Download to read offline













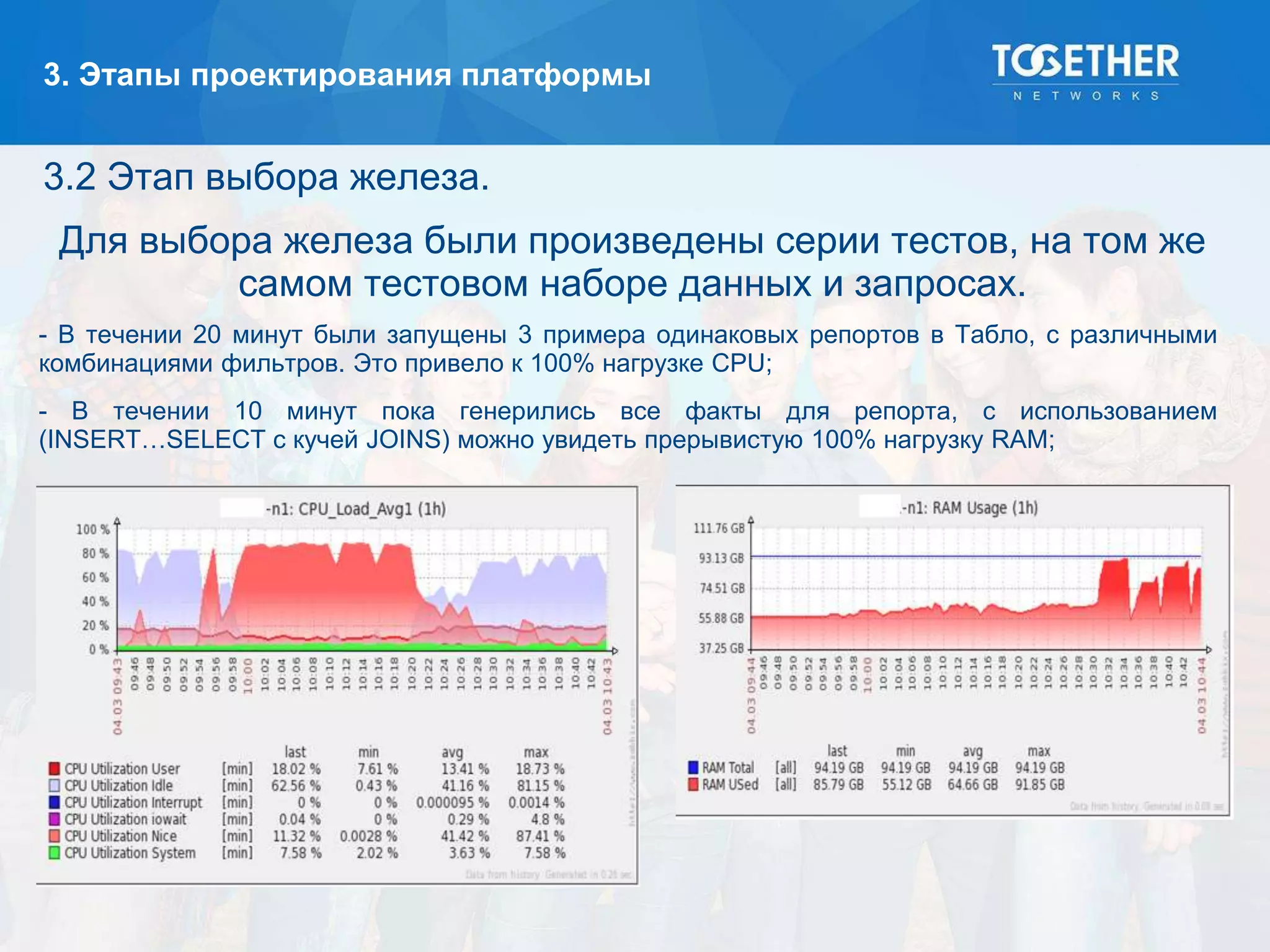
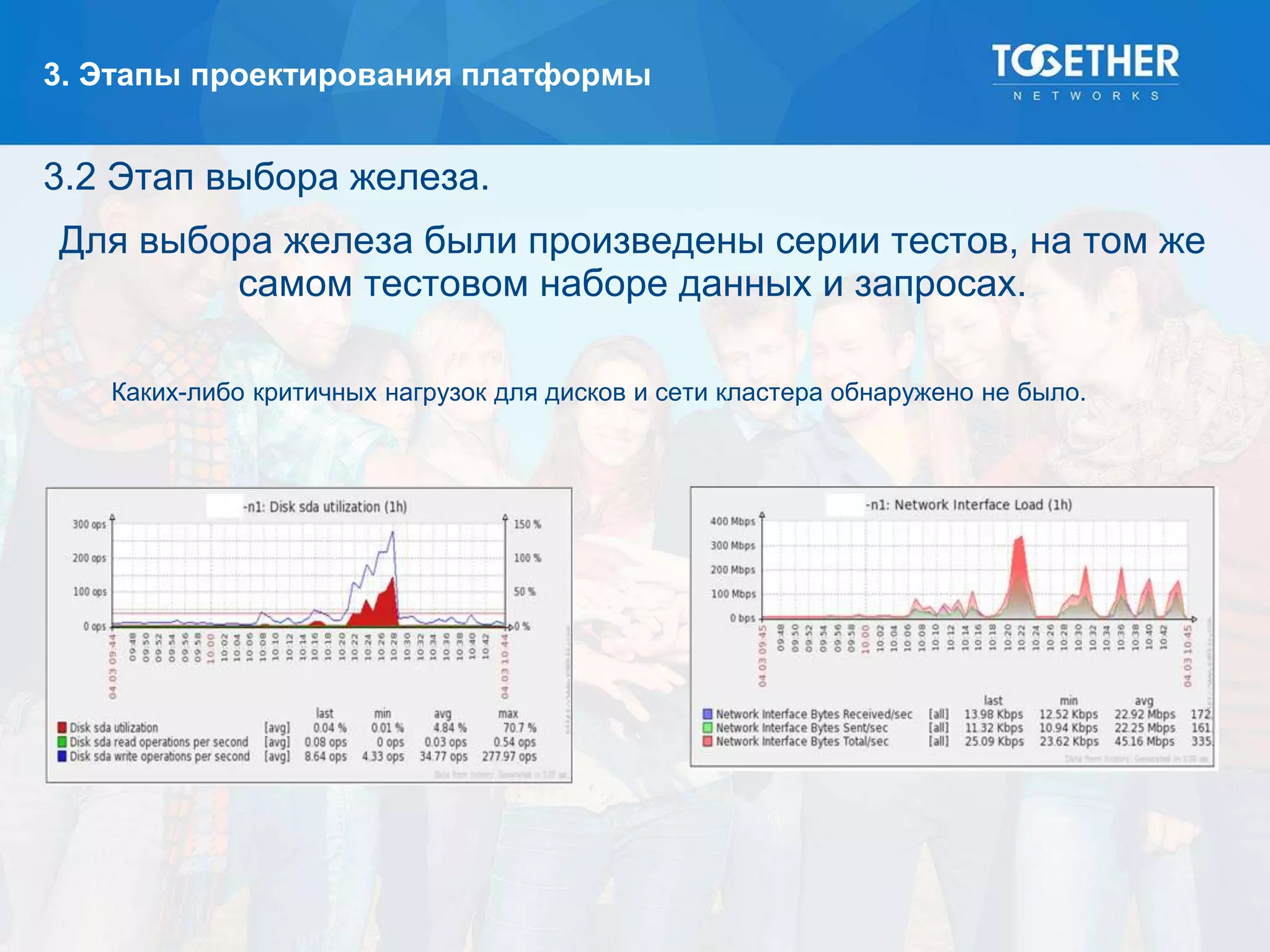






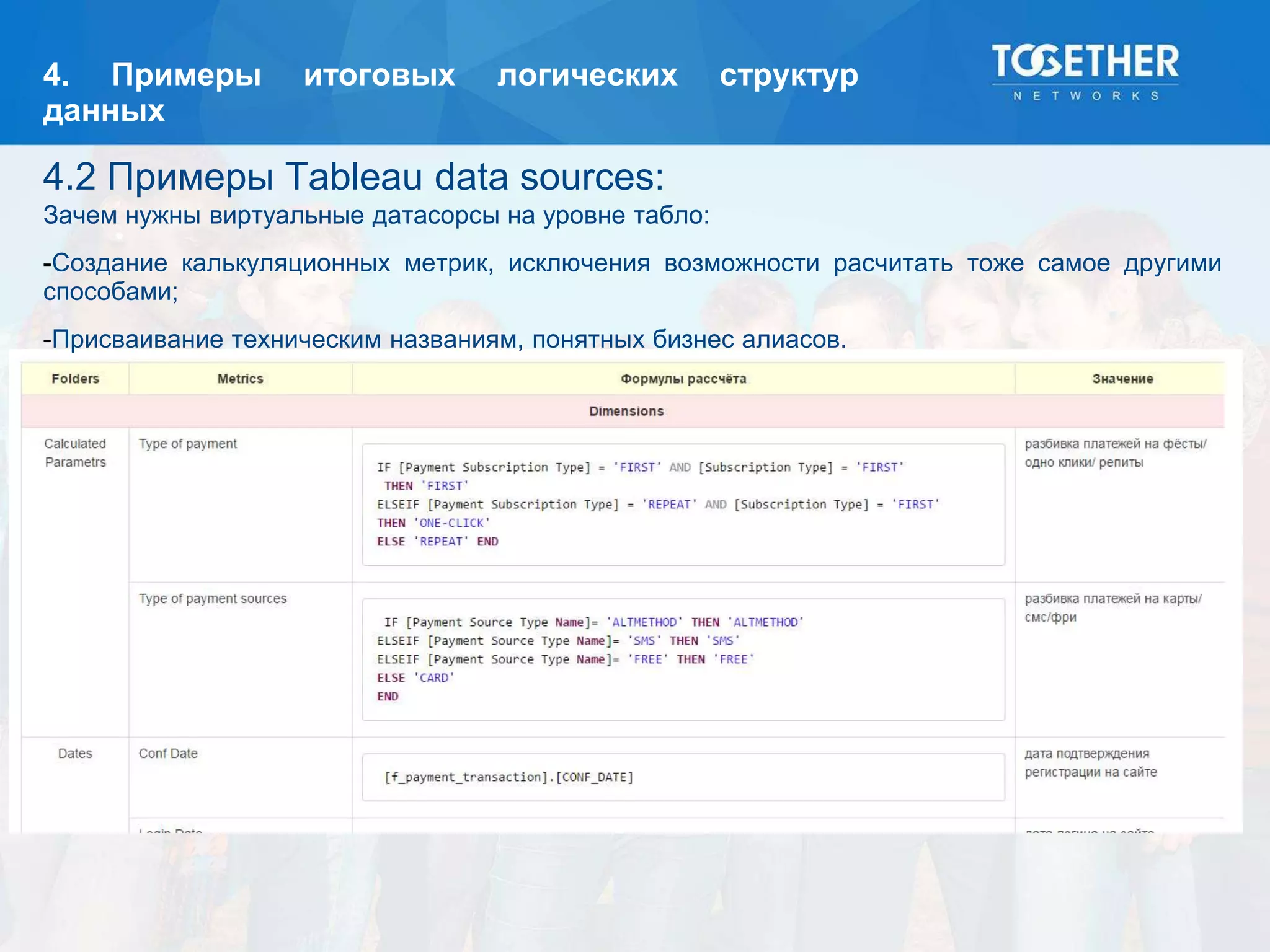

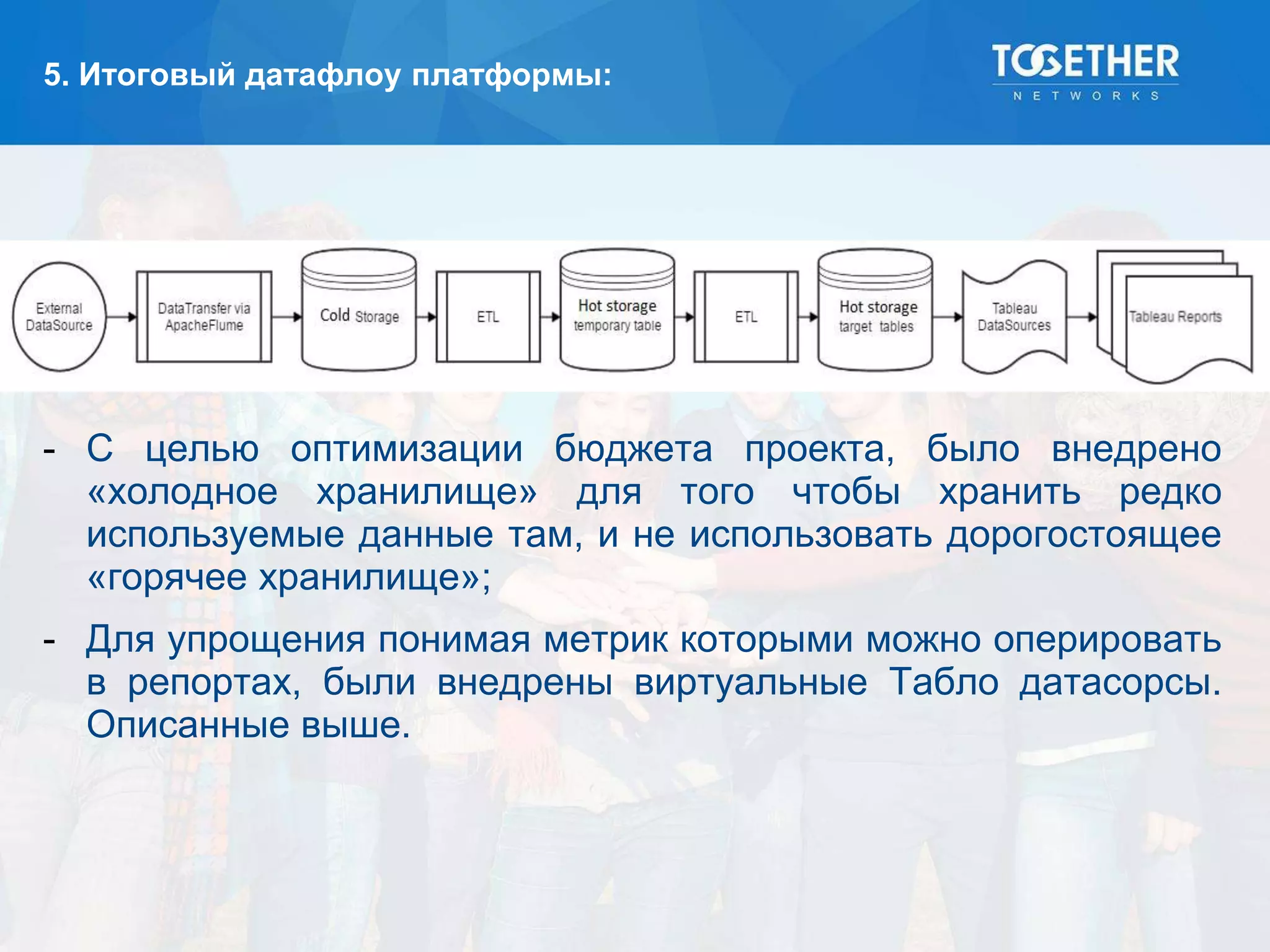

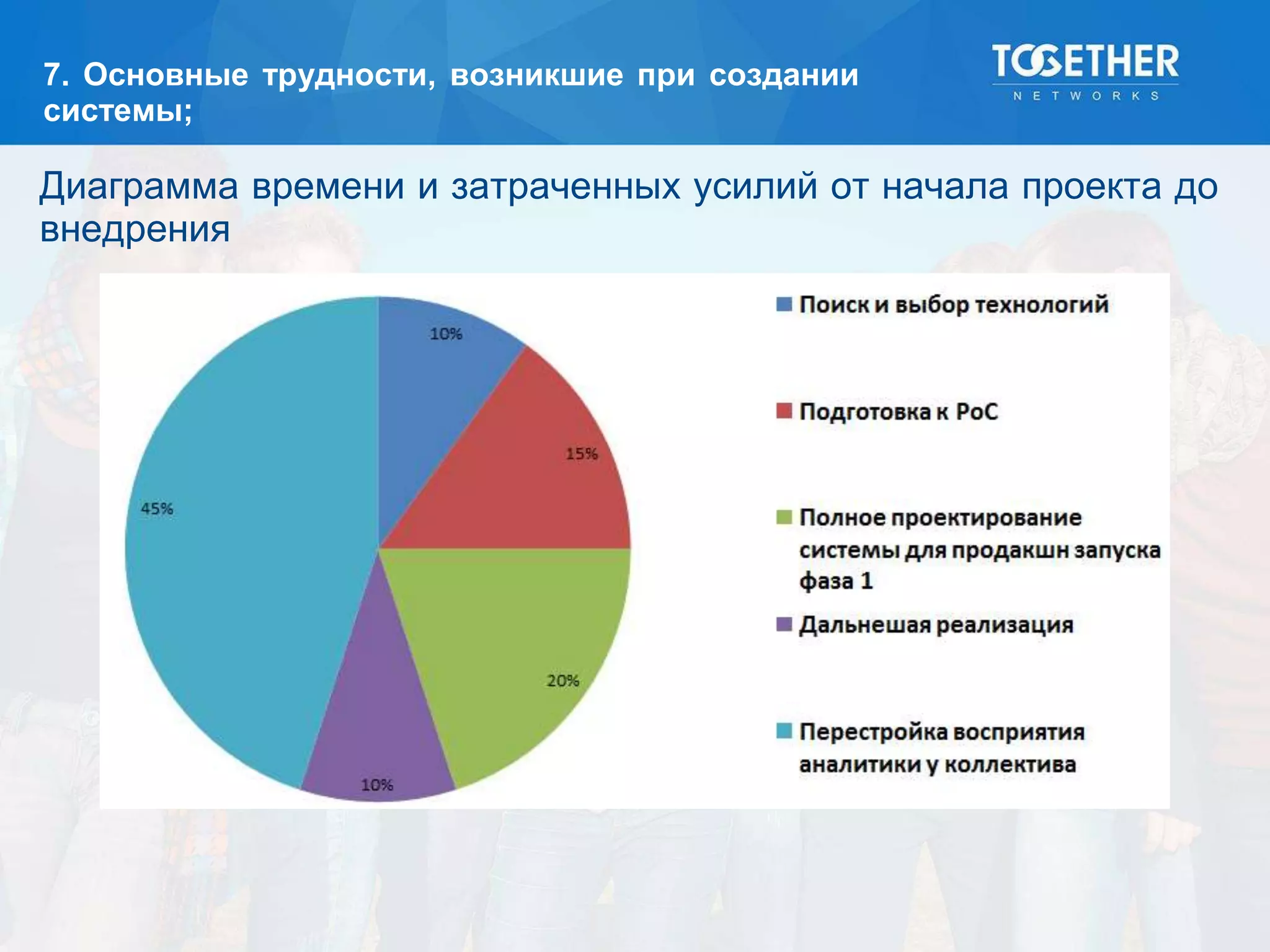
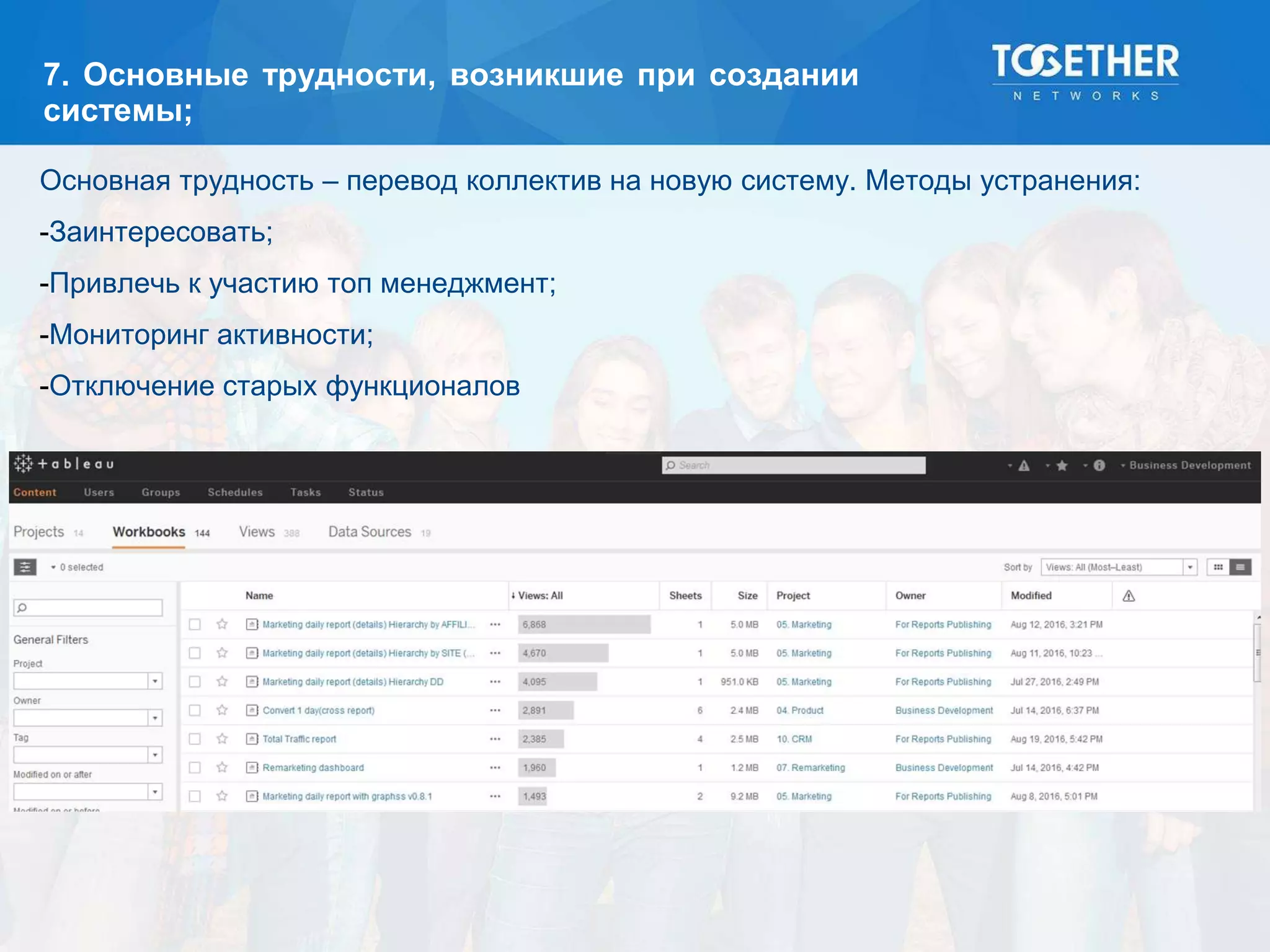
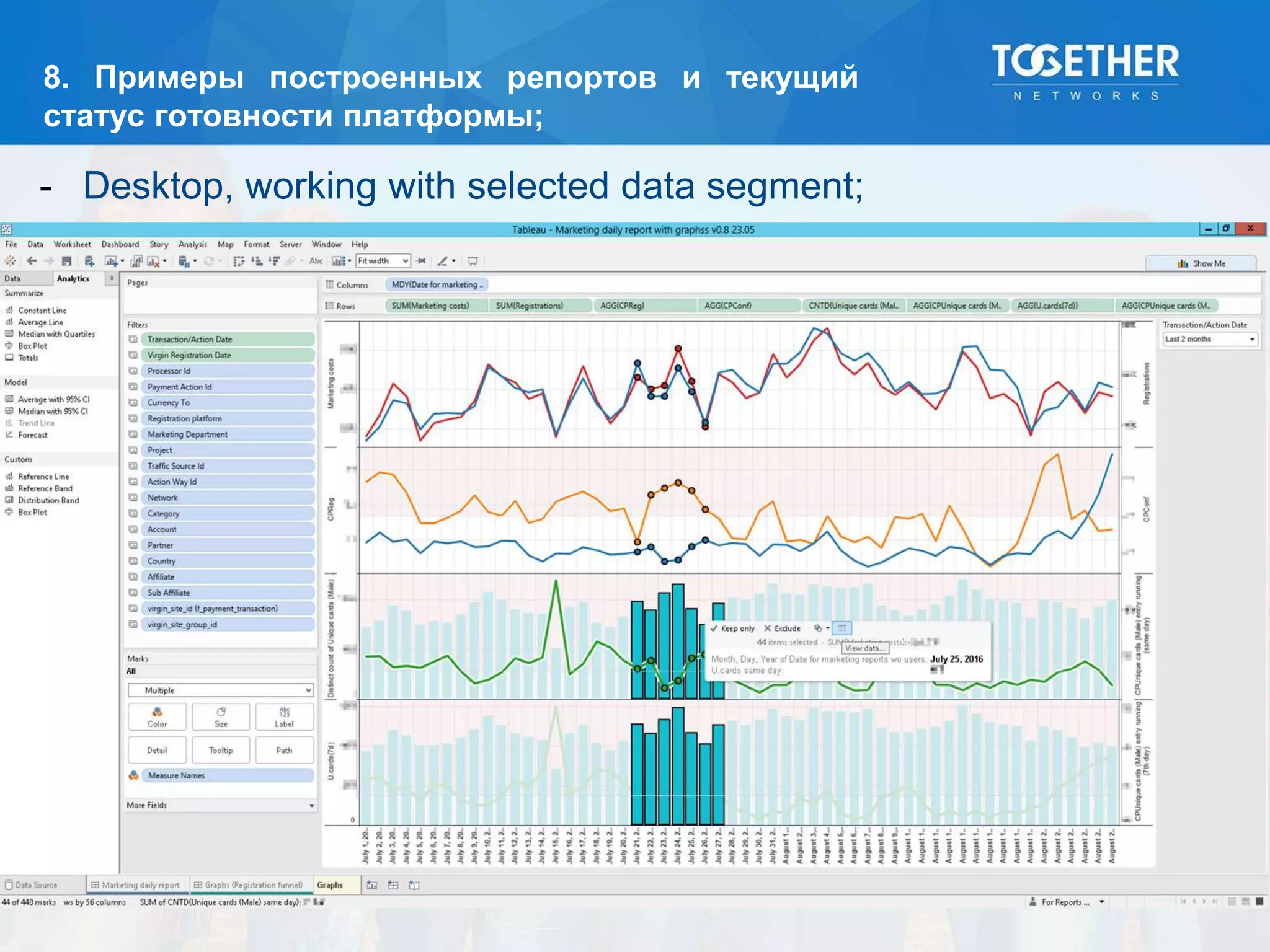

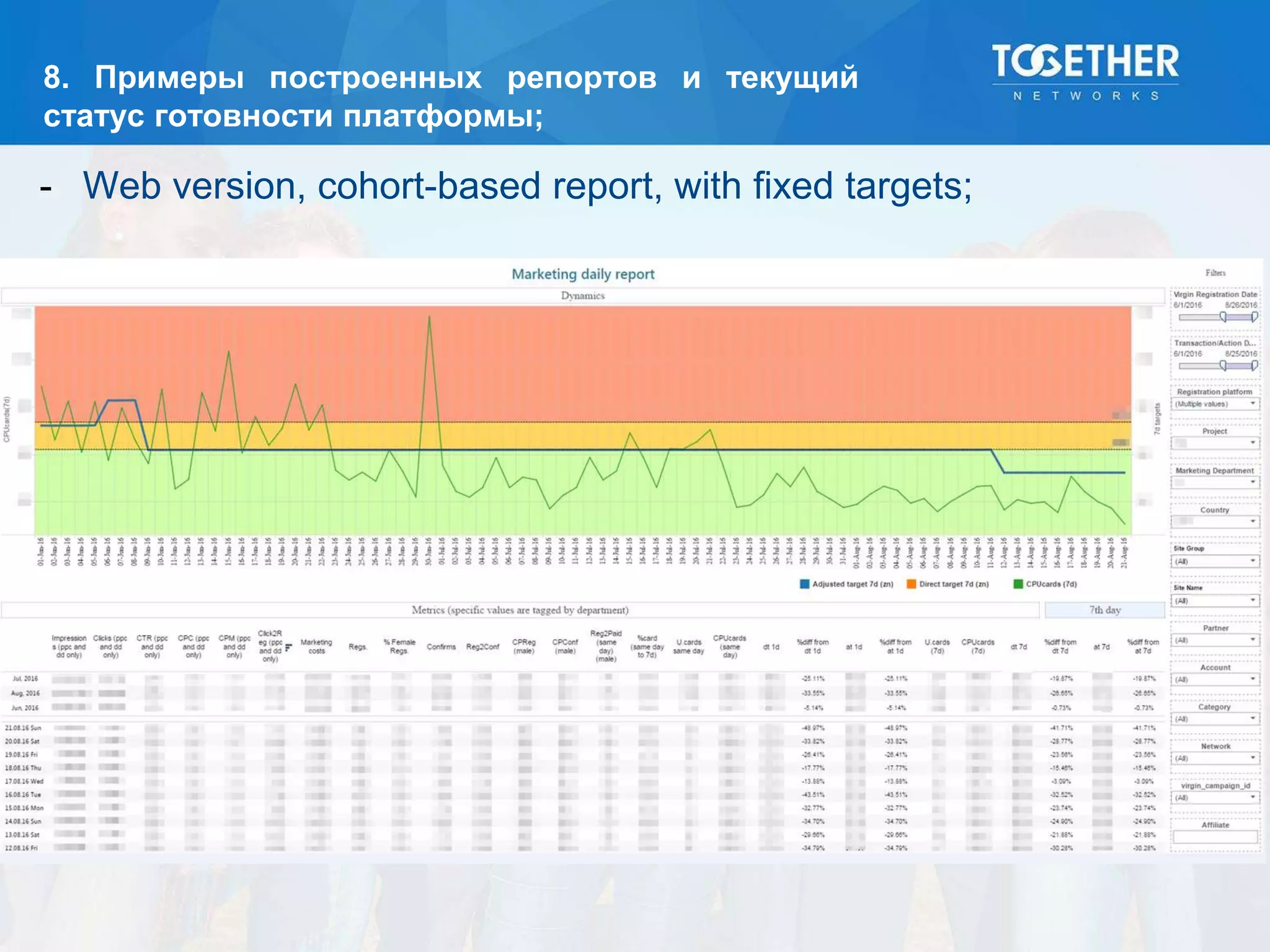
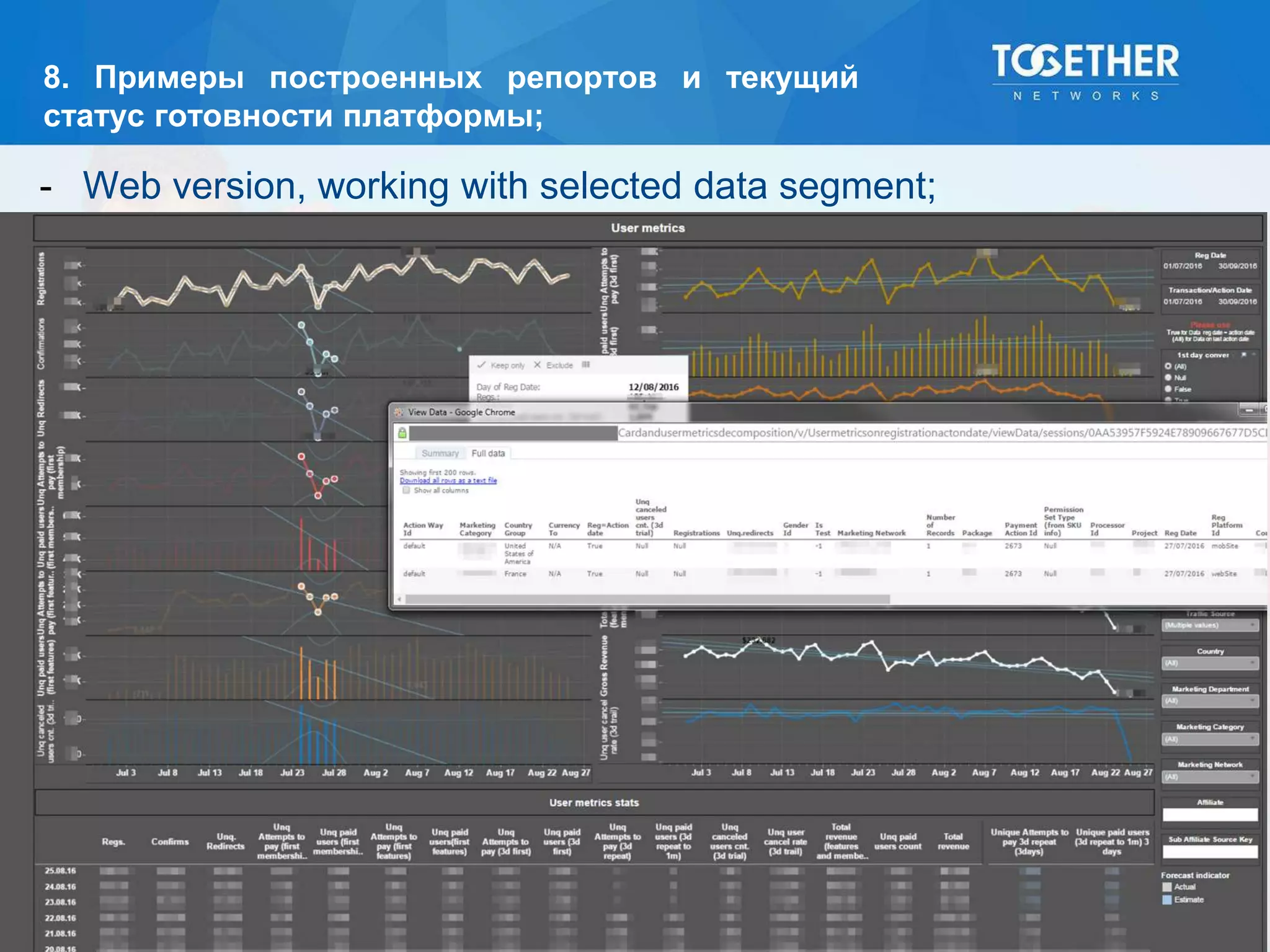
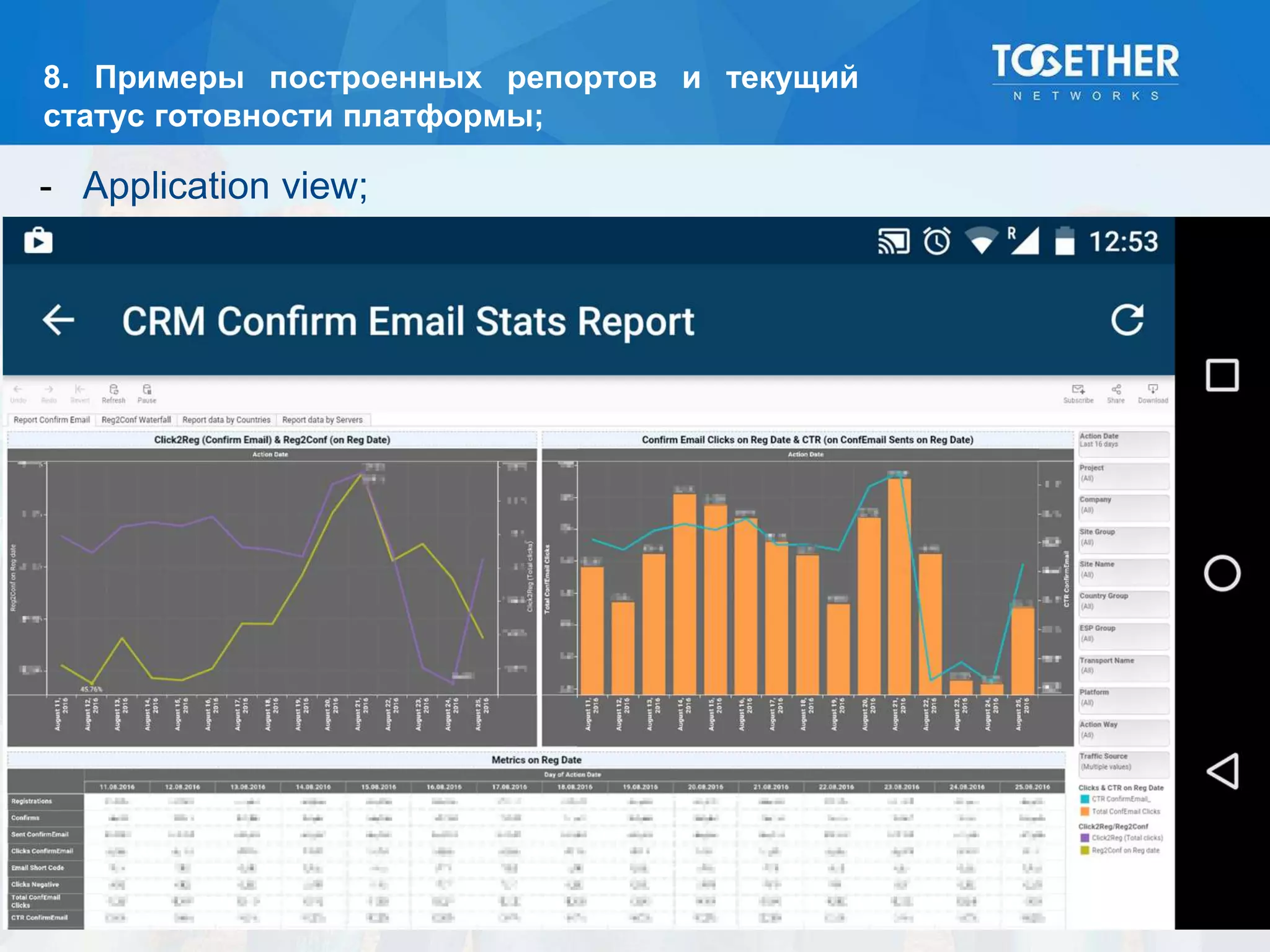




Документ описывает процесс построения и перехода на новую аналитическую платформу, включая существующие недостатки старой системы и этапы выбора технологий. Рассматриваются детали проектирования, выбор моделей данных, тестирование масштабируемости и сложности, возникшие в проекте. В конце подводятся итоги по окупаемости и результатам работы новой платформы.








































