Download to read offline

















![Social Connections 14 Berlin, October 16-17 2018
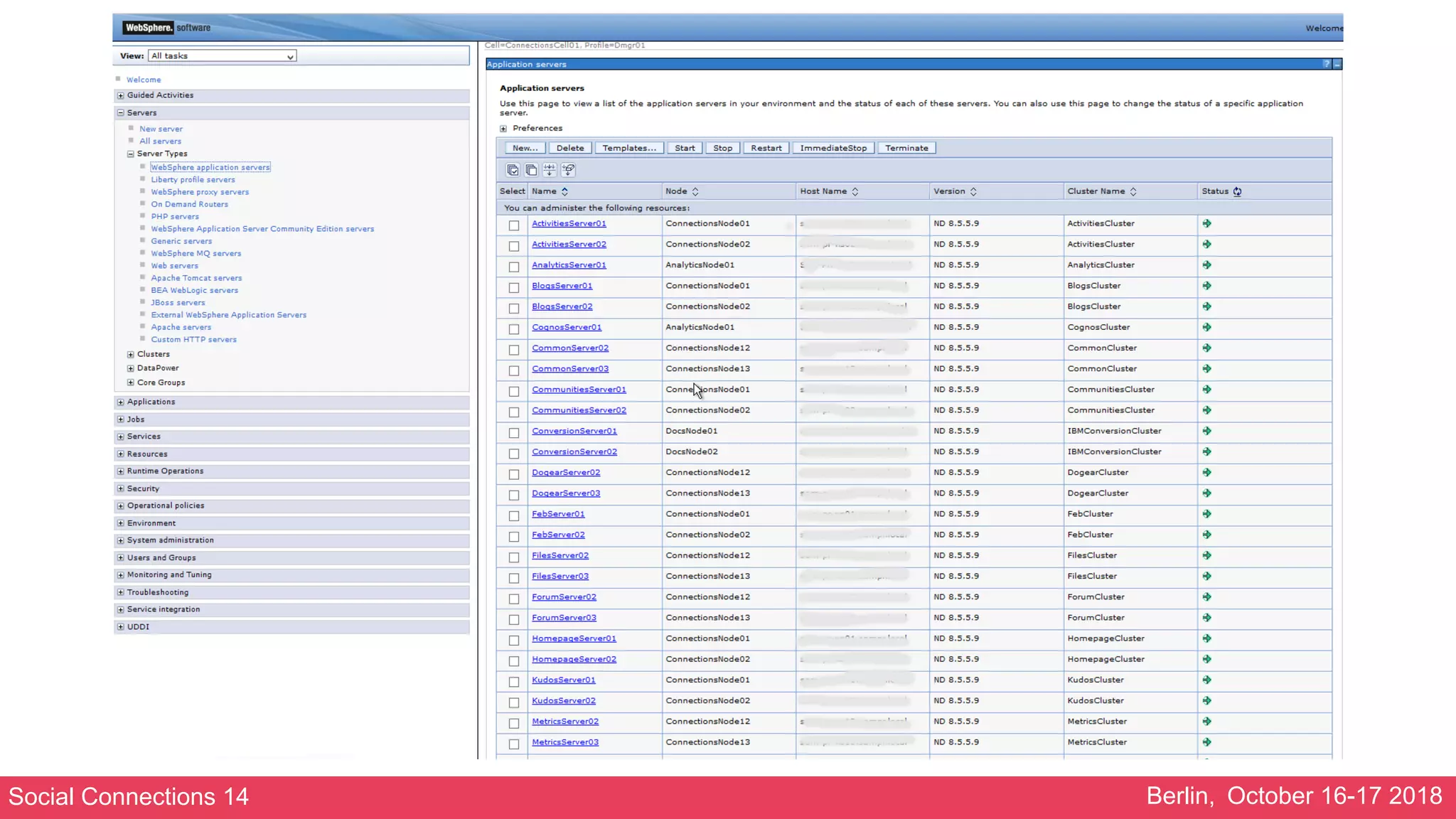
Craving Coordinator
• A lot of these errors in SystemOut.logs:
AgentClassImp W HMGR1001W: An attempt to receive a message of type GrowAgentRequest for Agent Agent: :
[_ham.serverid:ConnectionsCell01ConnectionsNode11SearchServer01]
[drs_inst_name:ic/services/cache/OAuth20DBClientCache][drs_inst_id: 1512698926654][ibm_agent.seq:1227]
[drs_mode:0][drs_agent_id:
CommunitiesServer01ic/services/cache/OAuth20DBClientCache9266541] in AgentClass AgentClass :
[policy:DefaultNOOPPolicy][drs_grp_id:
ConnectionsReplicationDomain] failed. The exception is
com.ibm.wsspi. hamanager.HAGroupMemberAlreadyExistsException: The member already exists
at com.ibm.ws.hamanager.impl.HAManagerImpl.joinGroup(HAManagerImpl.java:179)
at com.ibm.ws.hamanager.agent.AgentImpl.<init>(AgentImpl.java:174)
at com.ibm.ws.hamanager.agent.AgentClassImpl.onMessage(AgentClassImpl.java:429)
at com.ibm.ws.hamanager.impl.HAGroupImpl.doOnMessage(HAGroupImpl.java:794)
at com.ibm.ws.hamanager.impl.HAGroupImpl$HAGroupUserCallback.doCallback(HAGroupImpl.java:1382)
at com.ibm.ws.hamanager.impl.Worker.run(Worker.java:64)
at com.ibm.ws.util.ThreadPool$Worker.run(ThreadPool.java:1881)](https://image.slidesharecdn.com/stabilisingalargeibmconnectionsenvironment-181019211553/75/Stabilising-a-large-ibm-connections-environment-20-2048.jpg)






















![Social Connections 14 Berlin, October 16-17 2018
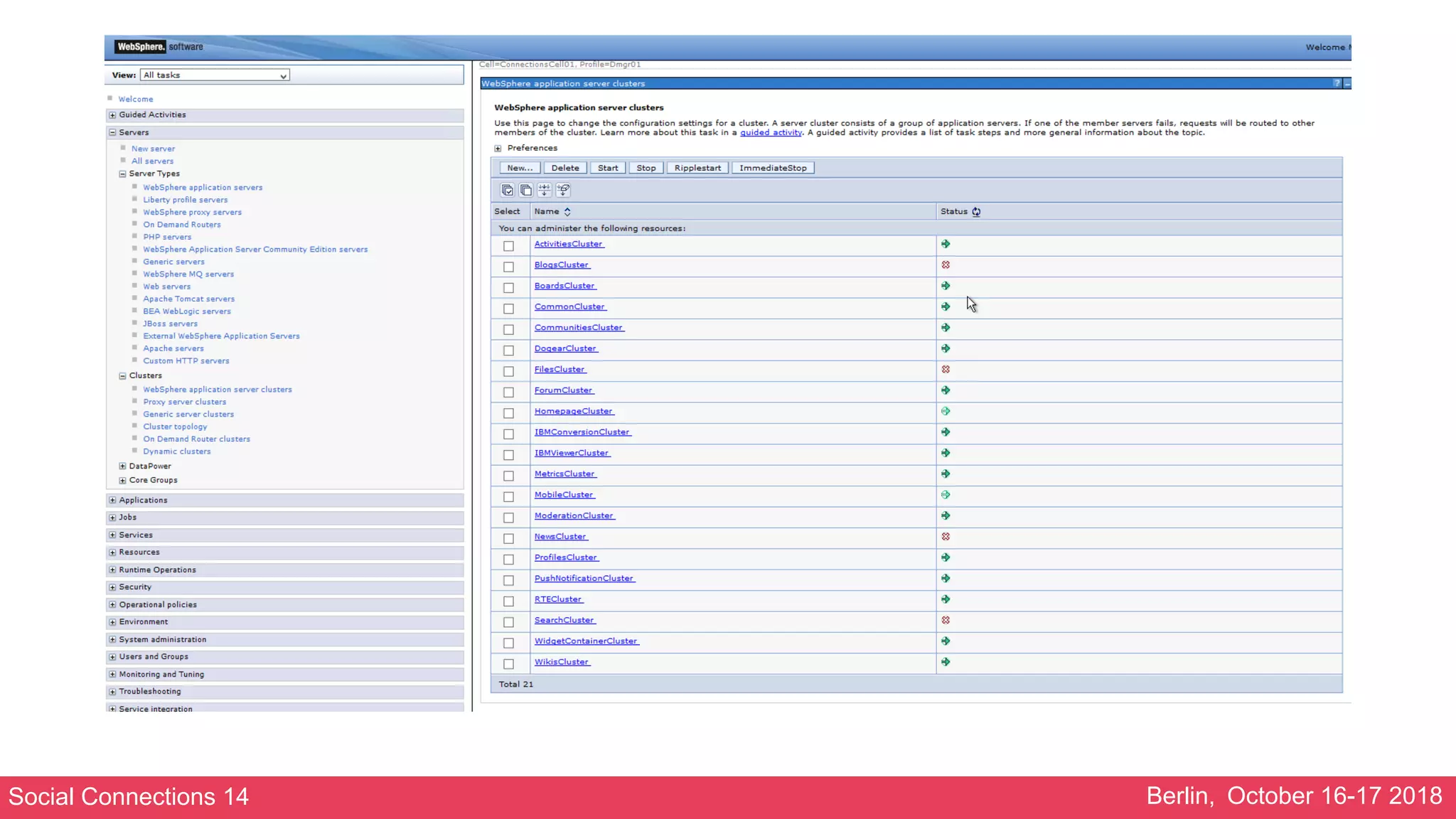
Bickering Blogs
• The cause:
• Certain actions (updating the hit counter, updating the likes counter)
would create a deadlock between the individual blog servers and the
blogs database
• This would result in hung threads in the blogs application
• The number of hung threads would rise to the maximum available
threads in about an hour
• When this happens the Blogs application would become unavailable
[13-3-18 9:38:13:696 CET] 000000f4 ThreadMonitor W WSVR0605W: Thread "WebContainer :
1" (00000162) has been active for 711627 milliseconds and may be hung. There is/are 11 thread(s)
in total in the server that may be hung.](https://image.slidesharecdn.com/stabilisingalargeibmconnectionsenvironment-181019211553/75/Stabilising-a-large-ibm-connections-environment-45-2048.jpg)







The document discusses the challenges and solutions encountered while stabilizing a large IBM Connections environment for a client with 22,000 employees. Key issues included SQL server memory overloads, clustering problems, and application crashes due to traffic spikes caused by specific large files. Ultimately, configurations were optimized and updated, leading to a more stable environment with no major outages reported for an entire year.


































































