著者名曖昧性解消手法の分類
3
[Ferreira, et.al., 2012]
データベースにおける名前曖昧性解消は1950年代から検討*される問題であり、
すでにいくつもの解法が提案されているがいまだ十分な解決をみていない
*NEWCOMBE, H. B., KENNEDY, J. M., AXFORD, S. J., & JAMES, A. P. (1959). Automatic linkage of vital records. Science
(New York, N.Y.), 130, 954–959. doi:http://dx.doi.org/10.1126%252Fscience.130.3381.954
Ferreira, A. A., Gonçalves, M. A., & Laender, A. H. F. (2012). A brief survey of automatic methods for author name
disambiguation. ACM SIGMOD Record, 41(2), 15. doi:10.1145/2350036.2350040
Tensor (a third-ordertensor)
8
Element-wise representation
See: Kolda, T. G., & Bader, B. W. (2009). Tensor Decompositions and Applications. SIAM Review, 51(3), 455–500.
doi:10.1137/07070111X
CP decomposition
• CP(CANDECOMP:Canonical decomposition (by Carroll and Chang, 1970) / PARAFAC:
Parallel factors (by Harshman, 1970)) (by Kiers, 2000)
• Hitchcock (1927) already proposed the idea of the polyadic form of a tensor as the sum of
a finite number of rank-one tensors.
13
[Kolda and Bader, 2009]の表記による
14.
Tucker decomposition
• Proposedby Tucker (1966)
14
[Kolda and Bader, 2009]の表記による
のとき、Tucker2 decompositionという
のとき、Tucker1 decompositionといい
Core tensor
Factor matrices as the principal components in each mode
15.
テンソル分解のためのツール
• In Python
–scikit-tensor 0.1
• CP, Tucker, INDSCAL, DEDICOM, RESCAL, tensor operations, etc.
• 2013年にリリース
• Maximilian Nickelによる
• https://pypi.python.org/pypi/scikit-tensor
– pytensor
• MatlabのTensor Toolboxをベース
• Computational biology への応用研究のために作成
• Yoo, J. O., Ramanathan, A., & Langmead, C. (2010). PyTensor: A Python based Tensor
Library. Carnegie Melon University, Computer Science Department.
• https://code.google.com/p/pytensor/
• In Matlab
– MATLAB Tensor Toolbox Version 2.6
• CP, Tucker, Tensor operations, etc.
• 2005年の初期リリース以来改定を続けている
• Tarama G. Koldaら, Sandia National Labs による
• http://www.sandia.gov/~tgkolda/TensorToolbox/index-2.6.html
– Tensorlab
• CP, Tucker, Block term decomposition (CP+Tucker), tensor operations, utilities, etc.
• 2013年に初期リリース
• Laurent Sorber, Marc Van Barel and Lieven De Lathauwer. Tensorlab v2.0, Available online,
January 2014
• http://www.tensorlab.net 15
制約付きTucker 2であるRESCAL*による
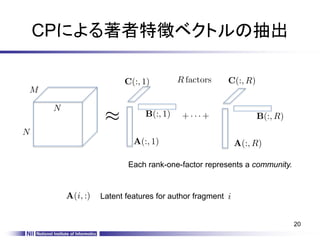
著者特徴ベクトルの抽出
21
and arecalculated by solving the following regularized minimization problem
Rank-R factorization for tensor
Tensor frontal slice-k
Latent features for author fragment
* Nickel, M., Tresp, V., & Kriegel, H.-P. (2011). A Three-Way Model for Collective Learning on Multi-Relational Data. 28th
International Conference on Machine Learning, 809–816.


![著者名曖昧性解消手法の分類
3
[Ferreira, et.al., 2012]
データベースにおける名前曖昧性解消は1950年代から検討*される問題であり、
すでにいくつもの解法が提案されているがいまだ十分な解決をみていない
* NEWCOMBE, H. B., KENNEDY, J. M., AXFORD, S. J., & JAMES, A. P. (1959). Automatic linkage of vital records. Science
(New York, N.Y.), 130, 954–959. doi:http://dx.doi.org/10.1126%252Fscience.130.3381.954
Ferreira, A. A., Gonçalves, M. A., & Laender, A. H. F. (2012). A brief survey of automatic methods for author name
disambiguation. ACM SIGMOD Record, 41(2), 15. doi:10.1145/2350036.2350040](https://image.slidesharecdn.com/ipsj-annual78-kurakawa-160312084033/85/slide-3-320.jpg)









![CP decomposition
• CP(CANDECOMP: Canonical decomposition (by Carroll and Chang, 1970) / PARAFAC:
Parallel factors (by Harshman, 1970)) (by Kiers, 2000)
• Hitchcock (1927) already proposed the idea of the polyadic form of a tensor as the sum of
a finite number of rank-one tensors.
13
[Kolda and Bader, 2009]の表記による](https://image.slidesharecdn.com/ipsj-annual78-kurakawa-160312084033/85/slide-13-320.jpg)
![Tucker decomposition
• Proposed by Tucker (1966)
14
[Kolda and Bader, 2009]の表記による
のとき、Tucker2 decompositionという
のとき、Tucker1 decompositionといい
Core tensor
Factor matrices as the principal components in each mode](https://image.slidesharecdn.com/ipsj-annual78-kurakawa-160312084033/85/slide-14-320.jpg)





































![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)

























