓰레드 프로그램에서 공유변수
◦ Mutex와 Semaphore
◦ 차이점 비교
◦ 뮤텍스는 카운트가 1인 바이너리 세마포어라고 볼 수 있다.
◦ 뮤텍스는 열쇠가 하나뿐인 세마포어이다.
◦ 세마포어는 열쇠가 여러 개일 수 있다.
◦ 세마포어는 일반적으로 공유 자원을 프로세스 단위에서 접근하는 것을 관리하기 위해 사용한다.
◦ 한 프로세스에게 주어진 N개의 공유 자원을 여러 쓰레드가 나눠 쓸 수 있도록 하는 등
◦ 뮤텍스는 쓰레드 단위에서 접근하는 것을 관리한다.
◦ 한 번에 한 쓰레드만 공유 변수를 이용하는 등
◦ 가장 큰 차이점은 관리하는 동기화 대상의 개수이다.
◦ 뮤텍스는 동기화 대상이 하나일 때, 세마포어는 하나 이상일 때 사용한다.
110.
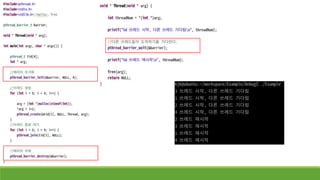
쓰레드 프로그램에서 공유변수 - 배리어
◦ 쓰레드의 싱크를 맞추기 위한 매커니즘
◦ 배리어를 설정한 쓰레드들은 기다리기로 한 숫자만큼의 쓰레드가 도착할 때까지 기다린다.
◦ 기다리는 동안은 block 상태가 된다.
◦ 기다리기로 한 숫자만큼의 쓰레드가 도착하면 다시 ready~run 상태가 된다.
◦ POSIX 함수에 정의되어 있다.
thread
111.
쓰레드 프로그램에서 공유변수 - 배리어
◦ pthread_barrier_init(pthread_barrier_t * restrict_Barrier, const pthread_barrierattr_t * restrict_attr, unsigned int count)
◦ 배리어를 만든다.
◦ 인자 설명
◦ restrict_Barrier : 배리어 변수의 주소
◦ restrict_attr : 설정. NULL을 넣으면 디폴트
◦ count : 배리어에 걸릴 쓰레드 수
◦ pthread_barrier_wait(pthread_barrier_t *barrier)
◦ 배리어를 설치한다.
◦ 싱크를 맞추고 싶은 부분에서 해당 함수를 호출한다.
◦ pthread_barrier_destroy(pthread_barrier_t *barrier)
◦ 배리어를 삭제한다.
Linux vs Windows
•리눅스와 윈도우는 같은 기능에도 약간의 차이가 있다.
object Linux/Unix Windows
File Lock kernel-mode kernel-mode
Critical Section 없음
user-mode
한 프로세스 내에서만 사용가능
Interlock 없음
user-mode
한 프로세스 내에서만 사용가능
Mutex
POSIX 함수
한 프로세스 내에서만 사용가능
하나의 공유자원 동기화에 사용
kernel-mode
프로세스끼리도 사용가능
타임아웃기능 사용가능
하나의 공유자원 동기화에 사용
Semaphore
kernel-mode
POSIX 함수
프로세스끼리도 사용가능
다중 공유자원 동기화에 사용
kernel-mode
프로세스끼리도 사용가능
타임아웃기능 사용가능
다중 공유자원 동기화에 사용
Condition Variable
POSIX 함수
타임아웃기능 사용가능
다중 스레드를 동시에 깨울 수 있음
없음
Event 없음
kernel-mode
프로세스끼리도 사용가능
타임아웃기능 사용가능
다중 스레드나 프로세스를 동시에 깨울 수 있음
115.
쓰레드 safe
◦ 여러쓰레드가 동시에 사용해도 안전하다는 의미
◦ 전역 변수 등 공유하는 리소스를 이용하지 않거나, 이용하더라도 락이 되어있어 안심하고 쓸 수 있는 것
◦ 흔하게 사용하는 API중에는 쓰레드 safe한 것도 있고, unsafe한 것도 있다.
◦ 따라서 멀티 쓰레드 프로그램을 만들 시에는 각 API들이 안전한지 반드시 확인해야 한다.
◦ 리눅스 man page(manual page)에 가면 쓰레드 safe 여부가 적혀 있다.
◦ 구글링하면 금방 나온다.
◦ 리눅스 커널에서 man 명령어를 이용해도 나온다.
◦ Ex) man printf
116.
쓰레드 safe
◦ Threadsafe 함수 중에서도 Reentrant 함수라는 특별한 종류가 있다.
◦ Thread safe 함수는 lock을 걸어(mutex 등) 제어하는 경우도 포함된다.
◦ Reentrant(재진입 가능한) 함수는 Thread safe 함수에 속하지만 Thread safe함수는 Reentrant 함수에 반드시 속하지는 않는다.
◦ Reentrant 함수는 어떤 경우에도 같은 결과를 내는 함수이다.
◦ 전역변수, static 변수를 이용하지 않는다.
◦ lock을 필요로 하지 않는다.
◦ Reentrant 함수이려면 lock을 필요로 하지 않도록 짜여 있어야 한다.
◦ Reentrant한 함수는 보통 이름 뒤에 _r을 붙인다.
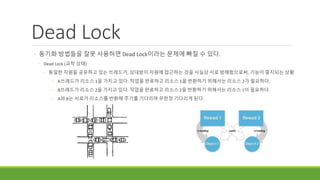
Dead Lock
◦ 동기화방법들을 잘못 사용하면 Dead Lock이라는 문제에 빠질 수 있다.
◦ Dead Lock (교착 상태)
◦ 동일한 자원을 공유하고 있는 쓰레드가, 상대방이 자원에 접근하는 것을 사실상 서로 방해함으로써, 기능이 중지되는 상황
◦ A쓰레드가 리소스 1을 가지고 있다. 작업을 완료하고 리소스 1을 반환하기 위해서는 리소스 2가 필요하다.
◦ B쓰레드가 리소스 2을 가지고 있다. 작업을 완료하고 리소스 2을 반환하기 위해서는 리소스 1이 필요하다.
◦ A와 B는 서로가 리소스를 반환해 주기를 기다리며 무한정 기다리게 된다.
119.
• 이 프로그램을실행하면 아무 것도
출력하지 않고 멈춘다.
• 일부러 dead lock을 만들었다.
120.
• 1번 쓰레드에서mutex1을 lock하고 sleep을 호출하여 block되었다.
• 1번 쓰레드가 block되어 2번 쓰레드에게 CPU가 할당되었다.
• 2번 쓰레드가 mutex2를 lock했다.
• 2번 쓰레드가 바로 다음 코드에서 mutex1을 lock하려고 했지만 이미 1번
쓰레드가 lock을 했다. 그래서 block 상태로 들어간다.
• 1번 쓰레드가 깨어나서 mutex2를 lock하려고 보니 2번 쓰레드가 이미 lock을 했다.
그래서 block 상태로 들어간다.
• mutex를 같은 순서로(mutex 1을 잠그고 mutex2를 잠그는 등) 사용한다면 dead
lock을 피할 수 있다.
• Deadlock은 치명적이다. 이를 피하기 위해 프로그래밍 할 때 많은 신경을
써야 한다.
• 쓰레드 뿐만 아니라 프로세스 사이에서도 일어날 수 있는 일이다.
• 해결하는 현실적인 방법은 어느 한 쪽을 종료하는 것 뿐이다.
121.
Dead Lock
◦ Deadlock은 다음 네 가지 조건이 전부 성립할 때 발생할 수 있다.
◦ 상호배제(Mutual exclusion) : 프로세스들이 필요로 하는 자원에 대해 배타적인 통제권을 요구한다.
◦ 점유대기(Hold and wait) : 프로세스가 할당된 자원을 가진 상태에서 다른 자원을 기다린다.
◦ 비선점(No preemption) : 프로세스가 어떤 자원의 사용을 끝낼 때까지 그 자원을 뺏을 수 없다.
◦ 순환대기(Circular wait) : 각 프로세스는 순환적으로 다음 프로세스가 요구하는 자원을 가지고 있다.
122.
Dead Lock
◦ 각리소스를 한 프로세스만 이용할 수 있고
◦ 상호 배제
◦ 다른 프로세스가 리소스를 놓기를 기다리고
◦ 점유 대기
◦ 다른 프로세스가 가진 리소스를 빼앗을 수 없고
◦ 비선점
◦ 각 프로세스가 순환적으로 다음 프로세스가 요구하는 자원을 가지고 있다
◦ 순환대기
123.
Dead Lock
◦ 어떻게대처하는가?
◦ 무시
◦ dead lock을 찾고, 회복시키기
◦ dead lock이 발생하기 전 상태로 돌아간다.
◦ 저장된 상태를 이용한다.
◦ 리소스를 잘 할당해서 dead lock이 일어나지 않도록 하기
◦ 예방하기
◦ 위의 4가지 조건이 전부 충족되는 일이 없도록 하기
◦ 다른 프로세스가 이용하는 리소스를 빼앗을 수 있게 한다.
◦ 리소스가 없으면 기다리지 않는다.
◦ 리소스에 순서를 매겨서, 순서대로만 요청 가능하게 한다.
◦ ...
◦ 예방하기 위한 알고리즘이 있지만, 보통은 그냥 OS가 dead lock에 걸린 프로그램을 종료한다.
124.
스케줄링
◦ OS는 다음에실행할 프로세스/스레드를 선택해야 한다.
◦ 이같은 선택을 하는 운영체제의 일부분을 스케줄러라 한다.
◦ 스케줄러의 알고리즘을 스케줄링 알고리즘이라 부른다.
◦ 커널이 직접 스레드를 관리하면 스레드가 어느 프로세스에 소속되어 있는지는 고려하지 않고 스
레드 단위로 이루어질 수 있다.
◦ 스케줄링이 필요한 상황
◦ 자식 프로세스를 생성했을 때, 자식 프로세스를 먼저 실행할 지 부모 프로세스를 먼저 실행할 지 결정해야 한다.
◦ 프로세스가 종료되었을 때, 다음에 어떤 프로세스를 실행할 지 결정해야 한다.
◦ 프로세스가 I/O가 완료되기를 기다리거나 다른 무언가 때문에 대기해야 할 때, 다음에 실행할 프로세스를 선택해야 한다.
◦ I/O가 완료되었을 경우, 해당 I/O를 신청했던 프로세스를 다시 실행할 지 다른 프로세스를 실행할 지 결정해야 한다.
125.
스케줄링
◦ 종류
◦ 비선점형스케줄링
◦ I/O때문에 block이 되거나, 다른 프로세스를 기다리기 위해 대기하거나, 자발적으로 CPU를 반환할 때까지 계속 수행할 수 있다. (CPU를 돌아가면서 쓰기 위해 쫓겨나는 일이 없다.)
◦ 실행한 순서대로 처리되는 공정성이 있음
◦ 처리 시간을 예상할 수 있다.
◦ 선점 방식보다 스케줄러 호출 빈도가 낮고 문맥 교환에 의한 오버헤드가 적다.
◦ 일괄 처리 시스템에 적합
◦ CPU 사용 시간이 긴 하나의 프로세스가 CPU 사용 시간이 짧은 여러 프로세스를 오랫동안 대기시킬 수 있으므로, 처리율이 떨어질 수 있음
◦ 선점형 스케줄링
◦ '운영 체제가 프로세서 자원을 선점'하고 있다가 각 프로세스의 요청이 있을 때 특정 요건들을 기준으로 자원을 배분하는 방식
◦ 프로세스를 선택하고 최대 값으로 정해진 시간을 넘지 않는 범위에서 실행되도록 한다.
◦ 여태까지 얘기한 스케줄링(돌아가면서 CPU를 쓰는 것)이 여기에 속함
◦ 어떤 프로세스가 CPU를 할당 받아 실행 중에 있어도 다른 프로세스가 실행 중인 프로세스를 중지하고 CPU를 강제로 점유할 수 있다.
◦ 어떤 프로세스가 CPU를 독차지하는 일이 없으므로 공평하다.
◦ 빠른 응답시간을 요하는 대화식 시분할 시스템에 적합
◦ 긴급한 프로세서를 제어할 수 있다.
126.
스케줄링
◦ 어떻게 프로세스에게일정 시간만큼 할당할 수 있을까?
◦ 하드웨어에서 주기적으로 인터럽트라는 신호를 발생한다.
◦ K번째 클록마다 신호를 보낸다.
◦ OS는 이 신호를 받으면 스케줄러를 호출한다.
127.
스케줄링
◦ 컴퓨터의 용도에따라 적합한 알고리즘을 선택한다
◦ 배치 시스템
◦ 급여, 재고, 미수 계좌, 지급 계좌, 이자 계산, 청구 처리 등 정기적인 작업을 수행하는 시스템
◦ 큰 규모의 일을 정기적으로 하므로 많은 프로세스를 동시에 실행할 필요가 적다.
◦ 비선점형 알고리즘 또는 긴 주기를 제공하는 선점형 알고리즘이 적절
◦ Context switching을 줄여 성능을 향상
◦ 대화식 사용자 환경
◦ 한 프로세스가 CPU를 독점하여 다른 사용자의 서비스를 방해해서는 안 된다.
◦ 선점형 알고리즘이 적합하다.
◦ 서버는 다수의 사용자에게 신속하게 서비스해야 하므로 이 유형에 속한다.
◦ 실시간 제약이 있는 시스템
◦ 바로바로 반응해야 하는 시스템(자동차에 있는 컴퓨터 등)
◦ 마감 시간(dead line)이 있다. 특정 일은 마감 시간 내에 완료해야 한다.
◦ 실시간 시스템에서는 보통 한 프로세스가 하는 일이 많지 않다.
◦ 빨리빨리 끝내고 바로 대기한다.
◦ 당장 필요한 프로그램만 실행한다.
◦ 비선점형이 적합하다. (많은 멀티태스킹이 필요로 하는 환경이 아니기 때문)
128.
스케줄링
◦ 비 선점선입선출(First Come First Served) 알고리즘 (FIFO, FCFS)
◦ 요청 순서대로 CPU를 할당 받음
◦ 하나의 queue에 넣어 관리
◦ Queue : First In First Out 하는 자료구조
◦ 단점
◦ 중요하지 않은 프로세스를 실행하느라 중요한 프로세스를 대기하게 할 수 있다.
◦ I/O가 주가 되는 프로세스(I/O-바운드 프로세스)는 CPU를 잠깐만 쓰면 되는데도 기다려야 한다. (비효율적)
◦ 금방 끝나는 프로세스임에도 다른 프로세스때문에 오래 기다려야 한다.
129.
스케줄링
◦ 비 선점최단 작업 우선(Shortest Job First) 알고리즘 (SJF)
◦ 대기하는 프로세스 중 가장 시간이 적게 걸리는 프로세스를 선택
◦ 매일 비슷한 일을 하는 시스템에서는 프로그램을 실행하고 마치는 데 걸리는 시간을 예측할 수 있다. 그런 시스템에서 사용
할 수 있는 알고리즘이다.
◦ 단점
◦ 오래 걸리는 프로세스는 계속 기다리기만 해야 함
◦ 최단 잔여시간(Shortest Remaining Time Next) 우선 알고리즘
◦ SJF의 선점형 버전
◦ 프로세스의 남은 실행 시간이 가장 짧은 작업을 선택
◦ SJF와 마찬가지로 작업의 실행 시간을 미리 알고있는 환경에서 가능
130.
스케줄링
◦ 라운드 로빈(Round-Robin) 알고리즘
◦ 암묵적으로 모든 프로세스가 똑같이 중요하다는 가정을 함
◦ 각 프로세스에게는 시간 할당량이라 불리는 시간 주기가 할당되며 한 번에 이 시간 동안만 실행
◦ 주기가 커지면 선입선출과 비슷해진다.
◦ 선입 선출의 선점형 버전
◦ 프로세스가 할당 시간이 끝나기 전에 대기하거나 종료하면 다른 프로세스에게 CPU를 준다.
◦ 들어온 순서대로 일정 시간 CPU를 이용, 시간이 끝나면 큐의 맨 뒤로 들어간다.
◦ 단점
◦ Context switching이 많이 일어나 오버헤드가 높다.
◦ 시간 주기를 잘 조정해야 함
131.
스케줄링
◦ 우선순위 스케줄링(Priority Scheduling)
◦ 각 프로세스에 우선순위를 할당
◦ 가장 높은 우선순위를 가진 실행 가능한 프로세스가 다음에 수행된다.
◦ 한 프로세스가 무한히 실행되는 것을 방지할 필요가 있음
◦ 클록 인터럽트마다 현재 실행중인 프로세스의 우선순위를 낮추는 방법
◦ 각 프로세스마다 최대로 실행할 수 있는 할당 시간을 가지는 방법
◦ 할당시간을 다 쓰면 다음으로 우선순위가 높은 프로세스에게 실행 기회를 줌
132.
스케줄링
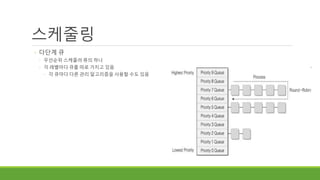
◦ 다단계 큐
◦우선순위 스케줄러 류의 하나
◦ 각 레벨마다 큐를 따로 가지고 있음
◦ 각 큐마다 다른 관리 알고리즘을 사용할 수도 있음
133.
스케줄링
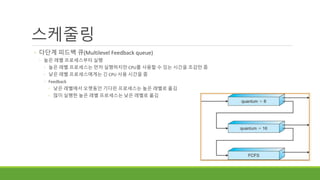
◦ 다단계 피드백큐(Multilevel Feedback queue)
◦ 높은 레벨 프로세스부터 실행
◦ 높은 레벨 프로세스는 먼저 실행하지만 CPU를 사용할 수 있는 시간을 조감만 줌
◦ 낮은 레벨 프로세스에게는 긴 CPU 사용 시간을 줌
◦ Feedback
◦ 낮은 레벨에서 오랫동안 기다린 프로세스는 높은 레벨로 옮김
◦ 많이 실행한 높은 레벨 프로세스는 낮은 레벨로 옮김
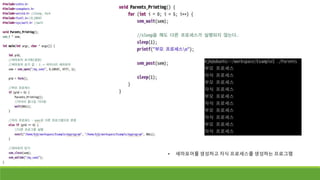
생산자/소비자 문제 프로그래밍
◦생산자는 물건을 1000개 만들었다. 한 번에 하나씩 창고에 옮길 수 있다.
◦ 소비자는 물건을 1000개 사고 싶다. 창고에 있는 물건만 살 수 있다. 한 번에 하나씩 살 수 있다.
◦ 창고에는 최대 100개 넣을 수 있다.
◦ 창고에 물건이 없다면 소비자는 물건이 창고에 들어올 때까지 기다려야 한다.
◦ 창고가 꽉 찼다면 생산자는 소비자가 물건을 사 갈 때까지 기다려야 한다.
◦ 생산자는 물건을 옮길 때마다 printf(“생산자 물건 옮김, 창고에 남은 물건 %d개”, product);
◦ 소비자는 물건을 살 때마다 printf(“소비자 물건 삼, 창고에 남은 물건 %d개”,product); 해야 한다.
◦ 이를 Mutex와 조건변수를 이용하여 프로그래밍 하세요
참고 사이트
◦ Linuxmulti process 프로그래밍 관련
◦ fork와 exec
◦ https://kldp.org/node/545
◦ http://bbolmin.tistory.com/35
◦ Windows multi process 프로그래밍 관련
◦ https://www.joinc.co.kr/w/Site/win_system_prog/multi_process
◦ Linux init 프로세스
◦ https://zetawiki.com/wiki/%EB%A6%AC%EB%88%85%EC%8A%A4_init_%ED%94%84%EB%A1%9C%EC%84%B8%EC%8A%A4
◦ http://www.ktword.co.kr/abbr_view.php?m_temp1=1858
◦ 프로세스, 쓰레드 정리
◦ http://jeemyeong.com/2017-03-27-Operation-9/
◦ http://itdexter.tistory.com/391
138.
참고 사이트
◦ 공유메모리 사용법(리눅스)
◦ https://www.joinc.co.kr/w/Site/system_programing/IPC/SharedMemory
◦ 메시지 큐 사용법(리눅스)
◦ https://www.joinc.co.kr/w/Site/system_programing/IPC/MessageQueue
◦ 시그널(리눅스)
◦ https://www.joinc.co.kr/w/Site/system_programing/Book_LSP/ch06_Signal
139.
참고 사이트
◦ POSIX쓰레드 함수와 사용법
◦ https://www.joinc.co.kr/w/Site/Thread/Beginning/PthreadApiReference
◦ 왜 쓰레드가 예측할 수 없게 wait상태에서 깨는가에 대한 답변
◦ https://stackoverflow.com/questions/8594591/why-does-pthread-cond-wait-have-spurious-wakeups
◦ 세마포어 함수와 사용법
◦ http://yebig.tistory.com/305
◦ 생산자-소비자 문제
◦ https://ko.wikipedia.org/wiki/생산자-소비자_문제
140.
참고 사이트
◦ 배리어함수와 사용법
◦ https://www.daemon-systems.org/man/pthread_barrier.3.html
◦ Thread safe란?
◦ https://kldp.org/node/36904
◦ Thread unsafe한 함수를 찾아주는 쉘 스크립트
◦ http://linuxspot.tistory.com/154
◦ Reentrant vs thread-safe
◦ https://kldp.org/node/18890
◦ http://sunyzero.tistory.com/97













![프로세스를 이용한 동시성 프로그래밍 – UNIX
◦ exec 계열 함수
◦ 종류
◦ 어떤 방식으로 실행할 프로그램을 찾는가에 따라
◦ main함수에 인자를 어떻게 넣는가에 따라
◦ 환경 변수를 어떻게 넘기는가에 따라
◦ l, v : argv인자를 넘겨줄 때 사용
◦ main함수 인자를 l일 경우는 char *로 하나씩
◦ v일 경우는 char *[]로 배열로
◦ e : 환경변수를 넘겨줄 때 사용
◦ 환경 변수를 char * []로 배열로 넘겨 줌
◦ p : 환경변수 path를 참조하기 때문에 절대 경로를 입력하지 않아도 됨](https://image.slidesharecdn.com/systemosstudy3-180519102312/85/System-os-study-3-25-320.jpg)









































































































![[Kerference] 시작! 리버싱 - 김종범(KERT)](https://cdn.slidesharecdn.com/ss_thumbnails/random-160725061046-thumbnail.jpg?width=640&height=640&fit=bounds)























