Download to read offline












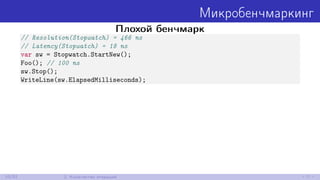

![Прогрев
Запустим бенчмарк несколько раз:
int[] x = new int[128 * 1024 * 1024];
for (int iter = 0; iter < 5; iter++)
{
var sw = Stopwatch.StartNew();
for (int i = 0; i < x.Length; i += 16)
x[i]++;
sw.Stop();
Console.WriteLine(sw.ElapsedMilliseconds);
}
11/52 2. Количество итераций](https://image.slidesharecdn.com/devfestakinshin-170929125407/85/slide-19-320.jpg)
![Прогрев
Запустим бенчмарк несколько раз:
int[] x = new int[128 * 1024 * 1024];
for (int iter = 0; iter < 5; iter++)
{
var sw = Stopwatch.StartNew();
for (int i = 0; i < x.Length; i += 16)
x[i]++;
sw.Stop();
Console.WriteLine(sw.ElapsedMilliseconds);
}
Результат:
176
81
62
62
62
11/52 2. Количество итераций](https://image.slidesharecdn.com/devfestakinshin-170929125407/85/slide-20-320.jpg)




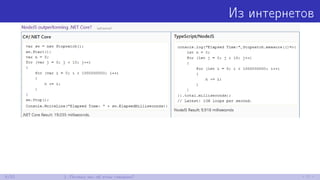
![Сумма элементов массива
const int N = 1024;
int[,] a = new int[N, N];
[Benchmark]
public double SumIj()
{
var sum = 0;
for (int i = 0; i < N; i++)
for (int j = 0; j < N; j++)
sum += a[i, j];
return sum;
}
[Benchmark]
public double SumJi()
{
var sum = 0;
for (int j = 0; j < N; j++)
for (int i = 0; i < N; i++)
sum += a[i, j];
return sum;
}
17/52 3. Работаем с памятью](https://image.slidesharecdn.com/devfestakinshin-170929125407/85/slide-26-320.jpg)
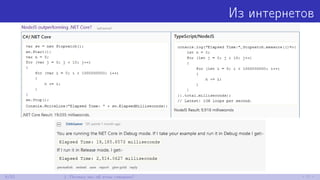
![Сумма элементов массива
const int N = 1024;
int[,] a = new int[N, N];
[Benchmark]
public double SumIj()
{
var sum = 0;
for (int i = 0; i < N; i++)
for (int j = 0; j < N; j++)
sum += a[i, j];
return sum;
}
[Benchmark]
public double SumJi()
{
var sum = 0;
for (int j = 0; j < N; j++)
for (int i = 0; i < N; i++)
sum += a[i, j];
return sum;
}
SumIj SumJi
LegacyJIT-x86 ≈1.3ms ≈4.0ms
17/52 3. Работаем с памятью](https://image.slidesharecdn.com/devfestakinshin-170929125407/85/slide-27-320.jpg)

![Branch prediction
const int N = 32767;
int[] sorted, unsorted; // random numbers [0..255]
private static int Sum(int[] data)
{
int sum = 0;
for (int i = 0; i < N; i++)
if (data[i] >= 128)
sum += data[i];
return sum;
}
[Benchmark]
public int Sorted()
{
return Sum(sorted);
}
[Benchmark]
public int Unsorted()
{
return Sum(unsorted);
}
20/52 4. Работаем с условными переходами](https://image.slidesharecdn.com/devfestakinshin-170929125407/85/slide-30-320.jpg)
![Branch prediction
const int N = 32767;
int[] sorted, unsorted; // random numbers [0..255]
private static int Sum(int[] data)
{
int sum = 0;
for (int i = 0; i < N; i++)
if (data[i] >= 128)
sum += data[i];
return sum;
}
[Benchmark]
public int Sorted()
{
return Sum(sorted);
}
[Benchmark]
public int Unsorted()
{
return Sum(unsorted);
}
Sorted Unsorted
LegacyJIT-x86 ≈20µs ≈139µs
20/52 4. Работаем с условными переходами](https://image.slidesharecdn.com/devfestakinshin-170929125407/85/slide-31-320.jpg)


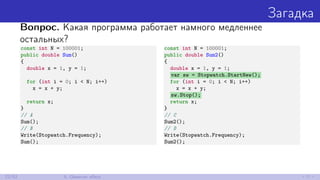
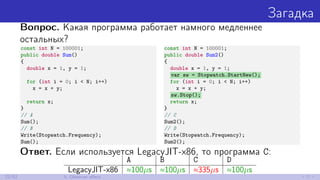
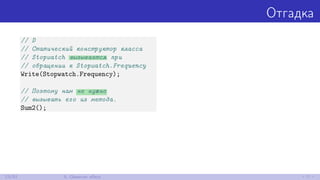
![Отгадка
// D
// Статический конструктор класса
// Stopwatch вызывается при
// обращении к Stopwatch.Frequency
Write(Stopwatch.Frequency);
// Поэтому нам не нужно
// вызывать его из метода.
Sum2();
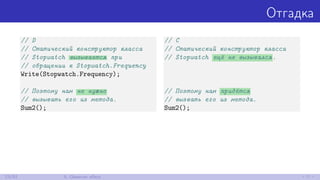
// C
// Статический конструктор класса
// Stopwatch ещё не вызывался.
// Поэтому нам придётся
// вызвать его из метода.
Sum2();
; x + y (A, B, D)
fld1
faddp st(1),st
; x + y (C)
fld1
fadd qword ptr [ebp-0Ch]
fstp qword ptr [ebp-0Ch]
23/52 5. Observer effect](https://image.slidesharecdn.com/devfestakinshin-170929125407/85/slide-38-320.jpg)



![Как же так?
RyuJIT-x64, Sqrt13
vsqrtsd xmm0,xmm0,mmword ptr [7FF94F9E4D28h]
vsqrtsd xmm1,xmm0,mmword ptr [7FF94F9E4D30h]
vaddsd xmm0,xmm0,xmm1
vsqrtsd xmm1,xmm0,mmword ptr [7FF94F9E4D38h]
vaddsd xmm0,xmm0,xmm1
vsqrtsd xmm1,xmm0,mmword ptr [7FF94F9E4D40h]
vaddsd xmm0,xmm0,xmm1
vsqrtsd xmm1,xmm0,mmword ptr [7FF94F9E4D48h]
vaddsd xmm0,xmm0,xmm1
vsqrtsd xmm1,xmm0,mmword ptr [7FF94F9E4D50h]
vaddsd xmm0,xmm0,xmm1
vsqrtsd xmm1,xmm0,mmword ptr [7FF94F9E4D58h]
vaddsd xmm0,xmm0,xmm1
vsqrtsd xmm1,xmm0,mmword ptr [7FF94F9E4D60h]
vaddsd xmm0,xmm0,xmm1
vsqrtsd xmm1,xmm0,mmword ptr [7FF94F9E4D68h]
vaddsd xmm0,xmm0,xmm1
vsqrtsd xmm1,xmm0,mmword ptr [7FF94F9E4D70h]
vaddsd xmm0,xmm0,xmm1
vsqrtsd xmm1,xmm0,mmword ptr [7FF94F9E4D78h]
vaddsd xmm0,xmm0,xmm1
vsqrtsd xmm1,xmm0,mmword ptr [7FF94F9E4D80h]
vaddsd xmm0,xmm0,xmm1
vsqrtsd xmm1,xmm0,mmword ptr [7FF94F9E4D88h]
vaddsd xmm0,xmm0,xmm1
ret
26/52 6. Constant folding](https://image.slidesharecdn.com/devfestakinshin-170929125407/85/slide-42-320.jpg)
![Как же так?
RyuJIT-x64, Sqrt14
vmovsd xmm0,qword ptr [7FF94F9C4C80h]
ret
27/52 6. Constant folding](https://image.slidesharecdn.com/devfestakinshin-170929125407/85/slide-43-320.jpg)

![Как же так?
Constant folding в действии
N001 [000001] dconst 1.0000000000000000 => $c0 {DblCns[1.000000]}
N002 [000002] mathFN => $c0 {DblCns[1.000000]}
N003 [000003] dconst 2.0000000000000000 => $c1 {DblCns[2.000000]}
N004 [000004] mathFN => $c2 {DblCns[1.414214]}
N005 [000005] + => $c3 {DblCns[2.414214]}
N006 [000006] dconst 3.0000000000000000 => $c4 {DblCns[3.000000]}
N007 [000007] mathFN => $c5 {DblCns[1.732051]}
N008 [000008] + => $c6 {DblCns[4.146264]}
N009 [000009] dconst 4.0000000000000000 => $c7 {DblCns[4.000000]}
N010 [000010] mathFN => $c1 {DblCns[2.000000]}
N011 [000011] + => $c8 {DblCns[6.146264]}
N012 [000012] dconst 5.0000000000000000 => $c9 {DblCns[5.000000]}
N013 [000013] mathFN => $ca {DblCns[2.236068]}
N014 [000014] + => $cb {DblCns[8.382332]}
N015 [000015] dconst 6.0000000000000000 => $cc {DblCns[6.000000]}
N016 [000016] mathFN => $cd {DblCns[2.449490]}
N017 [000017] + => $ce {DblCns[10.831822]}
N018 [000018] dconst 7.0000000000000000 => $cf {DblCns[7.000000]}
N019 [000019] mathFN => $d0 {DblCns[2.645751]}
N020 [000020] + => $d1 {DblCns[13.477573]}
...
29/52 6. Constant folding](https://image.slidesharecdn.com/devfestakinshin-170929125407/85/slide-45-320.jpg)

![Ещё один весёлый пример
private int[,] a;
[Params(511, 512, 513)] public int N;
[Setup] public void Setup() => a = new int[N, N];
// Ищем максимальный элемент в колонке
[Benchmark] public int Max() {
int max = 0;
for (int i = 0; i < N; i++)
max = Math.Max(max, a[i, 0]);
return max;
}
∗
Windows 10, .NET 4.6.2, LegacyJIT-x86, Skylake
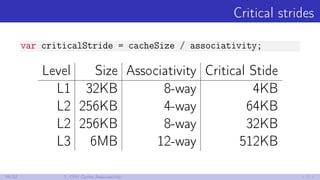
31/52 7. CPU Cache Associativity](https://image.slidesharecdn.com/devfestakinshin-170929125407/85/slide-47-320.jpg)

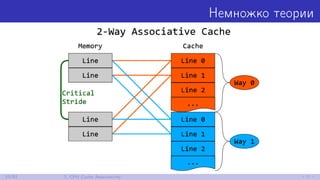



![Очень простые структурки
public struct Struct3 {
public byte X1, X2, X3;
}
public struct Struct8 {
public byte X1, X2, X3, X4, X5, X6, X7, X8;
}
private Struct3[] struct3 = new Struct3[256];
private Struct8[] struct8 = new Struct8[256];
37/52 8. Выравнивание](https://image.slidesharecdn.com/devfestakinshin-170929125407/85/slide-54-320.jpg)
![Очень простой бенчмарк
[Benchmark] public int S3() {
int res = 0;
for (int i = 0; i < struct3.Length; i++) {
var s = struct3[i]; res += s.X1 + s.X2;
}
return res;
}
[Benchmark] public int S8() {
int res = 0;
for (int i = 0; i < struct8.Length; i++) {
var s = struct8[i]; res += s.X1 + s.X2;
}
return res;
}
38/52 8. Выравнивание](https://image.slidesharecdn.com/devfestakinshin-170929125407/85/slide-55-320.jpg)
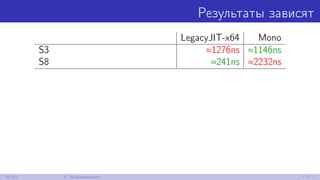

![Тот же самый бенчмарк
// А что будет под RyuJIT-x64?
[Benchmark] public int S3() {
int res = 0;
for (int i = 0; i < struct3.Length; i++) {
var s = struct3[i]; res += s.X1 + s.X2;
}
return res;
}
[Benchmark] public int S8() {
int res = 0;
for (int i = 0; i < struct8.Length; i++) {
var s = struct8[i]; res += s.X1 + s.X2;
}
return res;
}
40/52 8. Выравнивание](https://image.slidesharecdn.com/devfestakinshin-170929125407/85/slide-58-320.jpg)

![Смотрим ASM
; *** S3 ***
; res += s.X1 + s.X2;
add eax, r10d
add eax, r9d
; *** S8 ***
; res += s.X1 + s.X2;
movzx r9d, byte ptr [rsp+20h]
add eax, r9d
movzx r9d, byte ptr [rsp+21h]
add eax, r9d
42/52 8. Выравнивание](https://image.slidesharecdn.com/devfestakinshin-170929125407/85/slide-60-320.jpg)







Документ исследует сложности микробенчмаркинга на примере C#, обсуждая важность и применение бенчмарков для анализа производительности и сравнения алгоритмов. В ходе презентации рассматриваются различные аспекты, такие как количество итераций, работа с памятью, условные переходы и эффект наблюдателя. Также упоминается о наблюдении производительности программ и оптимизации через постоянное складывание.






























































