Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
nagix
1,478 views
大規模データ分析を支えるインフラ系オープンソースソフトウェアの最新事情
みんなのPython勉強会#13での発表資料です。
Data & Analytics
◦
Read more
5
Save
Share
Embed
Embed presentation
Download
Downloaded 18 times
1
/ 34
2
/ 34
3
/ 34
4
/ 34
5
/ 34
6
/ 34
7
/ 34
8
/ 34
9
/ 34
10
/ 34
11
/ 34
12
/ 34
13
/ 34
14
/ 34
15
/ 34
16
/ 34
17
/ 34
18
/ 34
19
/ 34
20
/ 34
21
/ 34
22
/ 34
23
/ 34
24
/ 34
25
/ 34
26
/ 34
27
/ 34
28
/ 34
29
/ 34
30
/ 34
31
/ 34
32
/ 34
33
/ 34
34
/ 34
More Related Content
PDF
データ分析を支える技術 DWH再入門
by
Satoru Ishikawa
PDF
Data Engineering Meetup #1 持続可能なデータ基盤のためのデータの多様性に対する取り組み
by
cyberagent
PDF
トレジャーデータとtableau実現する自動レポーティング
by
Takahiro Inoue
PDF
Tableauが魅せる Data Visualization の世界
by
Takahiro Inoue
PDF
データ分析チームの振り返り
by
Satoshi Noto
PDF
ビッグデータとデータマート
by
株式会社オプト 仙台ラボラトリ
PPTX
Spark Summit 2014 の報告と最近の取り組みについて
by
Recruit Technologies
PPTX
Cassandra - Kylo/Nifi
by
Mao Ito
データ分析を支える技術 DWH再入門
by
Satoru Ishikawa
Data Engineering Meetup #1 持続可能なデータ基盤のためのデータの多様性に対する取り組み
by
cyberagent
トレジャーデータとtableau実現する自動レポーティング
by
Takahiro Inoue
Tableauが魅せる Data Visualization の世界
by
Takahiro Inoue
データ分析チームの振り返り
by
Satoshi Noto
ビッグデータとデータマート
by
株式会社オプト 仙台ラボラトリ
Spark Summit 2014 の報告と最近の取り組みについて
by
Recruit Technologies
Cassandra - Kylo/Nifi
by
Mao Ito
Viewers also liked
PDF
DBエンジニアに必要だったPythonのスキル
by
Satoshi Yamada
PDF
Pythonで機械学習入門以前
by
Kimikazu Kato
PDF
[OSC2016沖縄]商用DBからPostgreSQLへの移行入門
by
Kosuke Kida
PPTX
Talend Data Quality - Customer Data Management platform
by
Максим Остархов
PDF
S14 t0 introduction
by
Takeshi Akutsu
PDF
プログラミング学習とScratch raspi python
by
Yoshitaka Shiono
PDF
ビッグデータ関連Oss動向調査とニーズ分析
by
Yukio Yoshida
PDF
見た目だけのデザインと意味を持つデザイン
by
Isezaki Toshiaki
PDF
Hadoopエコシステムの最新動向とNTTデータの取り組み (OSC 2016 Tokyo/Spring 講演資料)
by
NTT DATA OSS Professional Services
PDF
20151129インテリジェントホームロボティクス研究会
by
Komei Sugiura
PDF
Fast Data を扱うためのデザインパターン
by
MapR Technologies Japan
PDF
Cloud from Scratch / ゼロからクラウド構築
by
Tokyo University of Science
PPTX
S13 t0 introduction
by
Takeshi Akutsu
PDF
大分県 未来のIT技術者発見事業「プログラミング体験教室」
by
Kazuhiro Abe
PDF
S03 t2 sta_py_tsuji_0810_slides
by
Takeshi Akutsu
PDF
S09 t0 orientation
by
Takeshi Akutsu
PPTX
Pythonのプロファイリング
by
ysakaguchi
PPTX
Stapy#17LT
by
drillan
PDF
S12 t1 python学習奮闘記#5
by
Takeshi Akutsu
PDF
S10 p1 mitsuyoshi-sama_2
by
Takeshi Akutsu
DBエンジニアに必要だったPythonのスキル
by
Satoshi Yamada
Pythonで機械学習入門以前
by
Kimikazu Kato
[OSC2016沖縄]商用DBからPostgreSQLへの移行入門
by
Kosuke Kida
Talend Data Quality - Customer Data Management platform
by
Максим Остархов
S14 t0 introduction
by
Takeshi Akutsu
プログラミング学習とScratch raspi python
by
Yoshitaka Shiono
ビッグデータ関連Oss動向調査とニーズ分析
by
Yukio Yoshida
見た目だけのデザインと意味を持つデザイン
by
Isezaki Toshiaki
Hadoopエコシステムの最新動向とNTTデータの取り組み (OSC 2016 Tokyo/Spring 講演資料)
by
NTT DATA OSS Professional Services
20151129インテリジェントホームロボティクス研究会
by
Komei Sugiura
Fast Data を扱うためのデザインパターン
by
MapR Technologies Japan
Cloud from Scratch / ゼロからクラウド構築
by
Tokyo University of Science
S13 t0 introduction
by
Takeshi Akutsu
大分県 未来のIT技術者発見事業「プログラミング体験教室」
by
Kazuhiro Abe
S03 t2 sta_py_tsuji_0810_slides
by
Takeshi Akutsu
S09 t0 orientation
by
Takeshi Akutsu
Pythonのプロファイリング
by
ysakaguchi
Stapy#17LT
by
drillan
S12 t1 python学習奮闘記#5
by
Takeshi Akutsu
S10 p1 mitsuyoshi-sama_2
by
Takeshi Akutsu
Similar to 大規模データ分析を支えるインフラ系オープンソースソフトウェアの最新事情
PPTX
ビッグデータ処理データベースの全体像と使い分け 2018年version
by
Tetsutaro Watanabe
PPTX
ビッグデータ処理データベースの全体像と使い分け - 2017年 Version -
by
Tetsutaro Watanabe
PDF
Data platformdesign
by
Ryoma Nagata
PPTX
大量のデータ処理や分析に使えるOSS Apache Sparkのご紹介(Open Source Conference 2020 Online/Kyoto ...
by
NTT DATA Technology & Innovation
PDF
初めてのデータ分析基盤構築をまかされた、その時何を考えておくと良いのか
by
Techon Organization
PPTX
データサイエンティスト協会 セミナー2016 第2回 2016年7月19日
by
Atsushi Tsuchiya
PDF
成功事例に学べ! これからの時代のビッグデータ活用最新ベストプラクティス [Oracle Cloud Days Tokyo 2016]
by
オラクルエンジニア通信
PDF
[Oracle Innovation Summit Tokyo 2018] 水環境の持続を支えるクラウド型ICTプラットフォーム「Water Busine...
by
オラクルエンジニア通信
PDF
tut_pfi_2012
by
Preferred Networks
PDF
避けては通れないビッグデータ周辺の重要課題
by
kurikiyo
PPTX
ビックデータ処理技術の全体像とリクルートでの使い分け
by
Tetsutaro Watanabe
PDF
デジタル化への第一歩 「エンタープライズデータレイク構築事例のご紹介」
by
BeeX.inc
PDF
変わる!? リクルートグループのデータ解析基盤
by
Recruit Technologies
PDF
ビッグデータ分析基盤を支えるOSSたち
by
Toru Takahashi
PDF
データサイエンスとデータエンジニア
by
nagix
PDF
【講演資料】ビッグデータ時代の経営を支えるビジネスアナリティクスソリューション
by
Dell TechCenter Japan
PDF
Open Cloud Innovation2016 day1(これからのデータ分析者とエンジニアに必要なdatascienceexperienceツールと...
by
Atsushi Tsuchiya
PDF
S01 t3 data_engineer
by
Takeshi Akutsu
PDF
[INSIGHT OUT 2011] b21 ひとつのデータベース技術では生き残れない part2 no sql, hadoop
by
Insight Technology, Inc.
PDF
ビッグデータによる価値創造を実現するデータ収集・蓄積・分析クラウドサービス “簡単!賢く!データを活かす!”東芝データレイクサービスの取り組みのご紹介
by
griddb
ビッグデータ処理データベースの全体像と使い分け 2018年version
by
Tetsutaro Watanabe
ビッグデータ処理データベースの全体像と使い分け - 2017年 Version -
by
Tetsutaro Watanabe
Data platformdesign
by
Ryoma Nagata
大量のデータ処理や分析に使えるOSS Apache Sparkのご紹介(Open Source Conference 2020 Online/Kyoto ...
by
NTT DATA Technology & Innovation
初めてのデータ分析基盤構築をまかされた、その時何を考えておくと良いのか
by
Techon Organization
データサイエンティスト協会 セミナー2016 第2回 2016年7月19日
by
Atsushi Tsuchiya
成功事例に学べ! これからの時代のビッグデータ活用最新ベストプラクティス [Oracle Cloud Days Tokyo 2016]
by
オラクルエンジニア通信
[Oracle Innovation Summit Tokyo 2018] 水環境の持続を支えるクラウド型ICTプラットフォーム「Water Busine...
by
オラクルエンジニア通信
tut_pfi_2012
by
Preferred Networks
避けては通れないビッグデータ周辺の重要課題
by
kurikiyo
ビックデータ処理技術の全体像とリクルートでの使い分け
by
Tetsutaro Watanabe
デジタル化への第一歩 「エンタープライズデータレイク構築事例のご紹介」
by
BeeX.inc
変わる!? リクルートグループのデータ解析基盤
by
Recruit Technologies
ビッグデータ分析基盤を支えるOSSたち
by
Toru Takahashi
データサイエンスとデータエンジニア
by
nagix
【講演資料】ビッグデータ時代の経営を支えるビジネスアナリティクスソリューション
by
Dell TechCenter Japan
Open Cloud Innovation2016 day1(これからのデータ分析者とエンジニアに必要なdatascienceexperienceツールと...
by
Atsushi Tsuchiya
S01 t3 data_engineer
by
Takeshi Akutsu
[INSIGHT OUT 2011] b21 ひとつのデータベース技術では生き残れない part2 no sql, hadoop
by
Insight Technology, Inc.
ビッグデータによる価値創造を実現するデータ収集・蓄積・分析クラウドサービス “簡単!賢く!データを活かす!”東芝データレイクサービスの取り組みのご紹介
by
griddb
大規模データ分析を支えるインフラ系オープンソースソフトウェアの最新事情
1.
大規模データ分析を支えるインフラ系 オープンソースソフトウェアの最新事情 草薙 昭彦 (@nagix) MapR Technologies
2.
自己紹介 • 草薙 昭彦 (@nagix) •
MapR Technologies データエンジニア NS-SHAFT 無料!
3.
一般的な分析のデータフロー 収集 抽出 変換 加工 格納 集計 加工 生成 モデル 作成 可視化 レポート
4.
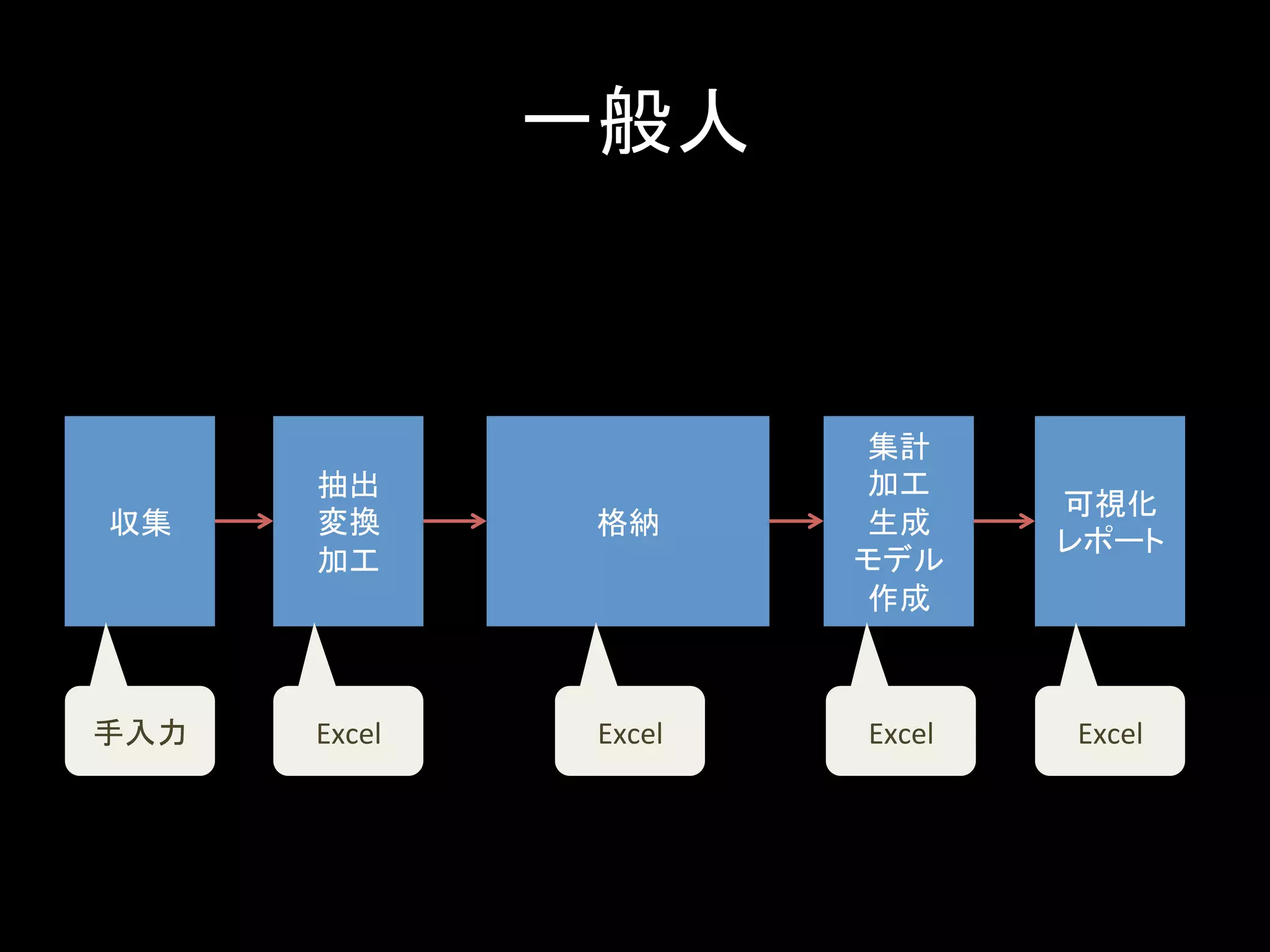
一般人 収集 抽出 変換 加工 格納 集計 加工 生成 モデル 作成 可視化 レポート 手入力 Excel Excel
Excel Excel
5.
一般人 収集 抽出 変換 加工 格納 集計 加工 生成 モデル 作成 可視化 レポート 手入力 Excel Excel
Excel Excel 実は専門家も
6.
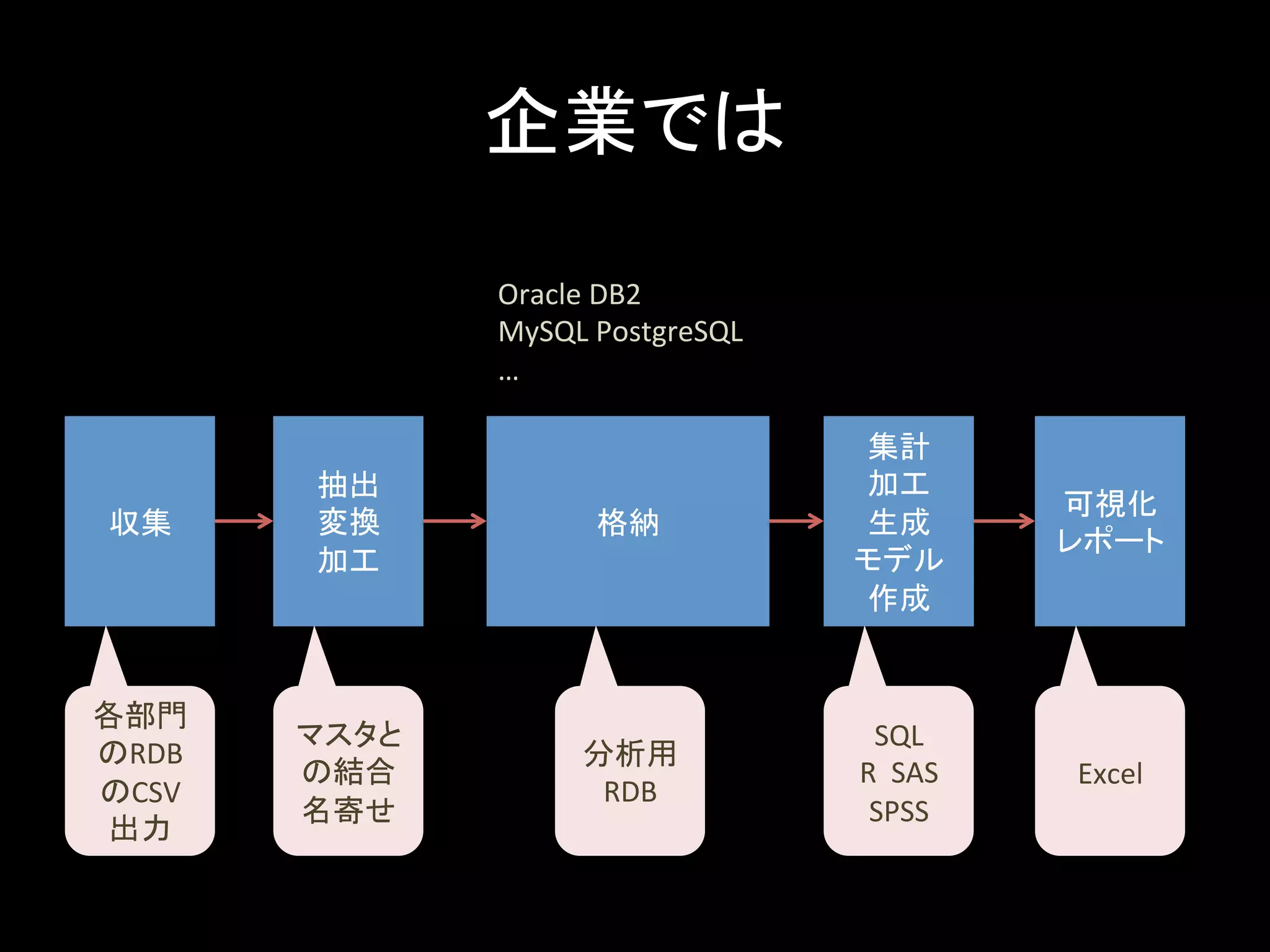
企業では 収集 抽出 変換 加工 格納 集計 加工 生成 モデル 作成 可視化 レポート 各部門 のRDB のCSV 出力 マスタと の結合 名寄せ 分析用 RDB SQL R SAS SPSS Excel Oracle DB2 MySQL PostgreSQL …
7.
組織の規模が大きくなると • データボリューム – 大容量ストレージ・効率の良い格納フォーマット • 処理性能 – データ増や複数ユーザの同時アクセスに対応 •
信頼性・可用性 – ハードウェアのHA化・データの複製 • セキュリティ – 認証・アクセス制御・暗号化・監査
8.
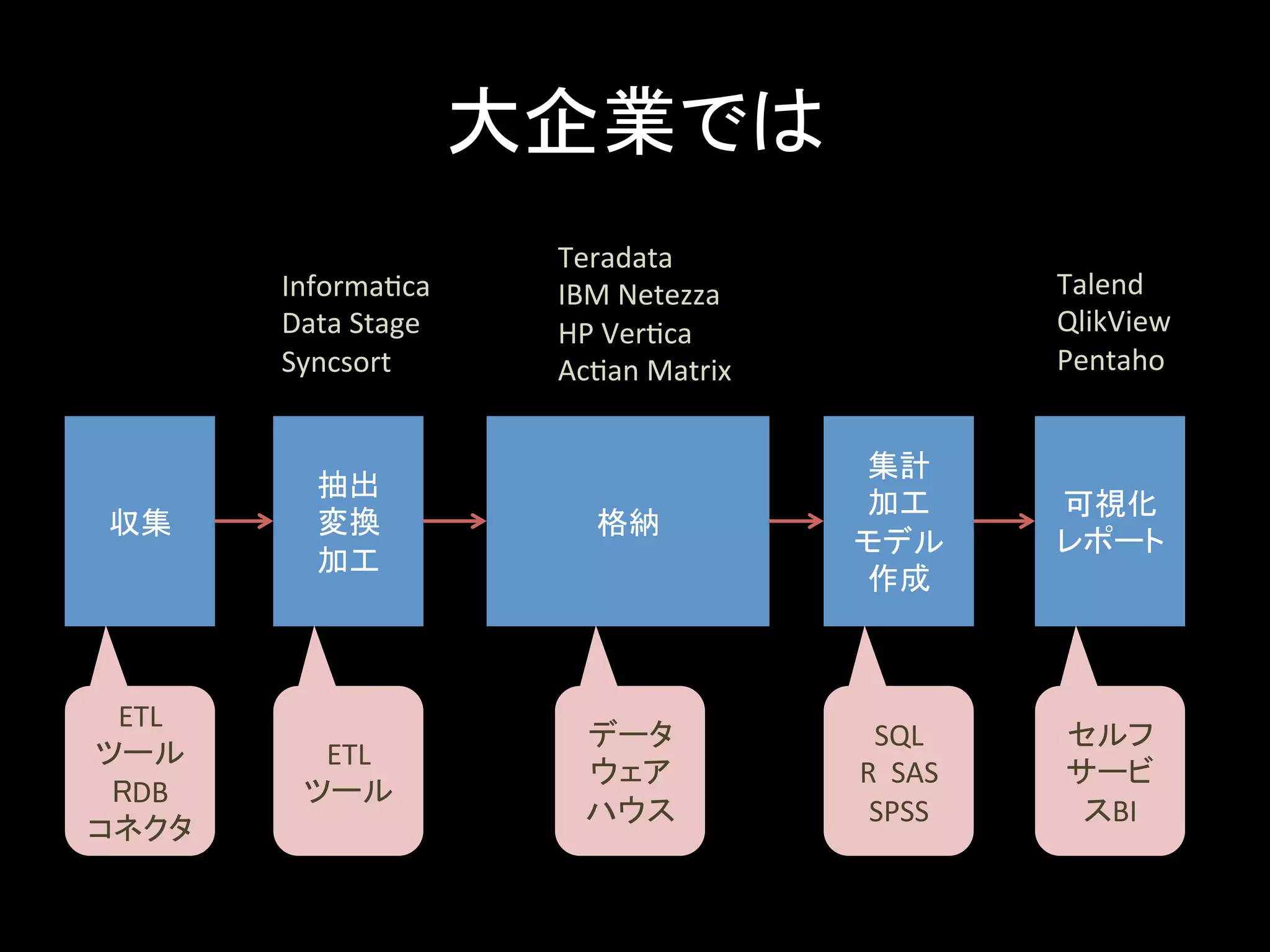
大企業では 収集 抽出 変換 加工 格納 集計 加工 モデル 作成 可視化 レポート ETL ツール RDB コネクタ ETL ツール データ ウェア ハウス SQL R SAS SPSS セルフ サービ スBI Teradata IBM Netezza HP VerLca AcLan Matrix InformaLca Data Stage Syncsort Talend QlikView Pentaho
9.
ビッグデータって何でしたっけ • データボリューム – 従来のアーキテクチャでは処理格納できない量 • データの種類 – 非構造化(=スキーマが確定していない)データ •
データの流入頻度 – 月次・日時バッチ投入から都度の投入へ
10.
大規模なデータを扱う時に重要なこと • スケールアウト(水平スケーラビリティ) • CPUとストレージの距離(データローカリティ) サーバ
・・・ スケールアウト可能なアルゴリズム・データ格納方式 共有ストレージ (NAS/SAN) サーバ レイテンシ の問題 スループット の問題 サーバ サーバ サーバ 内蔵 HDD /SSD 内蔵 HDD /SSD 内蔵 HDD /SSD CPU CPU CPU
11.
大規模なデータを扱う時に重要なこと • Data Gravity(データの重力) Web App Data 分析 App Data 会計 App Data マーケ App Data 販売 App Data 販売 App Data 会計 App マーケ App
12.
分析のROI • 最も重要なのはデータを増やしたとしてもそ れに見合うリターンが得られるかどうか – データが増えれば得られる価値は上がりそう・・ – 問題はコストをいかに抑えることができるか • コモディティハードウェアは必須! •
スケールアウト分散処理ソフトウェアは必須! • オープンソースソフトウェアは有力な選択肢
13.
参考 • Google対Yahoo—インターネット戦争でどうしてここ まで差がついたのかを振り返る hZp://jp.techcrunch.com/2016/05/23/20160522why-google-beat-yahoo-in-the-war-for-the-internet/ – “NetAppハードウェアのコストはYahooの規模の拡大と同 じ速さで増大し、Yahooの利益の大きな部分に食い込むこ ととなった” –
“これに対して Googleは、規模を拡大し新サービスを追加 するときに起きるはずの問題を、それが起きる前に予期し、 効率的に対処できるようGoogle File Systemの開発に全力 を挙げた”
14.
Hadoop ベース分析基盤(初期) 収集 抽出 変換 加工 格納 集計 加工 モデル作成 可視化 レポート ログ コレクタ RDB コネクタ Map Reduce Hive Pig HDFS Map Reduce Hive Pig Mahout セルフ サービ スBI
15.
Hadoopって? サーバ サーバ サーバ
サーバ サーバ サーバ
16.
Hadoopって? サーバ Hadoop Distributed File System (HDFS) データをブロックに 分割して分散配置、 3つのレプリカ作成
17.
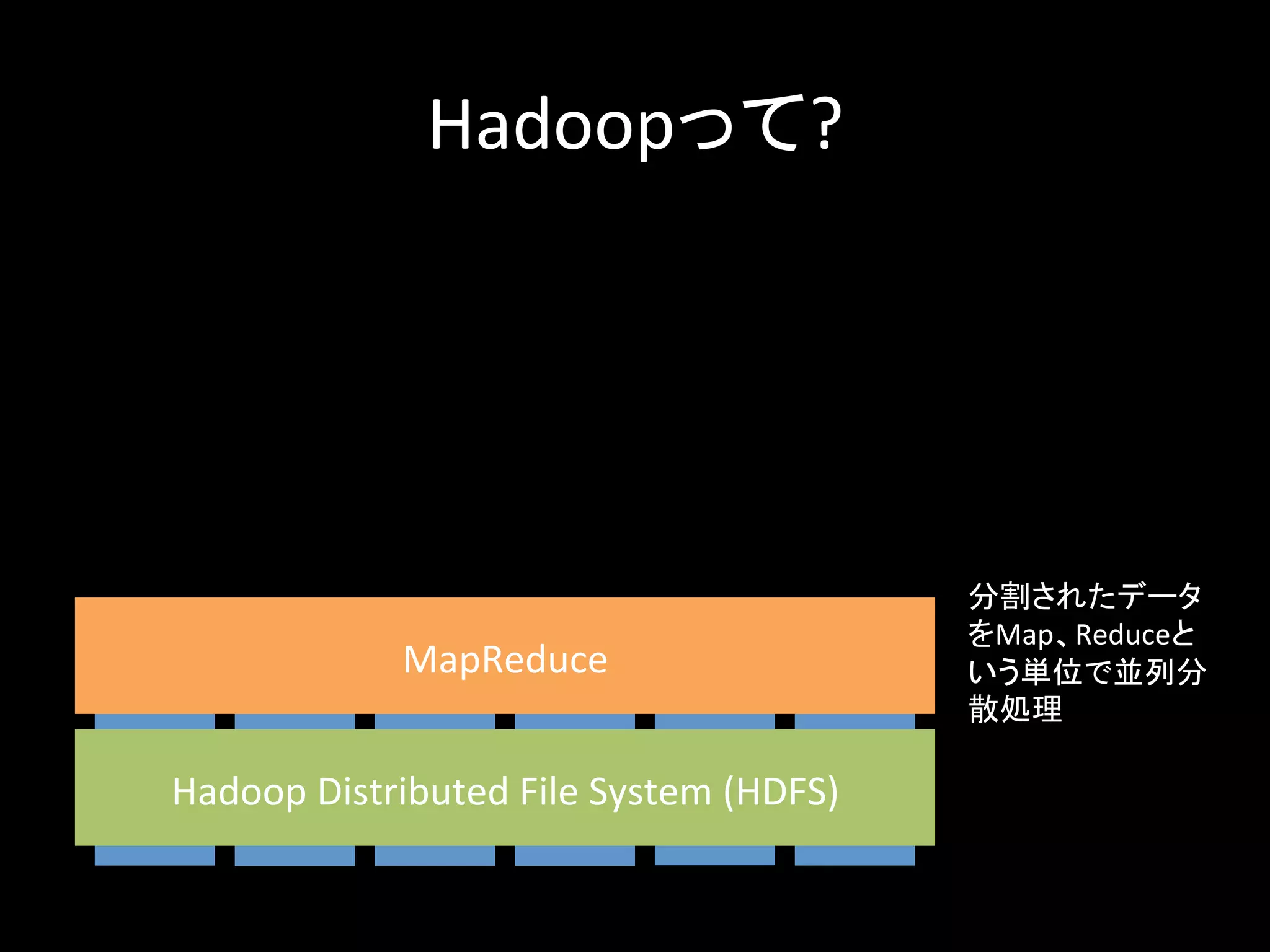
Hadoopって? サーバ Hadoop Distributed File System (HDFS) 分割されたデータ をMap、Reduceと いう単位で並列分 散処理 MapReduce
18.
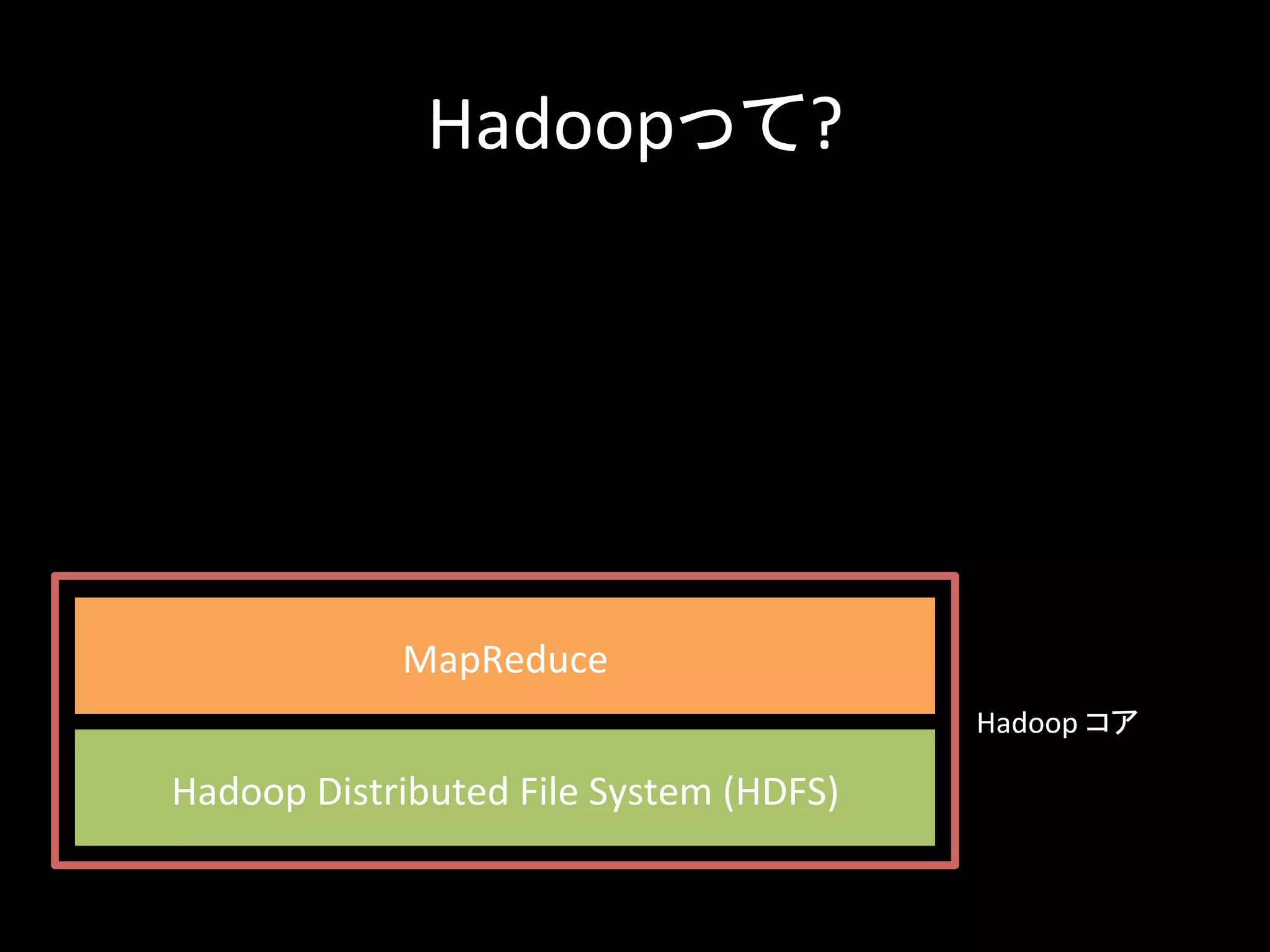
Hadoopって? Hadoop Distributed File System (HDFS) MapReduce Hadoop コア
19.
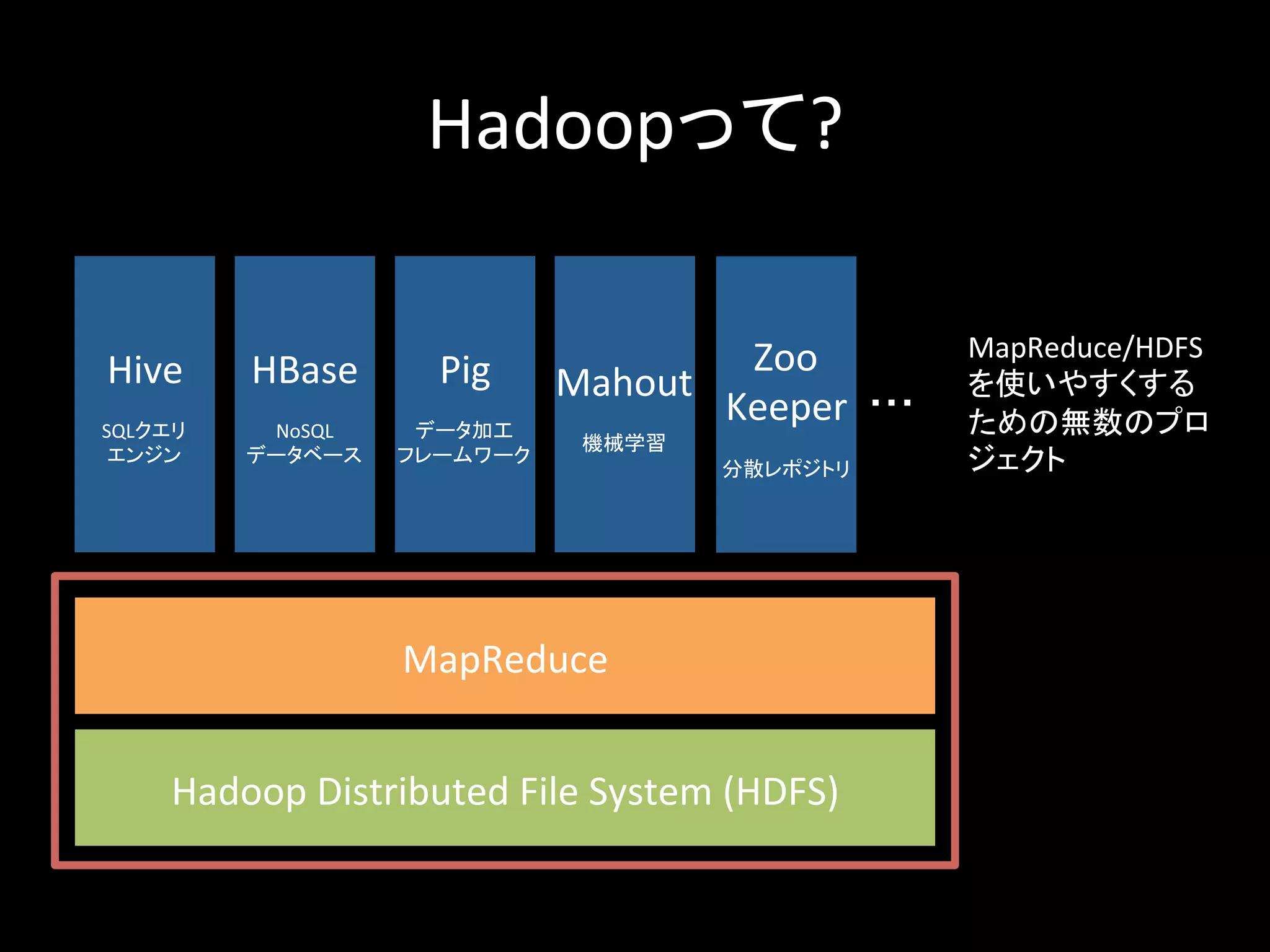
Hadoopって? Hadoop Distributed File System (HDFS) MapReduce Hive SQLクエリ エンジン HBase NoSQL データベース Pig データ加工 フレームワーク Mahout 機械学習 Zoo Keeper 分散レポジトリ ・・・ MapReduce/HDFS を使いやすくする ための無数のプロ ジェクト
20.
Hadoop ベース分析基盤(現在) 収集 抽出 変換 加工 格納 集計 加工 モデル作成 可視化 レポート ログ コレクタ RDB コネクタ Spark Hive Pig HDFS Spark SQL Dashbo ard NoteBo ok Apache Spark Apache Kylin Apache Drill Apache Impala Presto MLLib Oryx Apache Spark Apache Hive Apache Pig Apache Flume Fluentd Jupyter Apache Zeppelin Spark Notebook H2O
21.
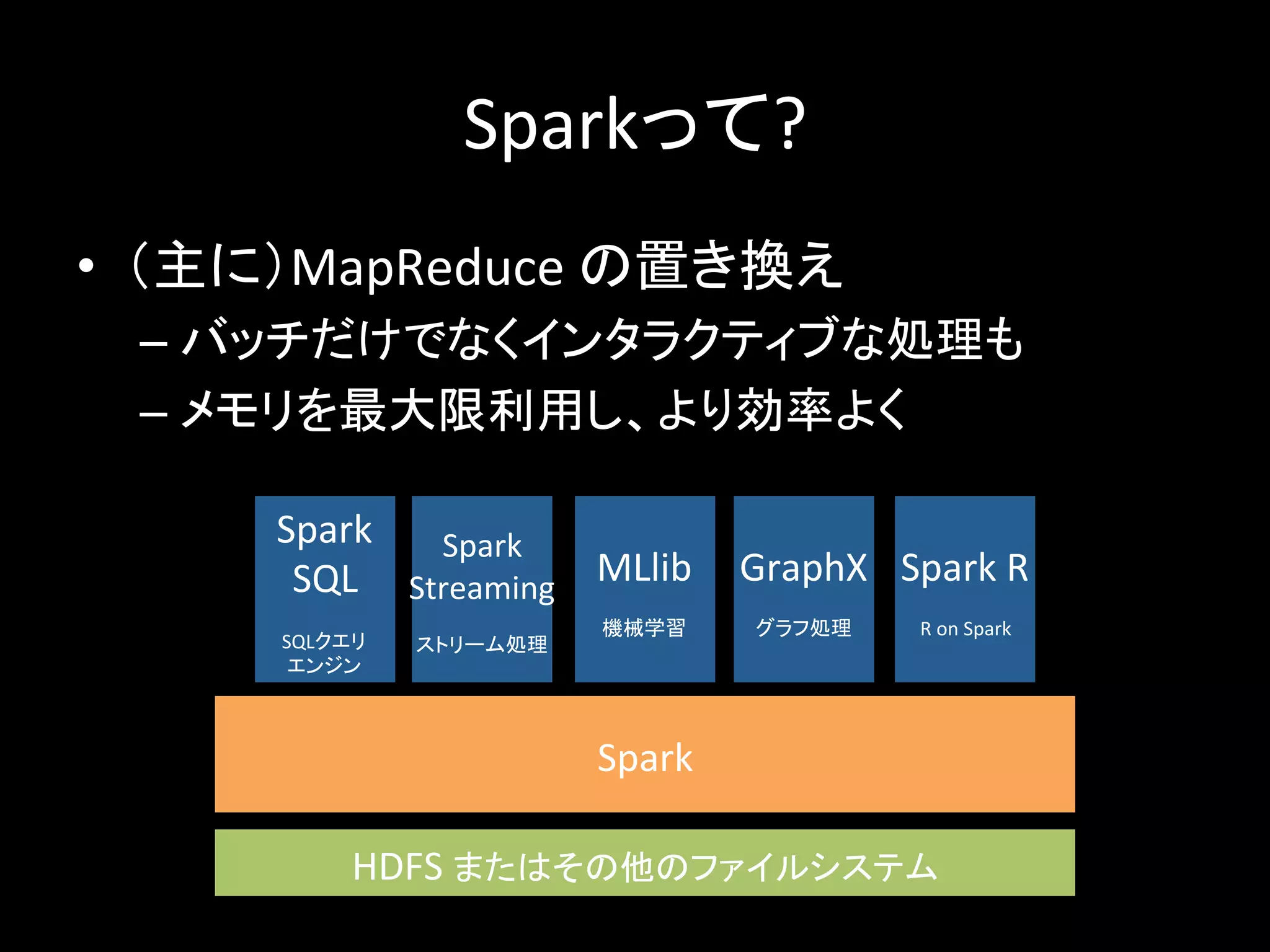
Sparkって? • (主に)MapReduce の置き換え – バッチだけでなくインタラクティブな処理も – メモリを最大限利用し、より効率よく Spark Spark SQL SQLクエリ エンジン Spark Streaming ストリーム処理 MLlib 機械学習 GraphX グラフ処理 Spark R R on Spark HDFS またはその他のファイルシステム
22.
トレンド:リアルタイム処理 • ビジネス側からの要件 – より早い変化の検知、決断、情報の提供 – 業務処理と分析処理は統合へ • データフロー、格納、処理それぞれに新しい アーキテクチャが必要 •
処理の2つのアプローチ – バッチを極限まで細かくしていく(マイクロバッチ) – メッセージを1つ1つ処理していく
23.
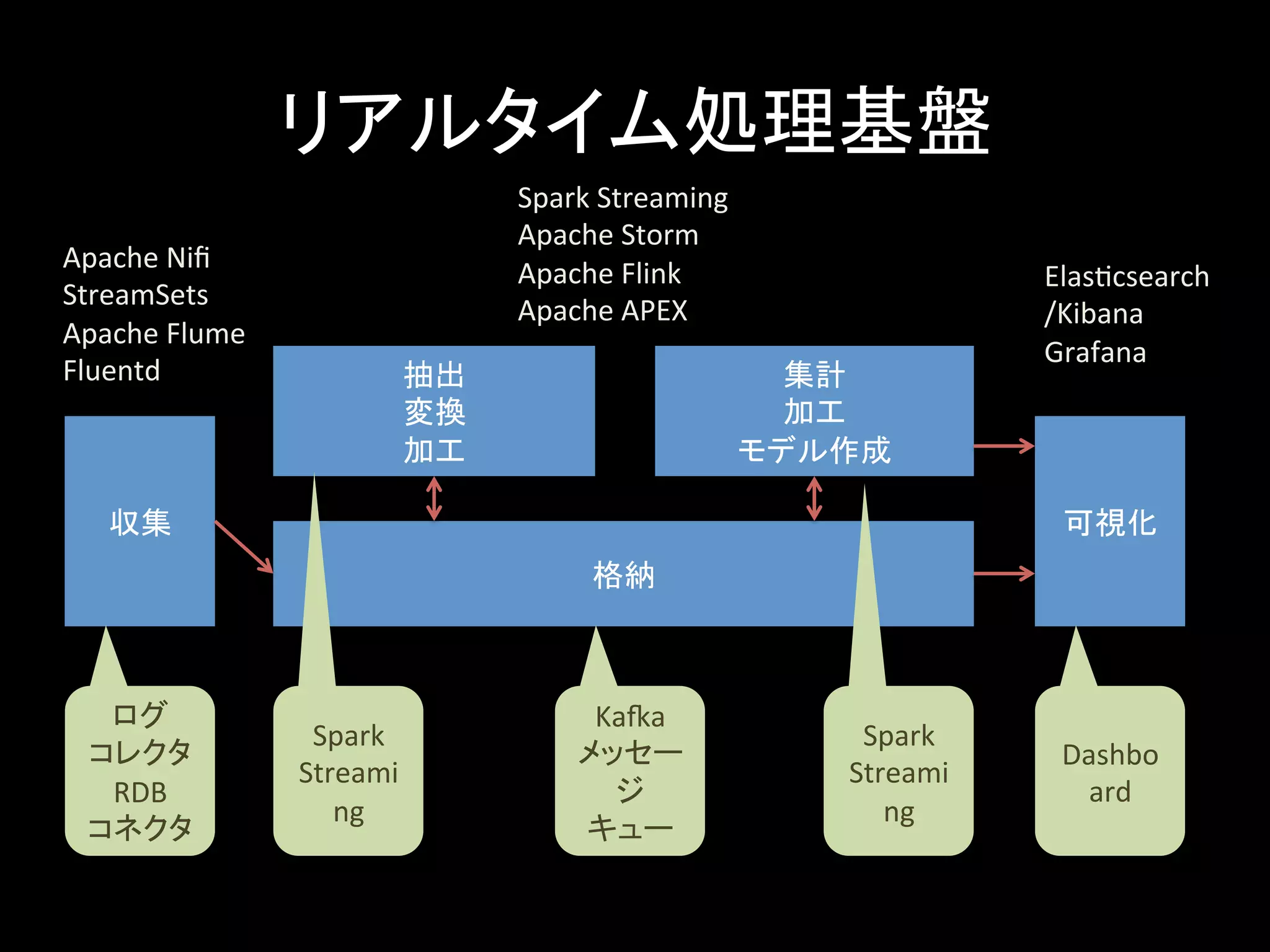
リアルタイム処理基盤 収集 抽出 変換 加工 格納 集計 加工 モデル作成 可視化 ログ コレクタ RDB コネクタ Spark Streami ng Kaka メッセー ジ キュー Spark Streami ng Dashbo ard Spark Streaming Apache Storm Apache Flink Apache APEX Apache Nifi StreamSets Apache Flume Fluentd ElasLcsearch /Kibana Grafana
24.
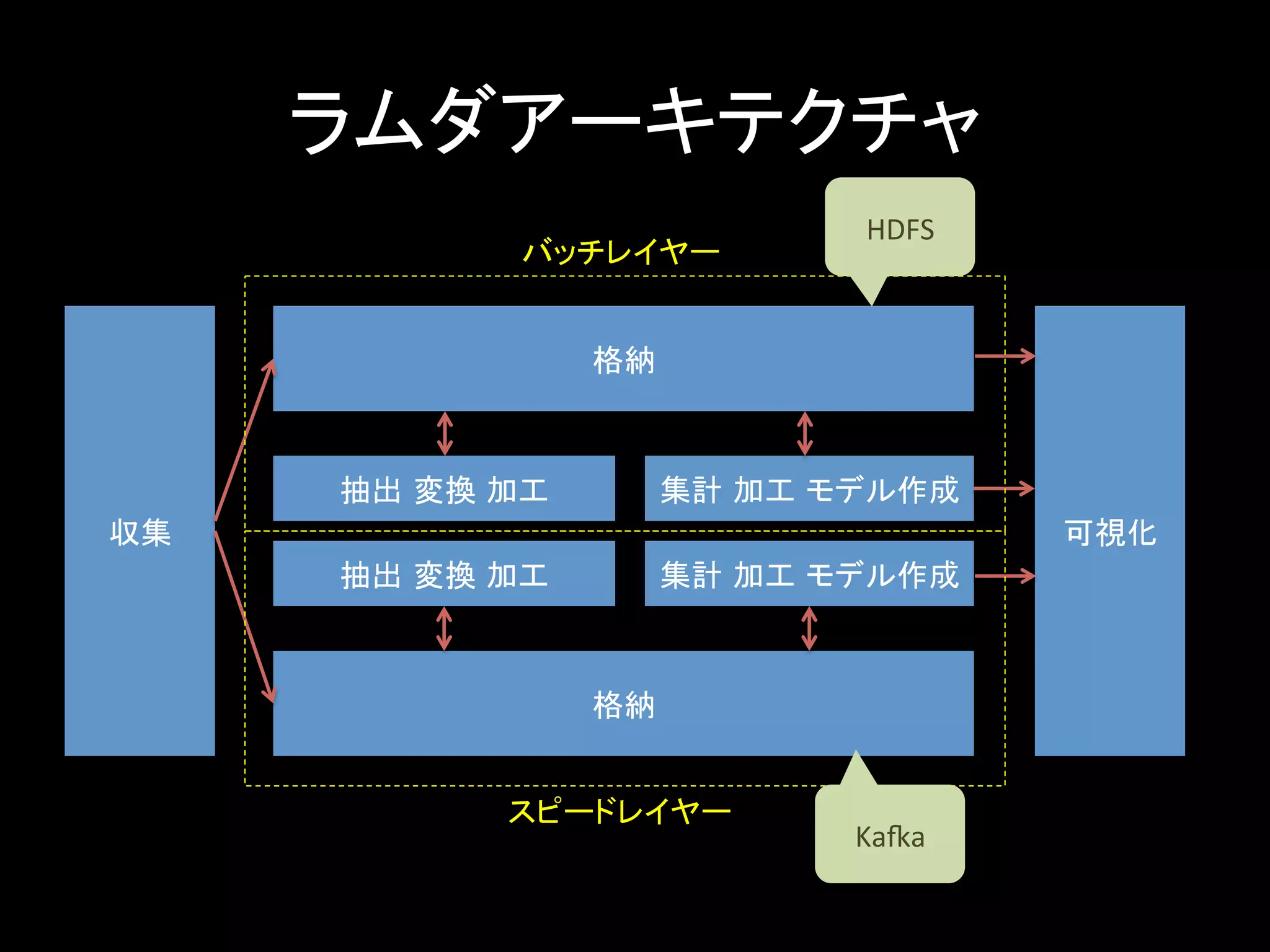
ラムダアーキテクチャ • バッチ処理(Data at Rest)とリアルタイムストリー ム処理(Streaming Data)は組み合わせることで 価値が出る – 近似的な速報値をリアルタイム処理で得る –
正確な集計や深い分析は履歴データを利用しバッチ 処理で得る • データを入口で複製し、用途に応じた最適な フォーマットで格納する – 例: 時間レンジの検索ならHBase、履歴集計なら Parquet
25.
ラムダアーキテクチャ hZps://www.mapr.com/developercentral/lambda-architecture
26.
ラムダアーキテクチャ 収集 抽出 変換 加工 格納 集計
加工 モデル作成 可視化 格納 抽出 変換 加工 集計 加工 モデル作成 バッチレイヤー スピードレイヤー Kaka HDFS
27.
分析のタイプ • バッチ分析 – 蓄積された大量データから知見を得る • リアルタイム分析 – 流れてくるデータを対象にとりあえずの解を得る •
インタラクティブ分析 – よくわからないものから鍵を見つけ方針を決める
28.
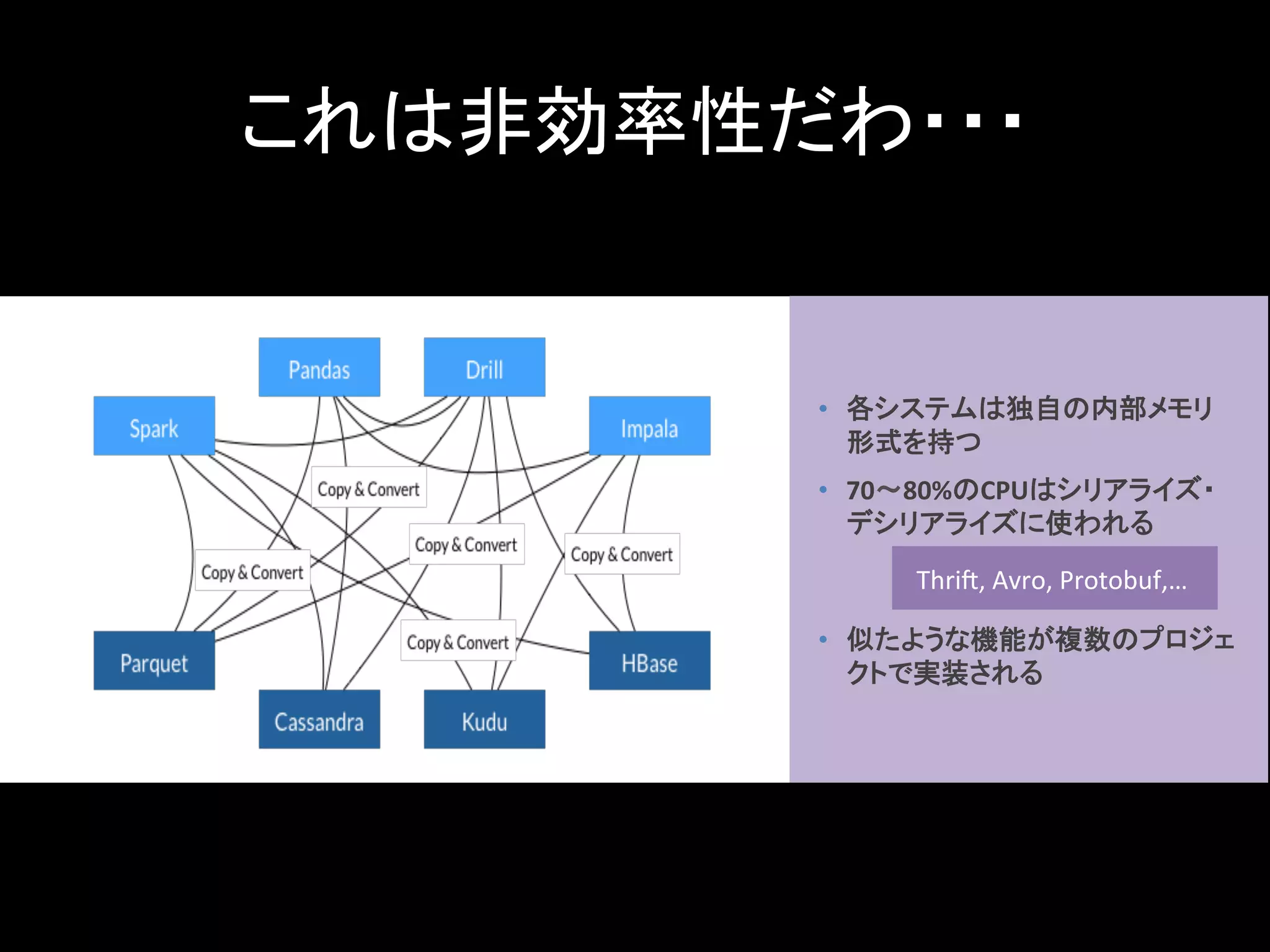
Apache Arrow • カラム型インメモリ分析のデファクト標準を目 指す Apache プロジェクト •
多くのビッグデータ系Apacheプロジェクトで共 通のデータ構造を使うといいよね? • データ構造、アルゴリズム、クロス言語バイン ディングを定義 • 最新のCPUの機能を活用した高速な分析
29.
これは非効率性だわ・・・ • 各システムは独自の内部メモリ 形式を持つ • 70〜80%のCPUはシリアライズ・ デシリアライズに使われる •
似たような機能が複数のプロジェ クトで実装される Thrin, Avro, Protobuf,…
30.
• すべてのシステムは共通のメモリ 形式を持つ • システム間のやりとりにオーバー ヘッドがない •
プロジェクト間で機能を共有できる (例: Parquet-to-Arrow リーダー) ならばこうだ
31.
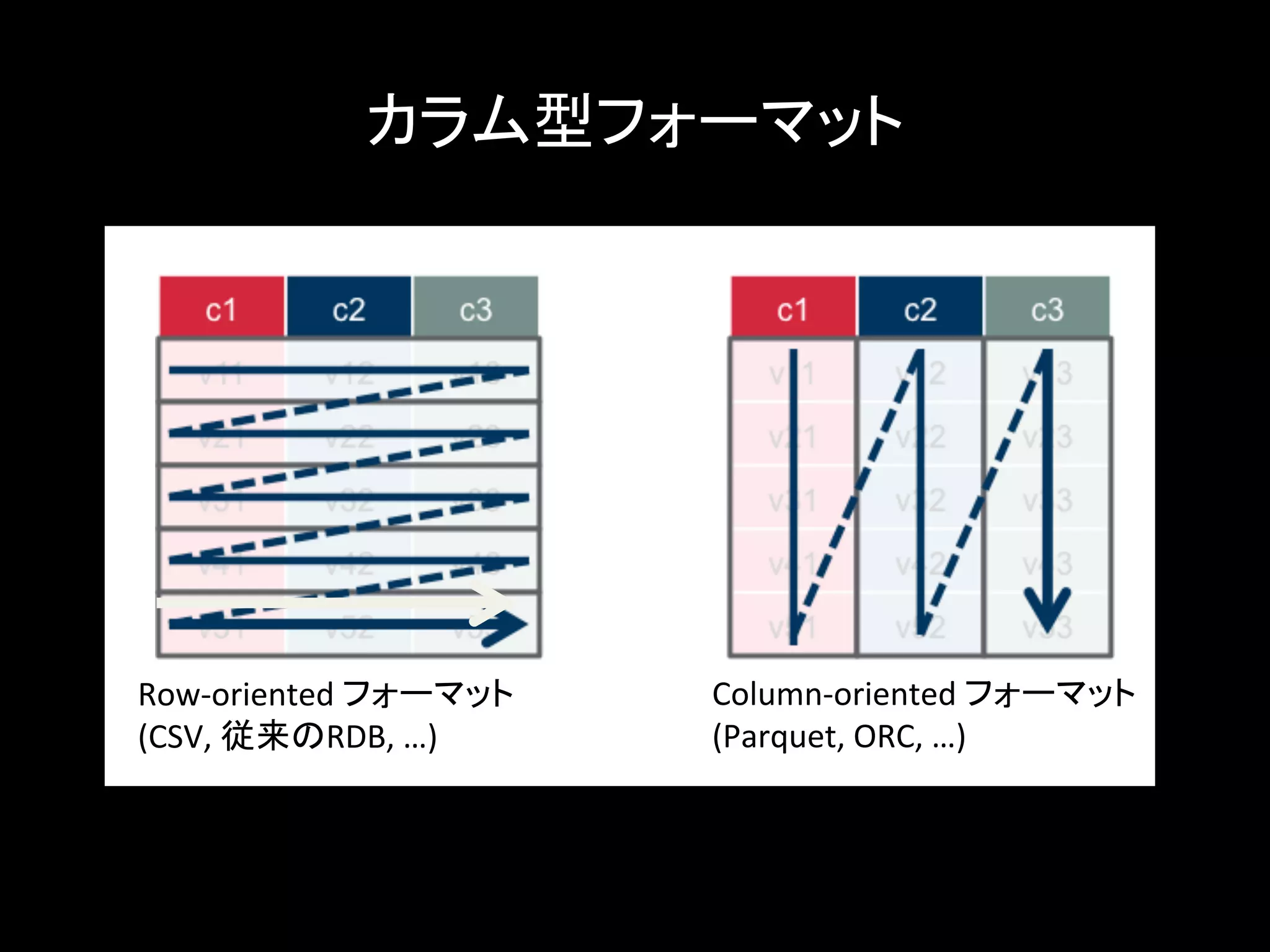
カラム型フォーマット Row-oriented フォーマット (CSV, 従来のRDB, …) Column-oriented フォーマット (Parquet, ORC, …)
32.
Feather File Format • Apache ArrowをベースにしたRとPythonの Data Frameに適したディスク上のファイル フォーマット • なんで今までこんな便利なものがなかったん だ!
33.
PyhtonはUI言語から処理言語へ? hZp://www.slideshare.net/wesm/nextgeneraLon-python-big-data-tools-powered-by-apache-arrow
34.
ありがとうございました
Download

































![[OSC2016沖縄]商用DBからPostgreSQLへの移行入門](https://cdn.slidesharecdn.com/ss_thumbnails/osc2016okinawadbmigrationtopostgres-160704053748-thumbnail.jpg?width=640&height=640&fit=bounds)























![成功事例に学べ! これからの時代のビッグデータ活用最新ベストプラクティス [Oracle Cloud Days Tokyo 2016]](https://cdn.slidesharecdn.com/ss_thumbnails/20161026oracleclouddaysbigdata-161122131938-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Oracle Innovation Summit Tokyo 2018] 水環境の持続を支えるクラウド型ICTプラットフォーム「Water Busine...](https://cdn.slidesharecdn.com/ss_thumbnails/ist18a-2-180822044642-thumbnail.jpg?width=640&height=640&fit=bounds)










![[INSIGHT OUT 2011] b21 ひとつのデータベース技術では生き残れない part2 no sql, hadoop](https://cdn.slidesharecdn.com/ss_thumbnails/insightout2011b21part2nosqlhadoop-111114020909-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
