Recommended
PPTX
[오픈소스컨설팅]Kafka message system 맛보기
PDF
Apache kafka intro_20150313_springloops
PDF
신림프로그래머 Kafka study
PDF
[112]clova platform 인공지능을 엮는 기술
PDF
카프카(kafka) 성능 테스트 환경 구축 (JMeter, ELK)
PDF
PPTX
Streaming platform Kafka in SK planet
PDF
Tdc2013 선배들에게 배우는 server scalability
PDF
지금 핫한 Real-time In-memory Stream Processing 이야기
PDF
Apache kafka 모니터링을 위한 Metrics 이해 및 최적화 방안
PDF
[Td 2015]개발하기 바쁜데 푸시서버와 메시지큐는 있는거 쓸래요(김영재)
PDF
Twitter의 대규모 시스템 운용 기술 어느 고래의 배속에서
PDF
서버인프라를지탱하는기술2_1-2
PDF
PPTX
[135] 오픈소스 데이터베이스, 은행 서비스에 첫발을 내밀다.
PPT
PDF
PPTX
PDF
PPTX
PDF
Optane DC Persistent Memory(DCPMM) 성능 테스트
PDF
How to build massive service for advance
PDF
서버인프라 구축 입문 basis of composing server and infra
PPTX
PPTX
PDF
메모리 할당에 관한 기초
PDF
NET 최선단 기술에 의한 고성능 웹 애플리케이션
PDF
2014.4.30 프라이머 개발자 모임 - 서버 장애 예방 및 대응 방법 공유
PPTX
PDF
Data in Motion을 위한 이벤트 기반 마이크로서비스 아키텍처 소개
More Related Content
PPTX
[오픈소스컨설팅]Kafka message system 맛보기
PDF
Apache kafka intro_20150313_springloops
PDF
신림프로그래머 Kafka study
PDF
[112]clova platform 인공지능을 엮는 기술
PDF
카프카(kafka) 성능 테스트 환경 구축 (JMeter, ELK)
PDF
PPTX
Streaming platform Kafka in SK planet
PDF
Tdc2013 선배들에게 배우는 server scalability
What's hot
PDF
지금 핫한 Real-time In-memory Stream Processing 이야기
PDF
Apache kafka 모니터링을 위한 Metrics 이해 및 최적화 방안
PDF
[Td 2015]개발하기 바쁜데 푸시서버와 메시지큐는 있는거 쓸래요(김영재)
PDF
Twitter의 대규모 시스템 운용 기술 어느 고래의 배속에서
PDF
서버인프라를지탱하는기술2_1-2
PDF
PPTX
[135] 오픈소스 데이터베이스, 은행 서비스에 첫발을 내밀다.
PPT
PDF
PPTX
PDF
PPTX
PDF
Optane DC Persistent Memory(DCPMM) 성능 테스트
PDF
How to build massive service for advance
PDF
서버인프라 구축 입문 basis of composing server and infra
PPTX
PPTX
PDF
메모리 할당에 관한 기초
PDF
NET 최선단 기술에 의한 고성능 웹 애플리케이션
PDF
2014.4.30 프라이머 개발자 모임 - 서버 장애 예방 및 대응 방법 공유
Similar to Kafka introduce kr
PPTX
PDF
Data in Motion을 위한 이벤트 기반 마이크로서비스 아키텍처 소개
PPTX
[월간 슬라이드] 단기완성 Apache kafka
PDF
PDF
[Main Session] 카프카, 데이터 플랫폼의 최강자
PDF
Data in Motion Tour Seoul 2024 - Keynote
PDF
PDF
Understanding of Apache kafka metrics for monitoring
PDF
[ 2021 AI + X 여름 캠프 ] 2. 장비 상호 연결 kafka를 이용한 매체 전송
PDF
PDF
Confluent Startup Webinar Series
PDF
AWS Summit Seoul 2023 | Confluent와 함께하는 실시간 데이터와 클라우드 여정
PPTX
Confluent와 함께 Data in Motion 실현
PDF
Confluent Cloud로 이벤트 기반 마이크로서비스 10배 확장하기 with 29CM
PDF
스타트업을 위한 Confluent 웨비나 3탄
PDF
Data in Motion Tour Seoul 2024 - Roadmap Demo
PDF
Lag 없는 실시간 데이터 파이프라인을 위한 아키텍처 개선기
PDF
PDF
SK planet Streaming system
PPTX
클라우드 네이티브를 위한 Confluent Cloud
Kafka introduce kr 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. kafka
1. 분산 클러스터 증설 용이
2. 디스크에 저장하므로 다운되도 메세지 남아 있음
3. 처리(소비)되는 메세지가 없이 쌓여 있어도 느려지지 않음
4. 대량의 메세지를 처리하면서도 속도도 빠름
15. kafka
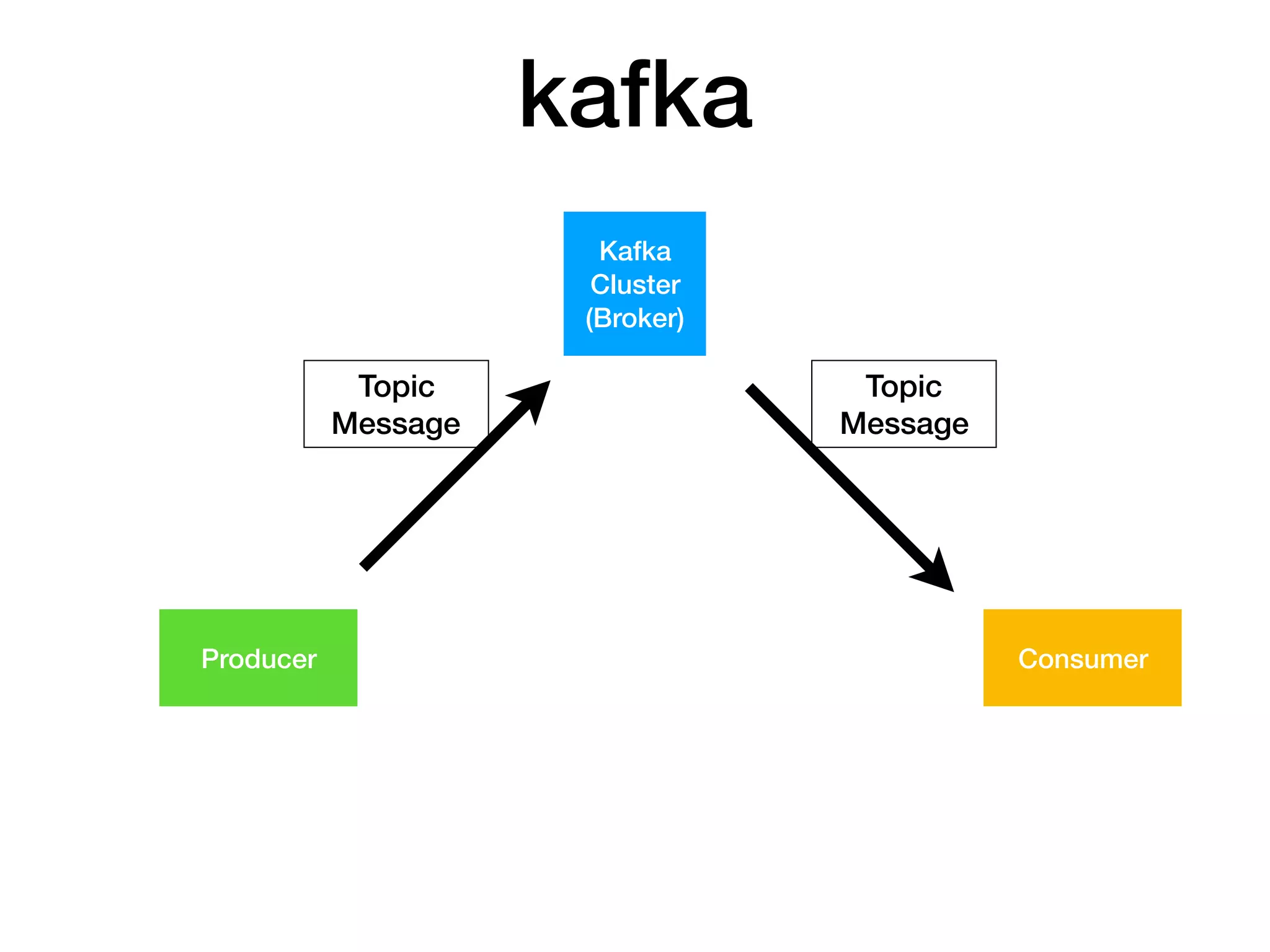
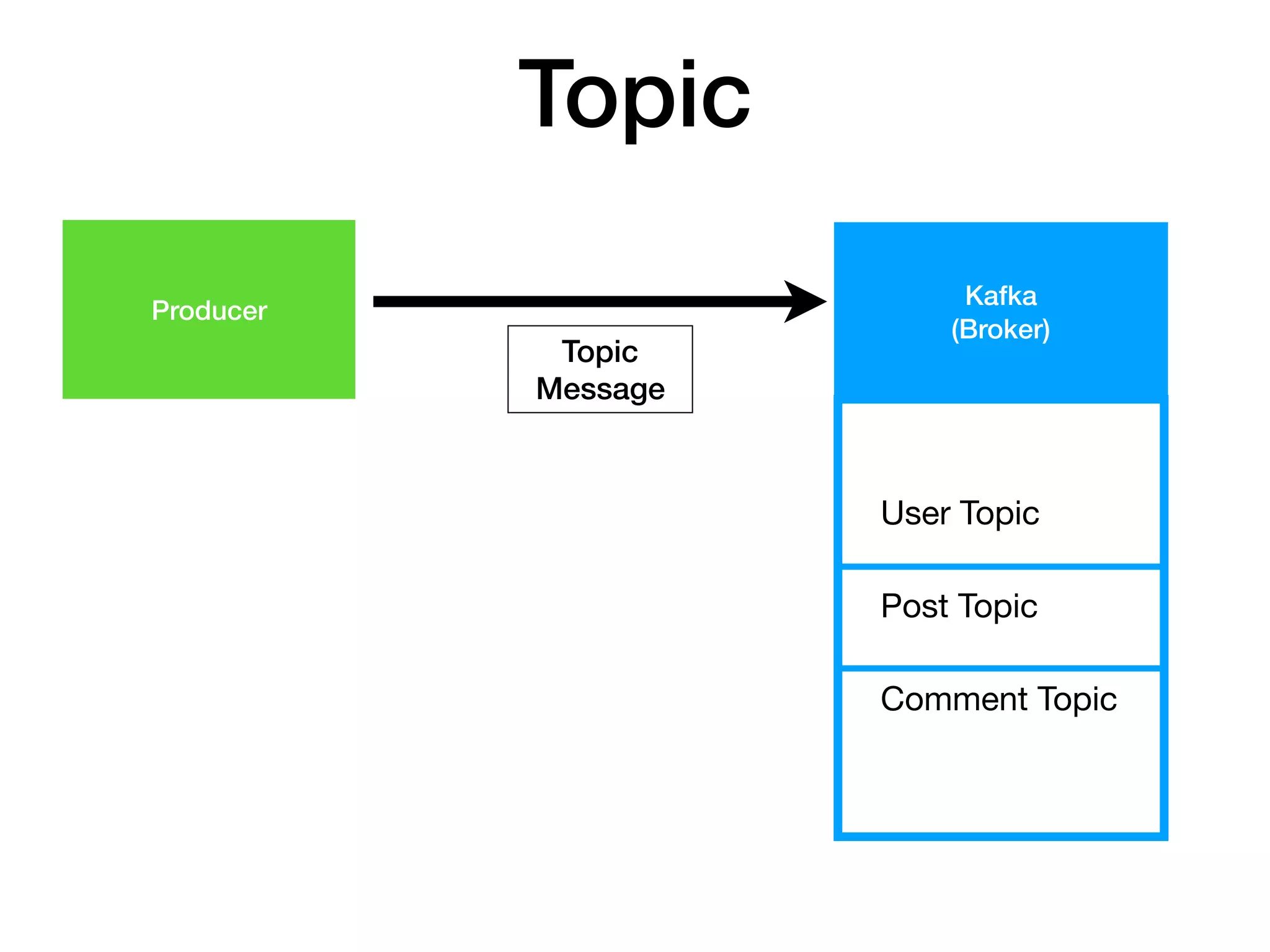
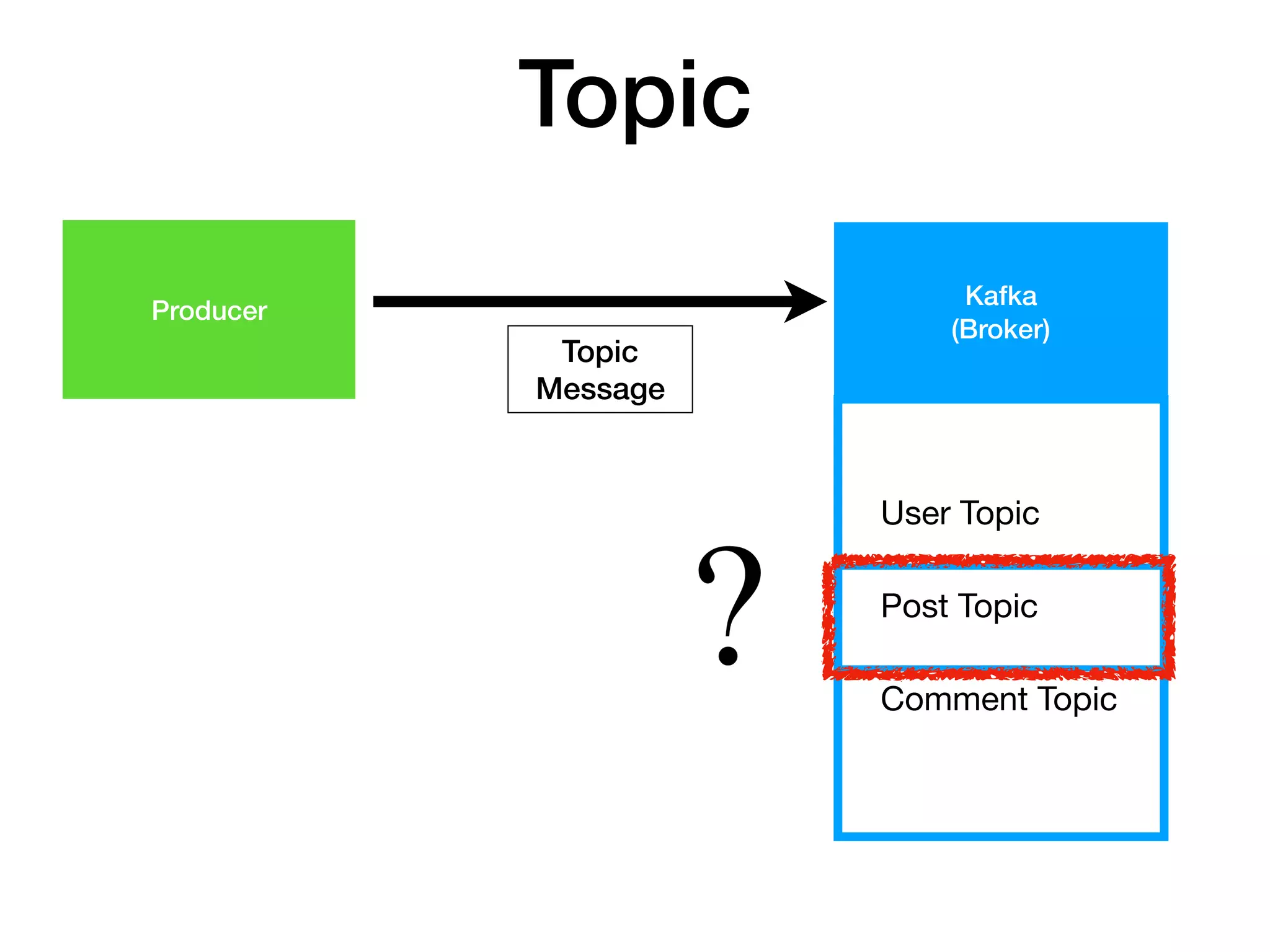
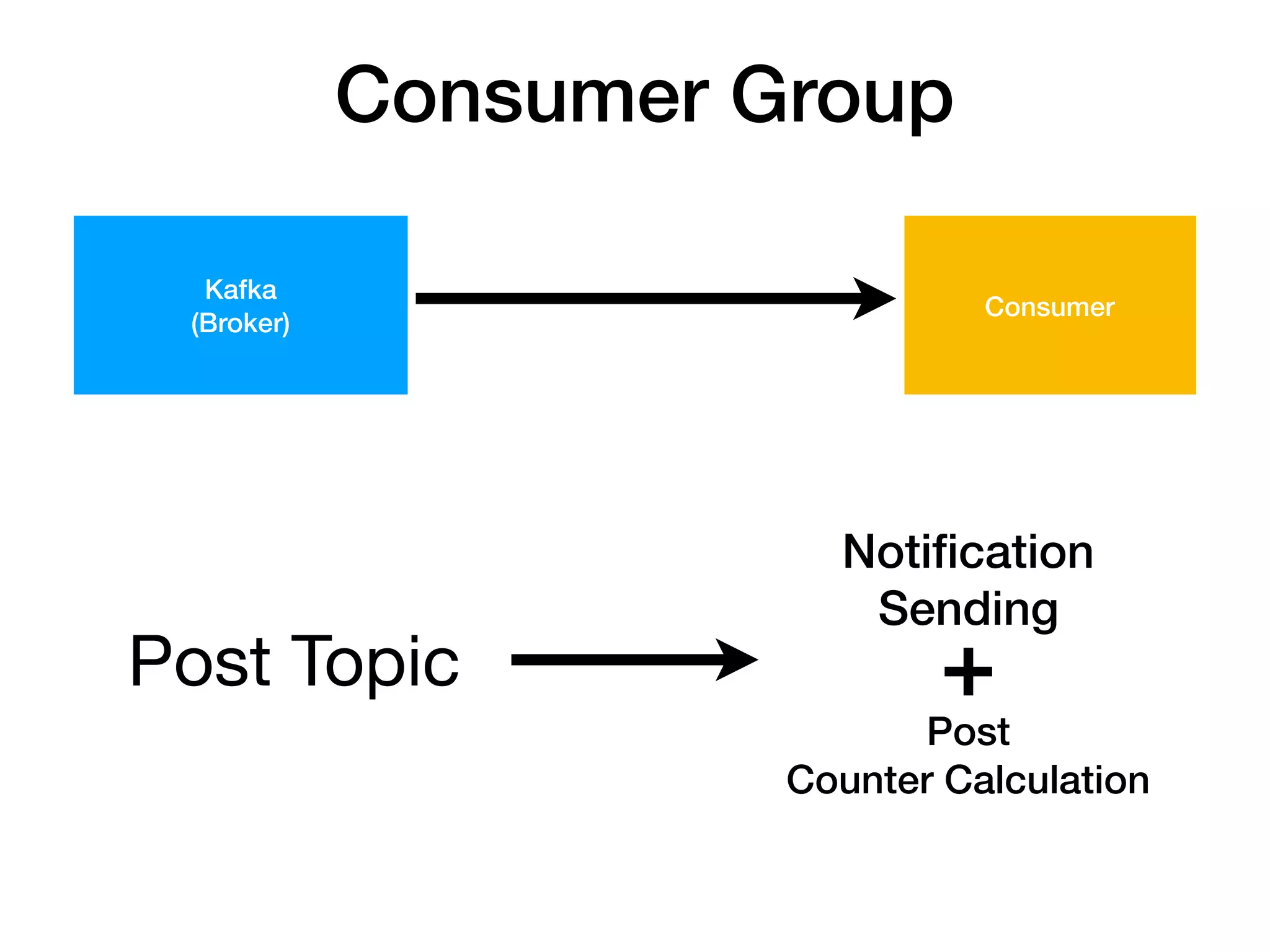
Topic 에 해당하는 Message를
Producer 가 Producing(publish) 하면
Consumer 가 Consuming(subscribe) 한다.
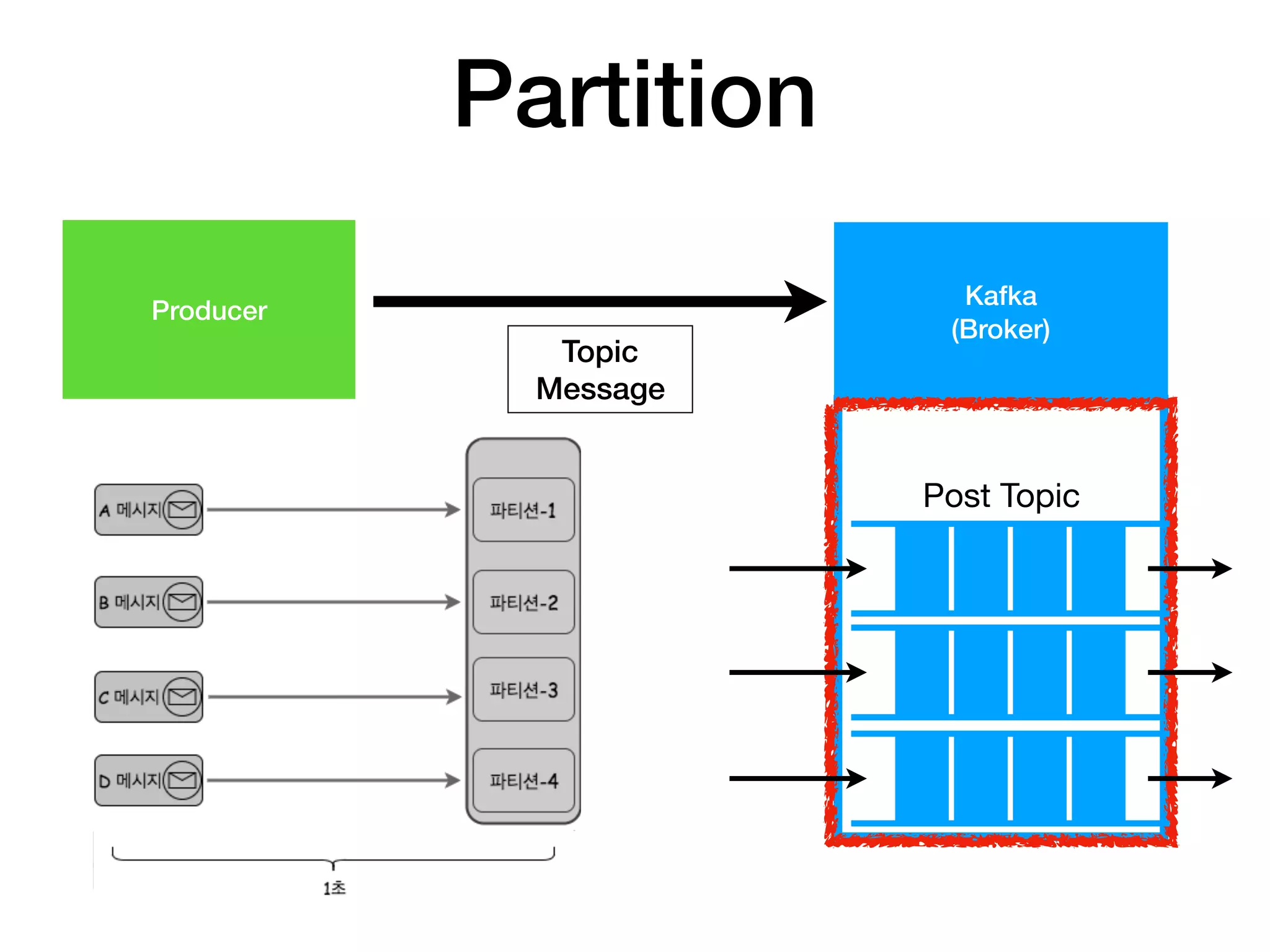
16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30. 31. 32. Partition1 Partition2 Partition3 Partition4
c
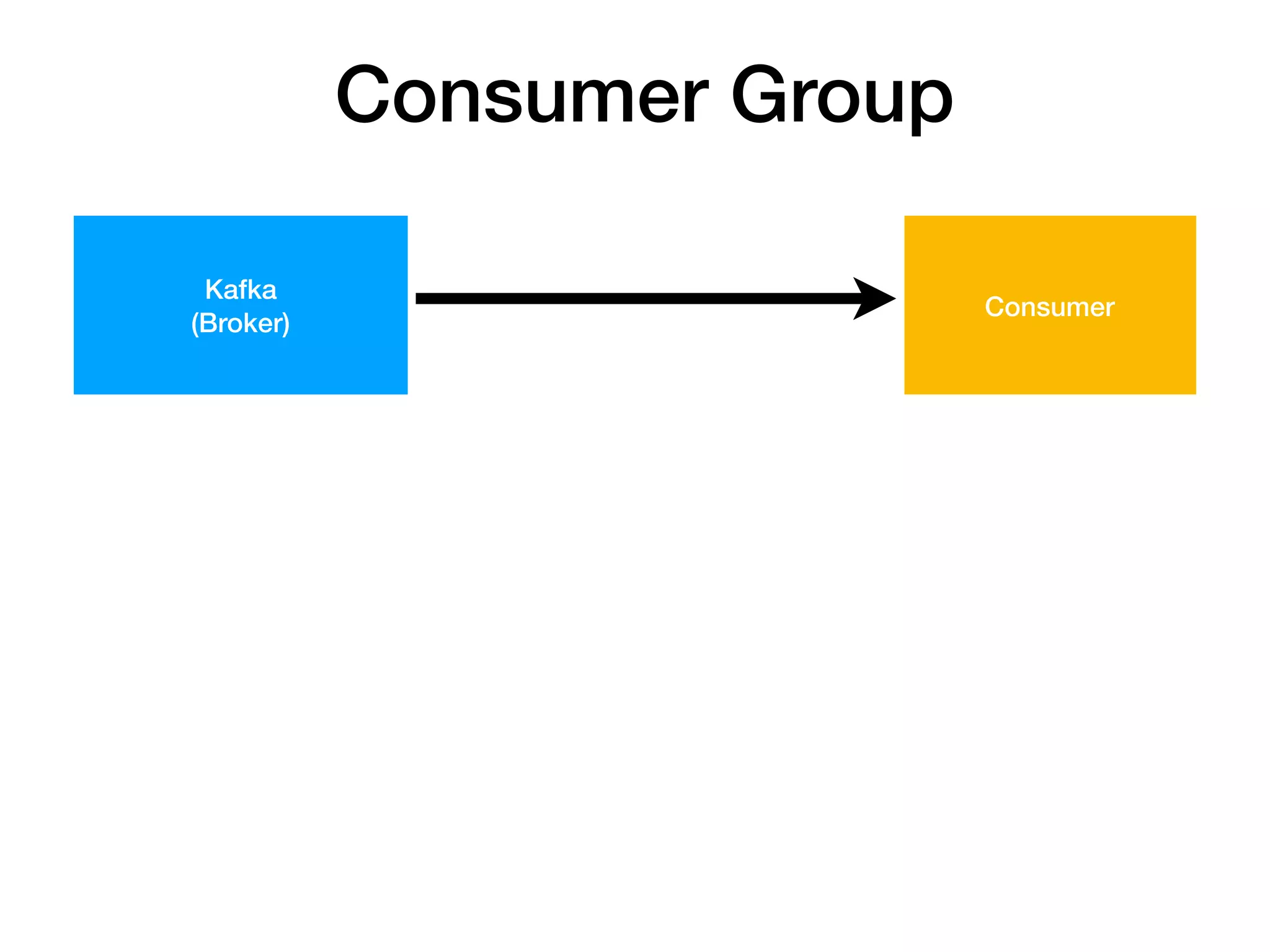
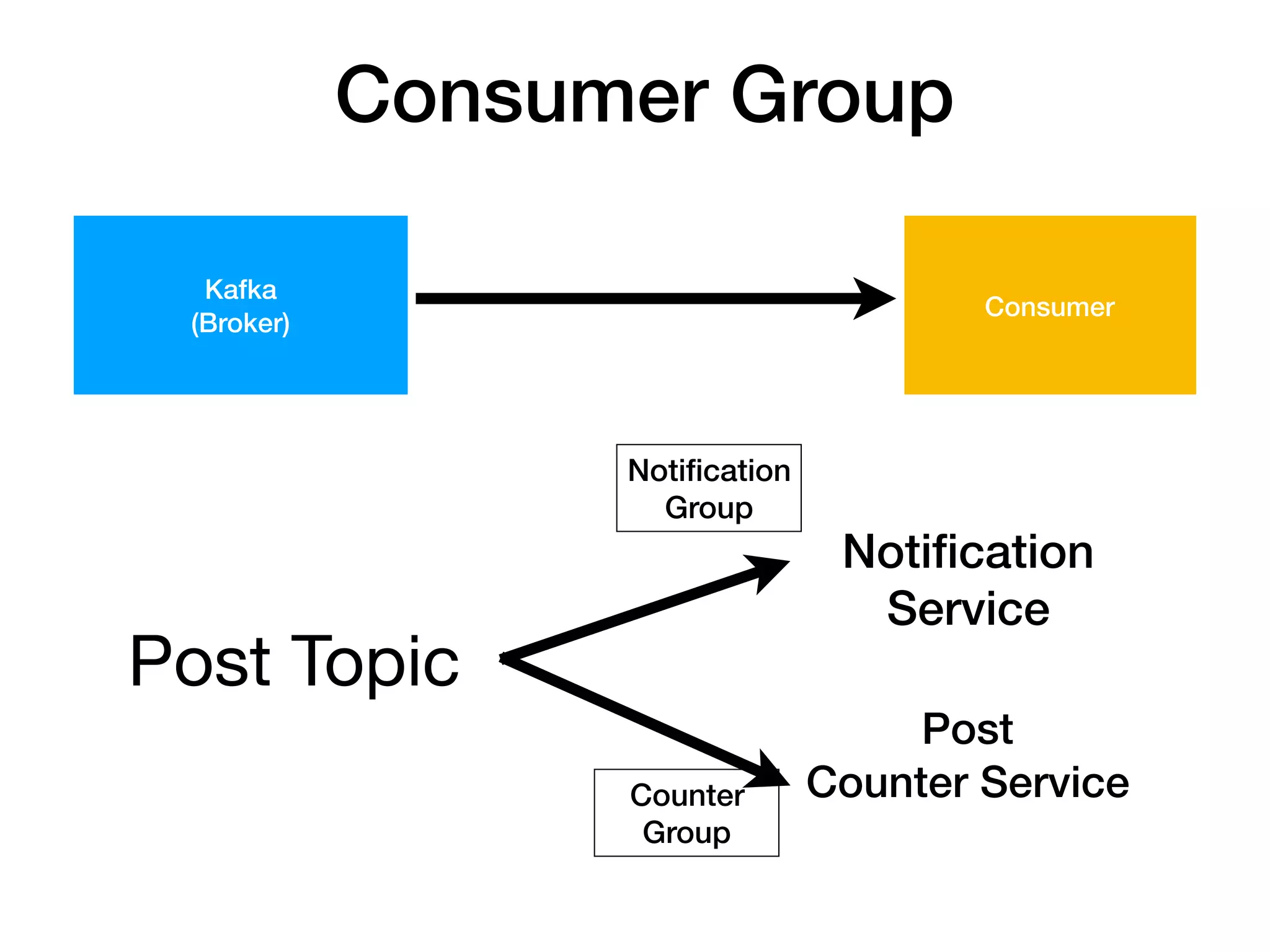
consumer consumer consumer consumer consumer consumer consumer
Consumer Group A Consumer Group B
kafka brocker
Consumer Group
Topic
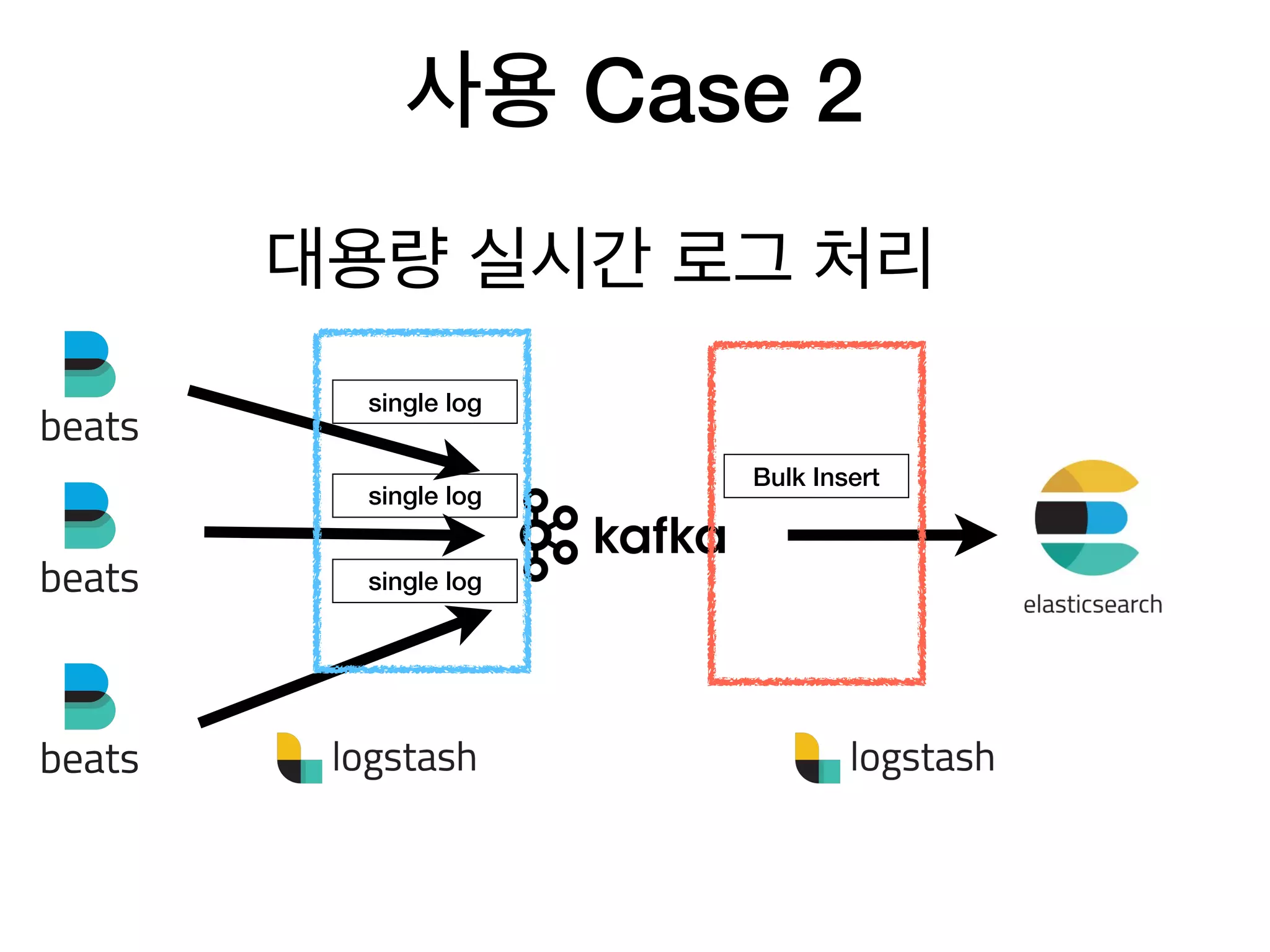
33. 34. 35. 36. 37. 38. 사용 Case 2
대용량 실시간 로그 처리
single log
single log
single log
Bulk Insert
39. 사용 Case 2
대용량 실시간 로그 처리
single log
single log
single log
Bulk Insert
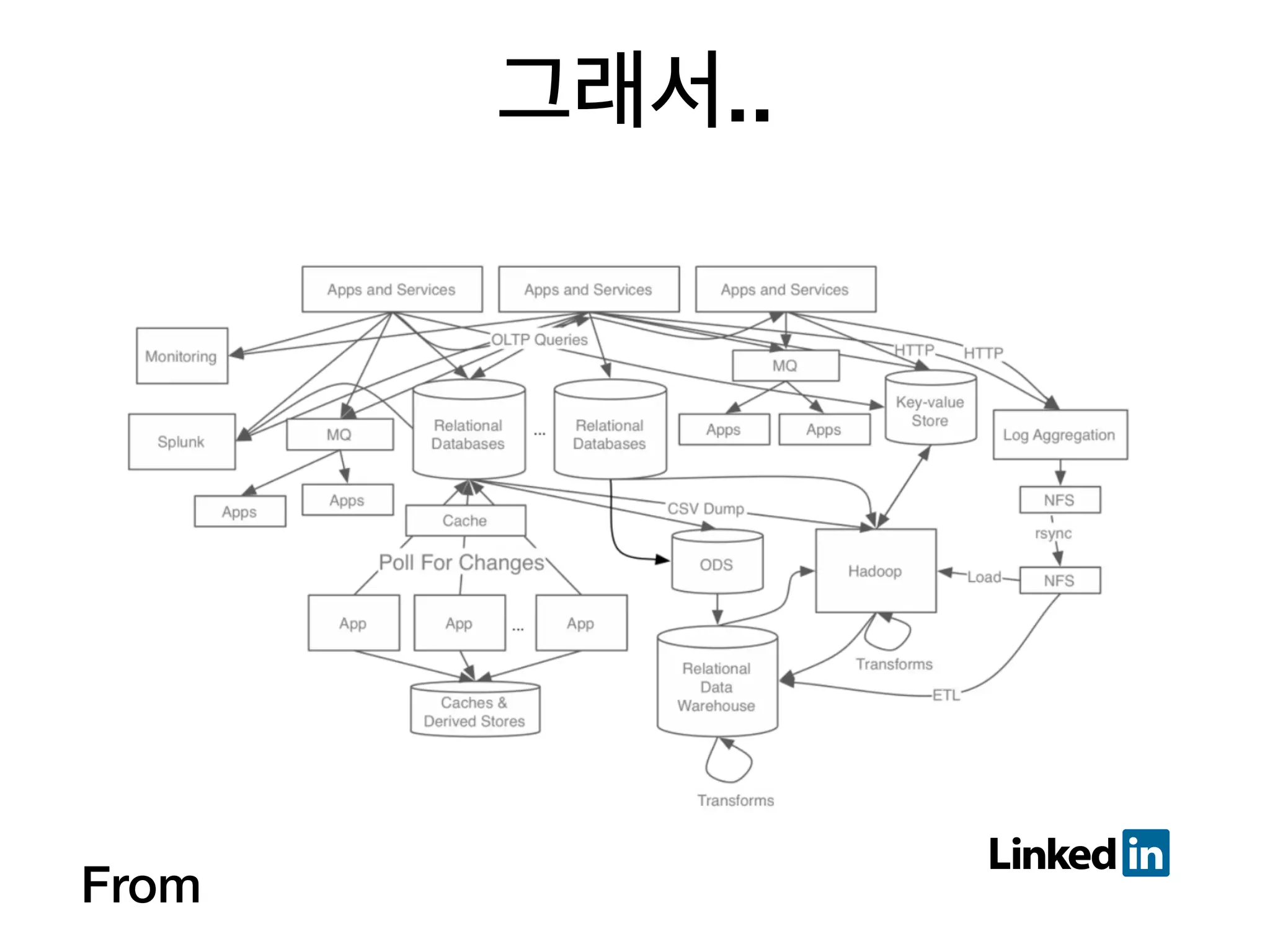
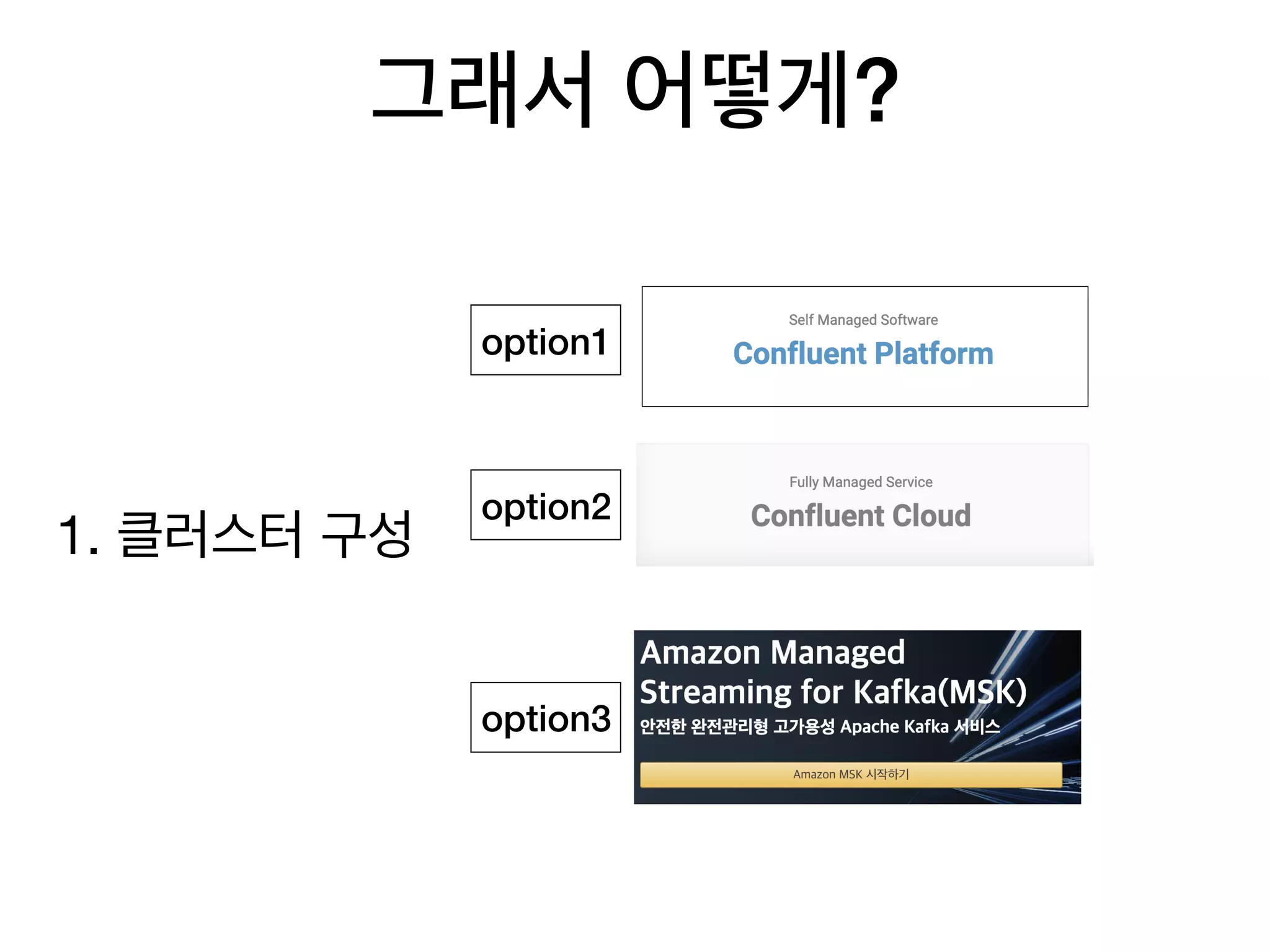
40. 41. 42. 43. 44. 45. 46. 47. 그래서 어떻게?
3. 진행 순서 1. Topic 설정
2. partition 설정
3. producing
4. consuming
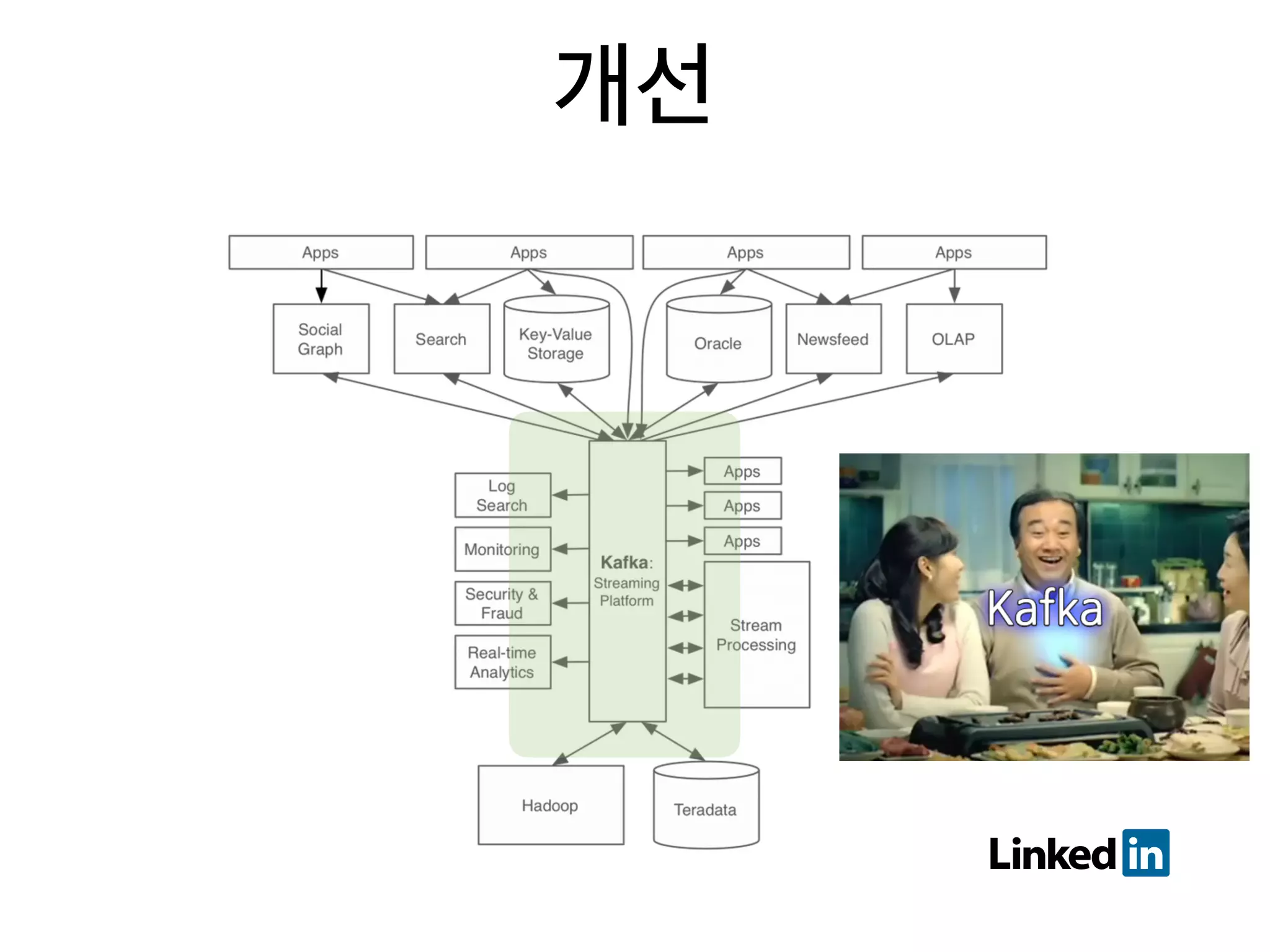
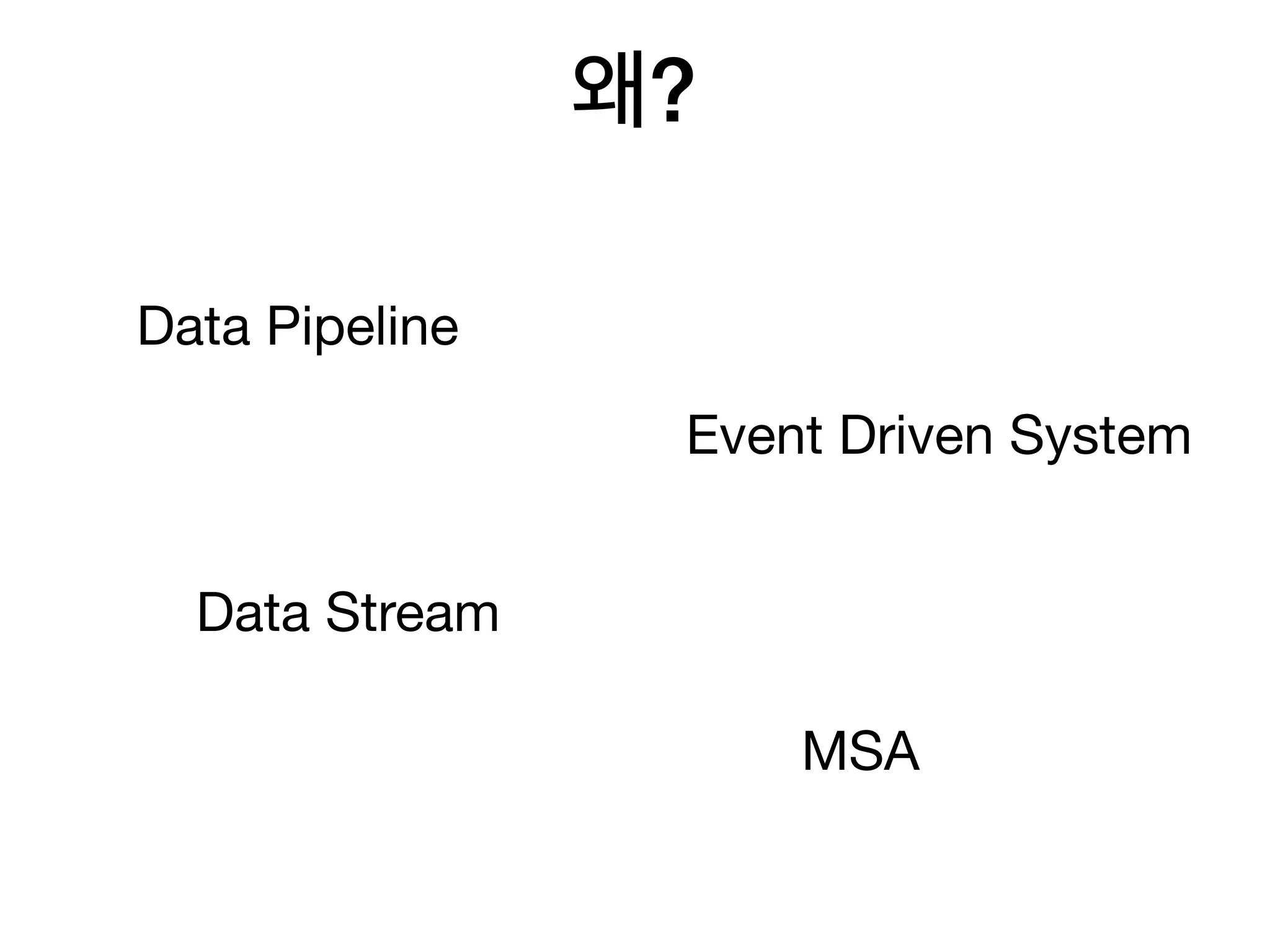
48. 49. 50. 51. 52. 53. 54. - 시스템이 충분히 복잡해지면 도입한다
- 기반 인프라가 되어간다. DB 같은 필수요소 처럼..
- use case 가 다양하다..
- 데이터 구조를 잘 짜야한다.
- MSA 하려면 거의 필수라고 느껴진다.
- producer 1 : multi consumer 구조가 핵심
써보며 느낀점
55. - kafka message 는 어떻게 잘 만들어야 하는가?
- consumer 에서 business model의 상태는 어
떻게 관리해야 하는가?
- fault tolerant 구성을 하기 위한 아키텍처
도입시 고민거리
56. 57. 1. 1 producer : n consumer 좋아요
2. 메세지 모델링은 고민되요
3. 도입 활용은 적당한 필요를 기반으로
4. 언어는 jvm 이 편하고
5. 클러스터 구성은 managed 가 속편합니다.
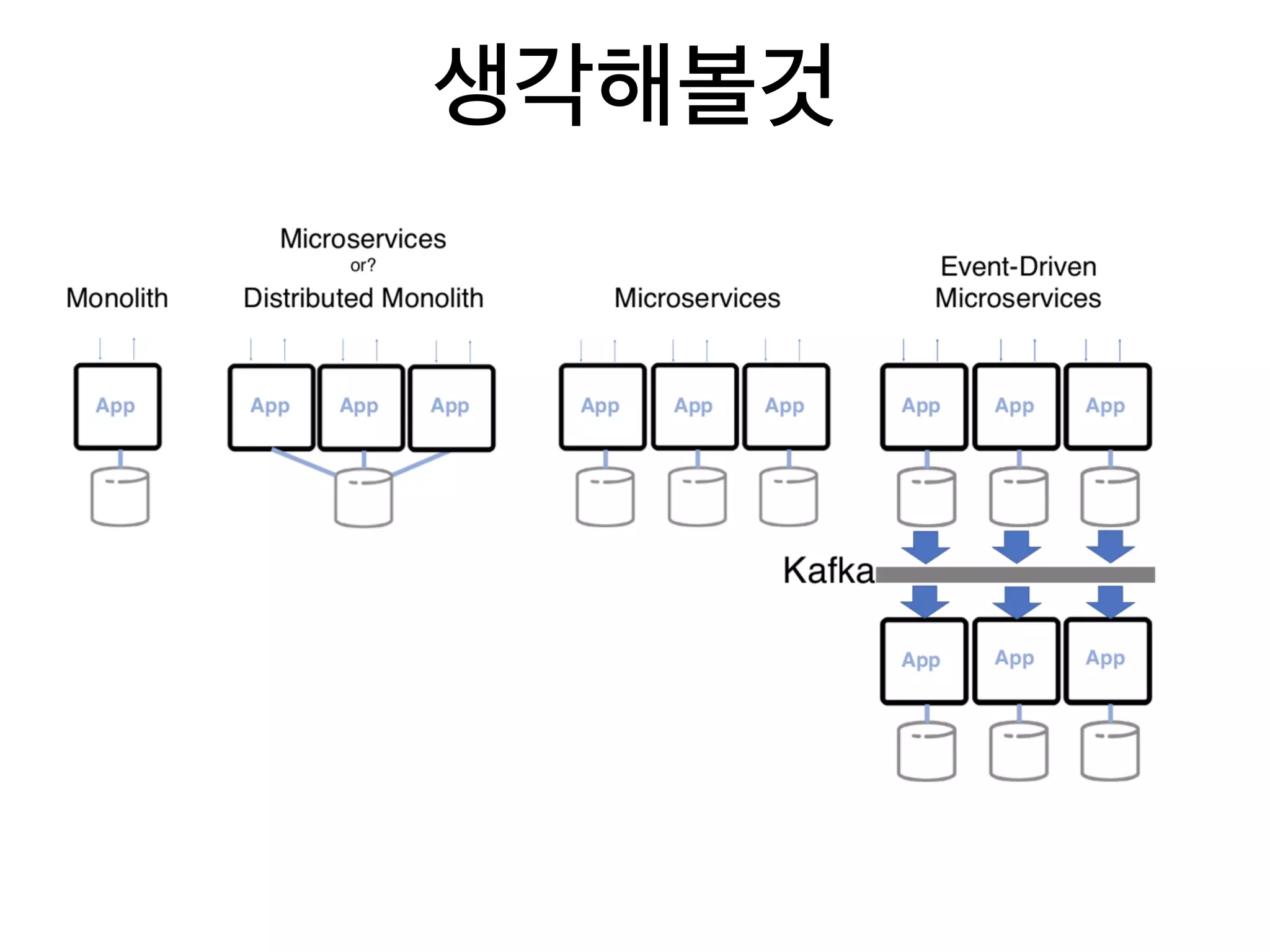
6. MSA, Event Driven Architecture 에서는 필수라고 생각됩니다.
요약
End-user를 위한 서비스를 개발하는 애플리케이션 개발자 입장
58. 59. 60.













































![[오픈소스컨설팅]Kafka message system 맛보기](https://cdn.slidesharecdn.com/ss_thumbnails/kafkamessagesystem-180730044904-thumbnail.jpg?width=640&height=640&fit=bounds)


![[112]clova platform 인공지능을 엮는 기술](https://cdn.slidesharecdn.com/ss_thumbnails/12clovaplatform-171016022611-thumbnail.jpg?width=640&height=640&fit=bounds)






![[Td 2015]개발하기 바쁜데 푸시서버와 메시지큐는 있는거 쓸래요(김영재)](https://cdn.slidesharecdn.com/ss_thumbnails/td2015-151104051535-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)



![[135] 오픈소스 데이터베이스, 은행 서비스에 첫발을 내밀다.](https://cdn.slidesharecdn.com/ss_thumbnails/35-171016061446-thumbnail.jpg?width=640&height=640&fit=bounds)















![[월간 슬라이드] 단기완성 Apache kafka](https://cdn.slidesharecdn.com/ss_thumbnails/monthlyslideapachekafka-190302052656-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Main Session] 카프카, 데이터 플랫폼의 최강자](https://cdn.slidesharecdn.com/ss_thumbnails/180519-kafka-oraclefin-180521125323-thumbnail.jpg?width=640&height=640&fit=bounds)



![[ 2021 AI + X 여름 캠프 ] 2. 장비 상호 연결 kafka를 이용한 매체 전송](https://cdn.slidesharecdn.com/ss_thumbnails/2-210731153335-thumbnail.jpg?width=640&height=640&fit=bounds)










