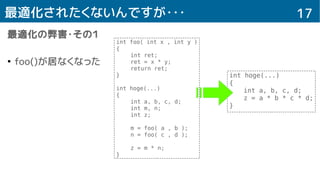
17最適化されたくないんですが・・・
最適化の弊害・その1
●
foo()が居なくなった
int foo( intx , int y )
{
int ret;
ret = x * y;
return ret;
}
int hoge(...)
{
int a, b, c, d;
int m, n;
int z;
m = foo( a , b );
n = foo( c , d );
z = m * n;
}
int hoge(...)
{
int a, b, c, d;
z = a * b * c * d;
}
18.
18最適化されたくないんですが・・・
最適化の弊害・その2
●
foo()が居なくなった
int bar( intx , int y )
{
xとyで複雑な計算;
return 結果;
}
int foo( int x , int y )
{
int ret;
ret = x * y;
return ret;
}
int hoge(...)
{
int a, b, c, d;
int m, n;
int z;
m = foo( a , b );
n = foo( c , d );
z = bar( m , n );;
}
int hoge(...)
{
int a, b, c, d;
int m;
int z;
m = a * b;
n = c * d;
z = bar( m , n );
}
barは残っている

















![19最適化されたくないんですが・・・
最適化の弊害・その3
最適化したら・・・
げげっ!100ステップのステートマシンになってしまった(苦笑)
この処理は時間がかかってもいい処理なんだけど、ループにしてよ。
コンパイラはそんなことにはお構いなく、最適化してしまいます。
将来、関数単位で最適化レベルを調整できるようにするつもり・・・
for(a=0;a<10;a++){
for(b=0;b<10;b++){
c[a*10+b] = a * b;
}
}
c[0] = 0 * 0;
c[1] = 0 * 1;
・・・
c[98] = 9 * 8;
c[99] = 9 * 9;](https://image.slidesharecdn.com/synverll-151209125516-lva1-app6892/85/Synverll-19-320.jpg)




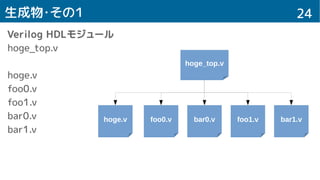
![25生成物・その2
モジュール module RGB2YCbCr(
input __func_clock,
input __func_reset,
input __func_start,
output reg __func_done,
output reg __func_ready,
// Global Memory
input [31:0] __gm_base,
output reg __gm_req,
output reg __gm_rnw,
input __gm_done,
output reg [31:0] __gm_adrs,
output reg [1:0] __gm_leng,
input [31:0] __gm_di,
output reg [31:0] __gm_do,
// Memory Singal
input [31:0] __base_buffer,
input [15:0] __args_xpos,
input [15:0] __args_ypos,
// Call Singal
// Result Singal
output reg __func_result
);
制御信号
メモリー
インターフェース
引数
戻り値](https://image.slidesharecdn.com/synverll-151209125516-lva1-app6892/85/Synverll-25-320.jpg)
![26生成物・その3
メモリマップ
一元化された
メモリマップが
出力される。
======================================================================
Memory Map
======================================================================
[GLOBAL/LOCAL] [MEMORY NAME] [ADDRESS] [SIZE]
GLOBAL @jpeg_ptr 00000000 4
GLOBAL @APP0info 00000004 18
<<<中略>>>
GLOBAL @CbAC_HT 00000808 768
@DCT %datalong 00000b08 256
GLOBAL @DU_DCT 00000c08 128
GLOBAL @zigzag 00000c88 64
GLOBAL @DU 00000cc8 128
@process_DU %calc_data 00000d48 4
@process_DU %1 00000d4c 4
<<<中略>>>
@process_DU %7 00000d64 4
@process_DU %8 00000d68 4
<<<中略>>>
@main_encoder %DCY 00000ef4 2
@main_encoder %DCCb 00000ef8 2
@main_encoder %DCCr 00000efc 2
@main_encoder %DU 00000f00 64
@create_jpeg %fillbits 00000f40 3
======================================================================](https://image.slidesharecdn.com/synverll-151209125516-lva1-app6892/85/Synverll-26-320.jpg)
![27こんなことができる
tempはFPGA内部メモリ、bufはFPGA外部メモリとすることができる
void hoge(char *buf)
{
int i;
char temp[10];
for(i=0;i<10;i++){
tmep[i] = ...;
}
for(i=0;i<10;i++){
buf[i] = temp[i];
}
}
void main()
{
char buf[10];
...
hoge(buf);
...
}
main.c hoge.c](https://image.slidesharecdn.com/synverll-151209125516-lva1-app6892/85/Synverll-27-320.jpg)


![3032bitアーキテクチャ
4Byteアライメント
4Byteアライメントでないメモリアクセスはデータがバグる。
例えば、こんな構造体
struct foo{
char a;
short b;
} S_FOO;
struct hoge{
foo[10];
} S_HOGE;](https://image.slidesharecdn.com/synverll-151209125516-lva1-app6892/85/Synverll-30-320.jpg)






![37アクセラレート
main関数はCPUで稼動さ
せ、hoge関数をFPGAでアクセラ
レートする
void main()
{
char buf[10];
...
#ifdef SOURCE
hoge(buf);
#else
hoge.buf = buf;
while(!hoge.ready);
hoge.start = 1;
while(!hoge.ready);
hoge.start = 0;
while(!hoge.done);
#endif
...
}](https://image.slidesharecdn.com/synverll-151209125516-lva1-app6892/85/Synverll-37-320.jpg)
![38Cテストアプリを使ってシミュレーションしたい
シミュレーション構想
Cソースで使ったテストアプリを
そのまま、使って
実機シミュレーションしたい!
テストベンチをもう一度、
書くのなんて嫌だ!
シミュレータなんて遅いから嫌だ!
void main()
{
char buf[10];
...
#ifdef SOURCE
hoge(buf);
#else
hoge.buf = buf;
while(!hoge.ready);
hoge.start = 1;
while(!hoge.ready);
hoge.start = 0;
while(!hoge.done);
#endif
...
}](https://image.slidesharecdn.com/synverll-151209125516-lva1-app6892/85/Synverll-38-320.jpg)
































































