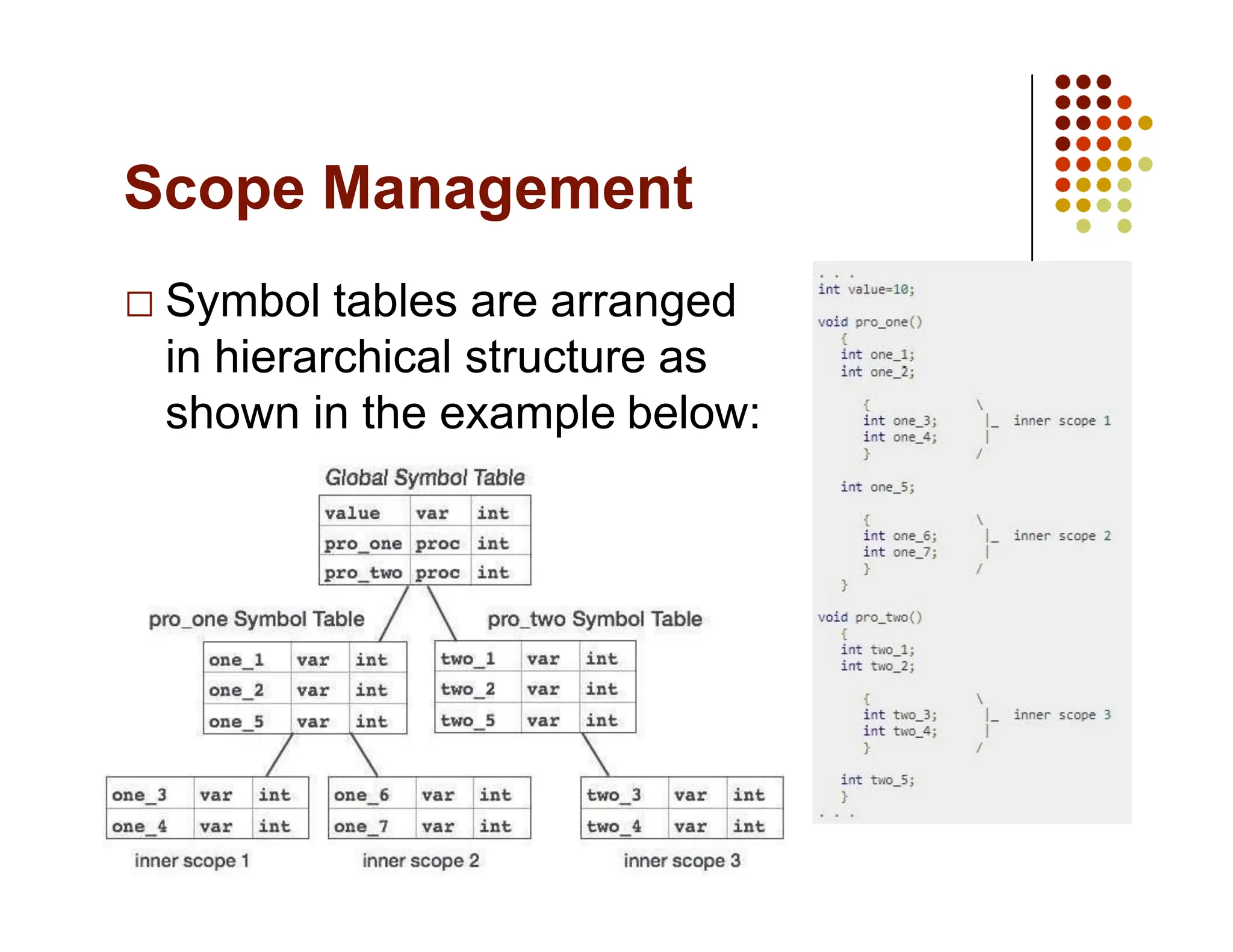
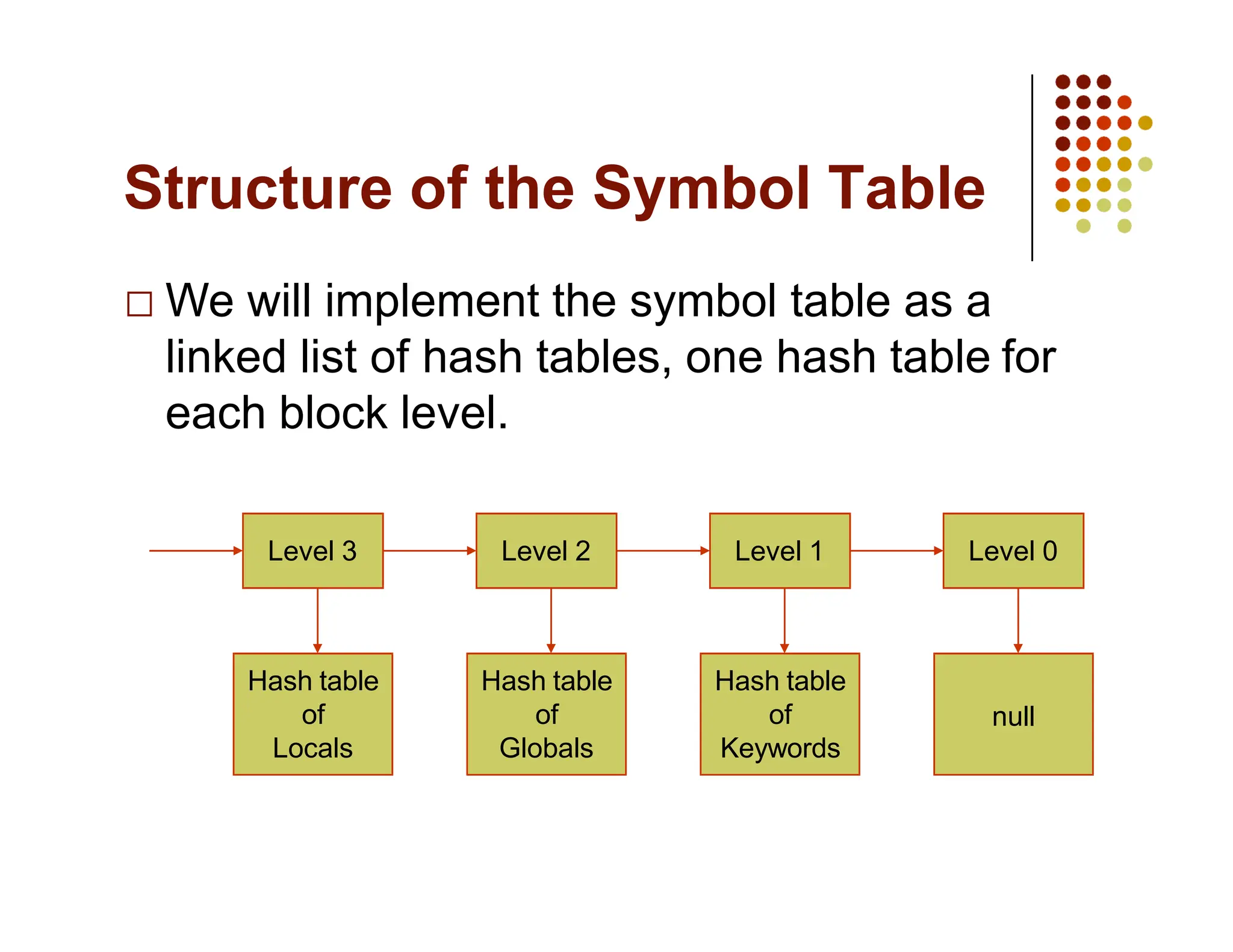
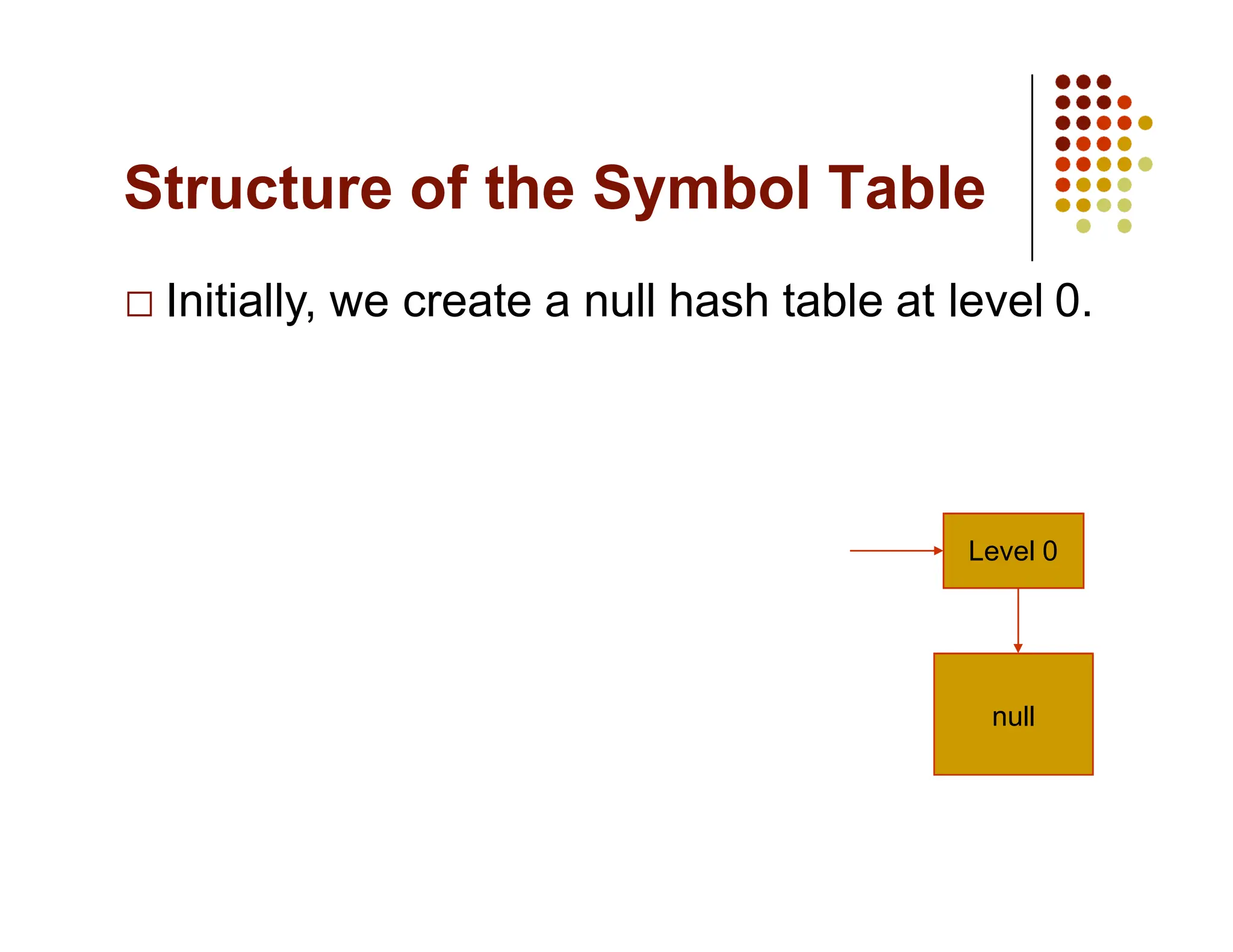
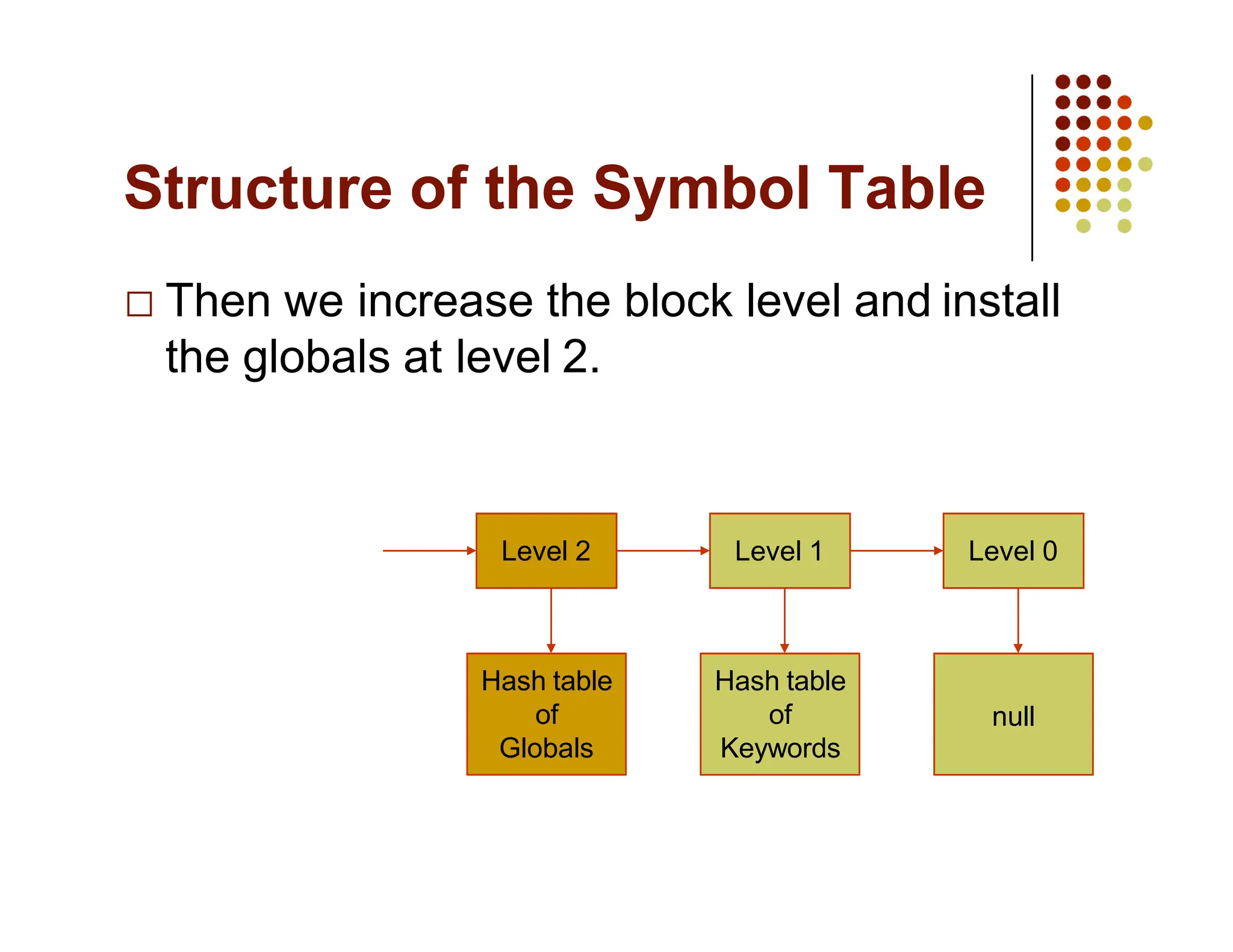
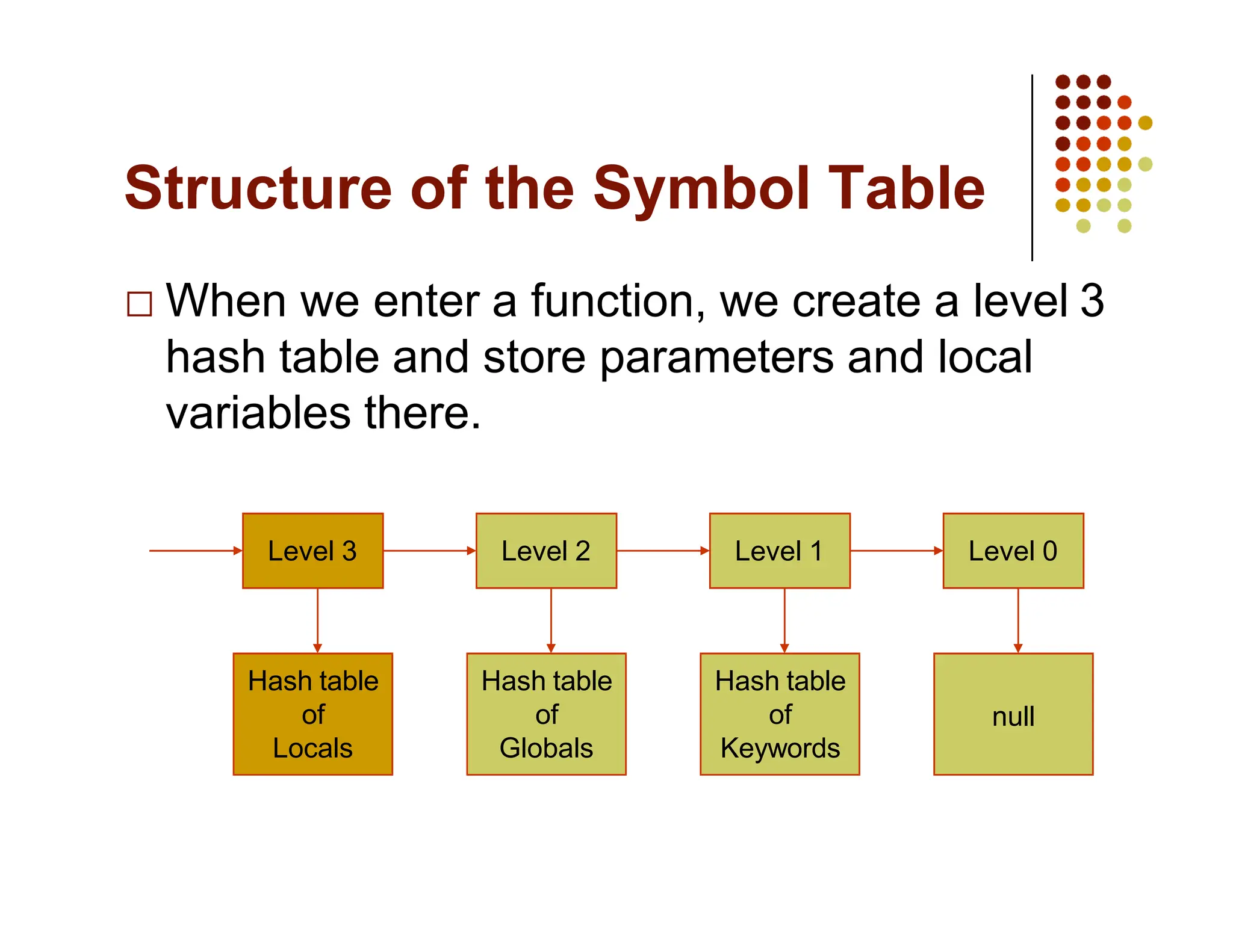
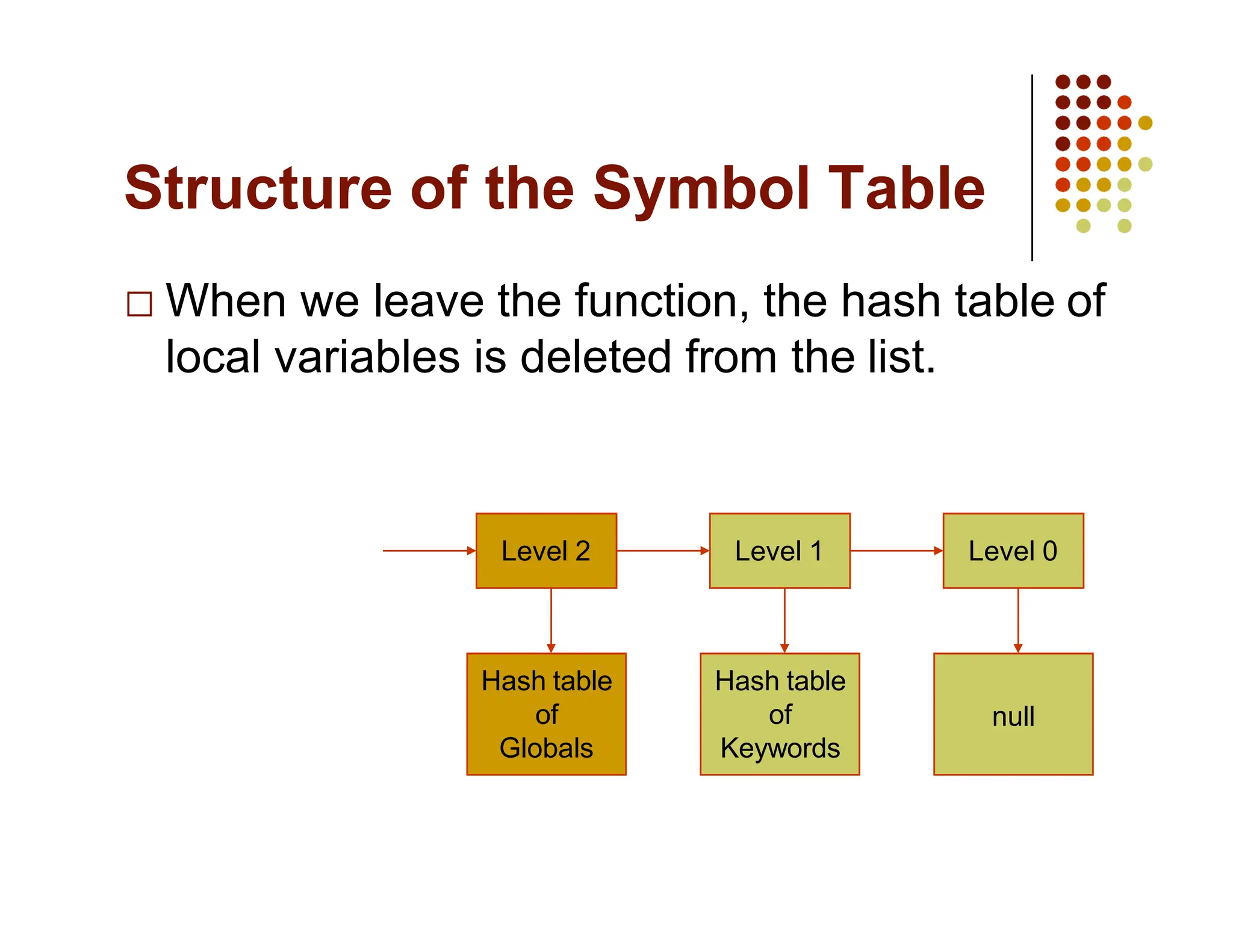
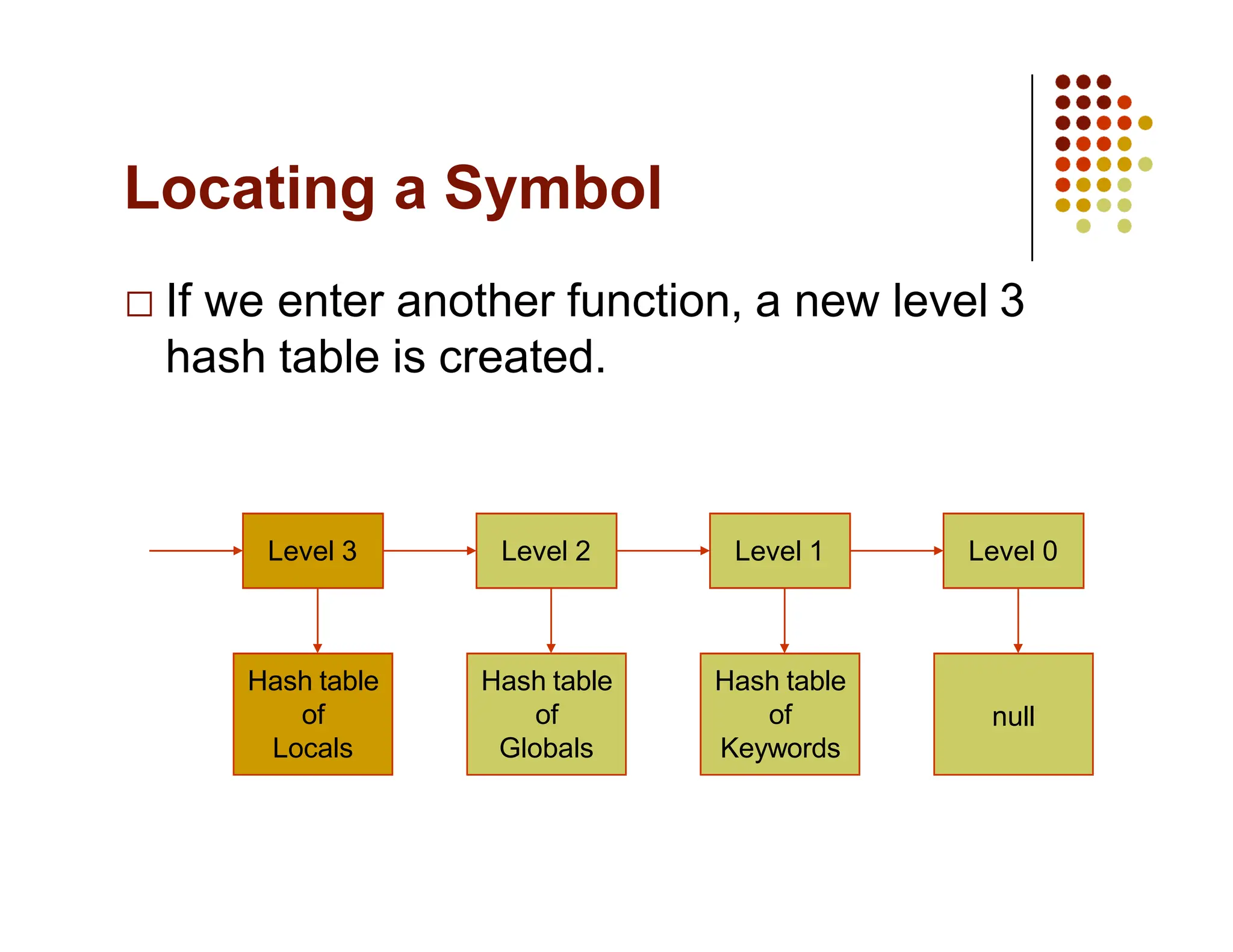
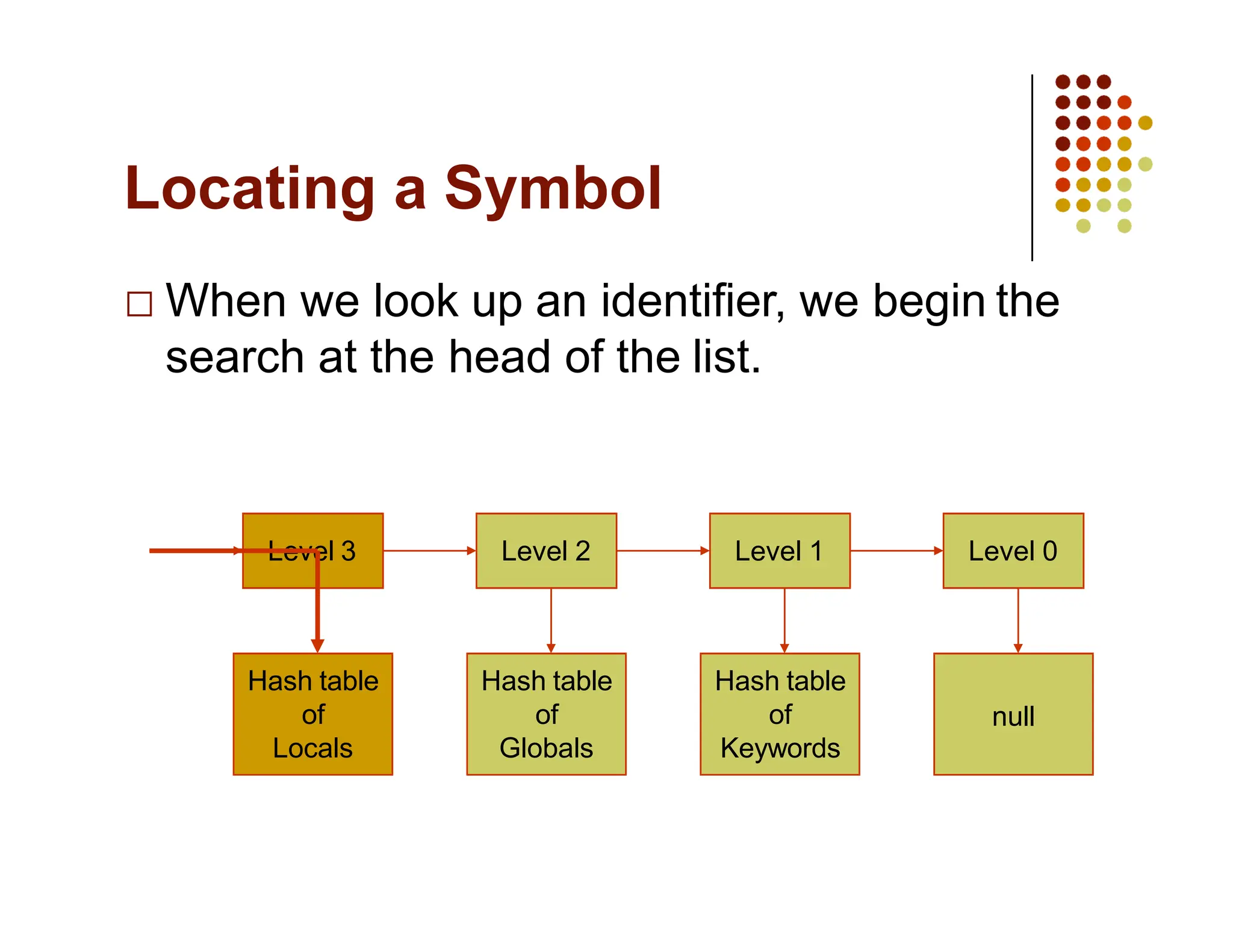
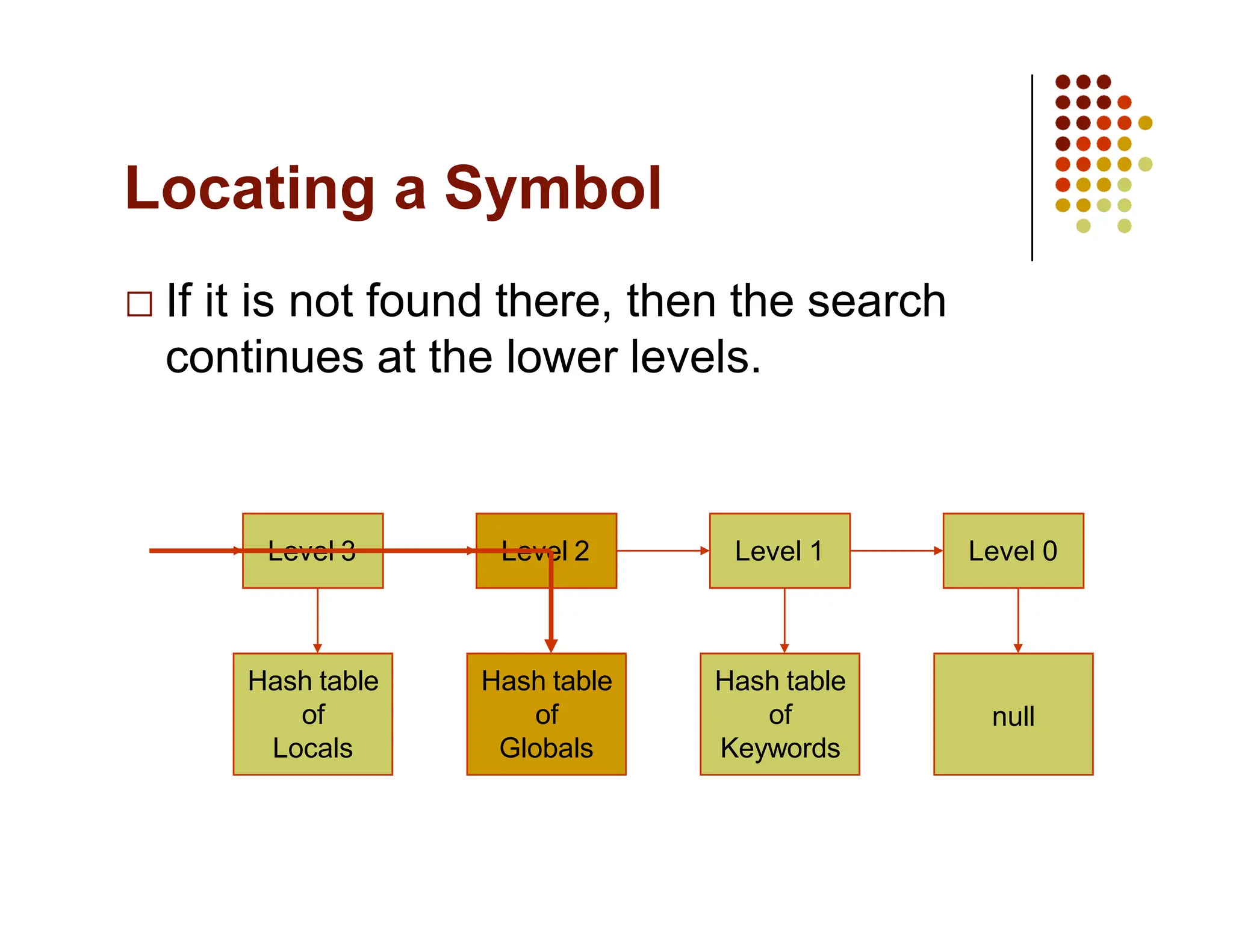
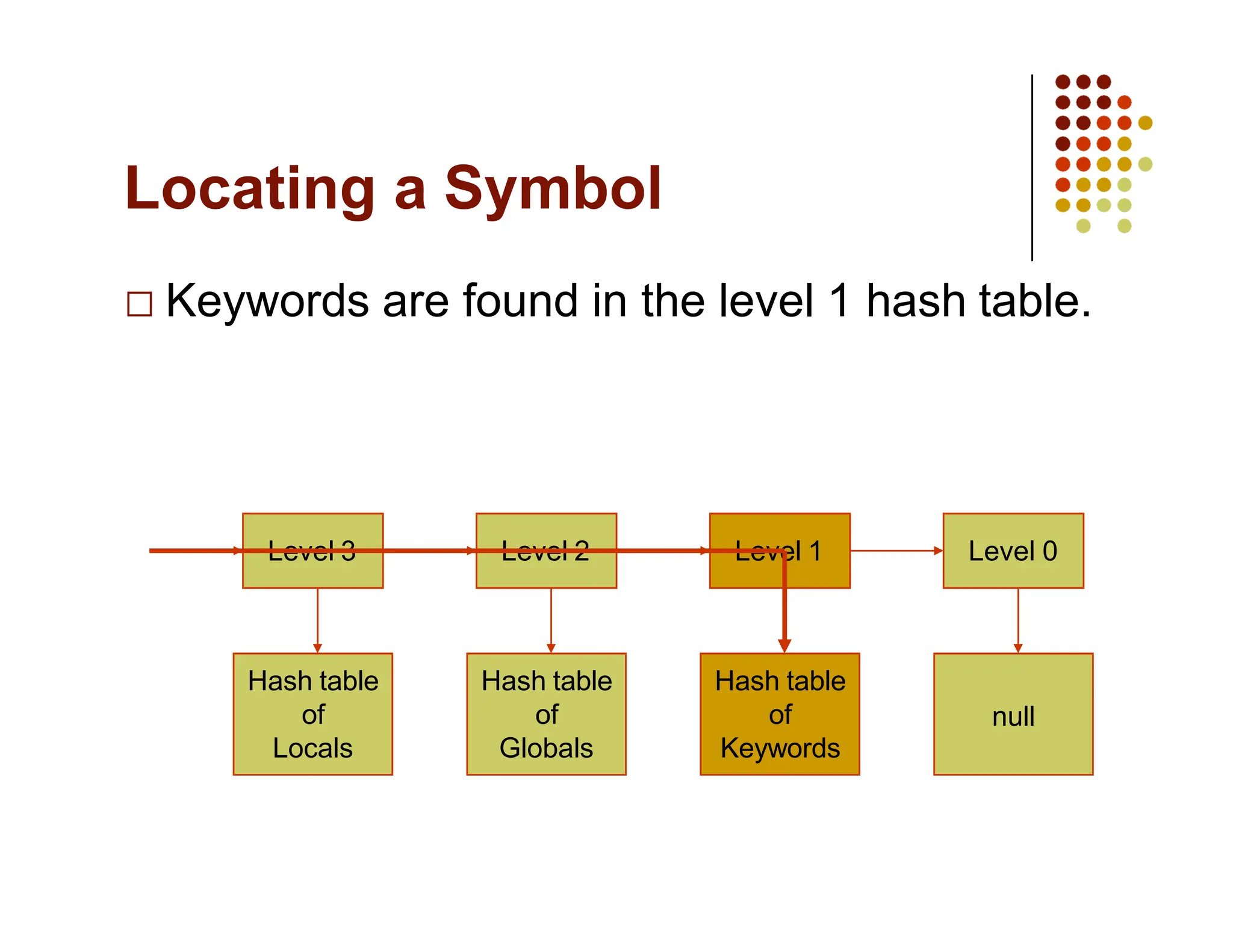
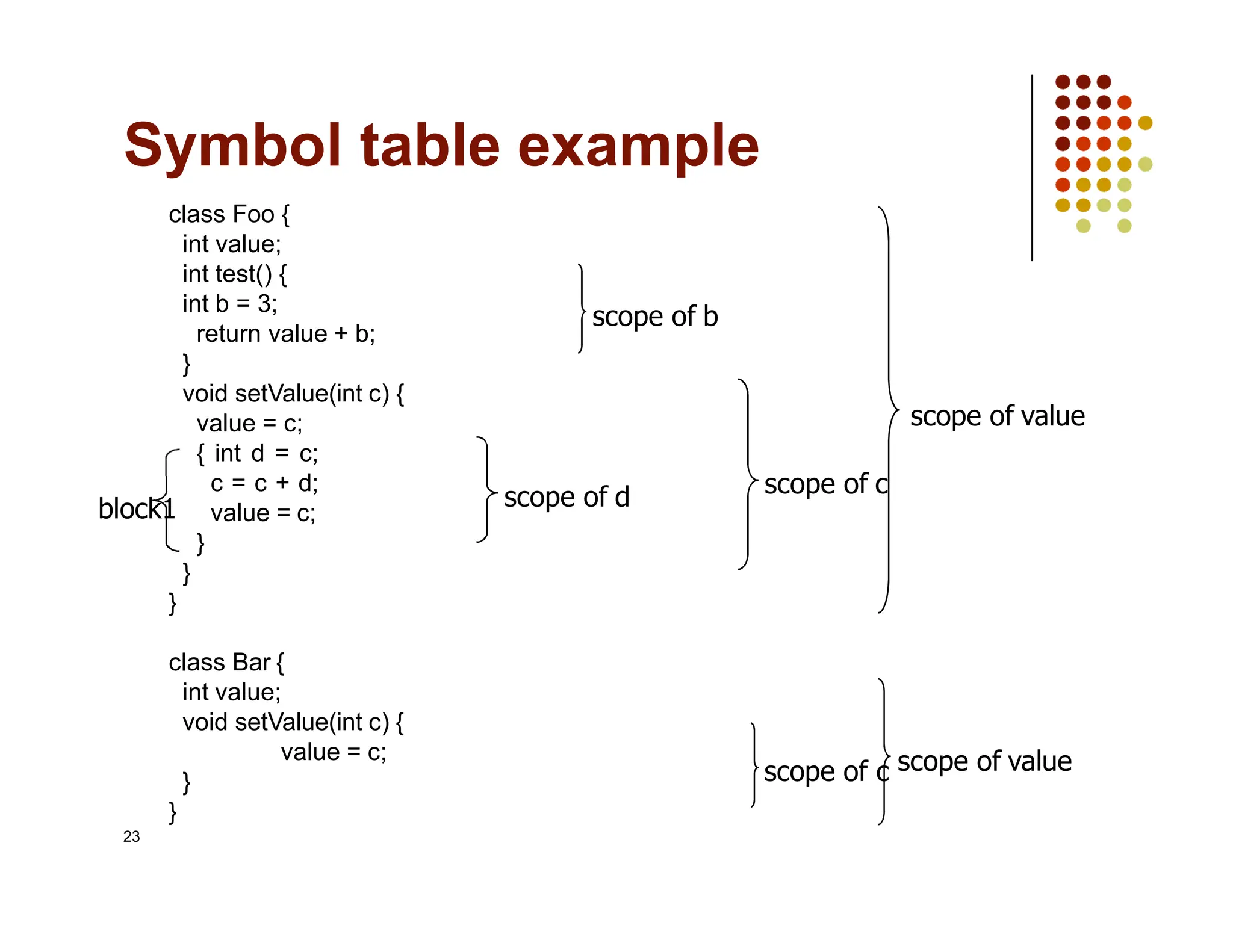
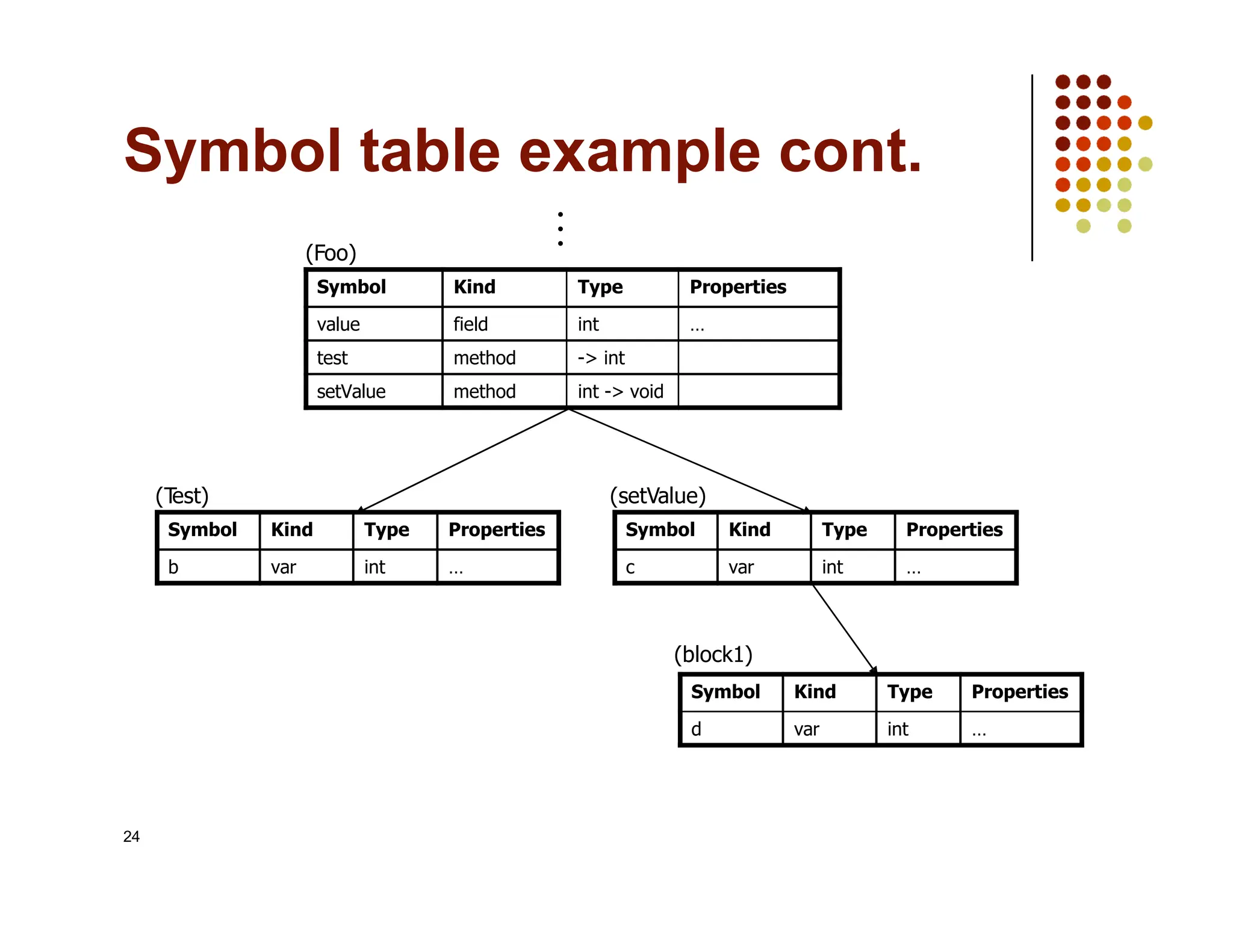
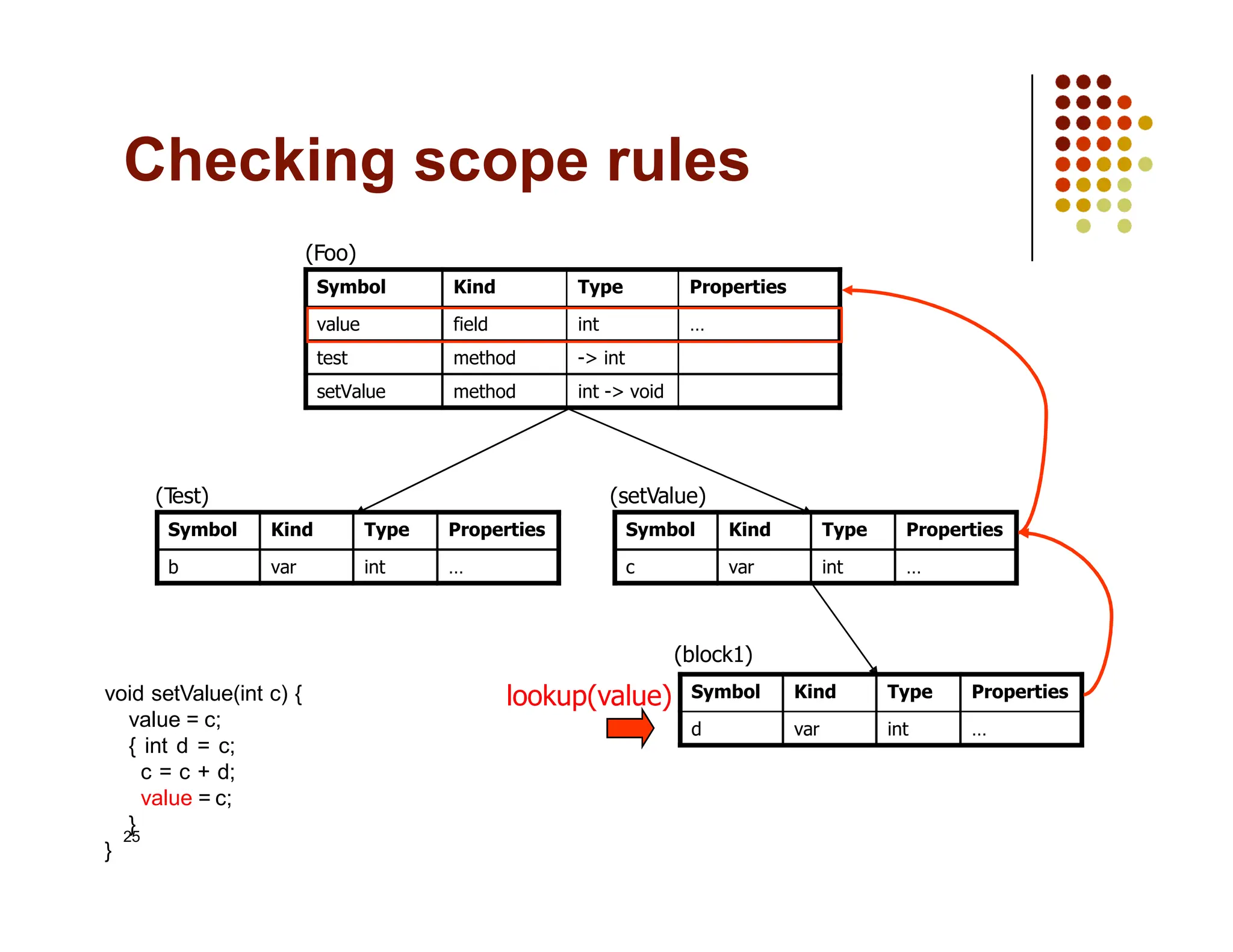
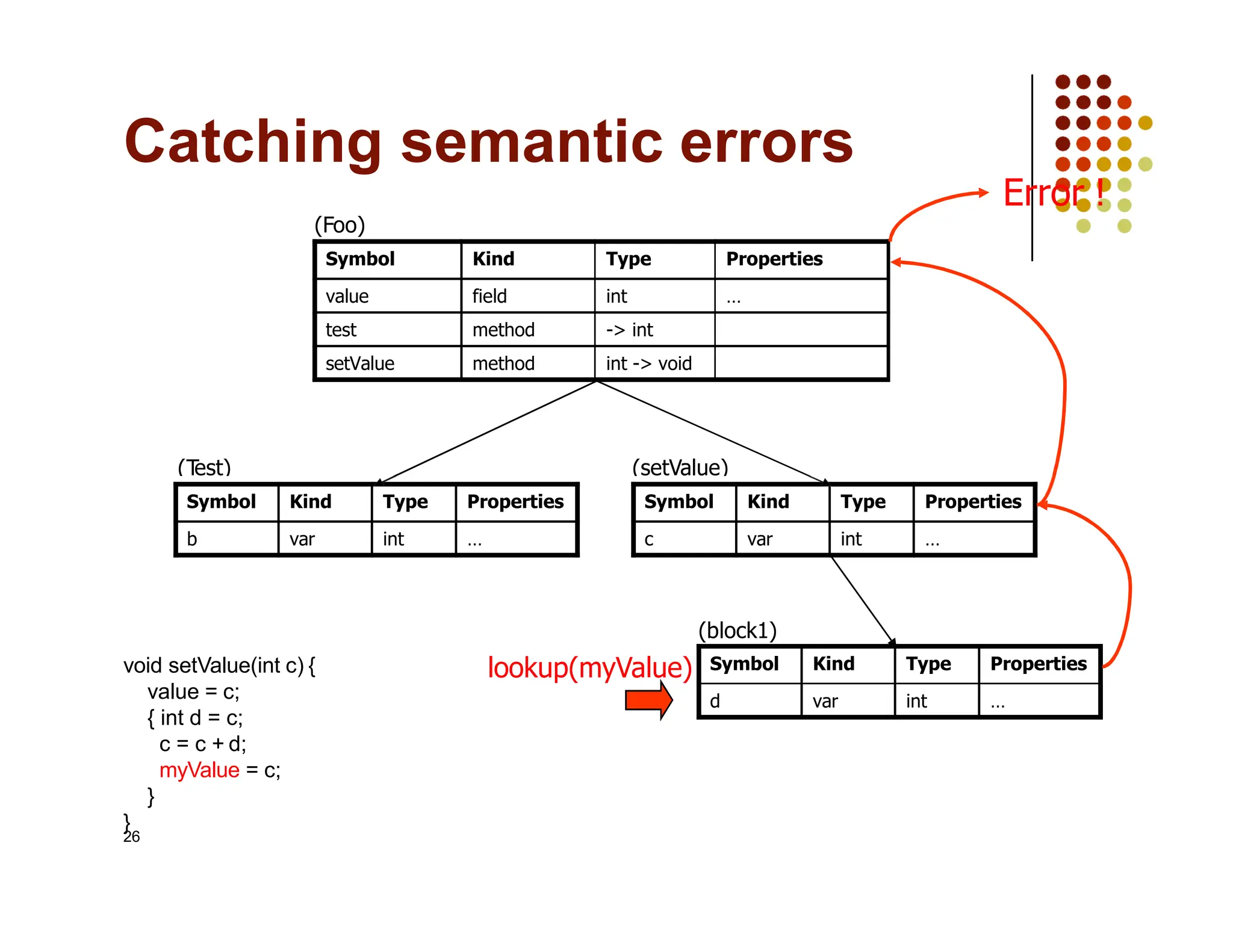
The document discusses symbol tables, a data structure used by compilers to store information about various entities like variables and functions. It covers their implementation methods, operations such as insert and lookup, and highlights their hierarchical structure for scope management. Additionally, it explains the role of hash tables in efficiently managing these tables, including handling collisions and maintaining performance.